 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generative Collaborative Networks for Single Image Super-Resolution
Mar 12, 2019

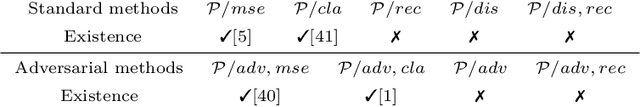
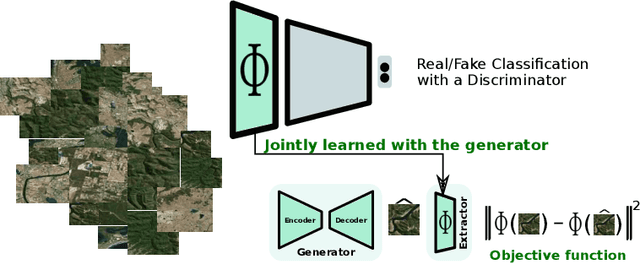
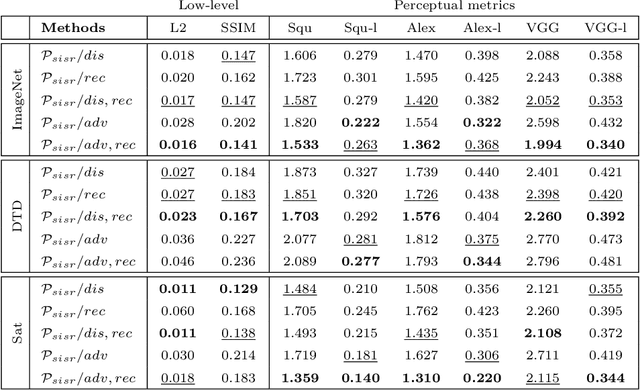
A common issue of deep neural networks-based methods for the problem of Single Image Super-Resolution (SISR), is the recovery of finer texture details when super-resolving at large upscaling factors. This issue is particularly related to the choice of the objective loss function. In particular, recent works proposed the use of a VGG loss which consists in minimizing the error between the generated high resolution images and ground-truth in the feature space of a Convolutional Neural Network (VGG19), pre-trained on the very "large" ImageNet dataset. When considering the problem of super-resolving images with a distribution "far" from the ImageNet images distribution (\textit{e.g.,} satellite images), their proposed \textit{fixed} VGG loss is no longer relevant. In this paper, we present a general framework named \textit{Generative Collaborative Networks} (GCN), where the idea consists in optimizing the \textit{generator} (the mapping of interest) in the feature space of a \textit{features extractor} network. The two networks (generator and extractor) are \textit{collaborative} in the sense that the latter "helps" the former, by constructing discriminative and relevant features (not necessarily \textit{fixed} and possibly learned \textit{mutually} with the generator). We evaluate the GCN framework in the context of SISR, and we show that it results in a method that is adapted to super-resolution domains that are "far" from the ImageNet domain.
