 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ID-Unet: Iterative Soft and Hard Deformation for View Synthesis
Mar 18, 2021
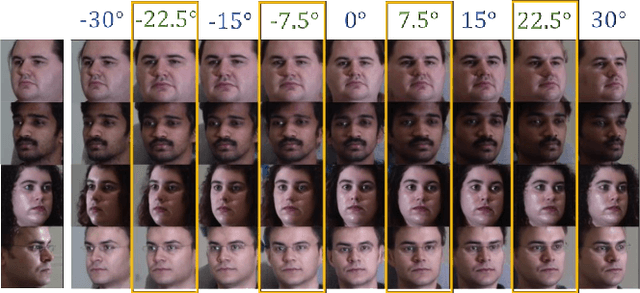
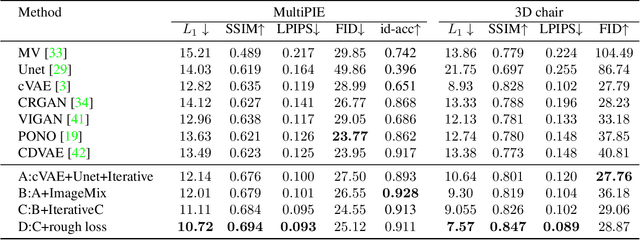
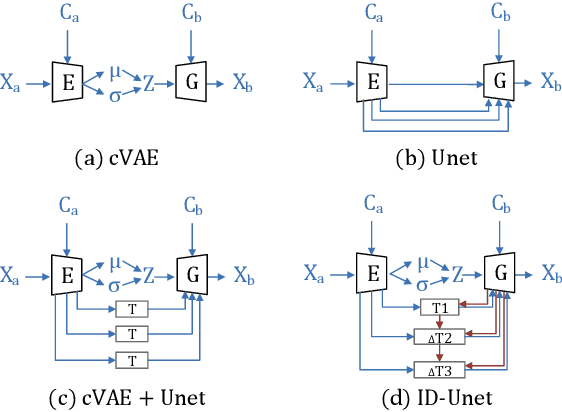
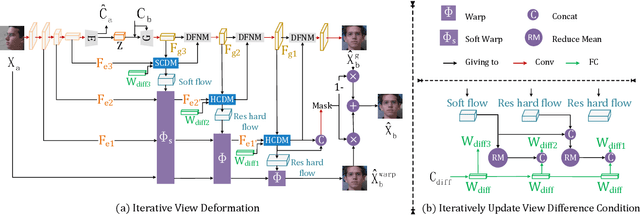
View synthesis is usually done by an autoencoder, in which the encoder maps a source view image into a latent content code, and the decoder transforms it into a target view image according to the condition. However, the source contents are often not well kept in this setting, which leads to unnecessary changes during the view translation. Although adding skipped connections, like Unet, alleviates the problem, but it often causes the failure on the view conformity. This paper proposes a new architecture by performing the source-to-target deformation in an iterative way. Instead of simply incorporating the features from multiple layers of the encoder, we design soft and hard deformation modules, which warp the encoder features to the target view at different resolutions, and give results to the decoder to complement the details. Particularly, the current warping flow is not only used to align the feature of the same resolution, but also as an approximation to coarsely deform the high resolution feature. Then the residual flow is estimated and applied in the high resolution, so that the deformation is built up in the coarse-to-fine fashion. To better constrain the model, we synthesize a rough target view image based on the intermediate flows and their warped features. The extensive ablation studies and the final results on two different data sets show the effectiveness of the proposed model.
