 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Weakly supervised cross-domain alignment with optimal transport
Aug 14, 2020
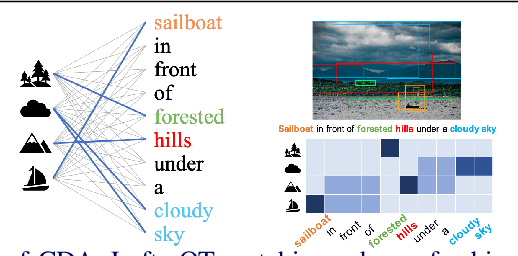
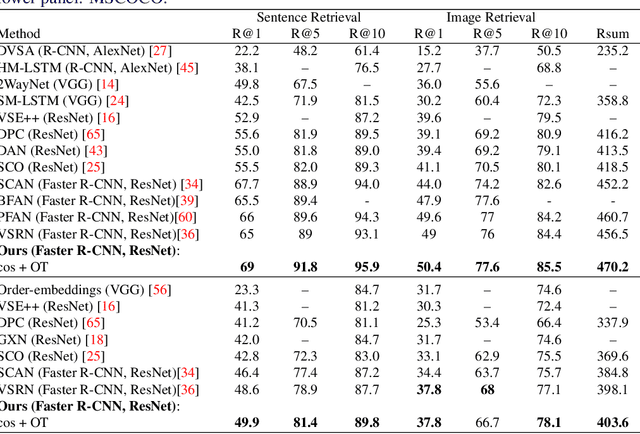
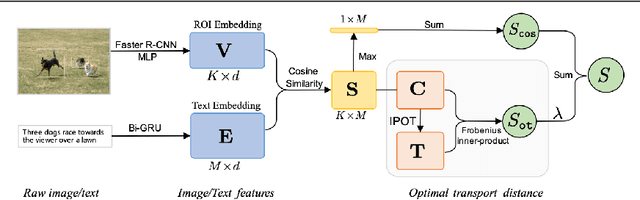
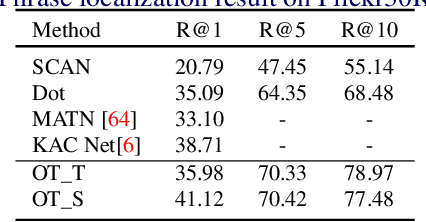
Cross-domain alignment between image objects and text sequences is key to many visual-language tasks, and it poses a fundamental challenge to both computer vision and natural language processing. This paper investigates a novel approach for the identification and optimization of fine-grained semantic similarities between image and text entities, under a weakly-supervised setup, improving performance over state-of-the-art solutions. Our method builds upon recent advances in optimal transport (OT) to resolve the cross-domain matching problem in a principled manner. Formulated as a drop-in regularizer, the proposed OT solution can be efficiently computed and used in combination with other existing approaches. We present empirical evidence to demonstrate the effectiveness of our approach, showing how it enables simpler model architectures to outperform or be comparable with more sophisticated designs on a range of vision-language tasks.
