 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep-Learning Driven Noise Reduction for Reduced Flux Computed Tomography
Jan 18, 2021
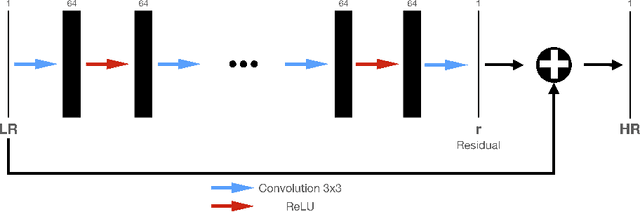
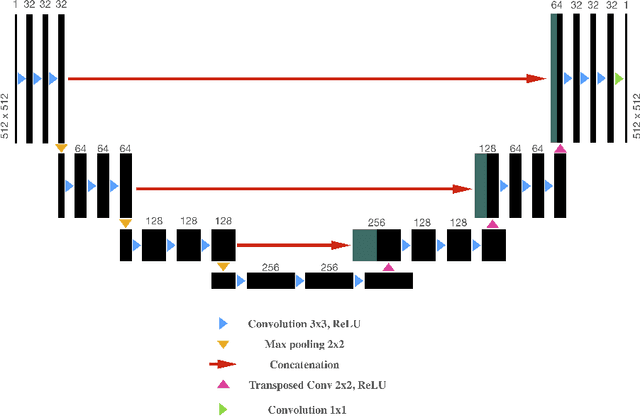
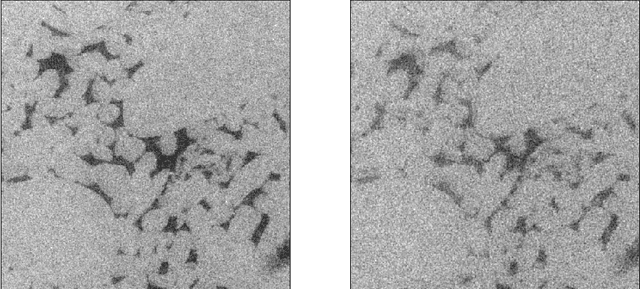
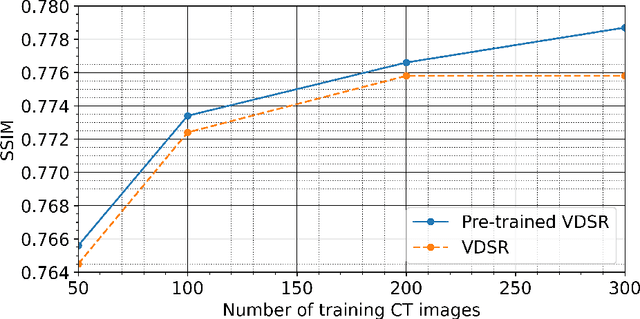
Deep neural networks have received considerable attention in clinical imaging, particularly with respect to the reduction of radiation risk. Lowering the radiation dose by reducing the photon flux inevitably results in the degradation of the scanned image quality. Thus, researchers have sought to exploit deep convolutional neural networks (DCNNs) to map low-quality, low-dose images to higher-dose, higher-quality images thereby minimizing the associated radiation hazard. Conversely, computed tomography (CT) measurements of geomaterials are not limited by the radiation dose. In contrast to the human body, however, geomaterials may be comprised of high-density constituents causing increased attenuation of the X-Rays. Consequently, higher dosage images are required to obtain an acceptable scan quality. The problem of prolonged acquisition times is particularly severe for micro-CT based scanning technologies. Depending on the sample size and exposure time settings, a single scan may require several hours to complete. This is of particular concern if phenomena with an exponential temperature dependency are to be elucidated. A process may happen too fast to be adequately captured by CT scanning. To address the aforementioned issues, we apply DCNNs to improve the quality of rock CT images and reduce exposure times by more than 60\%, simultaneously. We highlight current results based on micro-CT derived datasets and apply transfer learning to improve DCNN results without increasing training time. The approach is applicable to any computed tomography technology. Furthermore, we contrast the performance of the DCNN trained by minimizing different loss functions such as mean squared error and structural similarity index.