Learning Representational Invariances for Data-Efficient Action Recognition
Mar 30, 2021

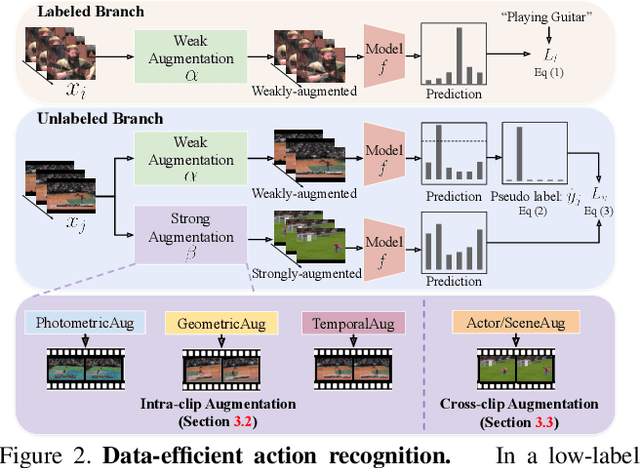
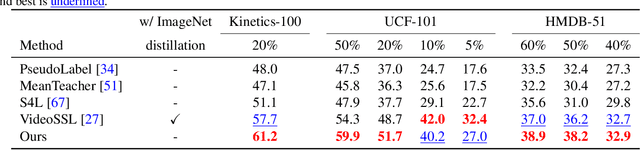
Data augmentation is a ubiquitous technique for improving image classification when labeled data is scarce. Constraining the model predictions to be invariant to diverse data augmentations effectively injects the desired representational invariances to the model (e.g., invariance to photometric variations), leading to improved accuracy. Compared to image data, the appearance variations in videos are far more complex due to the additional temporal dimension. Yet, data augmentation methods for videos remain under-explored. In this paper, we investigate various data augmentation strategies that capture different video invariances, including photometric, geometric, temporal, and actor/scene augmentations. When integrated with existing consistency-based semi-supervised learning frameworks, we show that our data augmentation strategy leads to promising performance on the Kinetics-100, UCF-101, and HMDB-51 datasets in the low-label regime. We also validate our data augmentation strategy in the fully supervised setting and demonstrate improved performance.
Equivariant Wavelets: Fast Rotation and Translation Invariant Wavelet Scattering Transforms
Apr 22, 2021
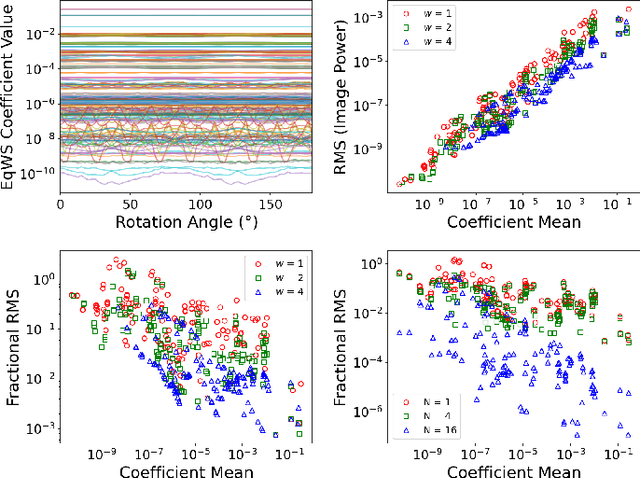
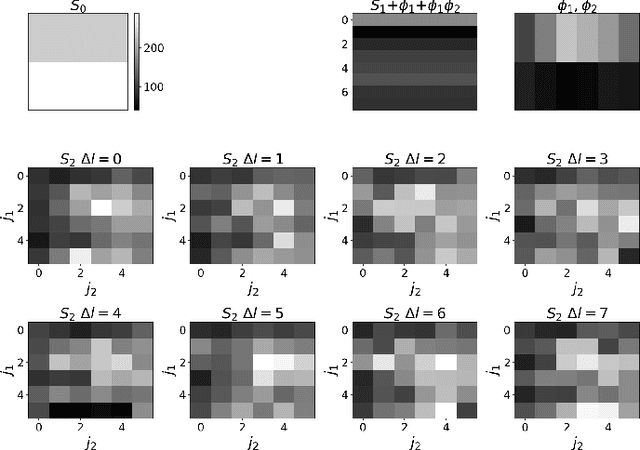
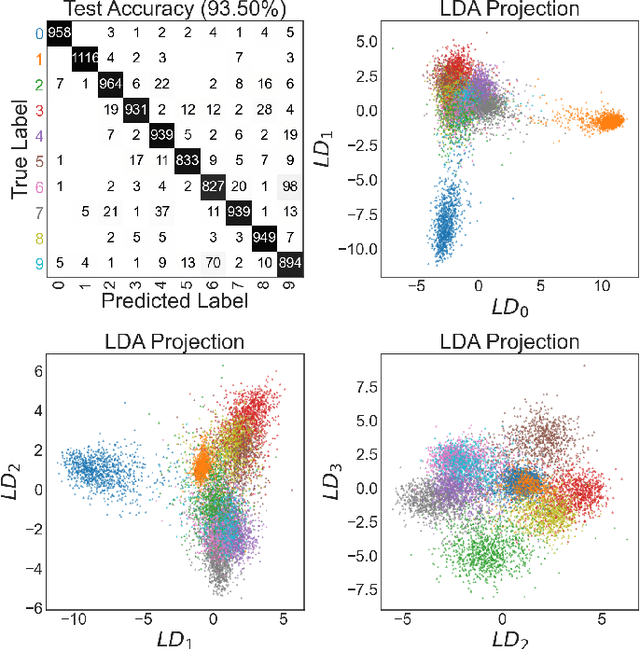
Wavelet scattering networks, which are convolutional neural networks (CNNs) with fixed filters and weights, are promising tools for image analysis. Imposing symmetry on image statistics can improve human interpretability, aid in generalization, and provide dimension reduction. In this work, we introduce a fast-to-compute, translationally invariant and rotationally equivariant wavelet scattering network (EqWS) and filter bank of wavelets (triglets). We demonstrate the