 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CEL-Net: Continuous Exposure for Extreme Low-Light Imaging
Dec 07, 2020




Deep learning methods for enhancing dark images learn a mapping from input images to output images with pre-determined discrete exposure levels. Often, at inference time the input and optimal output exposure levels of the given image are different from the seen ones during training. As a result the enhanced image might suffer from visual distortions, such as low contrast or dark areas. We address this issue by introducing a deep learning model that can continuously generalize at inference time to unseen exposure levels without the need to retrain the model. To this end, we introduce a dataset of 1500 raw images captured in both outdoor and indoor scenes, with five different exposure levels and various camera parameters. Using the dataset, we develop a model for extreme low-light imaging that can continuously tune the input or output exposure level of the image to an unseen one. We investigate the properties of our model and validate its performance, showing promising results.
TDAsweep: A Novel Dimensionality Reduction Method for Image Classification Tasks
Nov 14, 2020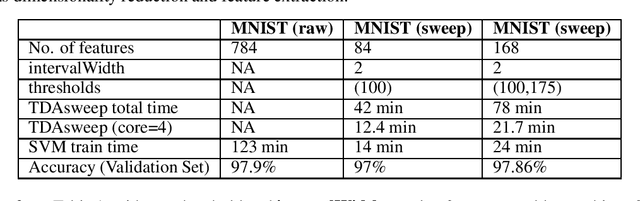
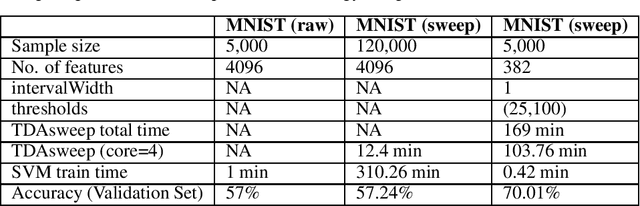
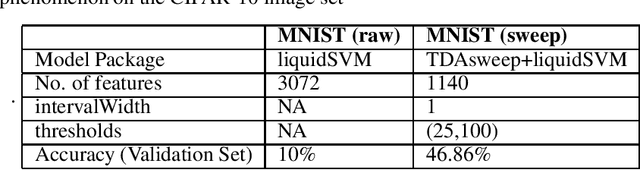

One of the most celebrated achievements of modern machine learning technology is automatic classification of images. However, success is typically achieved only with major computational costs. Here we introduce TDAsweep, a machine learning tool aimed at improving the efficiency of automatic classification of images.
Learning to Sort Image Sequences via Accumulated Temporal Differences
Oct 22, 2020
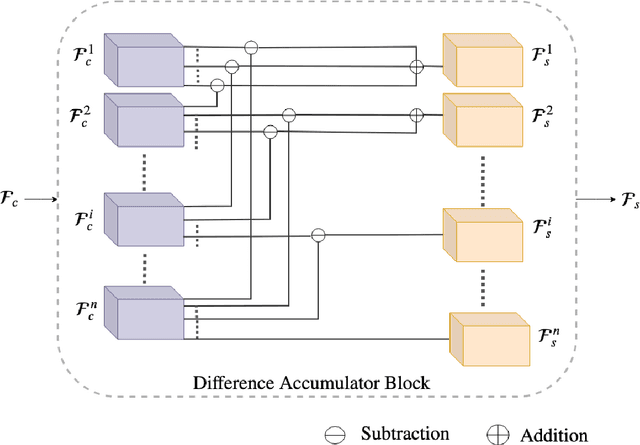

Consider a set of n images of a scene with dynamic objects captured with a static or a handheld camera. Let the temporal order in which these images are captured be unknown. There can be n! possibilities for the temporal order in which these images could have been captured. In this work, we tackle the problem of temporally sequencing the unordered set of images of a dynamic scene captured with a hand-held camera. We propose a convolutional block which captures the spatial information through 2D convolution kernel and captures the temporal information by utilizing the differences present among the feature maps extracted from the input images. We evaluate the performance of the proposed approach on the dataset extracted from a standard action recognition dataset, UCF101. We show that the proposed approach outperforms the state-of-the-art methods by a significant margin. We show that the network generalizes well by evaluating it on a dataset extracted from the DAVIS dataset, a dataset meant for video object segmentation, when the same network was trained with a dataset extracted from UCF101, a dataset meant for action recognition.
