 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adaptive Machine Learning for Time-Varying Systems: Low Dimensional Latent Space Tuning
Jul 13, 2021
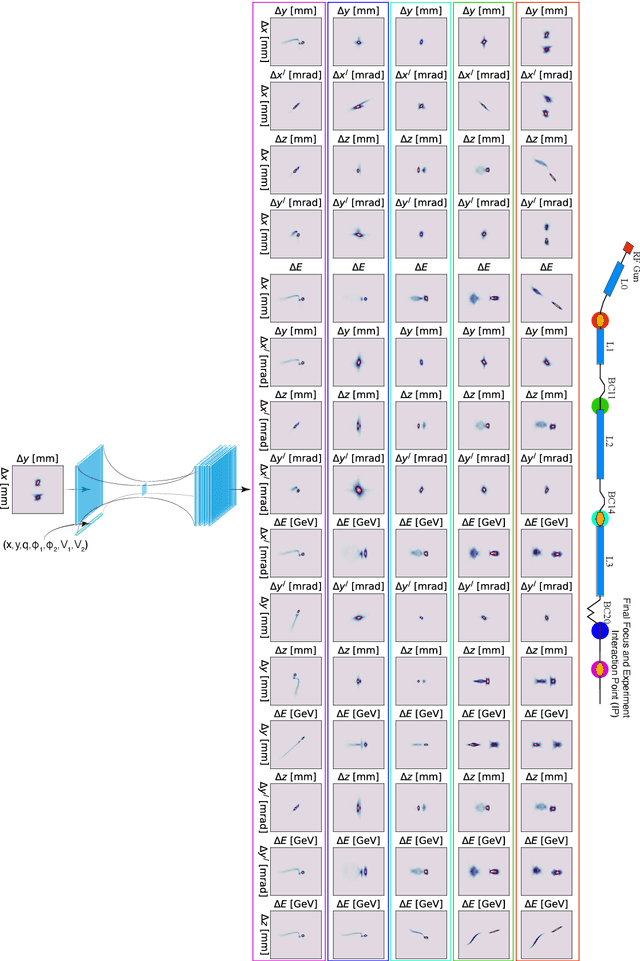
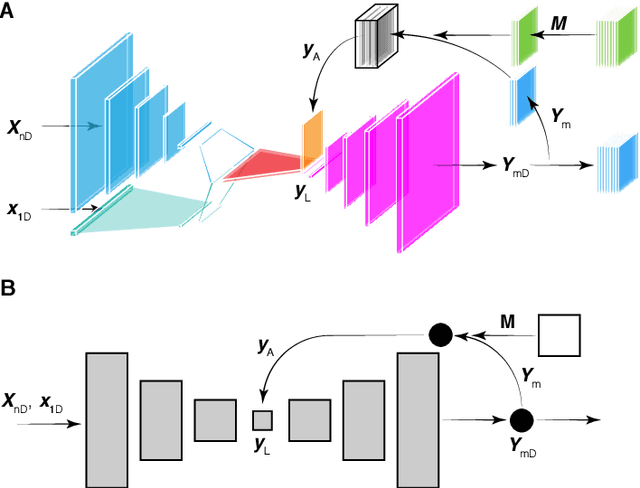
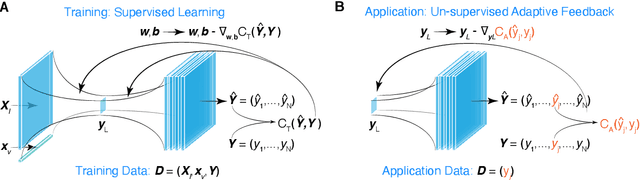
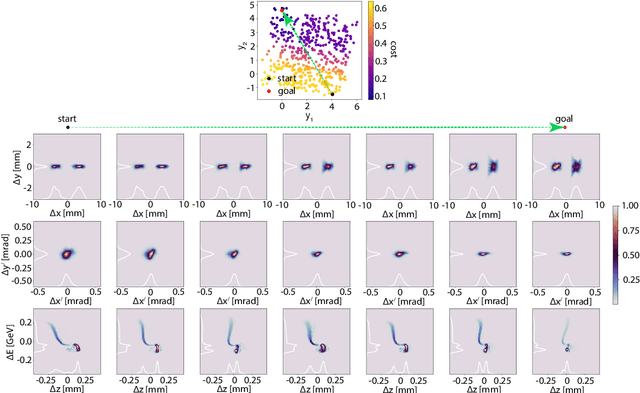
Machine learning (ML) tools such as encoder-decoder convolutional neural networks (CNN) can represent incredibly complex nonlinear functions which map between combinations of images and scalars. For example, CNNs can be used to map combinations of accelerator parameters and images which are 2D projections of the 6D phase space distributions of charged particle beams as they are transported between various particle accelerator locations. Despite their strengths, applying ML to time-varying systems, or systems with shifting distributions, is an open problem, especially for large systems for which collecting new data for re-training is impractical or interrupts operations. Particle accelerators are one example of large time-varying systems for which collecting detailed training data requires lengthy dedicated beam measurements which may no longer be available during regular operations. We present a recently developed method of adaptive ML for time-varying systems. Our approach is to map very high (N>100k) dimensional inputs (a combination of scalar parameters and images) into the low dimensional (N~2) latent space at the output of the encoder section of an encoder-decoder CNN. We then actively