Data Augmentation Based Malware Detection using Convolutional Neural Networks
Oct 05, 2020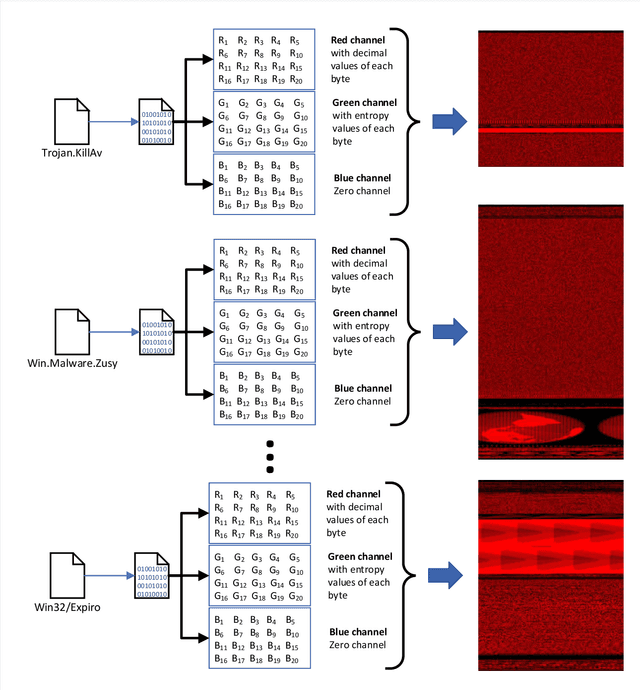

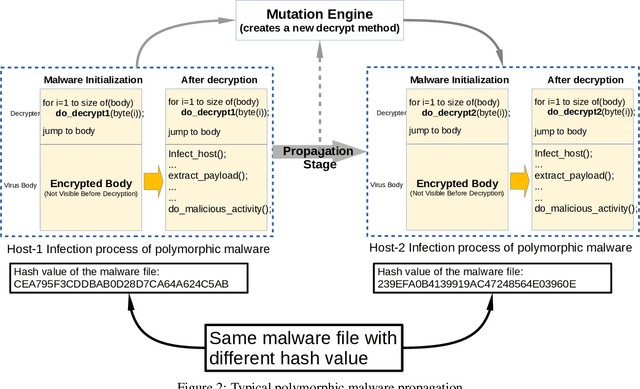

Recently, cyber-attacks have been extensively seen due to the everlasting increase of malware in the cyber world. These attacks cause irreversible damage not only to end-users but also to corporate computer systems. Ransomware attacks such as WannaCry and Petya specifically targets to make critical infrastructures such as airports and rendered operational processes inoperable. Hence, it has attracted increasing attention in terms of volume, versatility, and intricacy. The most important feature of this type of malware is that they change shape as they propagate from one computer to another. Since standard signature-based detection software fails to identify this type of malware because they have different characteristics on each contaminated computer. This paper aims at providing an image augmentation enhanced deep convolutional neural network (CNN) models for the detection of malware families in a metamorphic malware environment. The main contributions of the paper's model structure consist of three components, including image generation from malware samples, image augmentation, and the last one is classifying the malware families by using a convolutional neural network model. In the first component, the collected malware samples are converted binary representation to 3-channel images using windowing technique. The second component of the system create the augmented version of the images, and the last component builds a classification model. In this study, five different deep convolutional neural network model for malware family detection is used.