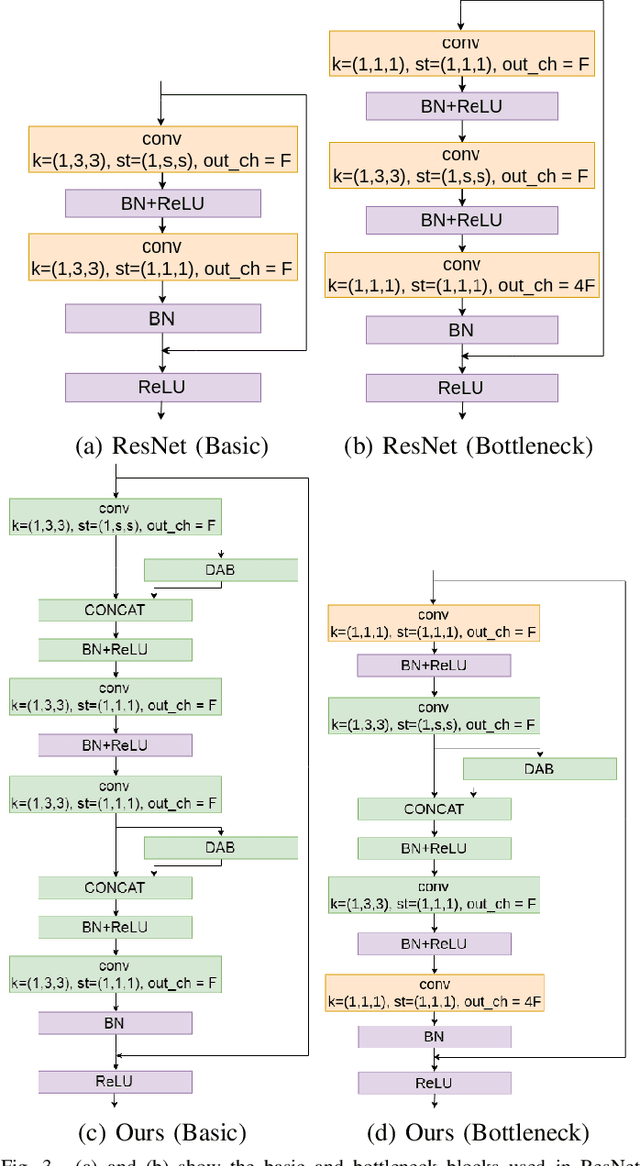
SVMA: A GAN-based model for Monocular 3D Human Pose Estimation
Jun 10, 2021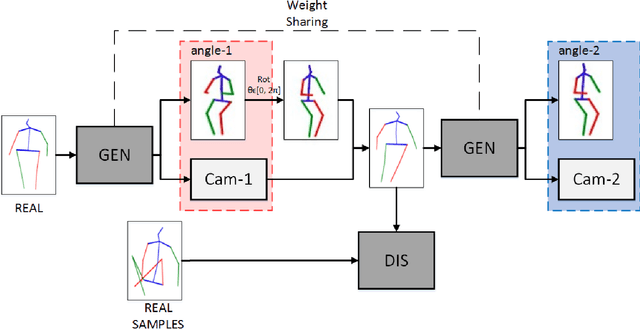
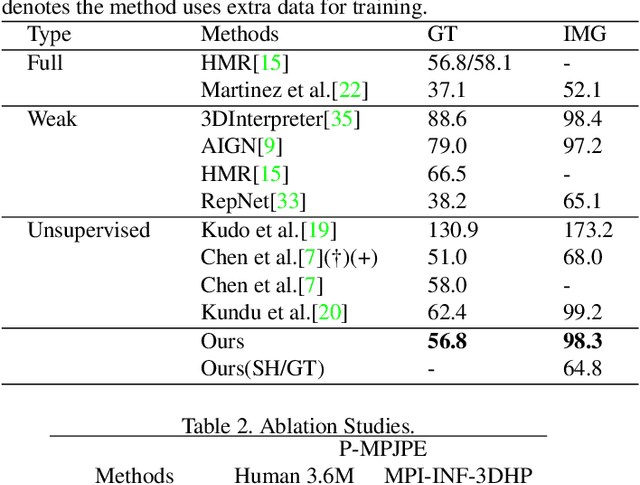
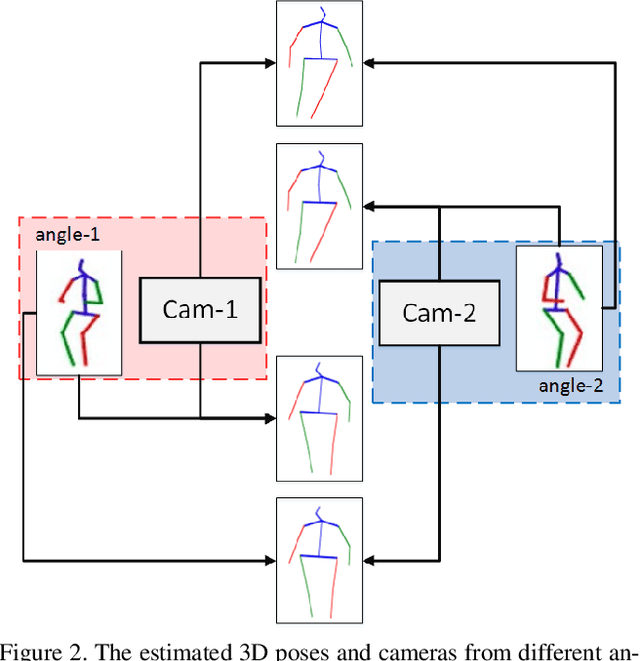
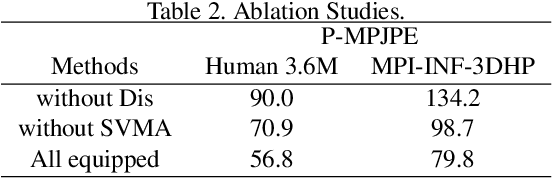
Recovering 3D human pose from 2D joints is a highly unconstrained problem, especially without any video or multi-view information. We present an unsupervised GAN-based model to recover 3D human pose from 2D joint locations extracted from a single image. Our model uses a GAN to learn the mapping of distribution from 2D poses to 3D poses, not the simple 2D-3D correspondence. Considering the reprojection constraint, our model can estimate the camera so that we can reproject the estimated 3D pose to the original 2D pose. Based on this reprojection method, we can rotate and reproject the generated pose to get our "new" 2D pose and then use a weight sharing generator to estimate the "new" 3D pose and a "new" camera. Through the above estimation process, we can define the single-view-multi-angle consistency loss during training to simulate multi-view consistency, which means the 3D poses and cameras estimated from two angles of a single view should be able to be mixed to generate rich 2D reprojections, and the 2D reprojections reprojected from the same 3D pose should be consistent. The experimental results on Human3.6M show that our method outperforms all the state-of-the-art methods, and results on MPI-INF-3DHP show that our method outperforms state-of-the-art by approximately 15.0%.
Ultrasound Image Representation Learning by Modeling Sonographer Visual Attention
Mar 07, 2019Image representations are commonly learned from class labels, which are a simplistic approximation of human image understanding. In this paper we demonstrate that transferable representations of images can be learned without manual annotations by modeling human visual attention. The basis of our analyses is a unique gaze tracking dataset of sonographers performing routine clinical fetal anomaly screenings. Models of sonographer visual attention are learned by training a convolutional neural network (CNN) to predict gaze on ultrasound video frames through visual saliency prediction or gaze-point regression. We evaluate the transferability of the learned representations to the task of ultrasound standard plane detection in two contexts. Firstly, we perform transfer learning by fine-tuning the CNN with a limited number of labeled standard plane images. We find that fine-tuning the saliency predictor is superior to training from random initialization, with an average F1-score improvement of 9.6% overall and 15.3% for the cardiac planes. Secondly, we train a simple softmax regression on the feature activations of each CNN layer in order to evaluate the representations independently of transfer learning hyper-parameters. We find that the attention models derive strong representations, approaching the precision of a fully-supervised baseline model for all but the last layer.