interpretability and quantify the invariance/equivariance of the coefficients, briefly commenting on difficulties with implementing scale equivariance. On MNIST, we show that training on a rotationally invariant reduction of the coefficients maintains rotational invariance when generalized to test data and visualize residual symmetry breaking terms. Rotation equivariance is leveraged to estimate the rotation angle of digits and reconstruct the full rotation dependence of each coefficient from a single angle. We benchmark EqWS with linear classifiers on EMNIST and CIFAR-10/100, introducing a new second-order, cross-color channel coupling for the color images. We conclude by comparing the performance of an isotropic reduction of the scattering coefficients and RWST, a previous coefficient reduction, on an isotropic classification of magnetohydrodynamic simulations with astrophysical relevance.
A Data Augmentation Method by Mixing Up Negative Candidate Answers for Solving Raven's Progressive Matrices
Mar 09, 2021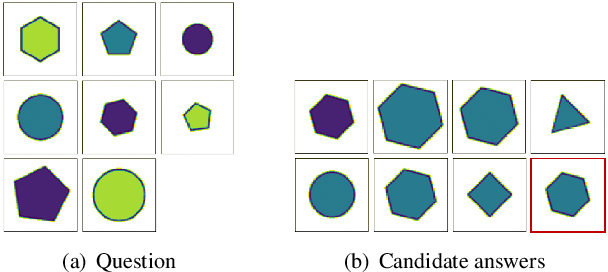

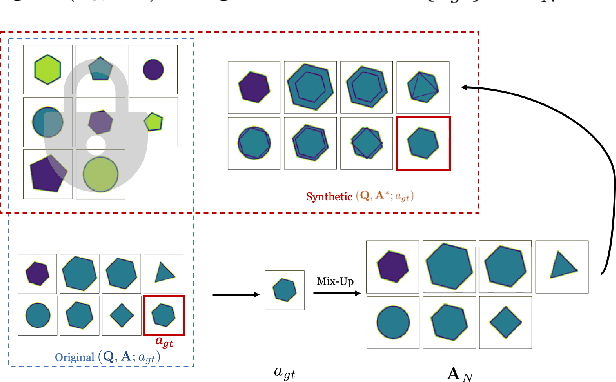
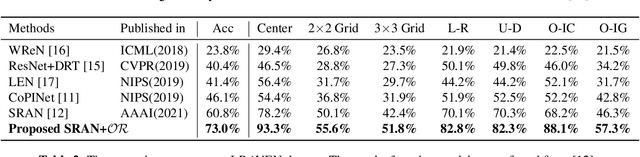
Raven's Progressive Matrices (RPMs) are frequently-used in testing human's visual reasoning ability. Recently developed RPM-like datasets and solution models transfer this kind of problems from cognitive science to computer science. In view of the poor generalization performance due to insufficient samples in RPM datasets, we propose a data augmentation strategy by image mix-up, which is generalizable to a variety of multiple-choice problems, especially for image-based RPM-like problems. By focusing on potential functionalities of negative candidate answers, the visual reasoning capability of the model is enhanced. By applying the proposed data augmentation method, we achieve significant and consistent improvement on various RPM-like datasets compared with the state-of-the-art models.
