 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adversarially-Trained Deep Nets Transfer Better
Jul 11, 2020


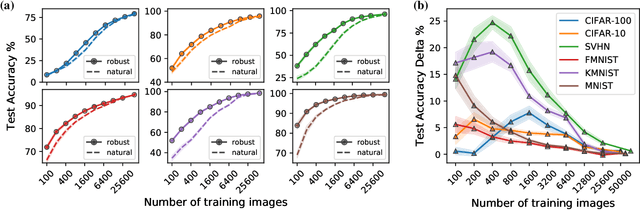
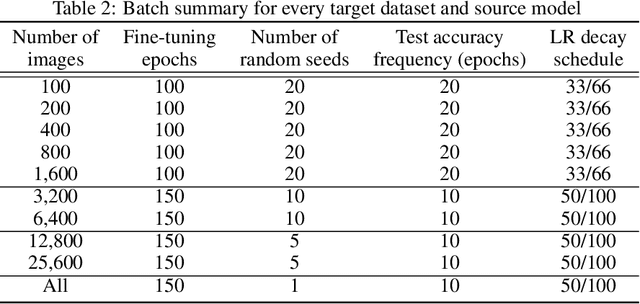
Transfer learning has emerged as a powerful methodology for adapting pre-trained deep neural networks to new domains. This process consists of taking a neural network pre-trained on a large feature-rich source dataset, freezing the early layers that encode essential generic image properties, and then fine-tuning the last few layers in order to capture specific information related to the target situation. This approach is particularly useful when only limited or weakly labelled data are available for the new task. In this work, we demonstrate that adversarially-trained models transfer better across new domains than naturally-trained models, even though it's known that these models do not generalize as well as naturally-trained models on the source domain. We show that this behavior results from a bias, introduced by the adversarial training, that pushes the learned inner layers to more natural image representations, which in turn enables better transfer.
Image-based phenotyping of diverse Rice (Oryza Sativa L.) Genotypes
Apr 06, 2020
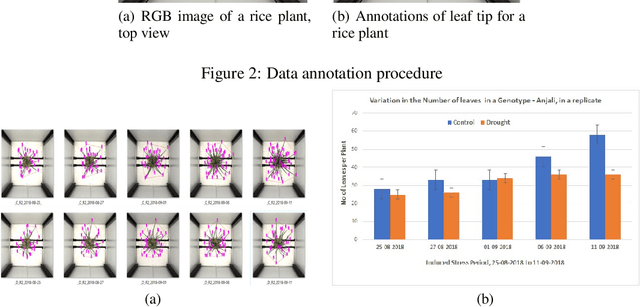
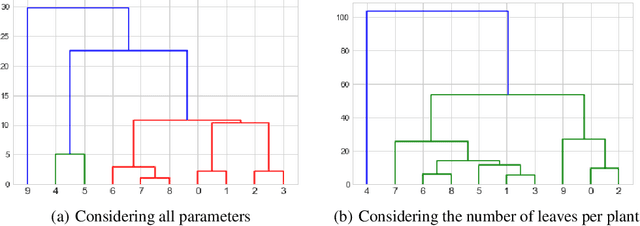
Development of either drought-resistant or drought-tolerant varieties in rice (Oryza sativa L.), especially for high yield in the context of climate change, is a crucial task across the world. The need for high yielding rice varieties is a prime concern for developing nations like India, China, and other Asian-African countries where rice is a primary staple food. The present investigation is carried out for discriminating drought tolerant, and susceptible genotypes. A total of 150 genotypes were grown under controlled conditions to evaluate at High Throughput Plant Phenomics facility, Nanaji Deshmukh Plant Phenomics Centre, Indian Council of Agricultural Research-Indian Agricultural Research Institute, New Delhi. A subset of 10 genotypes is taken out of 150 for the current investigation. To discriminate against the genotypes, we considered features such as the number of leaves per plant, the convex hull and convex hull area of a plant-convex hull formed by joining the tips of the leaves, the number of leaves per unit convex hull of a plant, canopy spread - vertical spread, and horizontal spread of a plant. We trained You Only Look Once (YOLO) deep learning algorithm for leaves tips detection and to estimate the number of leaves in a rice plant. With this proposed framework, we screened the genotypes based on selected traits. These genotypes were further grouped among different groupings of drought-tolerant and drought susceptible genotypes using the Ward method of clustering.