tune the low dimensional latent space-based representation of complex system dynamics by the addition of an adaptively tuned feedback vector directly before the decoder sections builds back up to our image-based high-dimensional phase space density representations. This method allows us to learn correlations within and to quickly tune the characteristics of incredibly high parameter systems and to track their evolution in real time based on feedback without massive new data sets for re-training.
Automatic Document Image Binarization using Bayesian Optimization
Oct 21, 2017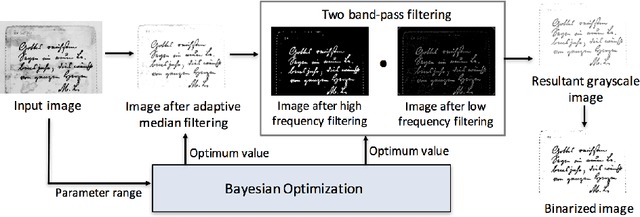
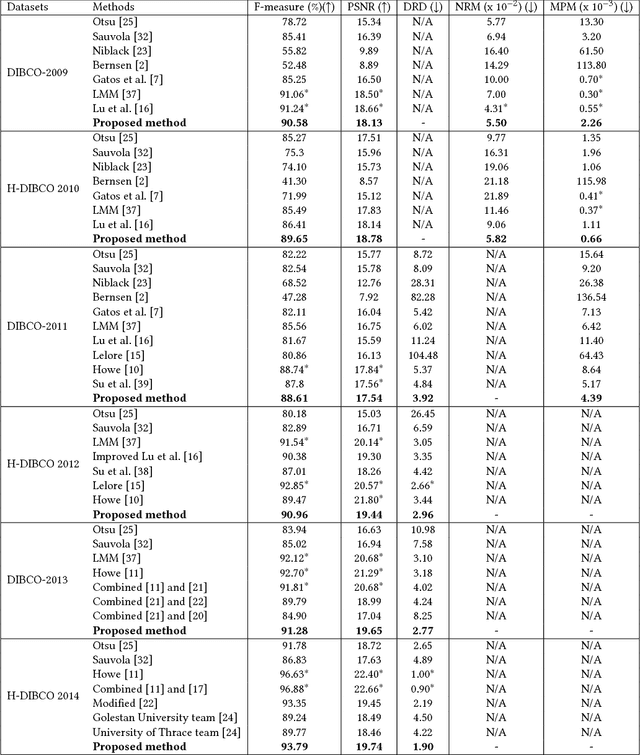

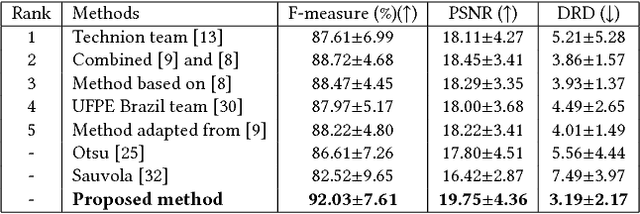
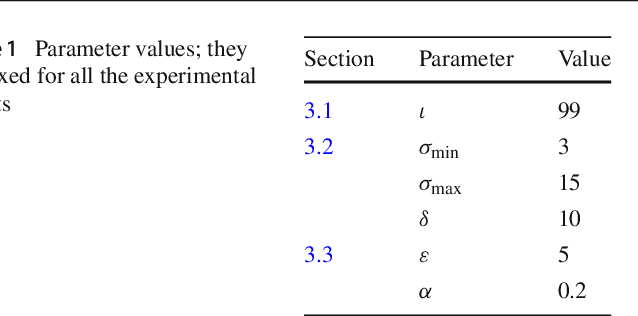
Document image binarization is often a challenging task due to various forms of degradation. Although there exist several binarization techniques in literature, the binarized image is typically sensitive to control parameter settings of the employed technique. This paper presents an automatic document image binarization algorithm to segment the text from heavily degraded document images. The proposed technique uses a two band-pass filtering approach for background noise removal, and Bayesian optimization for automatic hyperparameter selection for optimal results. The effectiveness of the proposed binarization technique is empirically demonstrated on the Document Image Binarization Competition (DIBCO) and the Handwritten Document Image Binarization Competition (H-DIBCO) datasets.