Mapping Low-Resolution Images To Multiple High-Resolution Images Using Non-Adversarial Mapping
Jun 21, 2020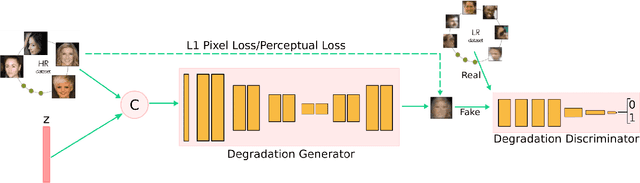
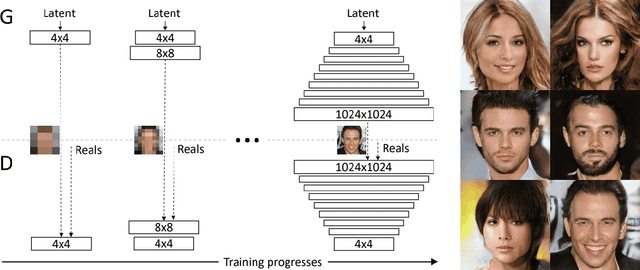
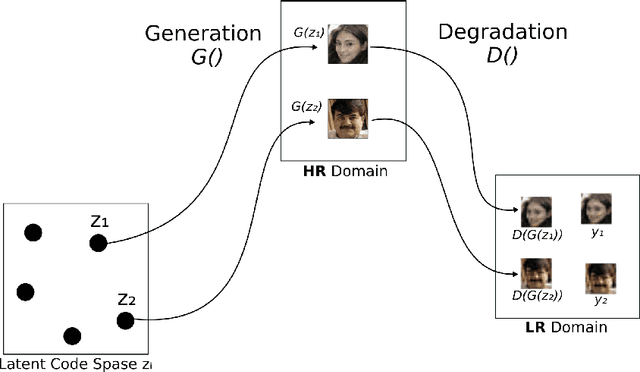

Several methods have recently been proposed for the Single Image Super-Resolution (SISR) problem. The current methods assume that a single low-resolution image can only yield a single high-resolution image. In addition, all of these methods use low-resolution images that were artificially generated through simple bilinear down-sampling. We argue that, first and foremost, the problem of SISR is an one-to-many mapping problem between the low resolution and all possible candidate high-resolution images and we address the challenging task of learning how to realistically degrade and down-sample high-resolution images. To circumvent this problem, we propose SR-NAM which utilizes the Non-Adversarial Mapping (NAM) technique. Furthermore, we propose a degradation model that learns how to transform high-resolution images to low-resolution images that resemble realistically taken low-resolution photos. Finally, some qualitative results for the proposed method along with the weaknesses of SR-NAM are included.
Suggestive Annotation: A Deep Active Learning Framework for Biomedical Image Segmentation
Jun 15, 2017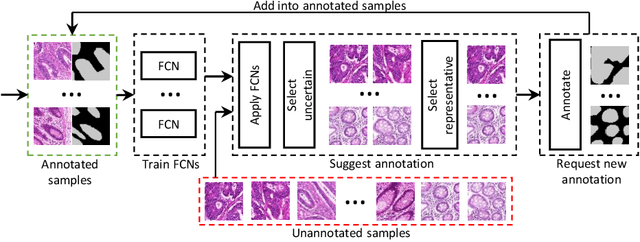
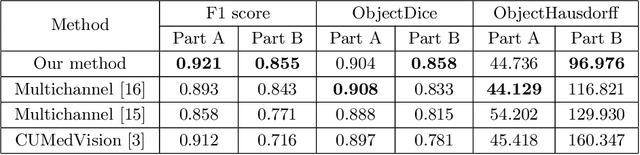
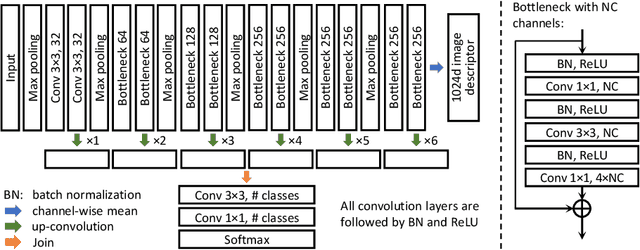

Image segmentation is a fundamental problem in biomedical image analysis. Recent advances in deep learning have achieved promising results on many biomedical image segmentation benchmarks. However, due to large variations in biomedical images (different modalities, image settings, objects, noise, etc), to utilize deep learning on a new application, it usually needs a new set of training data. This can incur a great deal of annotation effort and cost, because only biomedical experts can annotate effectively, and often there are too many instances in images (e.g., cells) to annotate. In this paper, we aim to address the following question: With limited effort (e.g., time) for annotation, what instances should be annotated in order to attain the best performance? We present a deep active learning framework that combines fully convolutional network (FCN) and active learning to significantly reduce annotation effort by making judicious suggestions on the most effective annotation areas. We utilize uncertainty and similarity information provided by FCN and formulate a generalized version of the maximum set cover problem to determine the most representative and uncertain areas for annotation. Extensive experiments using the 2015 MICCAI Gland Challenge dataset and a lymph node ultrasound image segmentation dataset show that, using annotation suggestions by our method, state-of-the-art segmentation performance can be achieved by using only 50% of training data.