Chair Segments: A Compact Benchmark for the Study of Object Segmentation
Dec 02, 2020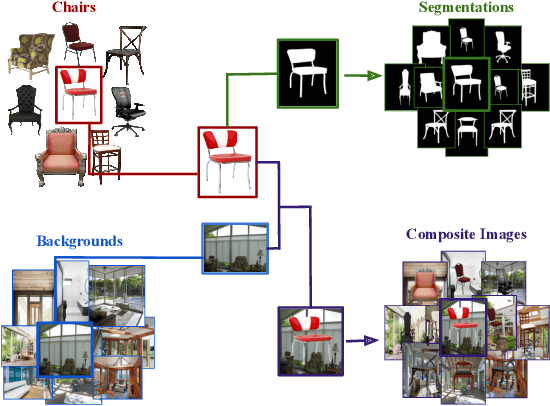
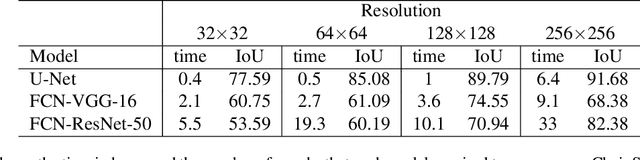

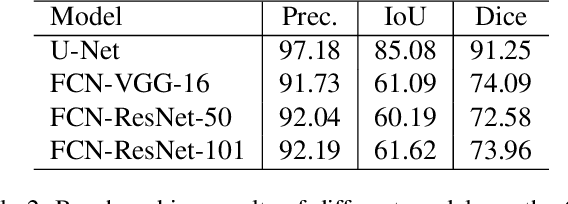
Over the years, datasets and benchmarks have had an outsized influence on the design of novel algorithms. In this paper, we introduce ChairSegments, a novel and compact semi-synthetic dataset for object segmentation. We also show empirical findings in transfer learning that mirror recent findings for image classification. We particularly show that models that are fine-tuned from a pretrained set of weights lie in the same basin of the optimization landscape. ChairSegments consists of a diverse set of prototypical images of chairs with transparent backgrounds composited into a diverse array of backgrounds. We aim for ChairSegments to be the equivalent of the CIFAR-10 dataset but for quickly designing and iterating over novel model architectures for segmentation. On Chair Segments, a U-Net model can be trained to full convergence in only thirty minutes using a single GPU. Finally, while this dataset is semi-synthetic, it can be a useful proxy for real data, leading to state-of-the-art accuracy on the Object Discovery dataset when used as a source of pretraining.
Regularization by Denoising via Fixed-Point Projection (RED-PRO)
Aug 01, 2020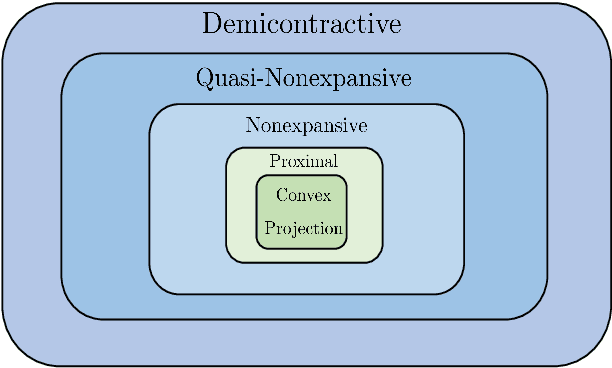
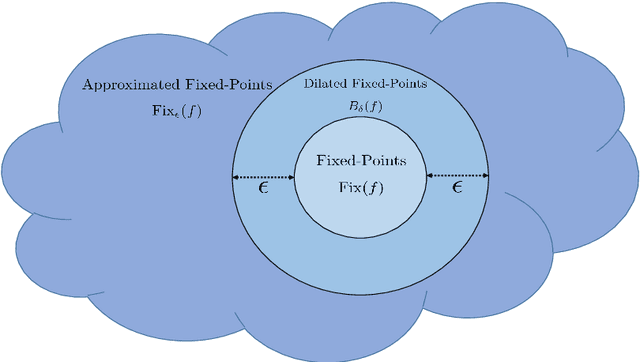
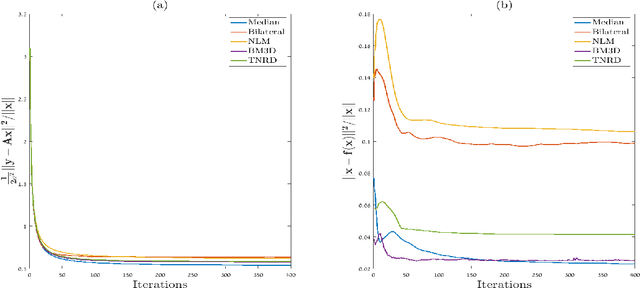
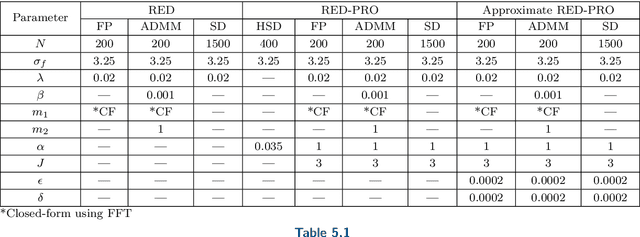
Inverse problems in image processing are typically cast as optimization tasks, consisting of data fidelity and stabilizing regularization terms. A recent regularization strategy of great interest utilizes the power of denoising engines. Two such methods are the Plug-and-Play