An Once-for-All Budgeted Pruning Framework for ConvNets Considering Input Resolution
Dec 02, 2020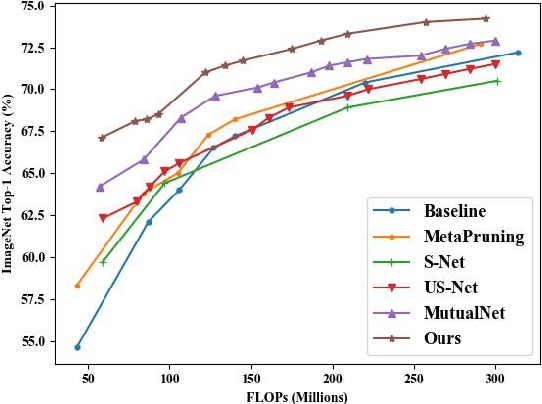

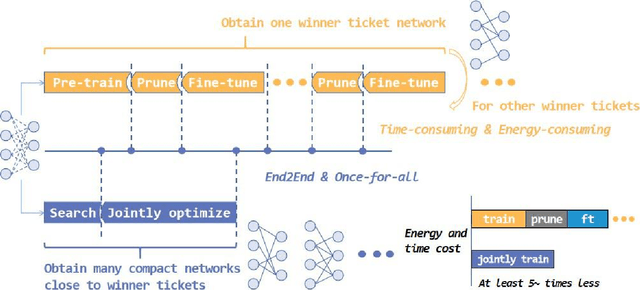
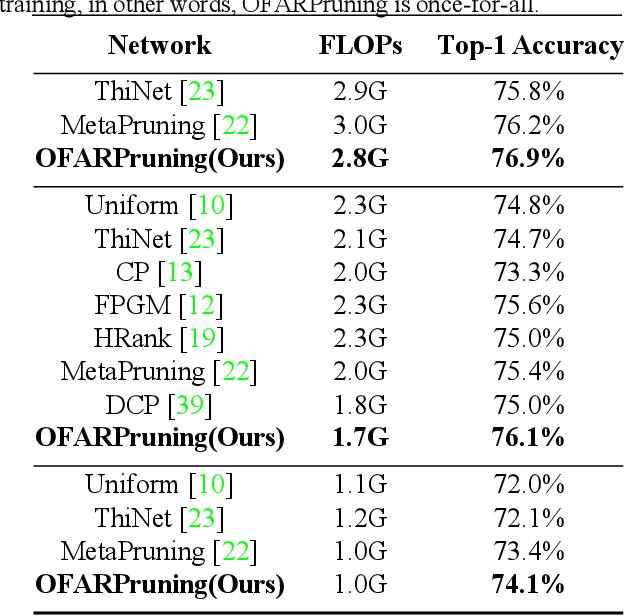
We propose an efficient once-for-all budgeted pruning framework (OFARPruning) to find many compact network structures close to winner tickets in the early training stage considering the effect of input resolution during the pruning process. In structure searching stage, we utilize cosine similarity to measure the similarity of the pruning mask to get high-quality network structures with low energy and time consumption. After structure searching stage, our proposed method randomly sample the compact structures with different pruning rates and input resolution to achieve joint optimization. Ultimately, we can obtain a cohort of compact networks adaptive to various resolution to meet dynamic FLOPs constraints on different edge devices with only once training. The experiments based on image classification and object detection show that OFARPruning has a higher accuracy than the once-for-all compression methods such as US-Net and MutualNet (1-2% better with less FLOPs), and achieve the same even higher accuracy as the conventional pruning methods (72.6% vs. 70.5% on MobileNetv2 under 170 MFLOPs) with much higher efficiency.