Adversarial Privacy-preserving Filter
Aug 04, 2020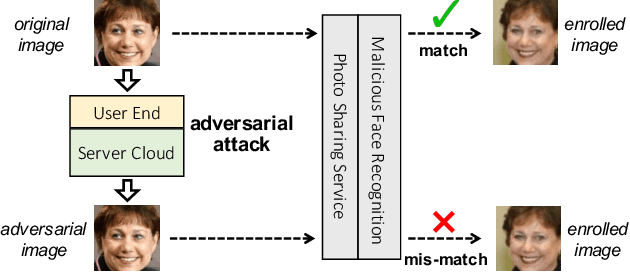
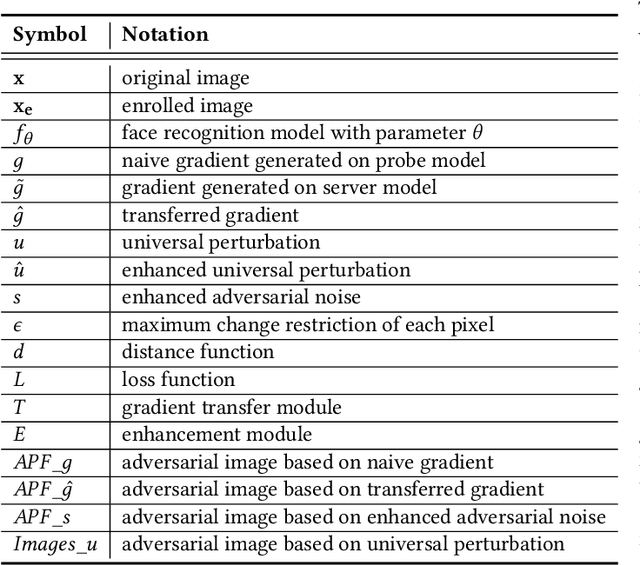
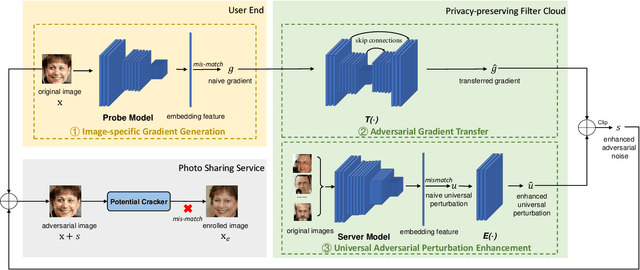
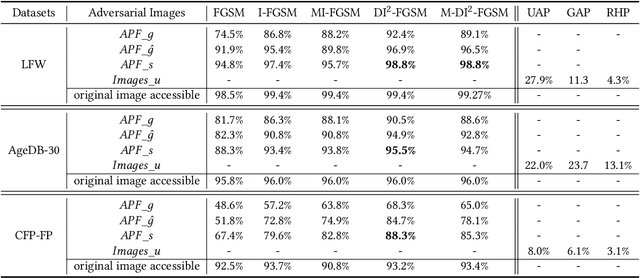
While widely adopted in practical applications, face recognition has been critically discussed regarding the malicious use of face images and the potential privacy problems, e.g., deceiving payment system and causing personal sabotage. Online photo sharing services unintentionally act as the main repository for malicious crawler and face recognition applications. This work aims to develop a privacy-preserving solution, called Adversarial Privacy-preserving Filter (APF), to protect the online shared face images from being maliciously used.We propose an end-cloud collaborated adversarial attack solution to satisfy requirements of privacy, utility and nonaccessibility. Specifically, the solutions consist of three modules: (1) image-specific gradient generation, to extract image-specific gradient in the user end with a compressed probe model; (2) adversarial gradient transfer, to fine-tune the image-specific gradient in the server cloud; and (3) universal adversarial perturbation enhancement, to append image-independent perturbation to derive the final adversarial noise. Extensive experiments on three datasets validate the effectiveness and efficiency of the proposed solution. A prototype application is also released for further evaluation.We hope the end-cloud collaborated attack framework could shed light on addressing the issue of online multimedia sharing privacy-preserving issues from user side.