Prior (PnP) and Regularization by Denoising (RED). While both have shown state-of-the-art results in various recovery tasks, their theoretical justification is incomplete. In this paper, we aim to enrich the understanding of RED and its connection to PnP. Towards that end, we reformulate RED as a convex optimization problem utilizing a projection (RED- PRO) onto the fixed-point set of demicontractive denoisers. We offer a simple iterative solution to this problem, and establish a novel unification of RED-PRO and PnP, while providing guarantees for their convergence to the globally optimal solution. We also present several relaxations of RED-PRO that allow for handling denoisers with limited fixed-point sets. Finally, we demonstrate RED-PRO for the tasks of image deblurring and super-resolution, showing improved results with respect to the original RED framework.
Generative ScatterNet Hybrid Deep Learning (G-SHDL) Network with Structural Priors for Semantic Image Segmentation
Feb 13, 2018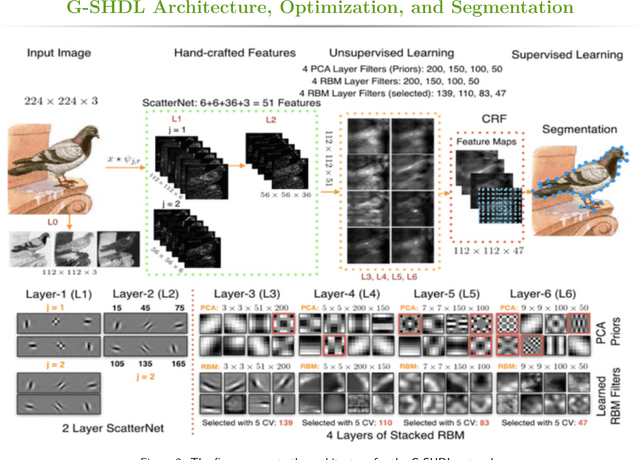
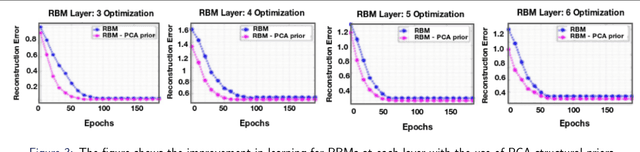
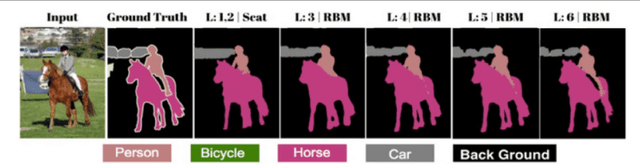
This paper proposes a generative ScatterNet hybrid deep learning (G-SHDL) network for semantic image segmentation. The proposed generative architecture is able to train rapidly from relatively small labeled datasets using the introduced structural priors. In addition, the number of filters in each layer of the architecture is optimized resulting in a computationally efficient architecture. The G-SHDL network produces state-of-the-art classification performance against unsupervised and semi-supervised learning on two image datasets. Advantages of the G-SHDL network over supervised methods are demonstrated with experiments performed on training datasets of reduced size.