Automatic Flare Spot Artifact Detection and Removal in Photographs
Mar 07, 2021

Flare spot is one type of flare artifact caused by a number of conditions, frequently provoked by one or more high-luminance sources within or close to the camera field of view. When light rays coming from a high-luminance source reach the front element of a camera, it can produce intra-reflections within camera elements that emerge at the film plane forming non-image information or flare on the captured image. Even though preventive mechanisms are used, artifacts can appear. In this paper, we propose a robust computational method to automatically detect and remove flare spot artifacts. Our contribution is threefold: firstly, we propose a characterization which is based on intrinsic properties that a flare spot is likely to satisfy; secondly, we define a new confidence measure able to select flare spots among the candidates; and, finally, a method to accurately determine the flare region is given. Then, the detected artifacts are removed by using exemplar-based inpainting. We show that our algorithm achieve top-tier quantitative and qualitative performance.
* Journal of Mathematical Imaging and Vision, 2019
Developing a Fidelity Evaluation Approach for Interpretable Machine Learning
Jun 16, 2021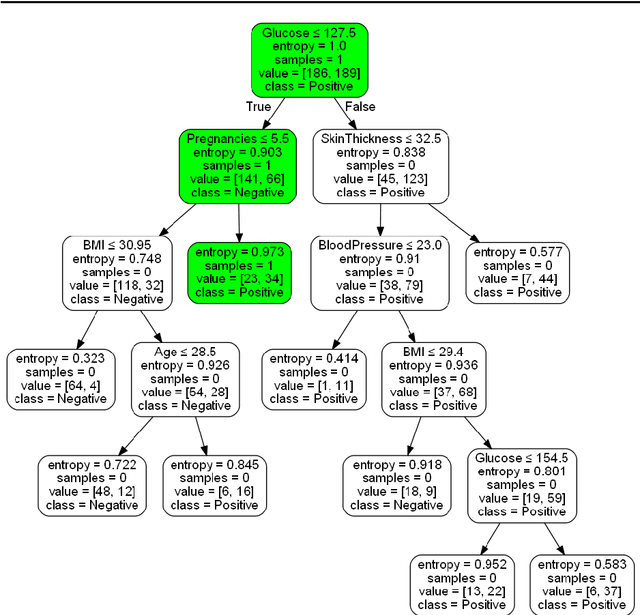
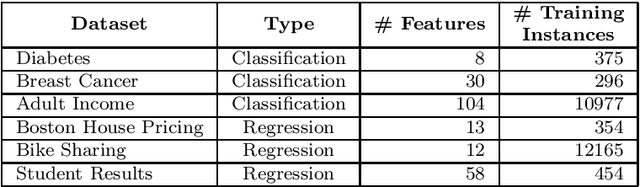
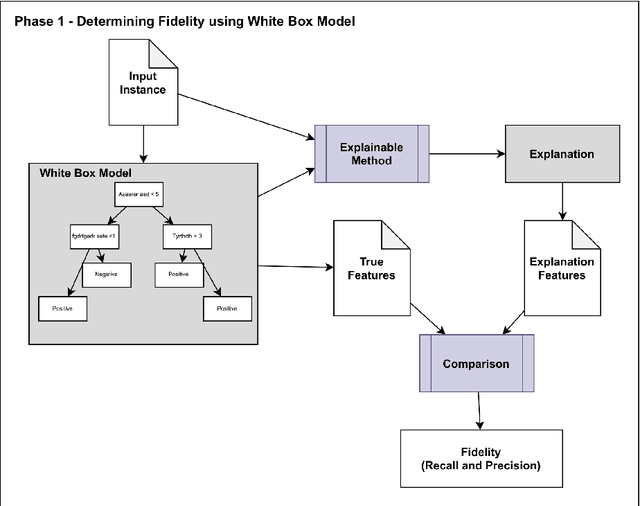
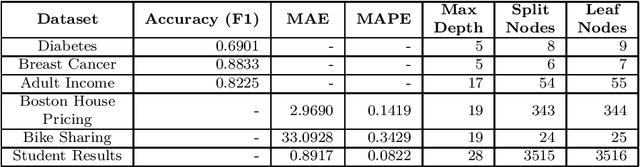
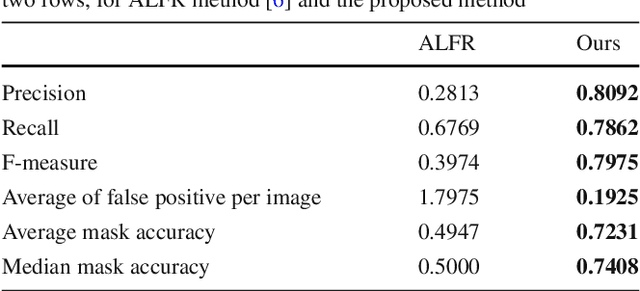
Although modern machine learning and deep learning methods allow for complex and in-depth data analytics, the predictive models generated by these methods are often highly complex, and lack transparency. Explainable AI (XAI) methods are used to improve the interpretability of these complex models, and in doing so improve transparency. However, the inherent fitness of these explainable methods can be hard to evaluate. In particular, methods to evaluate the fidelity of the