 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerDropBack: A Universally Applicable Approach for Accelerating Training of Deep Networks
Dec 23, 2024Training very deep convolutional networks is challenging, requiring significant computational resources and time. Existing acceleration methods often depend on specific architectures or require network modifications. We introduce LayerDropBack (LDB), a simple yet effective method to accelerate training across a wide range of deep networks. LDB introduces randomness only in the backward pass, maintaining the integrity of the forward pass, guaranteeing that the same network is used during both training and inference. LDB can be seamlessly integrated into the training process of any model without altering its architecture, making it suitable for various network topologies. Our extensive experiments across multiple architectures (ViT, Swin Transformer, EfficientNet, DLA) and datasets (CIFAR-100, ImageNet) show significant training time reductions of 16.93\% to 23.97\%, while preserving or even enhancing model accuracy. Code is available at \url{https://github.com/neiterman21/LDB}.
SMM-Conv: Scalar Matrix Multiplication with Zero Packing for Accelerated Convolution
Nov 23, 2024



We present a novel approach for accelerating convolutions during inference for CPU-based architectures. The most common method of computation involves packing the image into the columns of a matrix (im2col) and performing general matrix multiplication (GEMM) with a matrix of weights. This results in two main drawbacks: (a) im2col requires a large memory buffer and can experience inefficient memory access, and (b) while GEMM is highly optimized for scientific matrices multiplications, it is not well suited for convolutions. We propose an approach that takes advantage of scalar-matrix multiplication and reduces memory overhead. Our experiments with commonly used network architectures demonstrate a significant speedup compared to existing indirect methods.
ChannelDropBack: Forward-Consistent Stochastic Regularization for Deep Networks
Nov 23, 2024Incorporating stochasticity into the training process of deep convolutional networks is a widely used technique to reduce overfitting and improve regularization. Existing techniques often require modifying the architecture of the network by adding specialized layers, are effective only to specific network topologies or types of layers - linear or convolutional, and result in a trained model that is different from the deployed one. We present ChannelDropBack, a simple stochastic regularization approach that introduces randomness only into the backward information flow, leaving the forward pass intact. ChannelDropBack randomly selects a subset of channels within the network during the backpropagation step and applies weight updates only to them. As a consequence, it allows for seamless integration into the training process of any model and layers without the need to change its architecture, making it applicable to various network topologies, and the exact same network is deployed during training and inference. Experimental evaluations validate the effectiveness of our approach, demonstrating improved accuracy on popular datasets and models, including ImageNet and ViT. Code is available at \url{https://github.com/neiterman21/ChannelDropBack.git}.
Deep BI-RADS Network for Improved Cancer Detection from Mammograms
Nov 16, 2024While state-of-the-art models for breast cancer detection leverage multi-view mammograms for enhanced diagnostic accuracy, they often focus solely on visual mammography data. However, radiologists document valuable lesion descriptors that contain additional information that can enhance mammography-based breast cancer screening. A key question is whether deep learning models can benefit from these expert-derived features. To address this question, we introduce a novel multi-modal approach that combines textual BI-RADS lesion descriptors with visual mammogram content. Our method employs iterative attention layers to effectively fuse these different modalities, significantly improving classification performance over image-only models. Experiments on the CBIS-DDSM dataset demonstrate substantial improvements across all metrics, demonstrating the contribution of handcrafted features to end-to-end.
One Size Fits All: Hypernetwork for Tunable Image Restoration
Jun 13, 2022
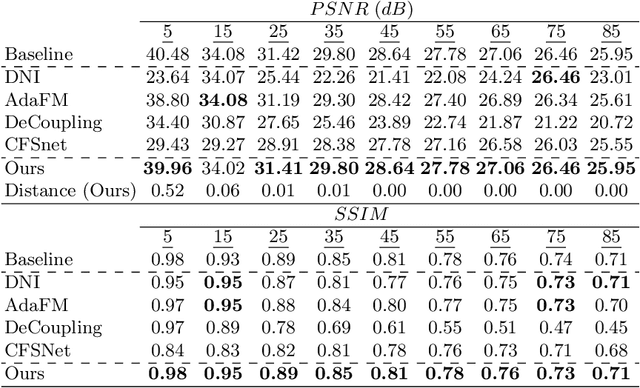
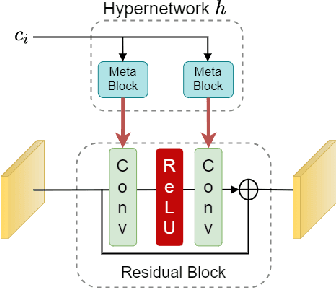

We introduce a novel approach for tunable image restoration that achieves the accuracy of multiple models, each optimized for a different level of degradation, with exactly the same number of parameters as a single model. Our model can be optimized to restore as many degradation levels as required with a constant number of parameters and for various image restoration tasks. Experiments on real-world datasets show that our approach achieves state-of-the art results in denoising, DeJPEG and super-resolution with respect to existing tunable models, allowing smoother and more accurate fitting over a wider range of degradation levels.