Template Matching Advances and Applications in Image Analysis
Oct 23, 2016
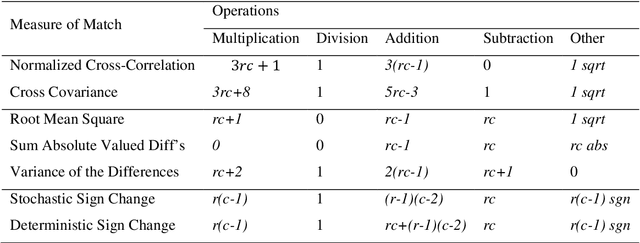
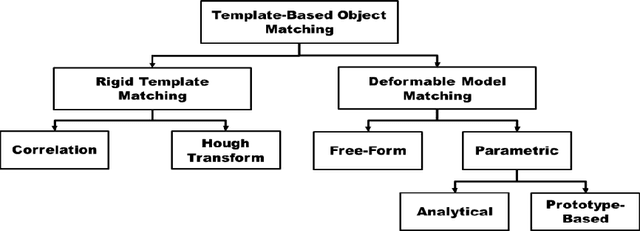
In most computer vision and image analysis problems, it is necessary to define a similarity measure between two or more different objects or images. Template matching is a classic and fundamental method used to score similarities between objects using certain mathematical algorithms. In this paper, we reviewed the basic concept of matching, as well as advances in template matching and applications such as invariant features or novel applications in medical image analysis. Additionally, deformable models and templates originating from classic template matching were discussed. These models have broad applications in image registration, and they are a fundamental aspect of novel machine vision or deep learning algorithms, such as convolutional neural networks (CNN), which perform shift and scale invariant functions followed by classification. In general, although template matching methods have restrictions which limit their application, they are recommended for use with other object recognition methods as pre- or post-processing steps. Combining a template matching technique such as normalized cross-correlation or dice coefficient with a robust decision-making algorithm yields a significant improvement in the accuracy rate for object detection and recognition.
Efficient Conditional Pre-training for Transfer Learning
Nov 20, 2020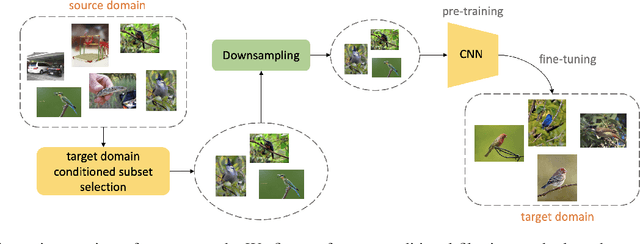
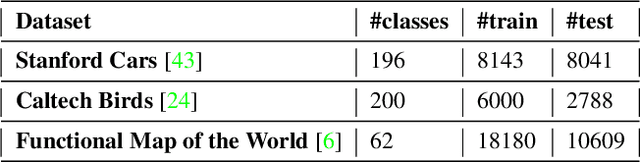
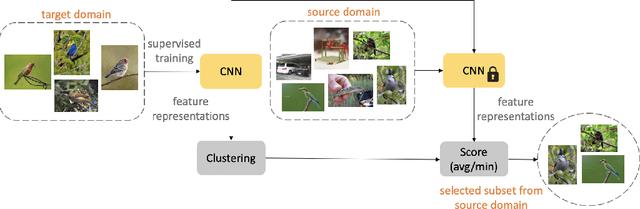
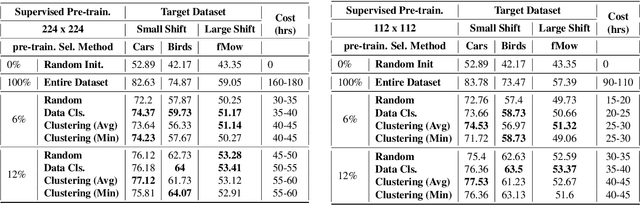