When Saliency Meets Sentiment: Understanding How Image Content Invokes Emotion and Sentiment
Nov 14, 2016

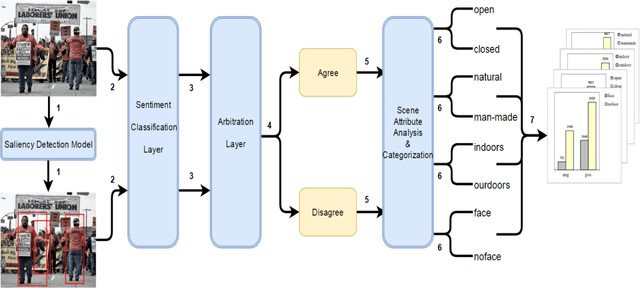
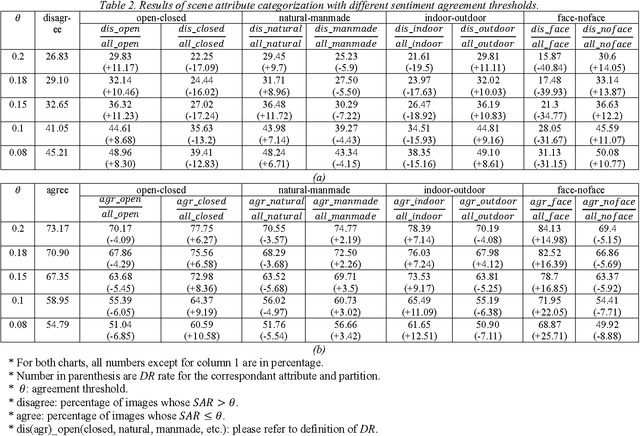
Sentiment analysis is crucial for extracting social signals from social media content. Due to the prevalence of images in social media, image sentiment analysis is receiving increasing attention in recent years. However, most existing systems are black-boxes that do not provide insight on how image content invokes sentiment and emotion in the viewers. Psychological studies have confirmed that salient objects in an image often invoke emotions. In this work, we investigate more fine-grained and more comprehensive interaction between visual saliency and visual sentiment. In particular, we partition images in several primary scene-type dimensions, including: open-closed, natural-manmade, indoor-outdoor, and face-noface. Using state of the art saliency detection algorithm and sentiment classification algorithm, we examine how the sentiment of the salient region(s) in an image relates to the overall sentiment of the image. The experiments on a representative image emotion dataset have shown interesting correlation between saliency and sentiment in different scene types and in turn shed light on the mechanism of visual sentiment evocation.
Convexity Shape Prior for Level Set based Image Segmentation Method
May 22, 2018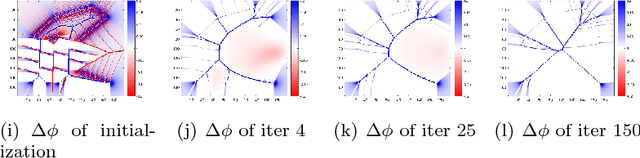
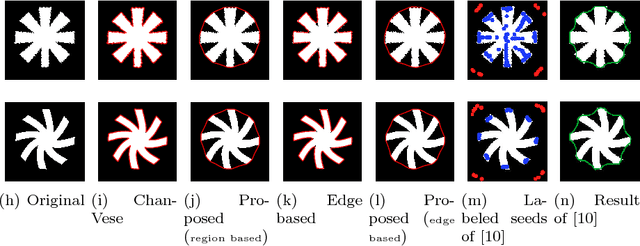
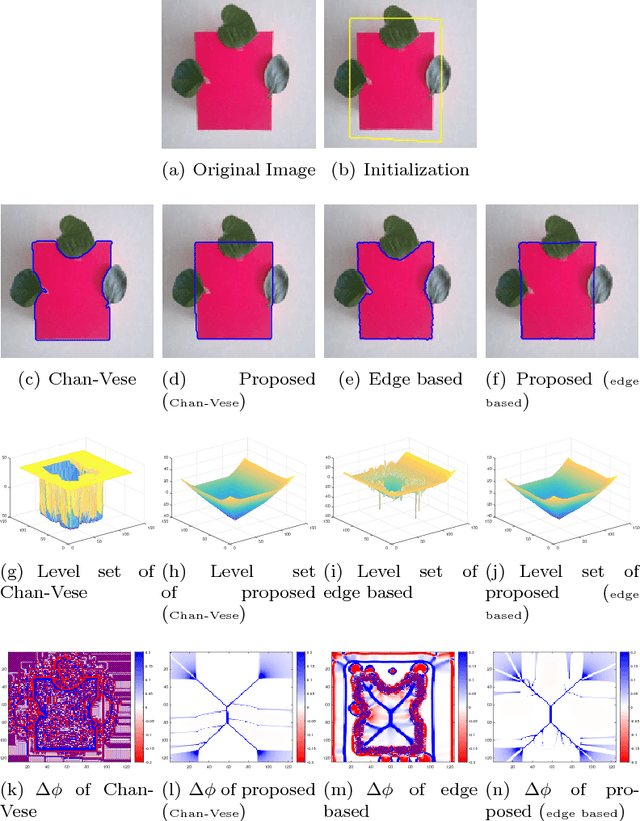

We propose a geometric convexity shape prior preservation method for variational level set based image segmentation methods. Our method is built upon the fact that the level set of a convex signed distanced function must be convex. This property enables us to transfer a complicated geometrical convexity prior into a simple inequality constraint on the function. An active set based Gauss-Seidel iteration is used to handle this constrained minimization problem to get an efficient algorithm. We apply our method to region and edge based level set segmentation models including Chan-Vese (CV) model with guarantee that the segmented region will be convex. Experimental results show the effectiveness and quality of the proposed model and algorithm.