Volumetric Propagation Network: Stereo-LiDAR Fusion for Long-Range Depth Estimation
Mar 24, 2021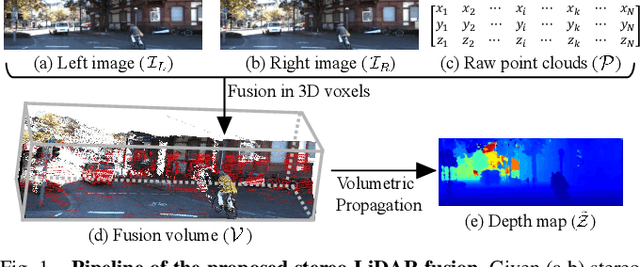
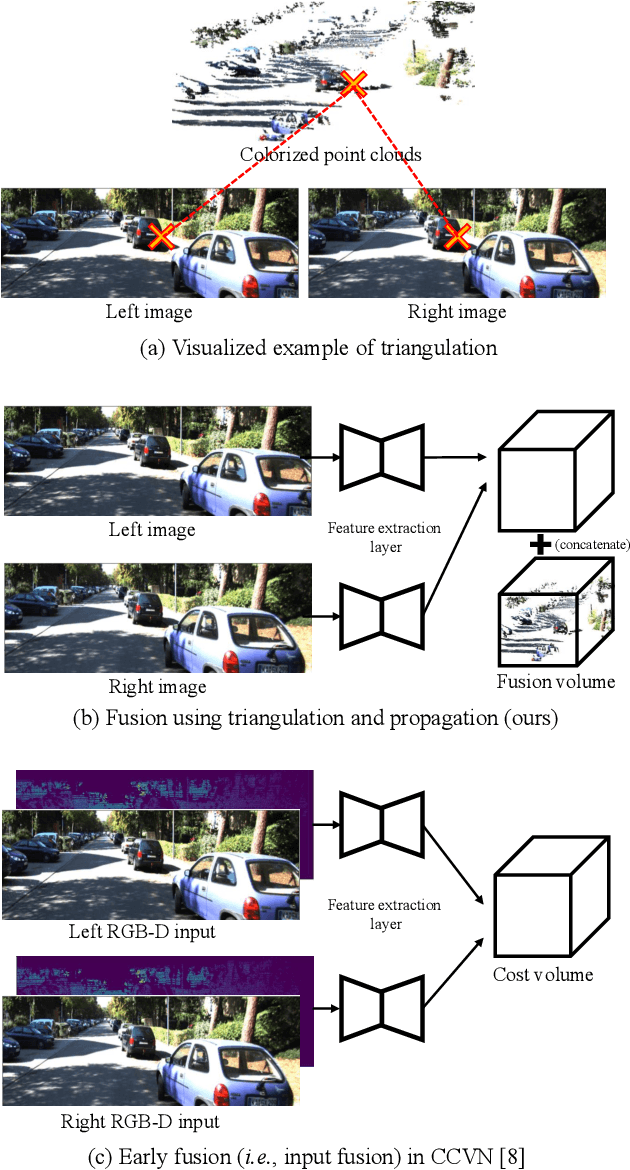
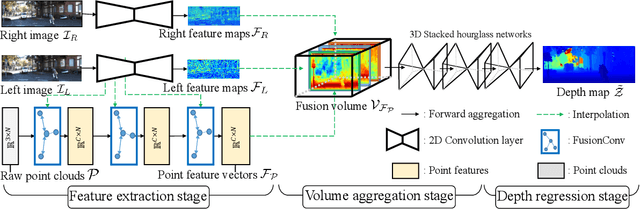
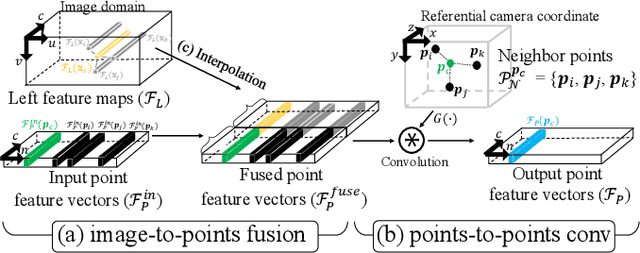
Stereo-LiDAR fusion is a promising task in that we can utilize two different types of 3D perceptions for practical usage -- dense 3D information (stereo cameras) and highly-accurate sparse point clouds (LiDAR). However, due to their different modalities and structures, the method of aligning sensor data is the key for successful sensor fusion. To this end, we propose a geometry-aware stereo-LiDAR fusion network for long-range depth estimation, called volumetric propagation network. The key idea of our network is to exploit sparse and accurate point clouds as a cue for guiding correspondences of stereo images in a unified 3D volume space. Unlike existing fusion strategies, we directly embed point clouds into the volume, which enables us to propagate valid information into nearby voxels in the volume, and to reduce the uncertainty of correspondences. Thus, it allows us to fuse two different input modalities seamlessly and regress a long-range depth map. Our fusion is further enhanced by a newly proposed feature extraction layer for point clouds guided by images: FusionConv. FusionConv extracts point cloud features that consider both semantic (2D image domain) and geometric (3D domain) relations and aid fusion at the volume. Our network achieves state-of-the-art performance on the KITTI and the Virtual-KITTI datasets among recent stereo-LiDAR fusion methods.