explanation to the underlying black box require further development, especially for tabular data. In this paper, we (a) propose a three phase approach to developing an evaluation method; (b) adapt an existing evaluation method primarily for image and text data to evaluate models trained on tabular data; and (c) evaluate two popular explainable methods using this evaluation method. Our evaluations suggest that the internal mechanism of the underlying predictive model, the internal mechanism of the explainable method used and model and data complexity all affect explanation fidelity. Given that explanation fidelity is so sensitive to context and tools and data used, we could not clearly identify any specific explainable method as being superior to another.
Retrieval Augmentation to Improve Robustness and Interpretability of Deep Neural Networks
Feb 25, 2021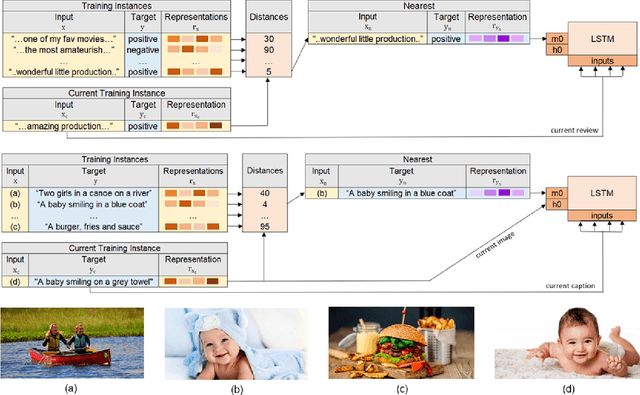
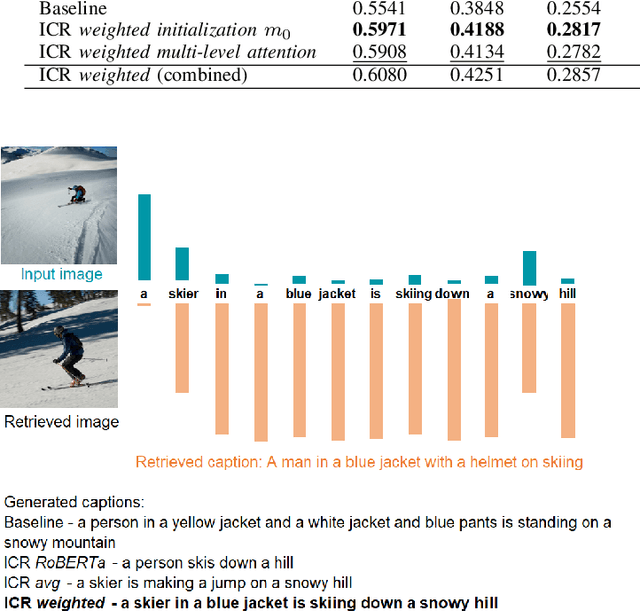


Deep neural network models have achieved state-of-the-art results in various tasks related to vision and/or language. Despite the use of large training data, most models are trained by iterating over single input-output pairs, discarding the remaining examples for the current prediction. In this work, we actively exploit the training data to improve the robustness and interpretability of deep neural networks, using the information from nearest training examples to aid the prediction both during training and testing. Specifically, the proposed approach uses the target of the nearest input example to initialize the memory state of an LSTM model or to guide attention mechanisms. We apply this approach to image captioning and sentiment analysis, conducting experiments with both image and text retrieval. Results show the effectiveness of the proposed models for the two tasks, on the widely used Flickr8 and IMDB datasets, respectively. Our code is publicly available http://github.com/RitaRamo/retrieval-augmentation-nn.