Almost all the state-of-the-art neural networks for computer vision tasks are trained by (1) Pre-training on a large scale dataset and (2) finetuning on the target dataset. This strategy helps reduce the dependency on the target dataset and improves convergence rate and generalization on the target task. Although pre-training on large scale datasets is very useful, its foremost disadvantage is high training cost. To address this, we propose efficient target dataset conditioned filtering methods to remove less relevant samples from the pre-training dataset. Unlike prior work, we focus on efficiency, adaptability, and flexibility in addition to performance. Additionally, we discover that lowering image resolutions in the pre-training step offers a great trade-off between cost and performance. We validate our techniques by pre-training on ImageNet in both the unsupervised and supervised settings and finetuning on a diverse collection of target datasets and tasks. Our proposed methods drastically reduce pre-training cost and provide strong performance boosts.
Compressed Sensing Plus Motion (CS+M): A New Perspective for Improving Undersampled MR Image Reconstruction
Oct 25, 2018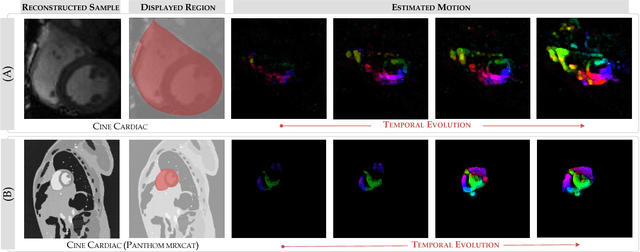
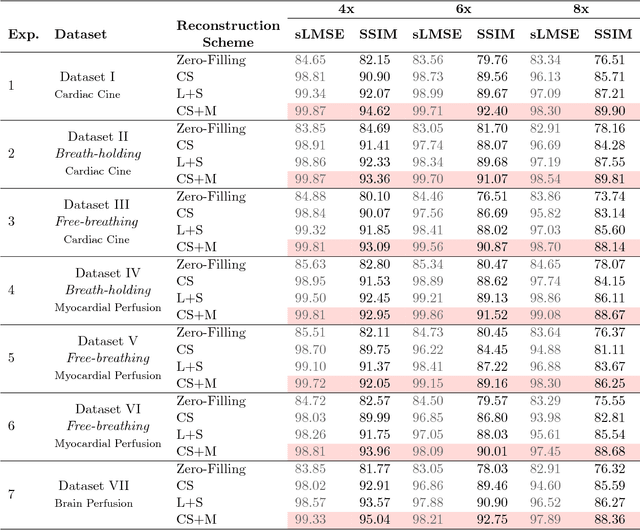

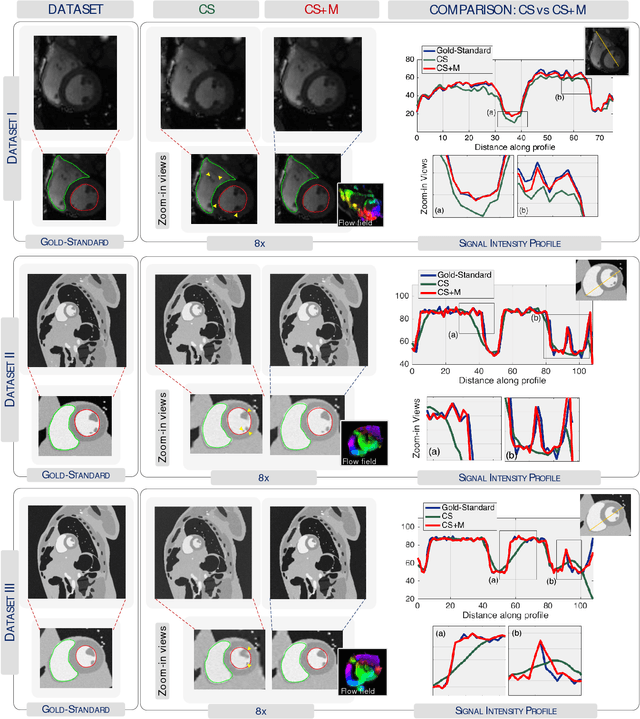
Purpose: To obtain high-quality reconstructions from highly undersampled dynamic MRI data with the goal of reducing the acquisition time and towards improving physicians' outcome in clinical practice in a range of clinical applications. Theory and Methods: In dynamic MRI scans, the interaction between the target structure and the physical motion affects the acquired measurements. We exploit the strong repercussion of motion in MRI by proposing a variational framework - called Compressed Sensing Plus Motion (CS+M) - that links in a single model, simultaneously and explicitly, the computation of the algorithmic MRI reconstruction and the physical motion. Most precisely, we recast the image reconstruction and motion estimation problems as a