A matrix-free Levenberg-Marquardt algorithm for efficient ptychographic phase retrieval
Feb 27, 2021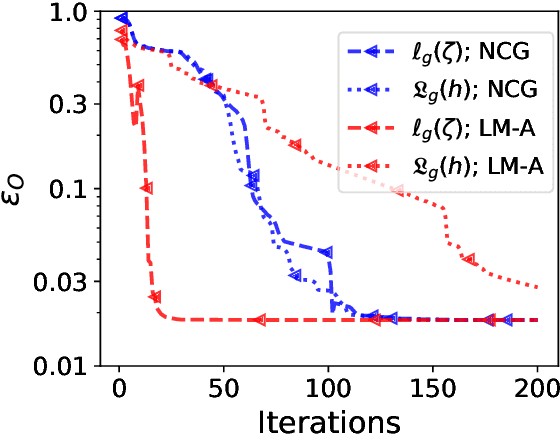
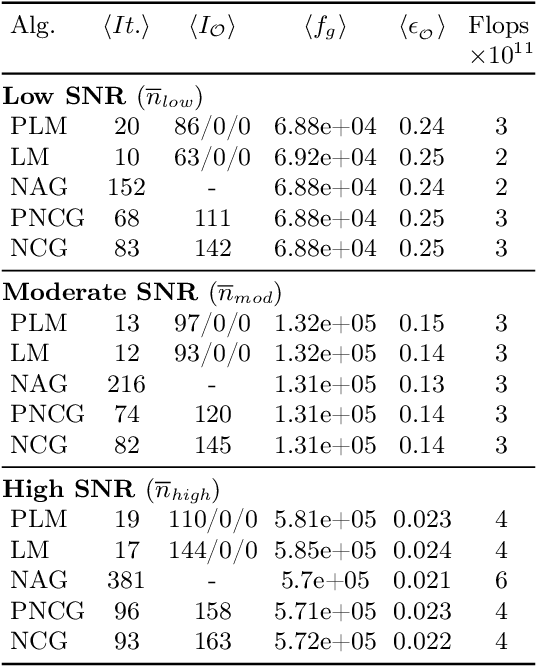

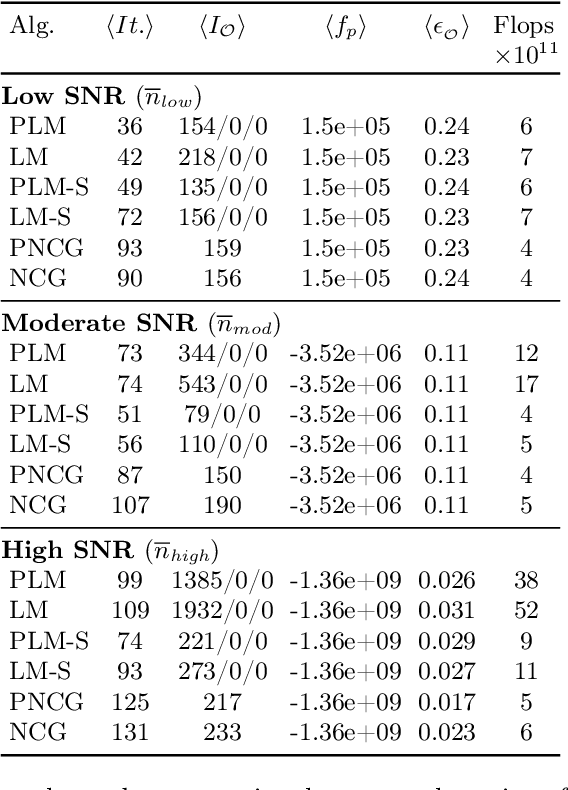
The phase retrieval problem, where one aims to recover a complex-valued image from far-field intensity measurements, is a classic problem encountered in a range of imaging applications. Modern phase retrieval approaches usually rely on gradient descent methods in a nonlinear minimization framework. Calculating closed-form gradients for use in these methods is tedious work, and formulating second order derivatives is even more laborious. Additionally, second order techniques often require the storage and inversion of large matrices of partial derivatives, with memory requirements that can be prohibitive for data-rich imaging modalities. We use a reverse-mode automatic differentiation (AD) framework to implement an efficient matrix-free version of the Levenberg-Marquardt (LM) algorithm, a longstanding method that finds popular use in nonlinear least-square minimization problems but which has seen little use in phase retrieval. Furthermore, we extend the basic LM algorithm so that it can be applied for general constrained optimization problems beyond just the least-square applications. Since we use AD, we only need to specify the physics-based forward model for a specific imaging application; the derivative terms are calculated automatically through matrix-vector products, without explicitly forming any large Jacobian or Gauss-Newton matrices. We demonstrate that this algorithm can be used to solve both the unconstrained ptychographic object retrieval problem and the constrained "blind" ptychographic object and probe retrieval problems, under both the Gaussian and Poisson noise models, and that this method outperforms best-in-class first-order ptychographic reconstruction methods: it provides excellent convergence guarantees with (in many cases) a superlinear rate of convergence, all with a computational cost comparable to, or lower than, the tested first-order algorithms.