Inability of spatial transformations of CNN feature maps to support invariant recognition
Apr 30, 2020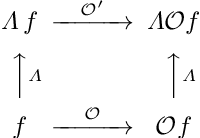
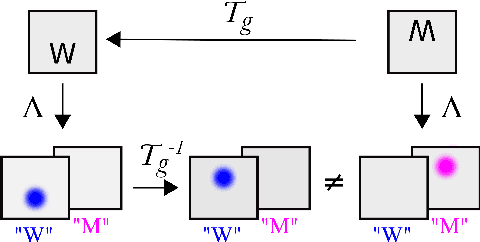
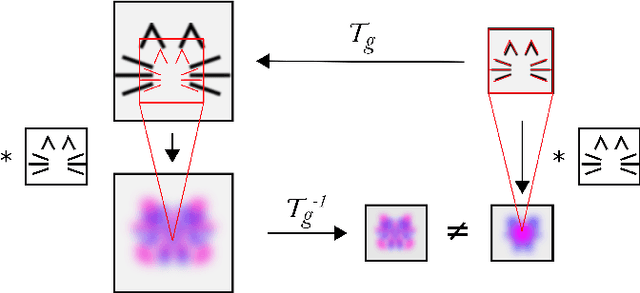
A large number of deep learning architectures use spatial transformations of CNN feature maps or filters to better deal with variability in object appearance caused by natural image transformations. In this paper, we prove that spatial transformations of CNN feature maps cannot align the feature maps of a transformed image to match those of its original, for general affine transformations, unless the extracted features are themselves invariant. Our proof is based on elementary analysis for both the single- and multi-layer network case. The results imply that methods based on spatial transformations of CNN feature maps or filters cannot replace image alignment of the input and cannot enable invariant recognition for general affine transformations, specifically not for scaling transformations or shear transformations. For rotations and reflections, spatially transforming feature maps or filters can enable invariance but only for networks with learnt or hardcoded rotation- or reflection-invariant features
What is the Role of Recurrent Neural Networks (RNNs) in an Image Caption Generator?
Aug 25, 2017
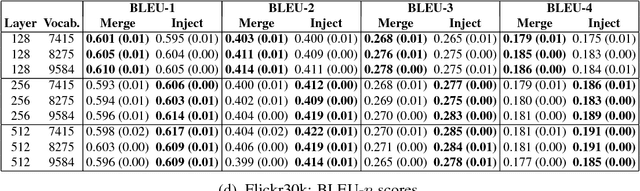
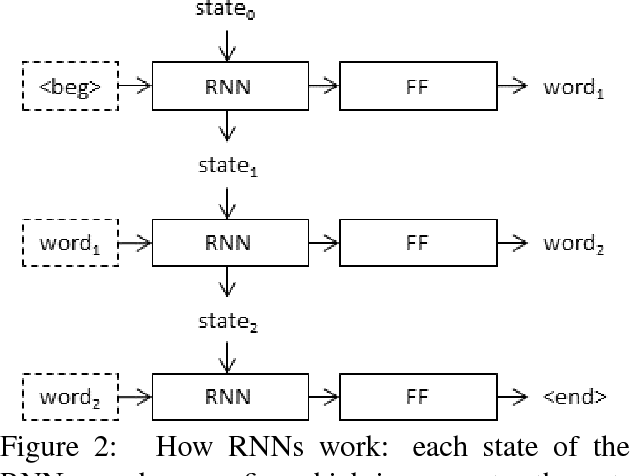
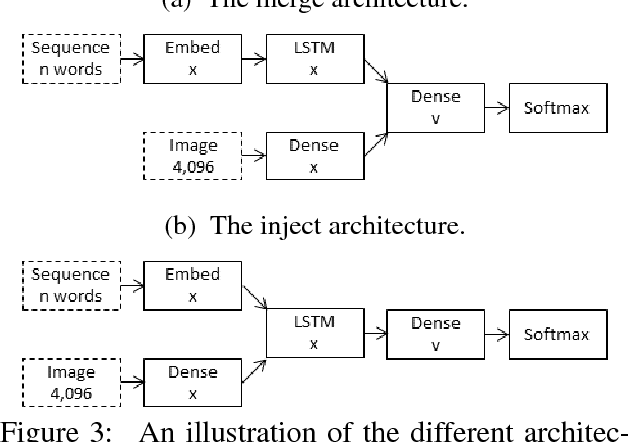
In neural image captioning systems, a recurrent neural network (RNN) is typically viewed as the primary `generation' component. This view suggests that the image features should be `injected' into the RNN. This is in fact the dominant view in the literature. Alternatively, the RNN can instead be viewed as only encoding the previously generated words. This view suggests that the RNN should only be used to encode linguistic features and that only the final representation should be `merged' with the image features at a later stage. This paper compares these two architectures. We find that, in general, late merging outperforms injection, suggesting that RNNs are better viewed as encoders, rather than generators.