K-expectiles clustering
Mar 16, 2021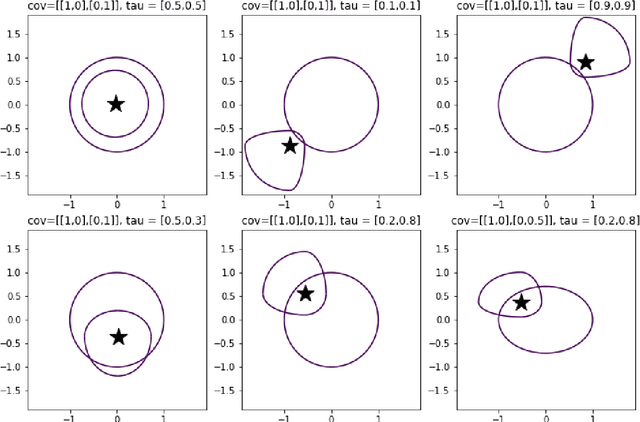
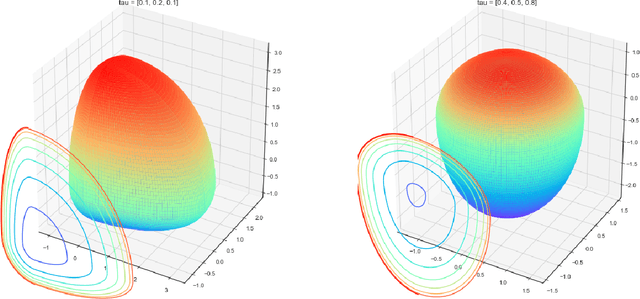
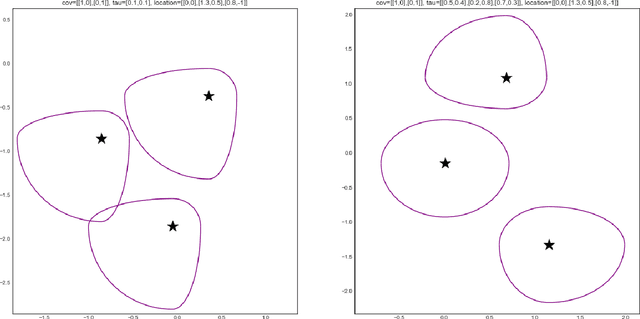

$K$-means clustering is one of the most widely-used partitioning algorithm in cluster analysis due to its simplicity and computational efficiency. However, $K$-means does not provide an appropriate clustering result when applying to data with non-spherically shaped clusters. We propose a novel partitioning clustering algorithm based on expectiles. The cluster centers are defined as multivariate expectiles and clusters are searched via a greedy algorithm by minimizing the within cluster '$\tau$ -variance'. We suggest two schemes: fixed $\tau$ clustering, and adaptive $\tau$ clustering. Validated by simulation results, this method beats both $K$-means and spectral clustering on data with asymmetric shaped clusters, or clusters with a complicated structure, including asymmetric normal, beta, skewed $t$ and $F$ distributed clusters. Applications of adaptive $\tau$ clustering on crypto-currency (CC) market data are provided. One finds that the expectiles clusters of CC markets show the phenomena of an institutional investors dominated market. The second application is on image segmentation. compared to other center based clustering methods, the adaptive $\tau$ cluster centers of pixel data can better capture and describe the features of an image. The fixed $\tau$ clustering brings more flexibility on segmentation with a decent accuracy.