Face Forgery Detection by 3D Decomposition
Nov 19, 2020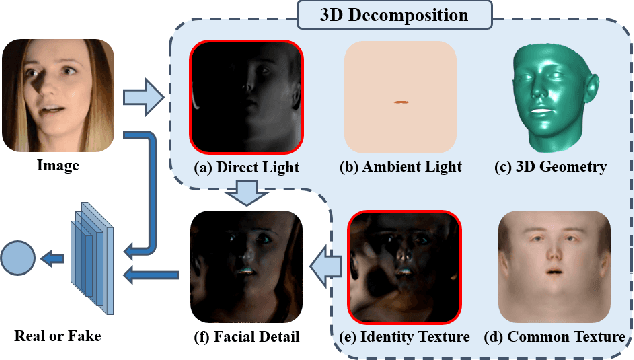


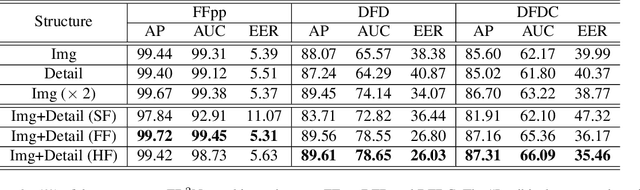
Detecting digital face manipulation has attracted extensive attention due to fake media's potential harms to the public. However, recent advances have been able to reduce the forgery signals to a low magnitude. Decomposition, which reversibly decomposes an image into several constituent elements, is a promising way to highlight the hidden forgery details. In this paper, we consider a face image as the production of the intervention of the underlying 3D geometry and the lighting environment, and decompose it in a computer graphics view. Specifically, by disentangling the face image into 3D shape, common texture, identity texture, ambient light, and direct light, we find the devil lies in the direct light and the identity texture. Based on this observation, we propose to utilize facial detail, which is the combination of direct light and identity texture, as the clue to detect the subtle forgery patterns. Besides, we highlight the manipulated region with a supervised attention mechanism and introduce a two-stream structure to exploit both face image and facial detail together as a multi-modality task. Extensive experiments indicate the effectiveness of the extra features extracted from the facial detail, and our method achieves the state-of-the-art performance.
Heterogeneous Noisy Short Signal Camouflage in Multi-Domain Environment Decision-Making
Jun 02, 2021
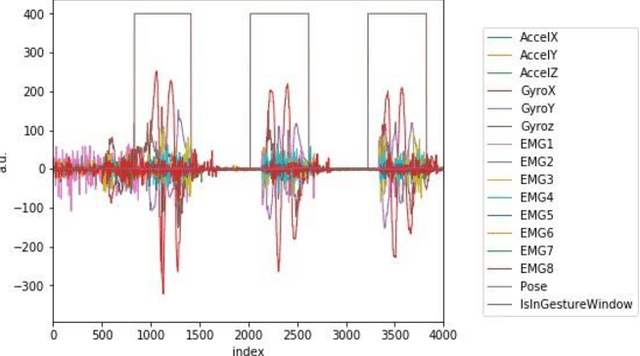
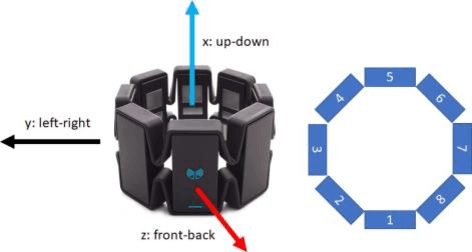
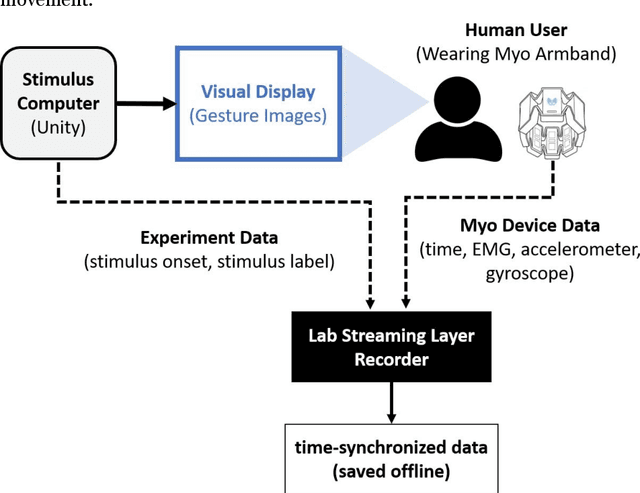
Data transmission between two or more digital devices in industry and government demands secure and agile technology. Digital information distribution often requires deployment of Internet of Things (IoT) devices and Data Fusion techniques which have also gained popularity in both, civilian and military environments, such as, emergence of Smart Cities and Internet of Battlefield Things (IoBT). This usually requires capturing and consolidating data from multiple sources. Because datasets do not necessarily originate from identical sensors, fused data typically results in a complex Big Data problem. Due to potentially sensitive nature of IoT datasets, Blockchain technology is used to facilitate secure sharing of IoT datasets, which allows digital information to be distributed, but not copied. However, blockchain has several limitations related to complexity, scalability, and excessive energy consumption. We propose