Logically Consistent Loss for Visual Question Answering
Nov 19, 2020
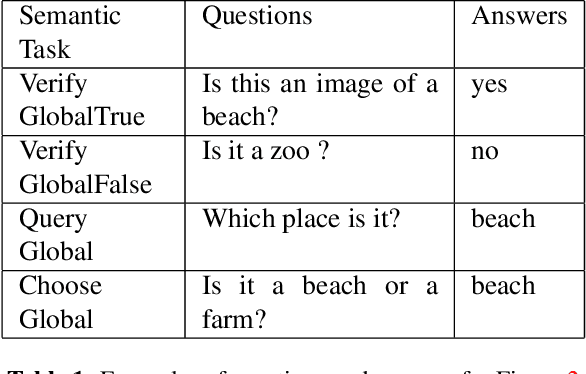
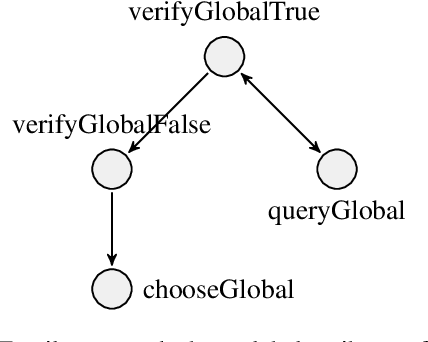
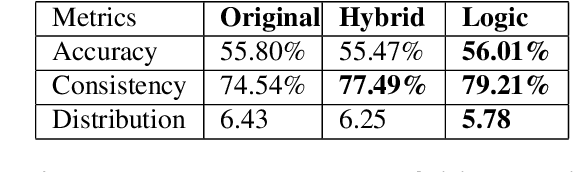
Given an image, a back-ground knowledge, and a set of questions about an object, human learners answer the questions very consistently regardless of question forms and semantic tasks. The current advancement in neural-network based Visual Question Answering (VQA), despite their impressive performance, cannot ensure such consistency due to identically distribution (i.i.d.) assumption. We propose a new model-agnostic logic constraint to tackle this issue by formulating a logically consistent loss in the multi-task learning framework as well as a data organisation called family-batch and hybrid-batch. To demonstrate usefulness of this proposal, we train and evaluate MAC-net based VQA machines with and without the proposed logically consistent loss and the proposed data organization. The experiments confirm that the proposed loss formulae and introduction of hybrid-batch leads to more consistency as well as better performance. Though the proposed approach is tested with MAC-net, it can be utilised in any other QA methods whenever the logical consistency between answers exist.