Analyzing and Improving Generative Adversarial Training for Generative Modeling and Out-of-Distribution Detection
Dec 11, 2020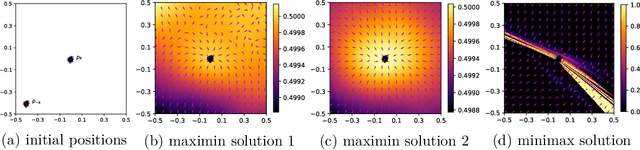
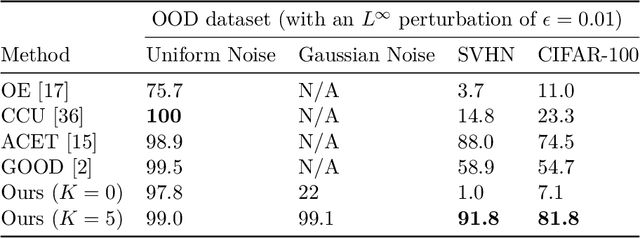


Generative adversarial training (GAT) is a recently introduced adversarial defense method. Previous works have focused on empirical evaluations of its application to training robust predictive models. In this paper we focus on theoretical understanding of the GAT method and extending its application to generative modeling and out-of-distribution detection. We analyze the optimal solutions of the maximin formulation employed by the GAT objective, and make a comparative analysis of the minimax formulation employed by GANs. We use theoretical analysis and 2D simulations to understand the convergence property of the training algorithm. Based on these results, we develop an incremental generative training algorithm, and conduct comprehensive evaluations of the algorithm's application to image generation and adversarial out-of-distribution detection. Our results suggest that generative adversarial training is a promising new direction for the above applications.
Deinterlacing Network for Early Interlaced Videos
Nov 27, 2020

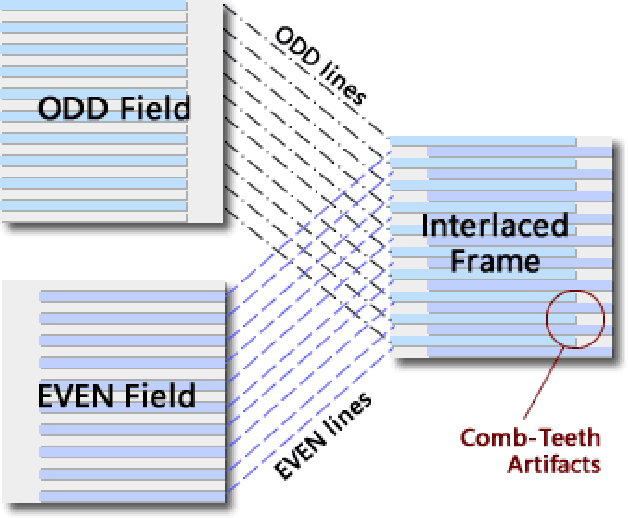
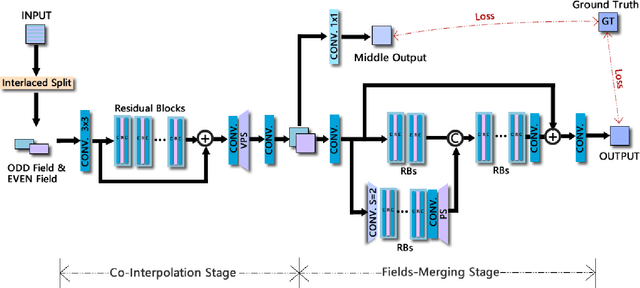
With the rapid development of image restoration techniques, high-definition reconstruction of early videos has achieved impressive results. However, there are few studies about the interlacing artifacts that often appear in early videos and significantly affect visual perception. Traditional deinterlacing approaches are mainly focused on early interlacing scanning systems and thus cannot handle the complex and complicated artifacts in real-world early interlaced videos. Hence, this paper proposes a specific deinterlacing network (DIN), which is motivated by the traditional deinterlacing strategy. The proposed DIN consists of two stages, i.e., a cooperative vertical interpolation stage for split fields, and a merging stage that is applied to perceive movements and remove ghost artifacts. Experimental results demonstrate that the proposed method can effectively remove complex artifacts in early interlaced videos.