Deep Aggregation of Regional Convolutional Activations for Content Based Image Retrieval
Sep 20, 2019



One of the key challenges of deep learning based image retrieval remains in aggregating convolutional activations into one highly representative feature vector. Ideally, this descriptor should encode semantic, spatial and low level information. Even though off-the-shelf pre-trained neural networks can already produce good representations in combination with aggregation methods, appropriate fine tuning for the task of image retrieval has shown to significantly boost retrieval performance. In this paper, we present a simple yet effective supervised aggregation method built on top of existing regional pooling approaches. In addition to the maximum activation of a given region, we calculate regional average activations of extracted feature maps. Subsequently, weights for each of the pooled feature vectors are learned to perform a weighted aggregation to a single feature vector. Furthermore, we apply our newly proposed NRA loss function for deep metric learning to fine tune the backbone neural network and to learn the aggregation weights. Our method achieves state-of-the-art results for the INRIA Holidays data set and competitive results for the Oxford Buildings and Paris data sets while reducing the training time significantly.
Context-aware Execution Migration Tool for Data Science Jupyter Notebooks on Hybrid Clouds
Jul 01, 2021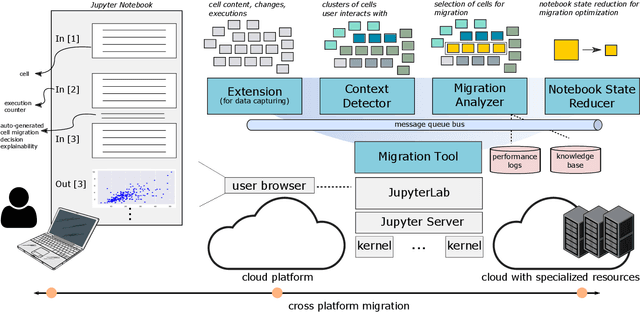
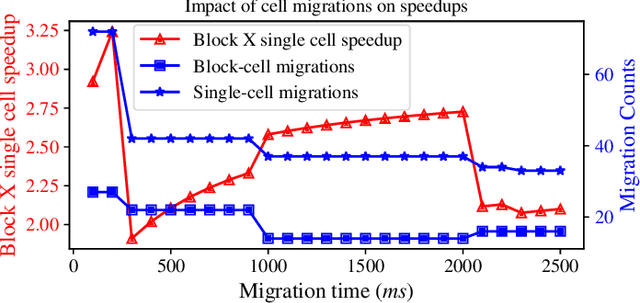
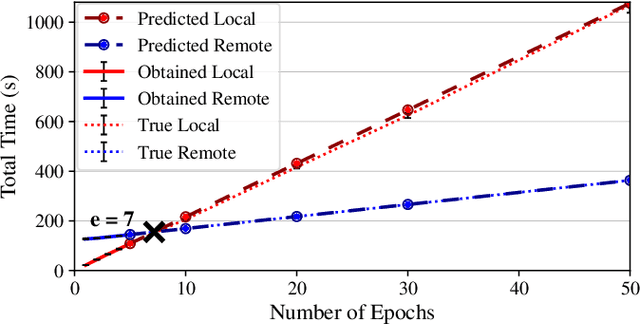
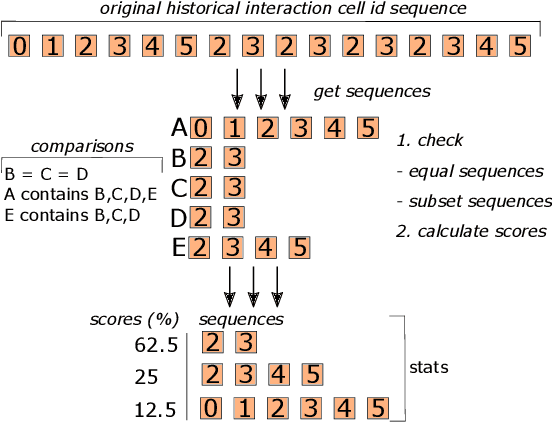
Interactive computing notebooks, such as Jupyter notebooks, have become a popular tool for developing and improving data-driven models. Such notebooks tend to be executed either in the user's own machine or in a cloud environment, having drawbacks and benefits in both approaches. This paper presents a solution developed as a Jupyter extension that automatically selects which cells, as well as in which scenarios, such cells should be migrated to a more suitable platform for execution. We describe how we reduce the execution state of the notebook to decrease migration time and we explore the knowledge of user interactivity patterns with the notebook to determine which blocks of cells should be migrated. Using notebooks from Earth science (remote sensing), image recognition, and hand written digit identification (machine learning), our experiments show notebook state reductions of up to 55x and migration decisions leading to performance gains of up to 3.25x when the user interactivity with the notebook is taken into consideration.