Pathological Evidence Exploration in Deep Retinal Image Diagnosis
Dec 06, 2018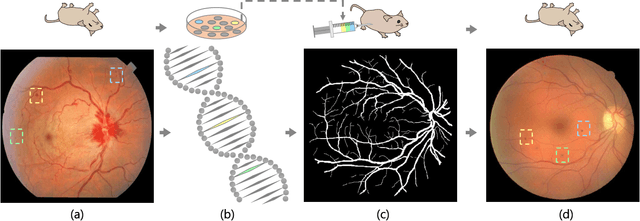

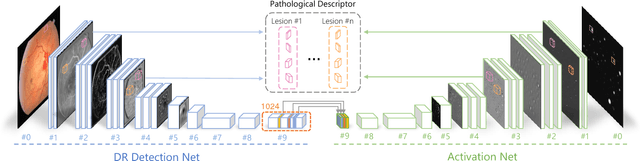

Though deep learning has shown successful performance in classifying the label and severity stage of certain disease, most of them give few evidence on how to make prediction. Here, we propose to exploit the interpretability of deep learning application in medical diagnosis. Inspired by Koch's Postulates, a well-known strategy in medical research to identify the property of pathogen, we define a pathological descriptor that can be extracted from the activated neurons of a diabetic retinopathy detector. To visualize the symptom and feature encoded in this descriptor, we propose a GAN based method to synthesize pathological retinal image given the descriptor and a binary vessel segmentation. Besides, with this descriptor, we can arbitrarily manipulate the position and quantity of lesions. As verified by a panel of 5 licensed ophthalmologists, our synthesized images carry the symptoms that are directly related to diabetic retinopathy diagnosis. The panel survey also shows that our generated images is both qualitatively and quantitatively superior to existing methods.
Mitigating belief projection in explainable artificial intelligence via Bayesian Teaching
Feb 07, 2021

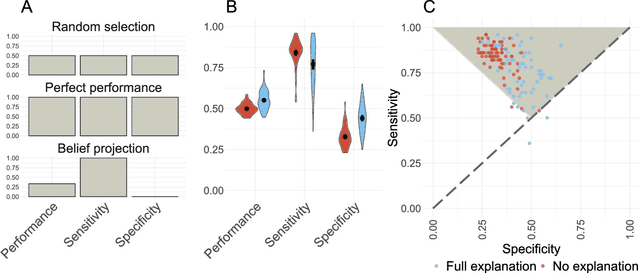
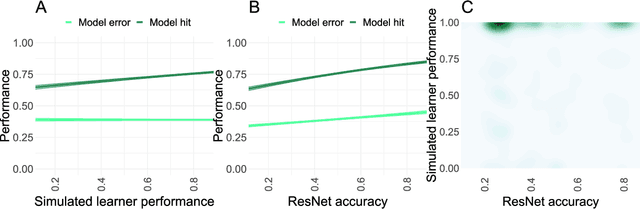
State-of-the-art deep-learning systems use decision rules that are challenging for humans to model. Explainable AI (XAI) attempts to improve human understanding but rarely accounts for how people typically reason about unfamiliar agents. We propose explicitly modeling the human explainee via Bayesian Teaching, which evaluates explanations by how much they shift explainees' inferences toward a desired goal. We assess Bayesian Teaching in a binary image classification task across a variety of contexts. Absent intervention, participants predict that the AI's classifications will match their own, but explanations generated by Bayesian Teaching improve their ability to predict the AI's judgements by moving them away from this prior belief. Bayesian Teaching further allows each case to be broken down into sub-examples (here saliency maps). These sub-examples complement whole examples by improving error detection for familiar categories, whereas whole examples help predict correct AI judgements of unfamiliar cases.
Saliency-based Sequential Image Attention with Multiset Prediction
Nov 14, 2017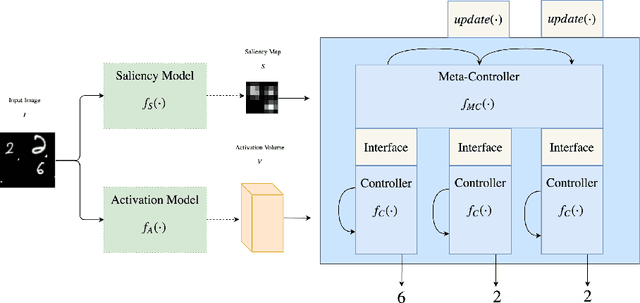
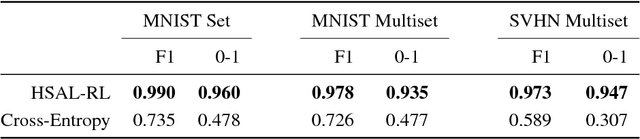


Humans process visual scenes selectively and sequentially using attention. Central to models of human visual attention is the saliency map. We propose a hierarchical visual architecture that operates on a saliency map and uses a novel attention mechanism to sequentially focus on salient regions and take additional glimpses within those regions. The architecture is motivated by human visual attention, and is used for multi-label image classification on a novel multiset task, demonstrating that it achieves high precision and recall while localizing objects with its attention. Unlike conventional multi-label image classification models, the model supports multiset prediction due to a reinforcement-learning based training process that allows for arbitrary label permutation and multiple instances per label.