Filtered Manifold Alignment
Nov 11, 2020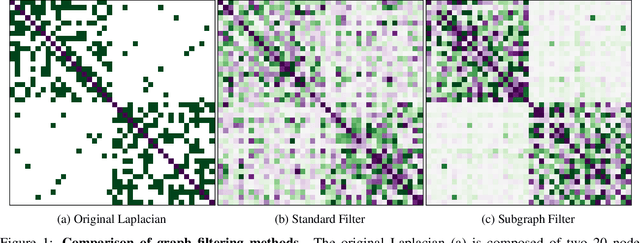
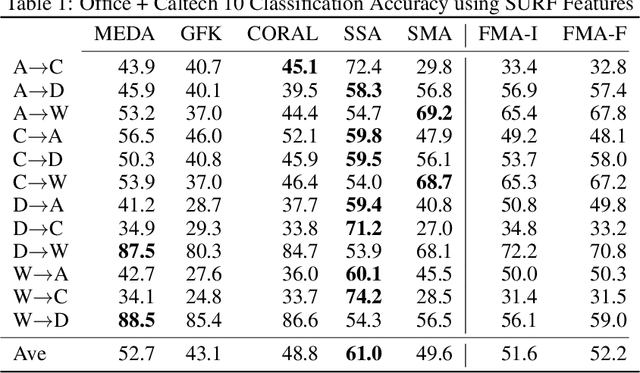
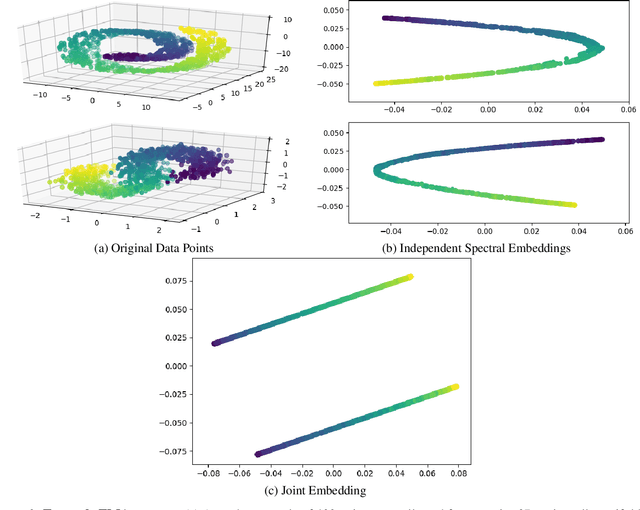
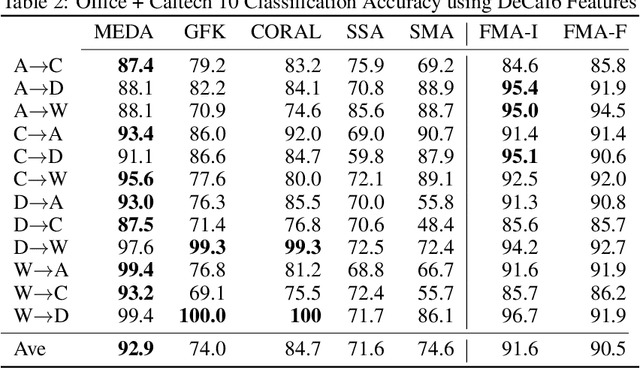
Domain adaptation is an essential task in transfer learning to leverage data in one domain to bolster learning in another domain. In this paper, we present a new semi-supervised manifold alignment technique based on a two-step approach of projecting and filtering the source and target domains to low dimensional spaces followed by joining the two spaces. Our proposed approach, filtered manifold alignment (FMA), reduces the computational complexity of previous manifold alignment techniques, is flexible enough to align domains with completely disparate sets of feature and demonstrates state-of-the-art classification accuracy on multiple benchmark domain adaptation tasks composed of classifying real world image datasets.