Free-Form Image Inpainting with Gated Convolution
Jun 10, 2018

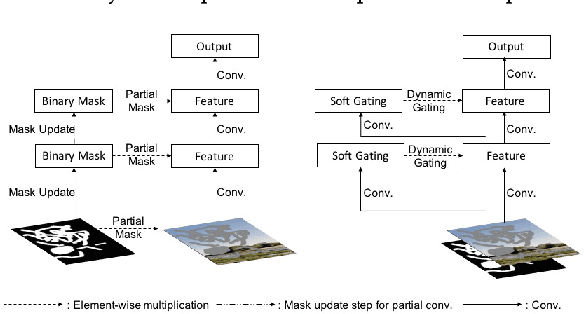

We present a novel deep learning based image inpainting system to complete images with free-form masks and inputs. The system is based on gated convolutions learned from millions of images without additional labelling efforts. The proposed gated convolution solves the issue of vanilla convolution that treats all input pixels as valid ones, generalizes partial convolution by providing a learnable dynamic feature selection mechanism for each channel at each spatial location across all layers. Moreover, as free-form masks may appear anywhere in images with any shapes, global and local GANs designed for a single rectangular mask are not suitable. To this end, we also present a novel GAN loss, named SN-PatchGAN, by applying spectral-normalized discriminators on dense image patches. It is simple in formulation, fast and stable in training. Results on automatic image inpainting and user-guided extension demonstrate that our system generates higher-quality and more flexible results than previous methods. We show that our system helps users quickly remove distracting objects, modify image layouts, clear watermarks, edit faces and interactively create novel objects in images. Furthermore, visualization of learned feature representations reveals the effectiveness of gated convolution and provides an interpretation of how the proposed neural network fills in missing regions. More high-resolution results and video materials are available at http://jiahuiyu.com/deepfill2
Infrared and visible image fusion using a novel deep decomposition method
Nov 06, 2018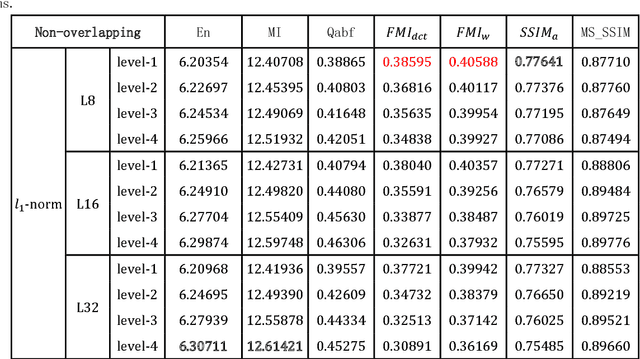
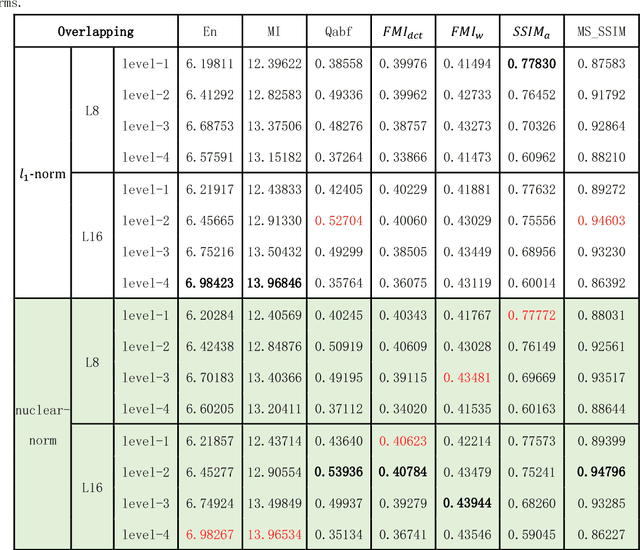
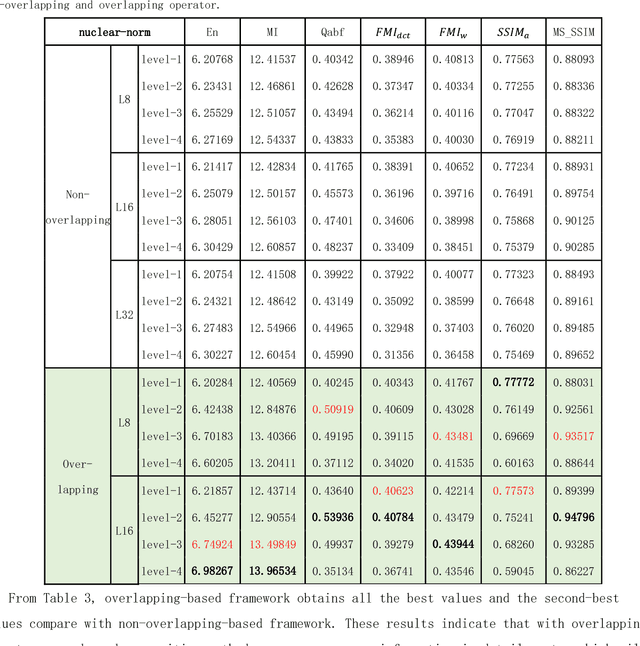
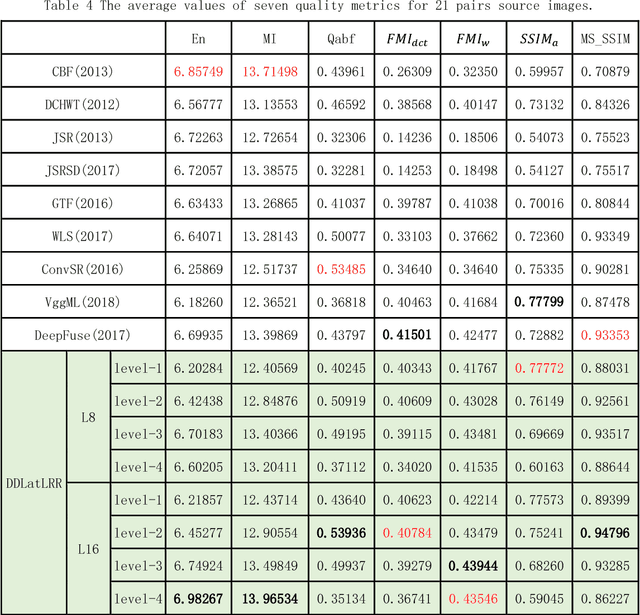