An Objective Evaluation Metric for image fusion based on Del Operator
May 19, 2019
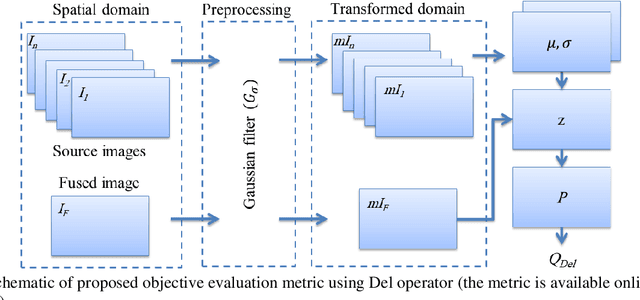
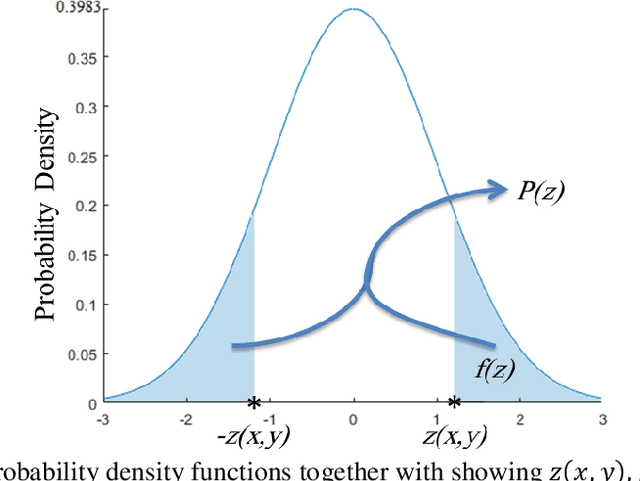
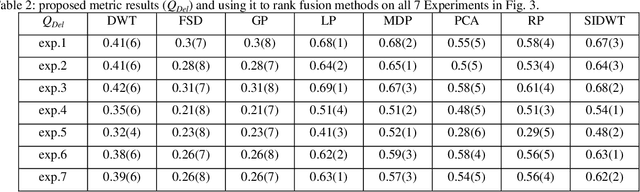
In this paper, a novel objective evaluation metric for image fusion is presented. Remarkable and attractive points of the proposed metric are that it has no parameter, the result is probability in the range of [0, 1] and it is free from illumination dependence. This metric is easy to implement and the result is computed in four steps: (1) Smoothing the images using Gaussian filter. (2) Transforming images to a vector field using Del operator. (3) Computing the normal distribution function ({\mu},{\sigma}) for each corresponding pixel, and converting to the standard normal distribution function. (4) Computing the probability of being well-behaved fusion method as the result. To judge the quality of the proposed metric, it is compared to thirteen well-known non-reference objective evaluation metrics, where eight fusion methods are employed on seven experiments of multimodal medical images. The experimental results and statistical comparisons show that in contrast to the previously objective evaluation metrics the proposed one performs better in terms of both agreeing with human visual perception and evaluating fusion methods that are not performed at the same level.