AI Playground: Unreal Engine-based Data Ablation Tool for Deep Learning
Jul 13, 2020
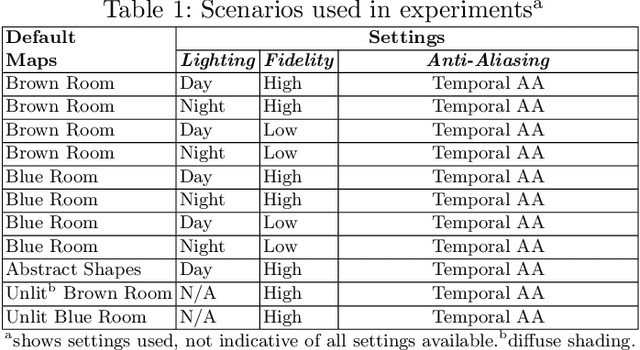
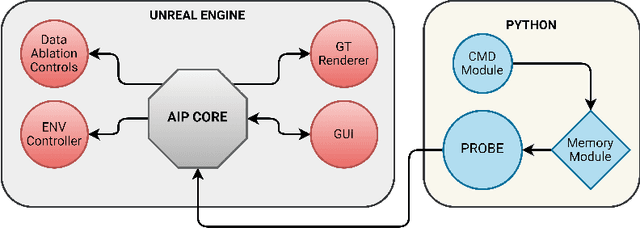

Machine learning requires data, but acquiring and labeling real-world data is challenging, expensive, and time-consuming. More importantly, it is nearly impossible to alter real data post-acquisition (e.g., change the illumination of a room), making it very difficult to measure how specific properties of the data affect performance. In this paper, we present AI Playground (AIP), an open-source, Unreal Engine-based tool for generating and labeling virtual image data. With AIP, it is trivial to capture the same image under different conditions (e.g., fidelity, lighting, etc.) and with different ground truths (e.g., depth or surface normal values). AIP is easily extendable and can be used with or without code. To validate our proposed tool, we generated eight datasets of otherwise identical but varying lighting and fidelity conditions. We then trained deep neural networks to predict (1) depth values, (2) surface normals, or (3) object labels and assessed each network's intra- and cross-dataset performance. Among other insights, we verified that sensitivity to different settings is problem-dependent. We confirmed the findings of other studies that segmentation models are very sensitive to fidelity, but we also found that they are just as sensitive to lighting. In contrast, depth and normal estimation models seem to be less sensitive to fidelity or lighting and more sensitive to the structure of the image. Finally, we tested our trained depth-estimation networks on two real-world datasets and obtained results comparable to training on real data alone, confirming that our virtual environments are realistic enough for real-world tasks.
Contrastive Cross-site Learning with Redesigned Net for COVID-19 CT Classification
Sep 15, 2020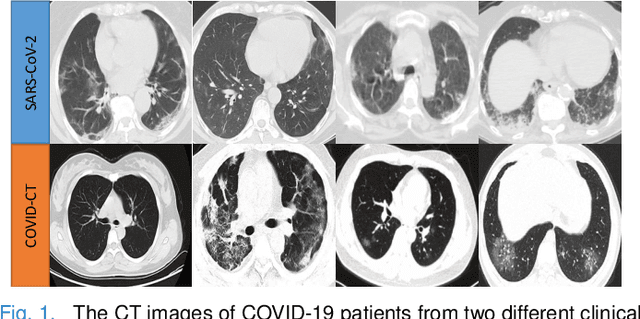
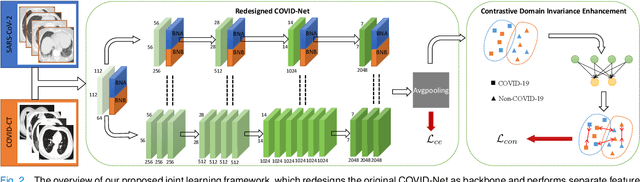
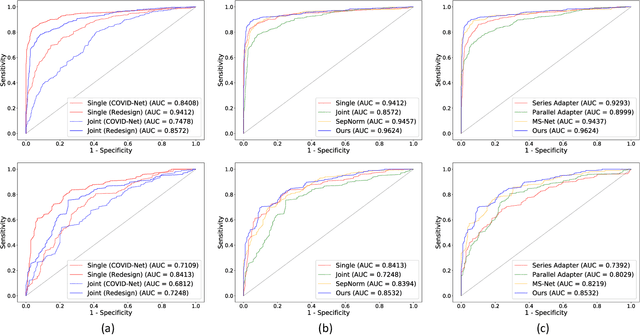
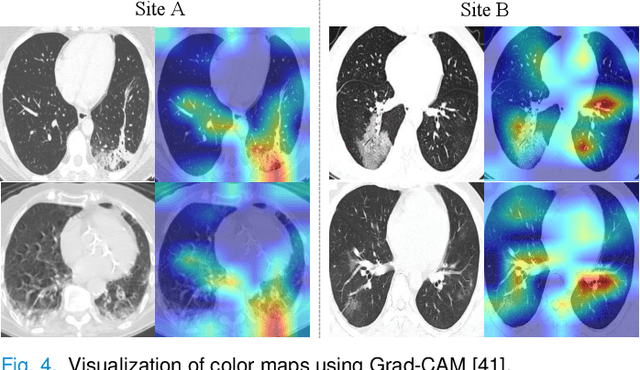