Infrared and visible image fusion is an important problem in image fusion tasks which has been applied widely in many fields. To better preserve the useful information from source images, in this paper, we propose an effective image fusion framework using a novel deep decomposition method which based on Latent Low-Rank Representation(LatLRR). And this decomposition method is also named DDLatLRR. Firstly, the LatLRR is utilized to learn a project matrix which used to extract salient features. Then, the base part and multi-level detail parts are obtained by DDLatLRR. With adaptive fusion strategies, the fused base part and the fused detail parts are reconstructed. Finally, the fused image is obtained by combine the fused base part and the detail parts. Compared with other fusion methods experimentally, the proposed algorithm has better fusion performance than state-of-the-art fusion methods in both subjective and objective evaluation. The Code of our fusion method is available at https://github.com/exceptionLi/imagefusion_deepdecomposition
Multi-Class Classification of Blood Cells -- End to End Computer Vision based diagnosis case study
Jun 23, 2021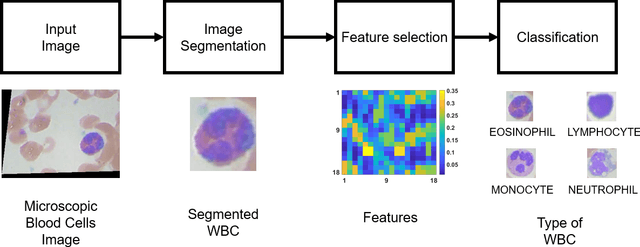
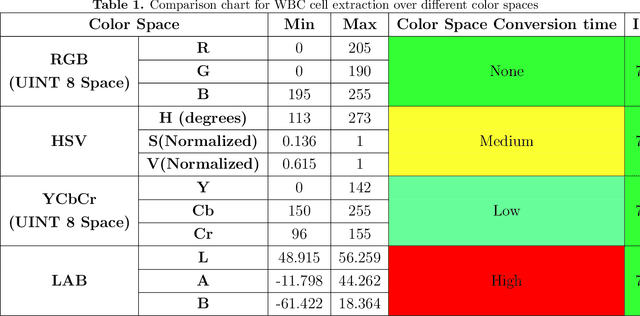
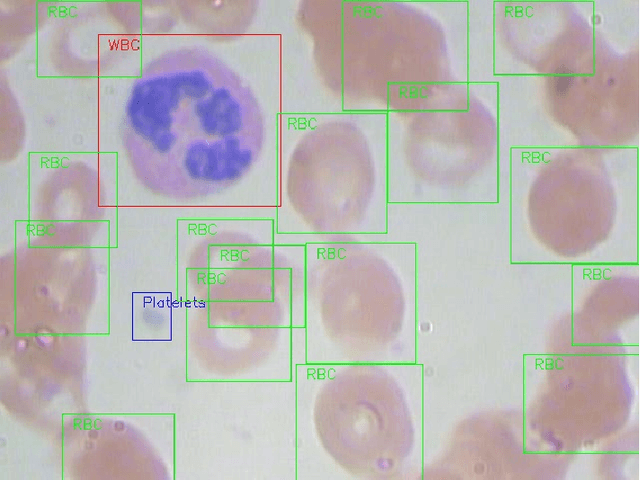
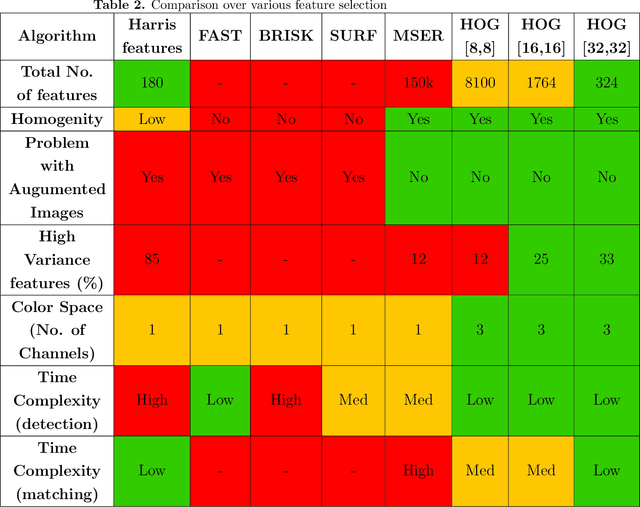
The diagnosis of blood-based diseases often involves identifying and characterizing patient blood samples. Automated methods to detect and classify blood cell subtypes have important medical applications. Automated medical image processing and analysis offers a powerful tool for medical diagnosis. In this work we tackle the problem of white blood cell classification based on the morphological characteristics of their outer contour, color. The work we would explore a set of preprocessing and segmentation (Color-based segmentation, Morphological processing, contouring) algorithms along with a set of features extraction methods (Corner detection algorithms and Histogram of Gradients(HOG)), dimensionality reduction algorithms (Principal Component Analysis(PCA)) that are able to recognize and classify through various Unsupervised(k-nearest neighbors) and Supervised (Support Vector Machine, Decision Trees, Linear Discriminant Analysis, Quadratic Discriminant Analysis, Naive Bayes) algorithms