Robust statistics and no-reference image quality assessment in Curvelet domain
Feb 11, 2019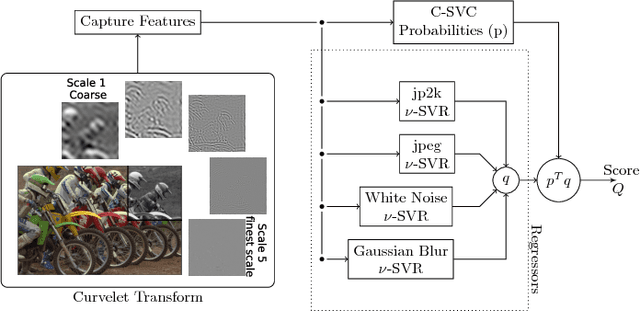
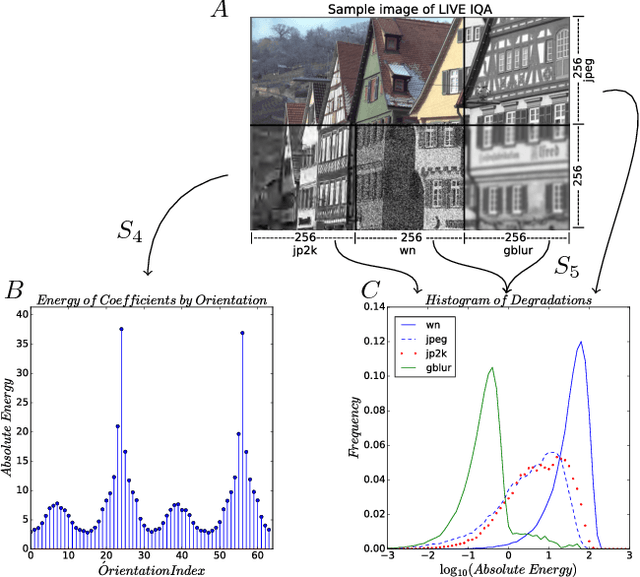
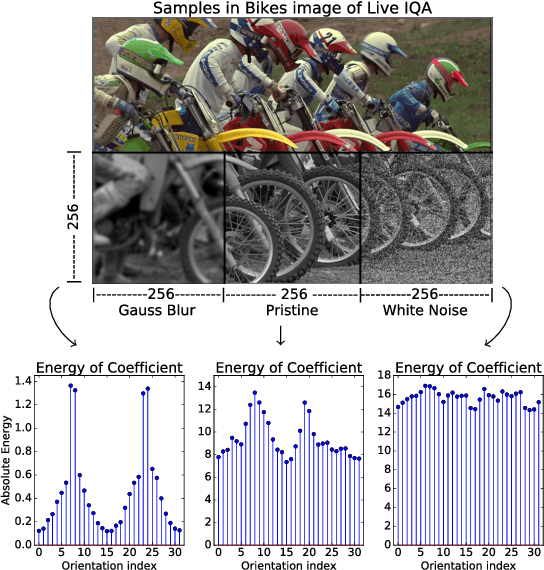
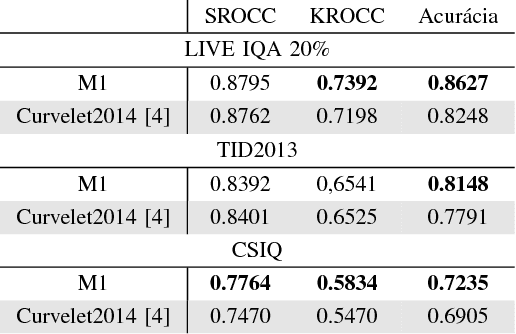
This paper uses robust statistics and curvelet transform to learn a general-purpose no-reference (NR) image quality assessment (IQA) model. The new approach, here called M1, competes with the Curvelet Quality Assessment proposed in 2014 (Curvelet2014). The central idea is to use descriptors based on robust statistics to extract features and predict the human opinion about degraded images. To show the consistency of the method the model is tested with 3 different datasets, LIVE IQA, TID2013 and CSIQ. To test evaluation, it is used the Wilcoxon test to verify the statistical significance of results and promote an accurate comparison between new model M1 and Curvelet2014. The results show a gain when robust statistics are used as descriptor.