CEL-Net: Continuous Exposure for Extreme Low-Light Imaging
Dec 07, 2020



Deep learning methods for enhancing dark images learn a mapping from input images to output images with pre-determined discrete exposure levels. Often, at inference time the input and optimal output exposure levels of the given image are different from the seen ones during training. As a result the enhanced image might suffer from visual distortions, such as low contrast or dark areas. We address this issue by introducing a deep learning model that can continuously generalize at inference time to unseen exposure levels without the need to retrain the model. To this end, we introduce a dataset of 1500 raw images captured in both outdoor and indoor scenes, with five different exposure levels and various camera parameters. Using the dataset, we develop a model for extreme low-light imaging that can continuously tune the input or output exposure level of the image to an unseen one. We investigate the properties of our model and validate its performance, showing promising results.
Separable Four Points Fundamental Matrix
Jun 10, 2020
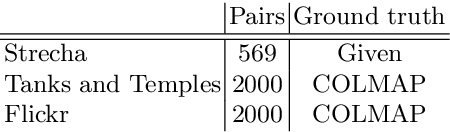
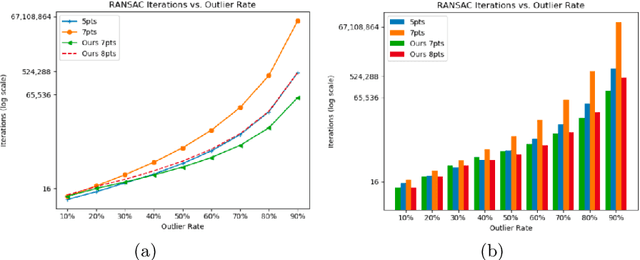
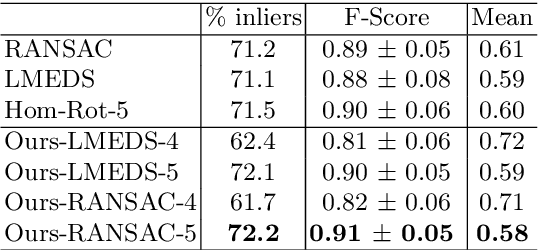
We present an approach for the computation of the fundamental matrix based on epipolar homography decomposition. We analyze the geometrical meaning of the decomposition-based representation and show that it guarantees a minimal number of RANSAC samples, on the condition that four correspondences are on an image line. Experiments on real-world image pairs show that our approach successfully recovers such four correspondences, provides accurate results and requires a very small number of RANSAC iterations.
Camera Calibration by Global Constraints on the Motion of Silhouettes
Apr 14, 2017
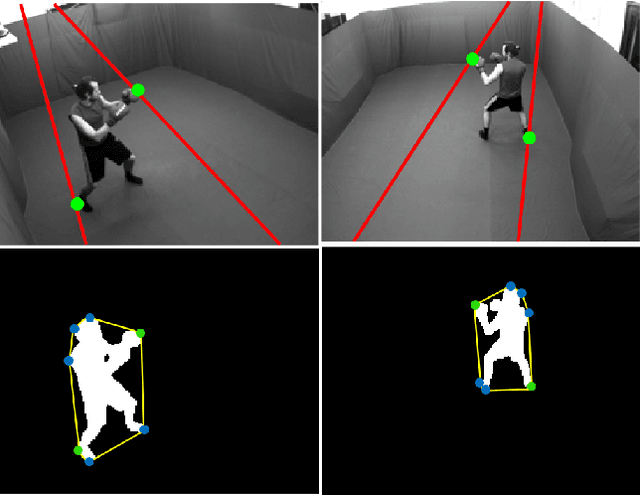
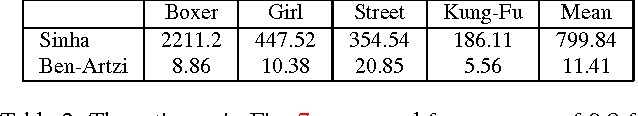
We address the problem of epipolar geometry using the motion of silhouettes. Such methods match epipolar lines or frontier points across views, which are then used as the set of putative correspondences. We introduce an approach that improves by two orders of magnitude the performance over state-of-the-art methods, by significantly reducing the number of outliers in the putative matching. We model the frontier points' correspondence problem as constrained flow optimization, requiring small differences between their coordinates over consecutive frames. Our approach is formulated as a Linear Integer Program and we show that due to the nature of our problem, it can be solved efficiently in an iterative manner. Our method was validated on four standard datasets providing accurate calibrations across very different viewpoints.