single optimisation problem that is solved, iteratively, by breaking it up into two more computationally tractable problems. The potentials and generalisation capabilities of our approach are demonstrated in different clinical applications including cardiac cine, cardiac perfusion and brain perfusion imaging. Results: The proposed scheme reduces blurring artefacts and preserves the target shape and fine details whilst observing the lowest reconstruction error under highly undersampling up to 12x. This results in lower residual aliasing artefacts than the compared reconstructions algorithms. Overall, the results coming from our scheme exhibit more stable behaviour and generate a reconstruction closer to the gold-standard. Conclusion: We show that incorporating physical motion to the CS computation yields a significant improvement of the MR image reconstruction, that in fact, is closer to the gold-standard. This translates to higher reconstruction quality whilst requiring less measurements.
Assessing the Influencing Factors on the Accuracy of Underage Facial Age Estimation
Dec 02, 2020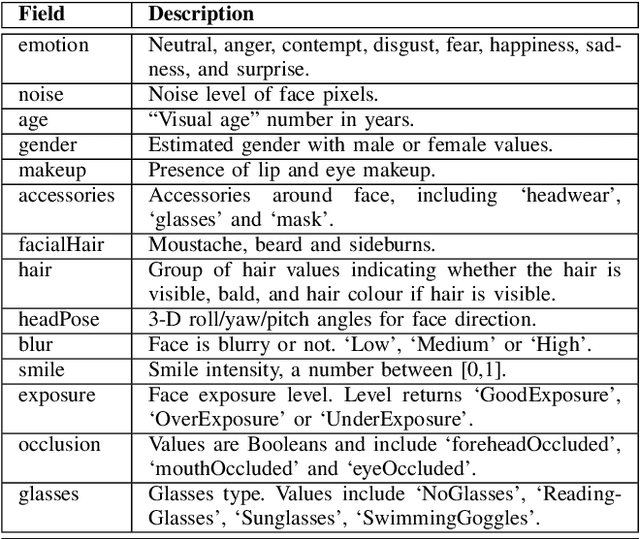
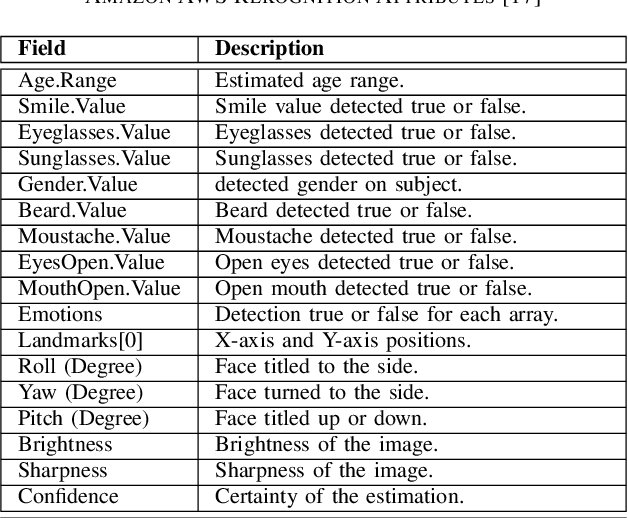
Swift response to the detection of endangered minors is an ongoing concern for law enforcement. Many child-focused investigations hinge on digital evidence discovery and analysis. Automated age estimation techniques are needed to aid in these investigations to expedite this evidence discovery process, and decrease investigator exposure to traumatic material. Automated techniques also show promise in decreasing the overflowing backlog of evidence obtained from increasing numbers of devices and online services. A lack of sufficient training data combined with natural human variance has been long hindering accurate automated age estimation -- especially for underage subjects. This