RandomForestMLP: An Ensemble-Based Multi-Layer Perceptron Against Curse of Dimensionality
Nov 02, 2020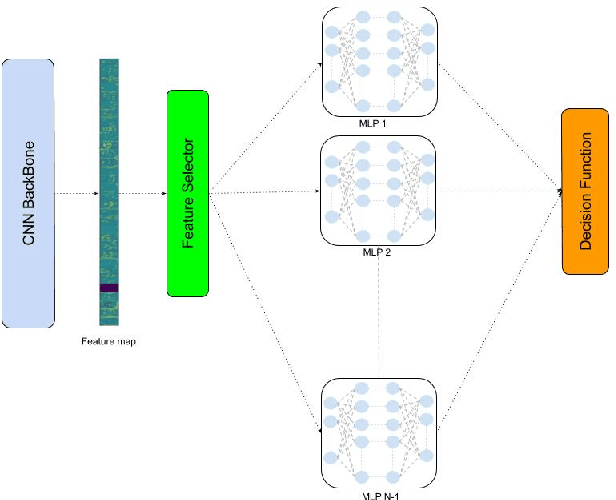
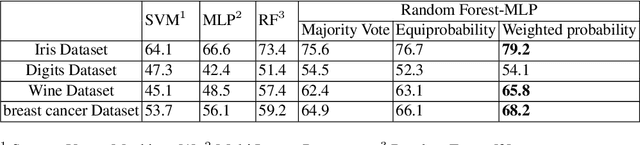
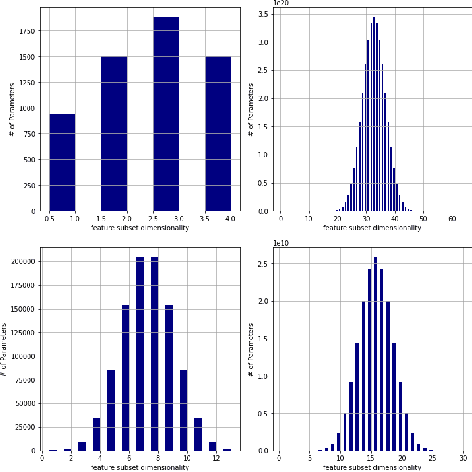
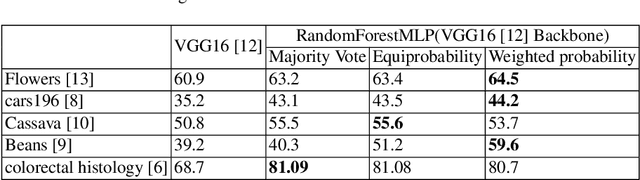
We present a novel and practical deep learning pipeline termed RandomForestMLP. This core trainable classification engine consists of a convolutional neural network backbone followed by an ensemble-based multi-layer perceptrons core for the classification task. It is designed in the context of self and semi-supervised learning tasks to avoid overfitting while training on very small datasets. The paper details the architecture of the RandomForestMLP and present different strategies for neural network decision aggregation. Then, it assesses its robustness to overfitting when trained on realistic image datasets and compares its classification performance with existing regular classifiers.