an approach to hide information (sensor signal) by transforming it to an image or an audio signal. In one of the latest attempts to the military modernization, we investigate sensor fusion approach by investigating the challenges of enabling an intelligent identification and detection operation and demonstrates the feasibility of the proposed Deep Learning and Anomaly Detection models that can support future application for specific hand gesture alert system from wearable devices.
* Published at: http://www.ibai-publishing.org/journal/issue_massdata/2020_september/massdata_11_1_3_26.php. arXiv admin note: substantial text overlap with arXiv:2106.01497
SAR Image Despeckling by Deep Neural Networks: from a pre-trained model to an end-to-end training strategy
Jul 02, 2020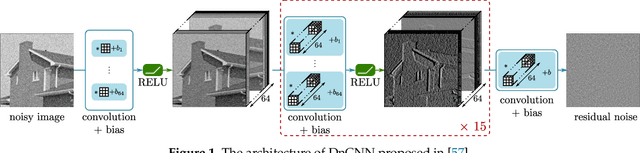
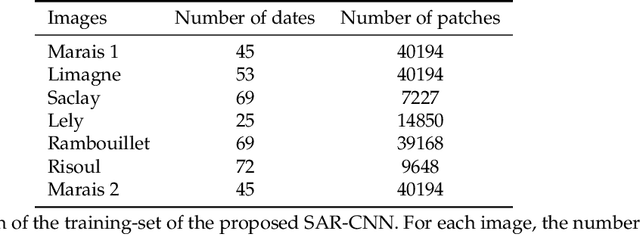
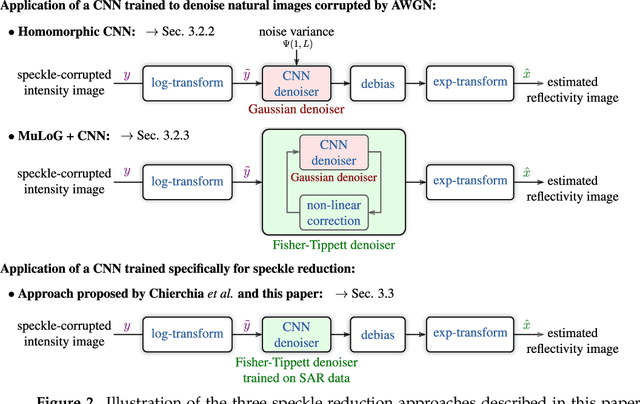
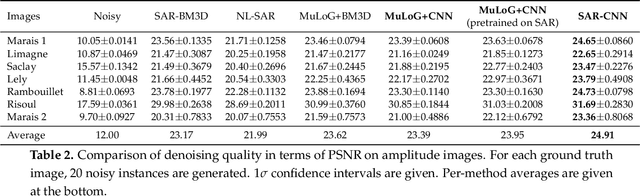
Speckle reduction is a longstanding topic in synthetic aperture radar (SAR) images. Many different schemes have been proposed for the restoration of intensity SAR images. Among the different possible approaches, methods based on convolutional neural networks (CNNs) have recently shown to reach state-of-the-art performance for SAR image restoration. CNN training requires good training data: many pairs of speckle-free / speckle-corrupted images. This is an issue in SAR applications, given the inherent scarcity of speckle-free images. To handle this problem, this paper analyzes different strategies one can adopt, depending on the speckle removal task one wishes to perform and the availability of multitemporal stacks of SAR data. The first strategy applies a CNN model, trained to remove additive white Gaussian noise from natural images, to a recently proposed SAR speckle removal framework: MuLoG (MUlti-channel LOgarithm with Gaussian denoising). No training on SAR images is performed, the network is readily applied to speckle reduction tasks. The second strategy considers a novel approach to construct a reliable dataset of speckle-free SAR images necessary to train a CNN model. Finally, a hybrid approach is also analyzed: the CNN used to remove additive white Gaussian noise is trained on speckle-free SAR images. The proposed methods are compared to other state-of-the-art speckle removal filters, to evaluate the quality of denoising and to discuss the pros and cons of the different strategies. Along with the paper, we make available the weights of the trained network to allow its usage by other researchers.
