 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeriving Visual Semantics from Spatial Context: An Adaptation of LSA and Word2Vec to generate Object and Scene Embeddings from Images
Sep 20, 2020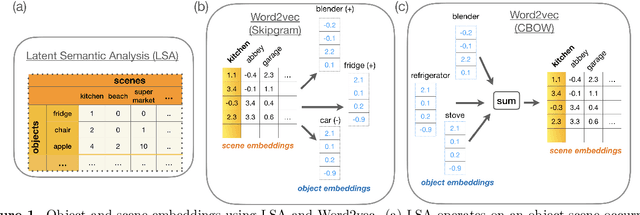
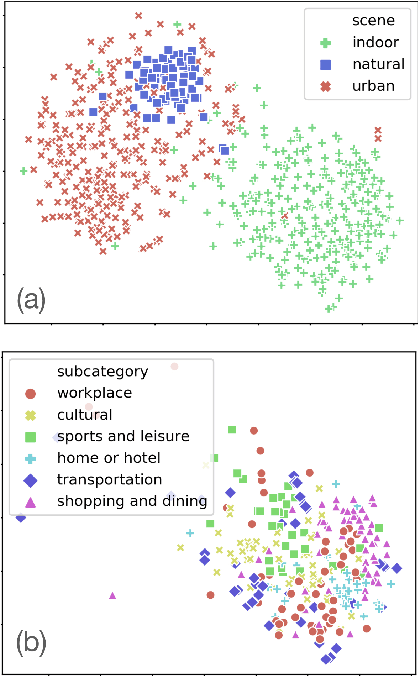
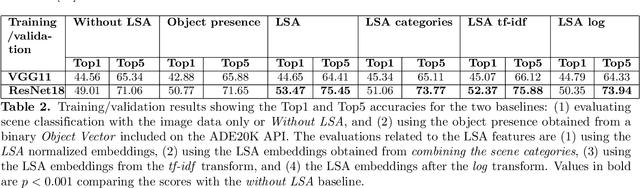

Embeddings are an important tool for the representation of word meaning. Their effectiveness rests on the distributional hypothesis: words that occur in the same context carry similar semantic information. Here, we adapt this approach to index visual semantics in images of scenes. To this end, we formulate a distributional hypothesis for objects and scenes: Scenes that contain the same objects (object context) are semantically related. Similarly, objects that appear in the same spatial context (within a scene or subregions of a scene) are semantically related. We develop two approaches for learning object and scene embeddings from annotated images. In the first approach, we adapt LSA and Word2vec's Skipgram and CBOW models to generate two sets of embeddings from object co-occurrences in whole images, one for objects and one for scenes. The representational space spanned by these embeddings suggests that the distributional hypothesis holds for images. In an initial application of this approach, we show that our image-based embeddings improve scene classification models such as ResNet18 and VGG-11 (3.72\% improvement on Top5 accuracy, 4.56\% improvement on Top1 accuracy). In the second approach, rather than analyzing whole images of scenes, we focus on co-occurrences of objects within subregions of an image. We illustrate that this method yields a sensible hierarchical decomposition of a scene into collections of semantically related objects. Overall, these results suggest that object and scene embeddings from object co-occurrences and spatial context yield semantically meaningful representations as well as computational improvements for downstream applications such as scene classification.
Cross-validation in high-dimensional spaces: a lifeline for least-squares models and multi-class LDA
Mar 27, 2018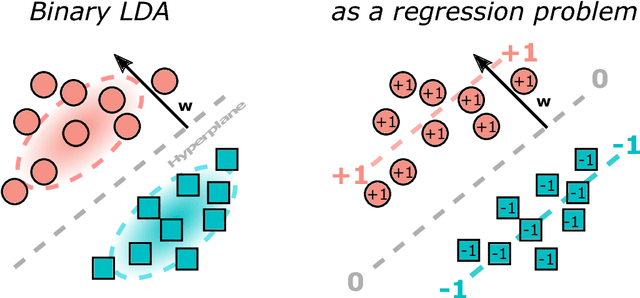

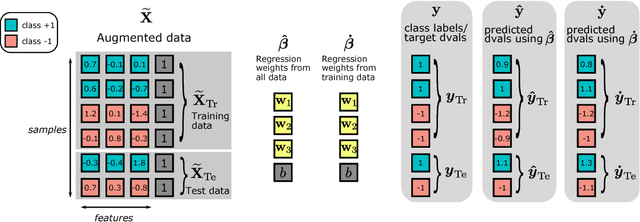
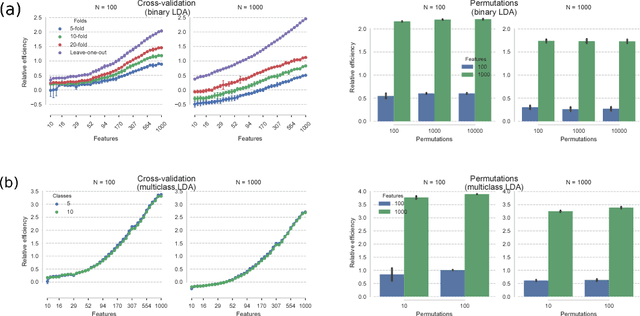
Least-squares models such as linear regression and Linear Discriminant Analysis (LDA) are amongst the most popular statistical learning techniques. However, since their computation time increases cubically with the number of features, they are inefficient in high-dimensional neuroimaging datasets. Fortunately, for k-fold cross-validation, an analytical approach has been developed that yields the exact cross-validated predictions in least-squares models without explicitly training the model. Its computation time grows with the number of test samples. Here, this approach is systematically investigated in the context of cross-validation and permutation testing. LDA is used exemplarily but results hold for all other least-squares methods. Furthermore, a non-trivial extension to multi-class LDA is formally derived. The analytical approach is evaluated using complexity calculations, simulations, and permutation testing of an EEG/MEG dataset. Depending on the ratio between features and samples, the analytical approach is up to 10,000x faster than the standard approach (retraining the model on each training set). This allows for a fast cross-validation of least-squares models and multi-class LDA in high-dimensional data, with obvious applications in multi-dimensional datasets, Representational Similarity Analysis, and permutation testing.