The pandemic of coronavirus disease 2019 (COVID-19) has lead to a global public health crisis spreading hundreds of countries. With the continuous growth of new infections, developing automated tools for COVID-19 identification with CT image is highly desired to assist the clinical diagnosis and reduce the tedious workload of image interpretation. To enlarge the datasets for developing machine learning methods, it is essentially helpful to aggregate the cases from different medical systems for learning robust and generalizable models. This paper proposes a novel joint learning framework to perform accurate COVID-19 identification by effectively learning with heterogeneous datasets with distribution discrepancy. We build a powerful backbone by redesigning the recently proposed COVID-Net in aspects of network architecture and learning strategy to improve the prediction accuracy and learning efficiency. On top of our improved backbone, we further explicitly tackle the cross-site domain shift by conducting separate feature normalization in latent space. Moreover, we propose to use a contrastive training objective to enhance the domain invariance of semantic embeddings for boosting the classification performance on each dataset. We develop and evaluate our method with two public large-scale COVID-19 diagnosis datasets made up of CT images. Extensive experiments show that our approach consistently improves the performances on both datasets, outperforming the original COVID-Net trained on each dataset by 12.16% and 14.23% in AUC respectively, also exceeding existing state-of-the-art multi-site learning methods.
Learning Loss for Test-Time Augmentation
Oct 22, 2020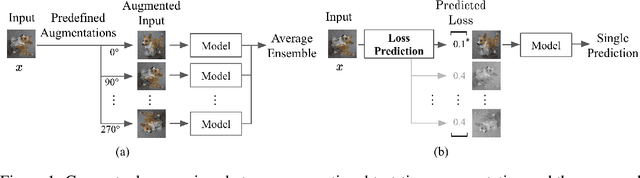
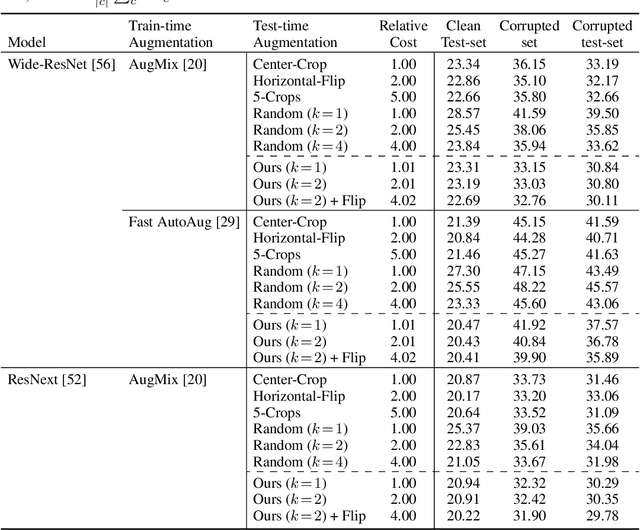
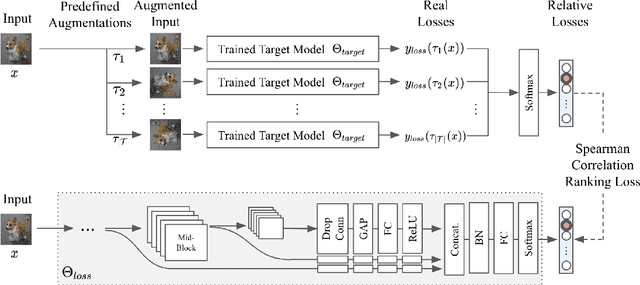

Data augmentation has been actively studied for robust neural networks. Most of the recent data augmentation methods focus on augmenting datasets during the training phase. At the testing phase, simple transformations are still widely used for test-time augmentation. This paper proposes a novel instance-level test-time augmentation that efficiently selects suitable transformations for a test input. Our proposed method involves an auxiliary module to predict the loss of each possible transformation given the input. Then, the transformations having lower predicted losses are applied to the input. The network obtains the results by averaging the prediction results of augmented inputs. Experimental results on several image classification benchmarks show that the proposed instance-aware test-time augmentation improves the model's robustness against various corruptions.