UAV Localization Using Autoencoded Satellite Images
Feb 10, 2021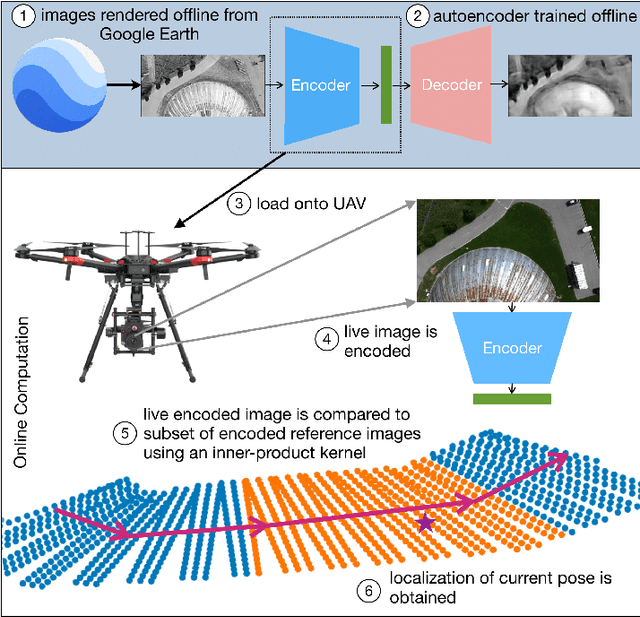


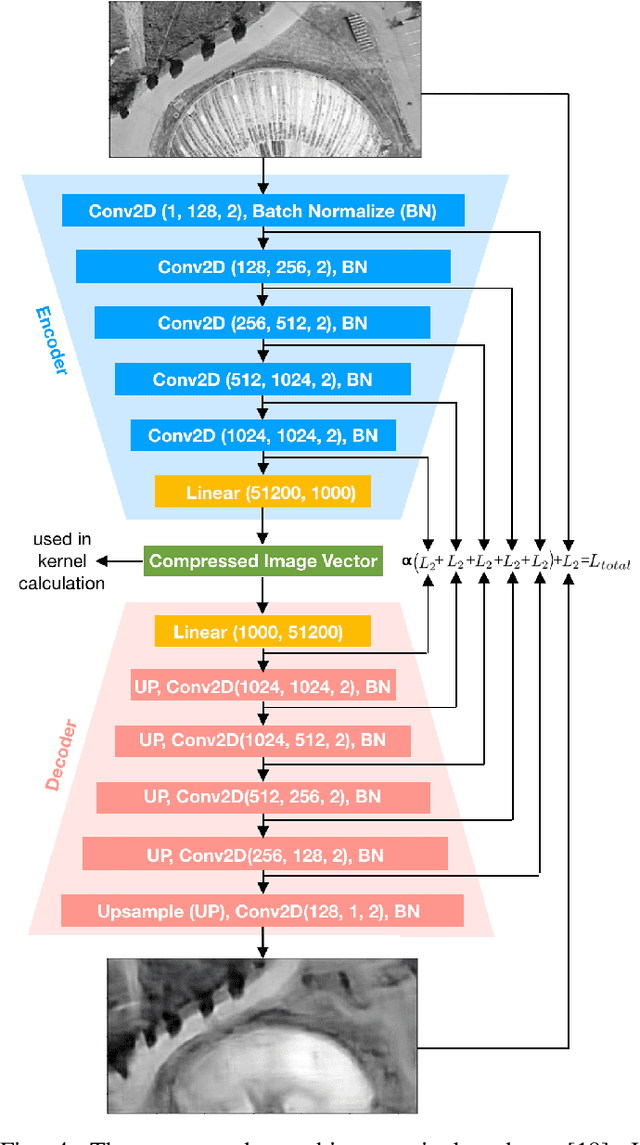
We propose and demonstrate a fast, robust method for using satellite images to localize an Unmanned Aerial Vehicle (UAV). Previous work using satellite images has large storage and computation costs and is unable to run in real time. In this work, we collect Google Earth (GE) images for a desired flight path offline and an autoencoder is trained to compress these images to a low-dimensional vector representation while retaining the key features. This trained autoencoder is used to compress a real UAV image, which is then compared to the precollected, nearby, autoencoded GE images using an inner-product kernel. This results in a distribution of weights over the corresponding GE image poses and is used to generate a single localization and associated covariance to represent uncertainty. Our localization is computed in 1% of the time of the current standard and is able to achieve a comparable RMSE of less than 3m in our experiments, where we robustly matched UAV images from six runs spanning the lighting conditions of a single day to the same map of satellite images.
Automated Video Labelling: Identifying Faces by Corroborative Evidence