different categories of white blood cells to Eosinophil, Lymphocyte, Monocyte, and Neutrophil. We even take a step forwards to explore various Deep Convolutional Neural network architecture (Sqeezent, MobilenetV1,MobilenetV2, InceptionNet etc.) without preprocessing/segmentation and with preprocessing. We would like to explore many algorithms to identify the robust algorithm with least time complexity and low resource requirement. The outcome of this work can be a cue to selection of algorithms as per requirement for automated blood cell classification.
DeepCorrect: Correcting DNN models against Image Distortions
Jan 09, 2018



In recent years, the widespread use of deep neural networks (DNNs) has facilitated great improvements in performance for computer vision tasks like image classification and object recognition. In most realistic computer vision applications, an input image undergoes some form of image distortion such as blur and additive noise during image acquisition or transmission. Deep networks trained on pristine images perform poorly when tested on such distortions. In this paper, we evaluate the effect of image distortions like Gaussian blur and additive noise on the activations of pre-trained convolutional filters. We propose a metric to identify the most noise susceptible convolutional filters and rank them in order of the highest gain in classification accuracy upon correction. In our proposed approach called DeepCorrect, we apply small stacks of convolutional layers with residual connections, at the output of these ranked filters and train them to correct the worst distortion affected filter activations, whilst leaving the rest of the pre-trained filter outputs in the network unchanged. Performance results show that applying DeepCorrect models for common vision tasks like image classification (CIFAR-100, ImageNet), object recognition (Caltech-101, Caltech-256) and scene classification (SUN-397), significantly improves the robustness of DNNs against distorted images and outperforms the alternative approach of network fine-tuning.