Camera Calibration from Dynamic Silhouettes Using Motion Barcodes
Jan 08, 2017
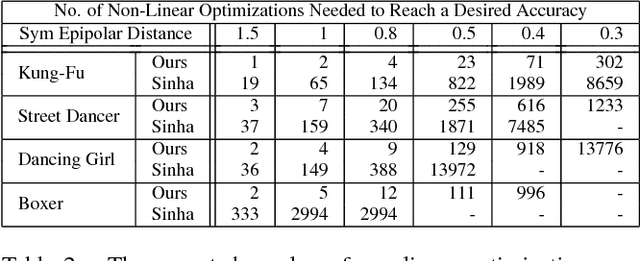
Computing the epipolar geometry between cameras with very different viewpoints is often problematic as matching points are hard to find. In these cases, it has been proposed to use information from dynamic objects in the scene for suggesting point and line correspondences. We propose a speed up of about two orders of magnitude, as well as an increase in robustness and accuracy, to methods computing epipolar geometry from dynamic silhouettes. This improvement is based on a new temporal signature: motion barcode for lines. Motion barcode is a binary temporal sequence for lines, indicating for each frame the existence of at least one foreground pixel on that line. The motion barcodes of two corresponding epipolar lines are very similar, so the search for corresponding epipolar lines can be limited only to lines having similar barcodes. The use of motion barcodes leads to increased speed, accuracy, and robustness in computing the epipolar geometry.
* Update metadata
Epipolar Geometry Based On Line Similarity
Jan 08, 2017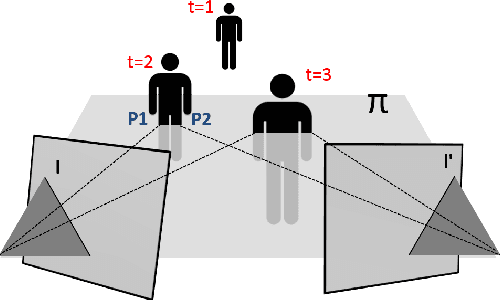
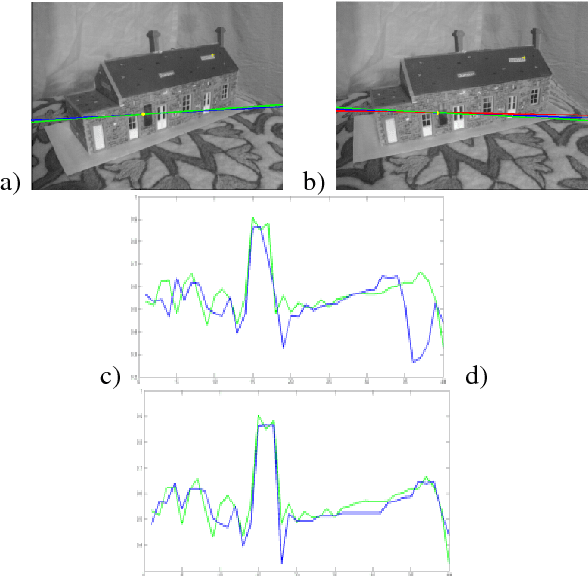
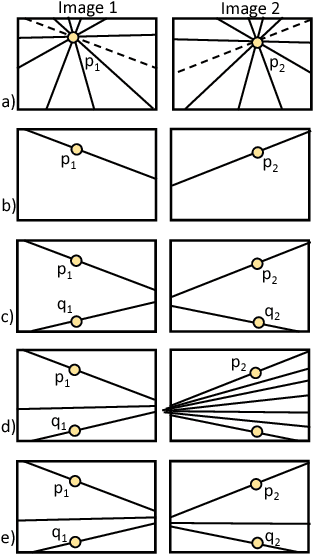

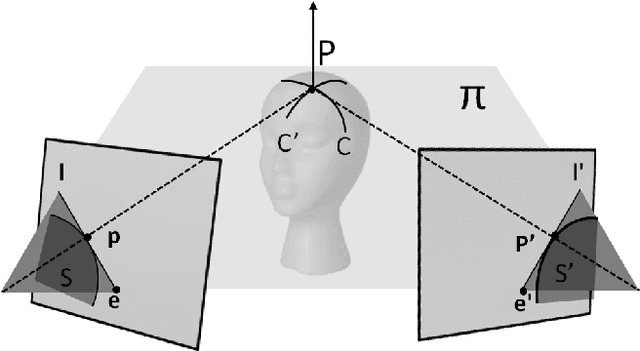
It is known that epipolar geometry can be computed from three epipolar line correspondences but this computation is rarely used in practice since there are no simple methods to find corresponding lines. Instead, methods for finding corresponding points are widely used. This paper proposes a similarity measure between lines that indicates whether two lines are corresponding epipolar lines and enables finding epipolar line correspondences as needed for the computation of epipolar geometry. A similarity measure between two lines, suitable for video sequences of a dynamic scene, has been previously described. This paper suggests a stereo matching similarity measure suitable for images. It is based on the quality of stereo matching between the two lines, as corresponding epipolar lines yield a good stereo correspondence. Instead of an exhaustive search over all possible pairs of lines, the search space is substantially reduced when two corresponding point pairs are given. We validate the proposed method using real-world images and compare it to state-of-the-art methods. We found this method to be more accurate by a factor of five compared to the standard method using seven corresponding points and comparable to the 8-points algorithm.
* ICPR 2016, Cancun, Dec 2016