Feb 10, 2021
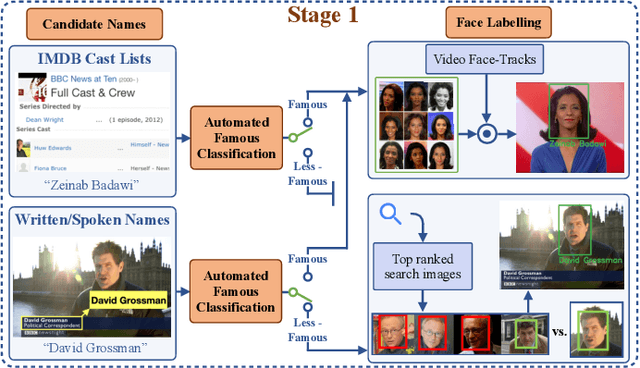
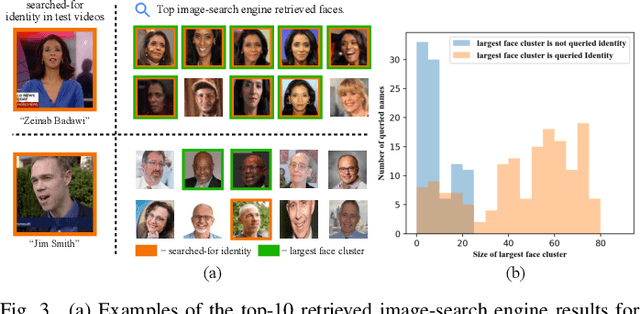

We present a method for automatically labelling all faces in video archives, such as TV broadcasts, by combining multiple evidence sources and multiple modalities (visual and audio). We target the problem of ever-growing online video archives, where an effective, scalable indexing solution cannot require a user to provide manual annotation or supervision. To this end, we make three key contributions: (1) We provide a novel, simple, method for determining if a person is famous or not using image-search engines. In turn this enables a face-identity model to be built reliably and robustly, and used for high precision automatic labelling; (2) We show that even for less-famous people, image-search engines can then be used for corroborative evidence to accurately label faces that are named in the scene or the speech; (3) Finally, we quantitatively demonstrate the benefits of our approach on different video domains and test settings, such as TV shows and news broadcasts. Our method works across three disparate datasets without any explicit domain adaptation, and sets new state-of-the-art results on all the public benchmarks.