Improving Layer-wise Adaptive Rate Methods using Trust Ratio Clipping
Nov 27, 2020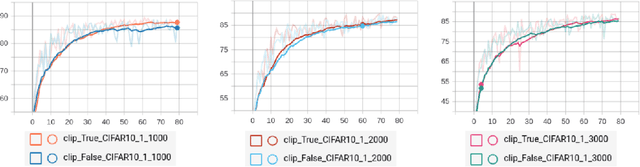

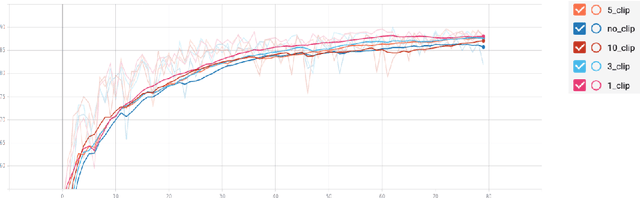
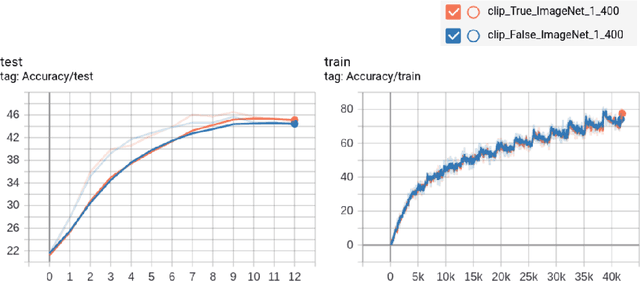
Training neural networks with large batch is of fundamental significance to deep learning. Large batch training remarkably reduces the amount of training time but has difficulties in maintaining accuracy. Recent works have put forward optimization methods such as LARS and LAMB to tackle this issue through adaptive layer-wise optimization using trust ratios. Though prevailing, such methods are observed to still suffer from unstable and extreme trust ratios which degrades performance. In this paper, we propose a new variant of LAMB, called LAMBC, which employs trust ratio clipping to stabilize its magnitude and prevent extreme values. We conducted experiments on image classification tasks such as ImageNet and CIFAR-10 and our empirical results demonstrate promising improvements across different batch sizes.
TEC: Tensor Ensemble Classifier for Big Data
Feb 26, 2021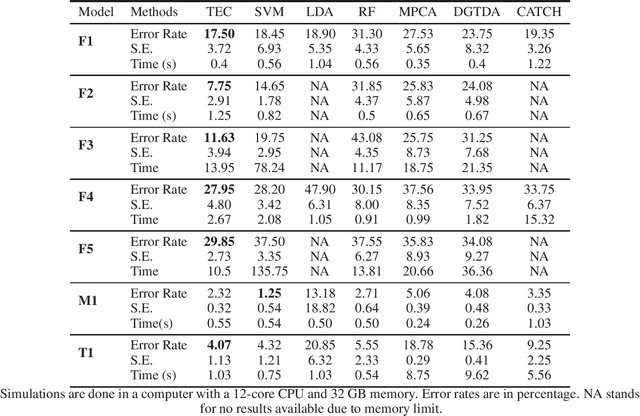
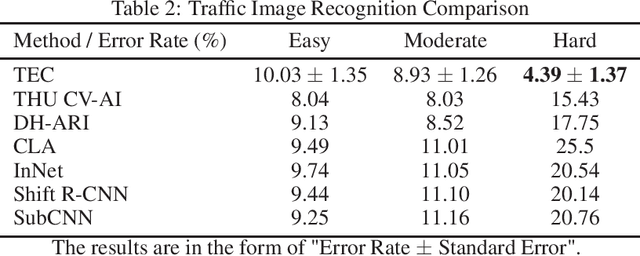
Tensor (multidimensional array) classification problem has become very popular in modern applications such as image recognition and high dimensional spatio-temporal data analysis. Support Tensor Machine (STM) classifier, which is extended from the support vector machine, takes CANDECOMP / Parafac (CP) form of tensor data as input and predicts the data labels. The distribution-free and statistically consistent properties of STM highlight its potential in successfully handling wide varieties of data applications. Training a STM can be computationally expensive with high-dimensional tensors. However, reducing the size of tensor with a random projection technique can reduce the computational time and cost, making it feasible to handle large size tensors on regular machines. We name an STM estimated with randomly projected tensor as Random Projection-based Support Tensor Machine (RPSTM). In this work, we propose a Tensor Ensemble Classifier (TEC), which aggregates multiple RPSTMs for big tensor classification. TEC utilizes the ensemble idea to minimize the excessive classification risk brought by random projection, providing statistically consistent predictions while taking the computational advantage of RPSTM. Since each RPSTM can be estimated independently, TEC can further take advantage of parallel computing techniques and be more computationally efficient. The theoretical and numerical results demonstrate the decent performance of TEC model in high-dimensional tensor classification problems. The model prediction is statistically consistent as its risk is shown to converge to the optimal Bayes risk. Besides, we highlight the trade-off between the computational cost and the prediction risk for TEC model. The method is validated by extensive simulation and a real data example. We prepare a python package for applying TEC, which is available at our GitHub.