Quantifying error contributions of computational steps, algorithms and hyperparameter choices in image classification pipelines
Feb 25, 2019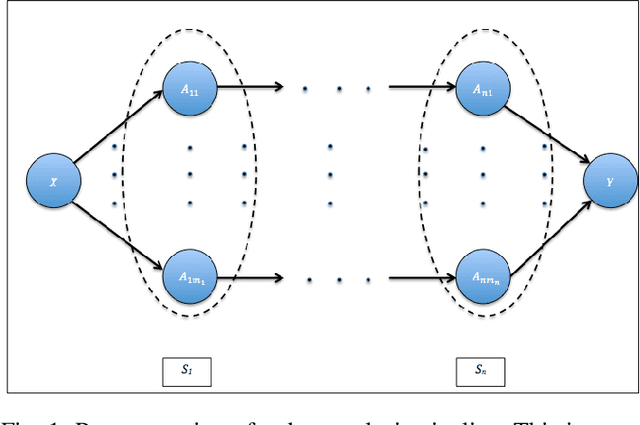
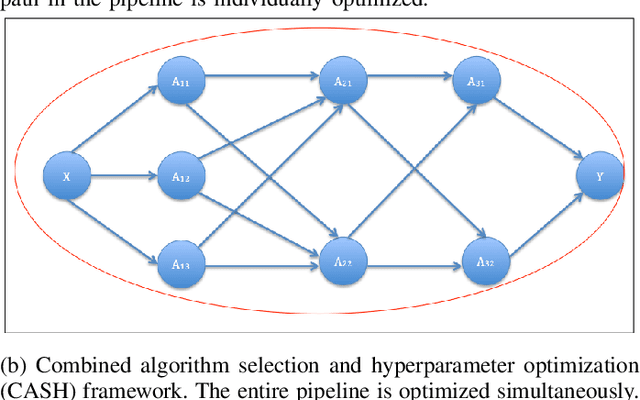
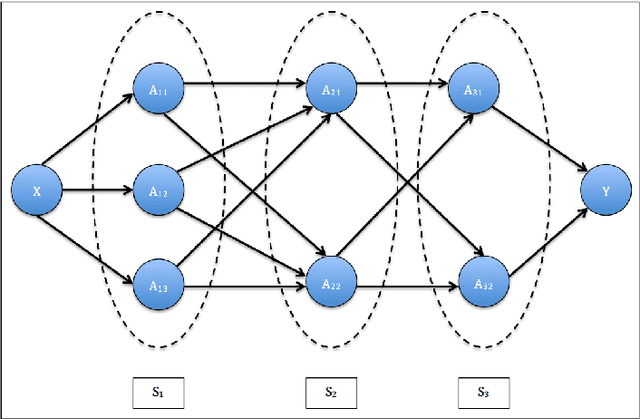
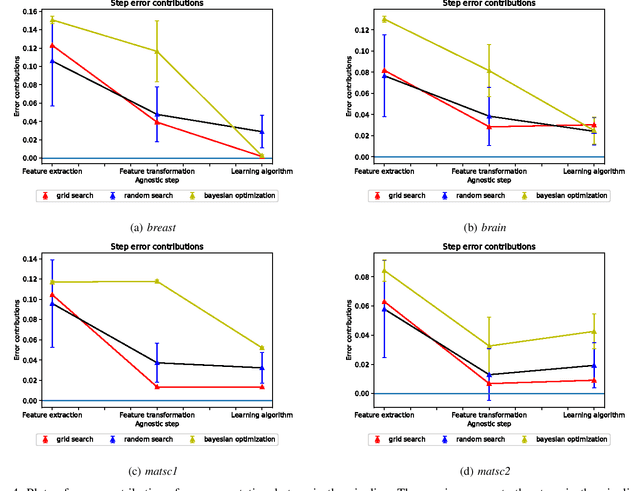
Data science relies on pipelines that are organized in the form of interdependent computational steps. Each step consists of various candidate algorithms that maybe used for performing a particular function. Each algorithm consists of several hyperparameters. Algorithms and hyperparameters must be optimized as a whole to produce the best performance. Typical machine learning pipelines typically consist of complex algorithms in each of the steps. Not only is the selection process combinatorial, but it is also important to interpret and understand the pipelines. We propose a method to quantify the importance of different layers in the pipeline, by computing an error contribution relative to an agnostic choice of algorithms in that layer. We demonstrate our methodology on image classification pipelines. The agnostic methodology quantifies the error contributions from the computational steps, algorithms and hyperparameters in the image classification pipeline. We show that algorithm selection and hyper-parameter optimization methods can be used to quantify the error contribution and that random search is able to quantify the contribution more accurately than Bayesian optimization. This methodology can be used by domain experts to understand machine learning and data analysis pipelines in terms of their individual components, which can help in prioritizing different components of the pipeline.