paper presented a comprehensive evaluation of the performance of two cloud age estimation services (Amazon Web Service's Rekognition service and Microsoft Azure's Face API) against a dataset of over 21,800 underage subjects. The objective of this work is to evaluate the influence that certain human biometric factors, facial expressions, and image quality (i.e. blur, noise, exposure and resolution) have on the outcome of automated age estimation services. A thorough evaluation allows us to identify the most influential factors to be overcome in future age estimation systems.
Discernible Compressed Images via Deep Perception Consistency
Feb 17, 2020
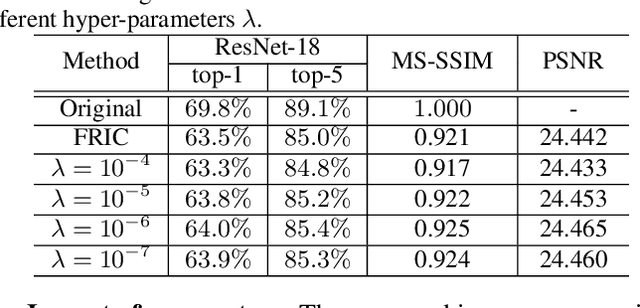
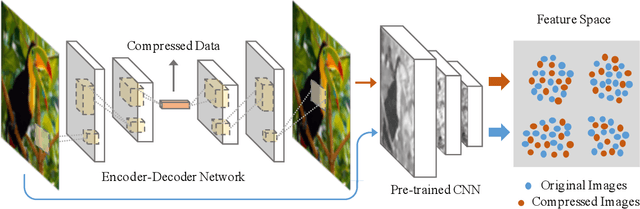
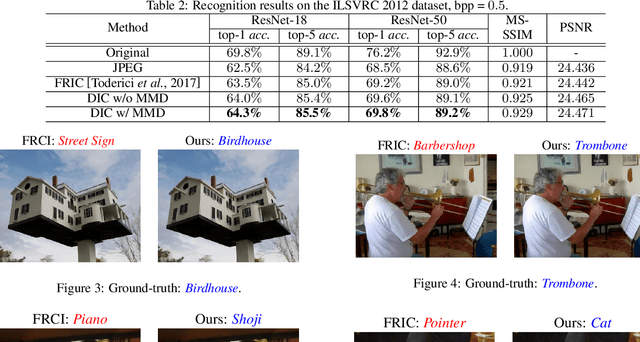
Image compression, as one of the fundamental low-level image processing tasks, is very essential for computer vision. Conventional image compression methods tend to obtain compressed images by minimizing their appearance discrepancy with the corresponding original images, but pay little attention to their efficacy in downstream perception tasks, e.g., image recognition and object detection. In contrast, this paper aims to produce compressed images by pursuing both appearance and perception consistency. Based on the encoder-decoder framework, we propose using a pre-trained CNN to extract features of original and compressed images. In addition, the maximum mean discrepancy (MMD) is employed to minimize the difference between feature distributions. The resulting compression network can generate images with high image quality and preserve the consistent perception in the feature domain, so that these images can be well recognized by pre-trained machine learning models. Experiments on benchmarks demonstrate the superiority of the proposed algorithm over comparison methods.