Portrait Neural Radiance Fields from a Single Image
Dec 10, 2020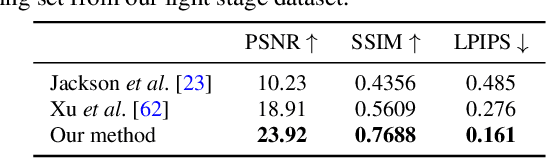
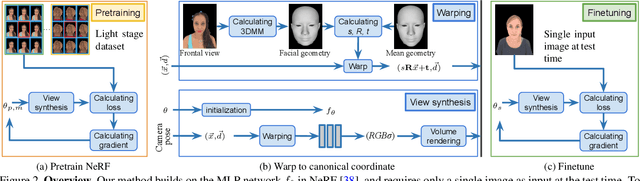
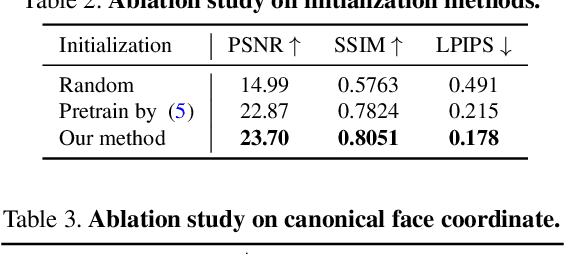
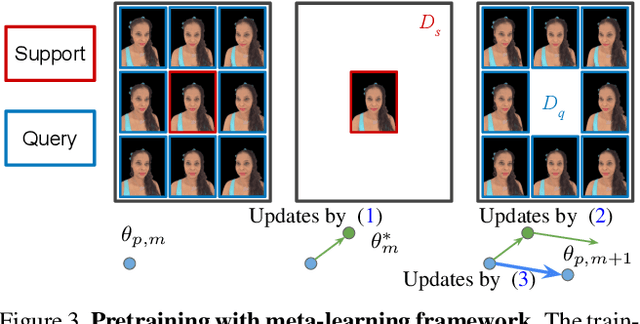
We present a method for estimating Neural Radiance Fields (NeRF) from a single headshot portrait. While NeRF has demonstrated high-quality view synthesis, it requires multiple images of static scenes and thus impractical for casual captures and moving subjects. In this work, we propose to pretrain the weights of a multilayer perceptron (MLP), which implicitly models the volumetric density and colors, with a meta-learning framework using a light stage portrait dataset. To improve the generalization to unseen faces, we train the MLP in the canonical coordinate space approximated by 3D face morphable models. We quantitatively evaluate the method using controlled captures and demonstrate the generalization to real portrait images, showing favorable results against state-of-the-arts.
Puzzle-CAM: Improved localization via matching partial and full features
Jan 28, 2021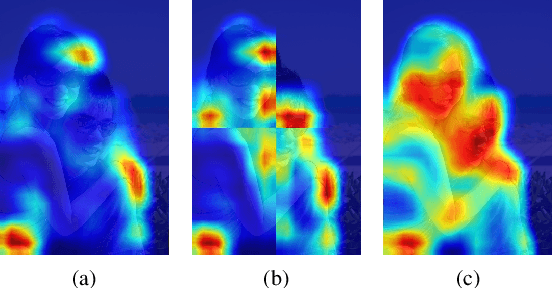
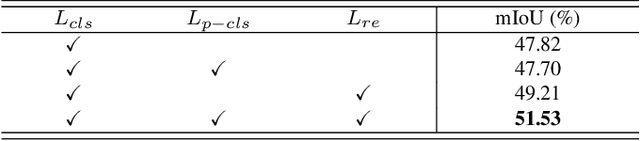
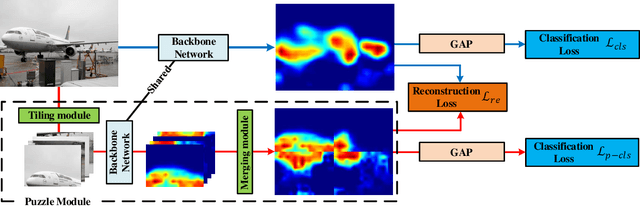
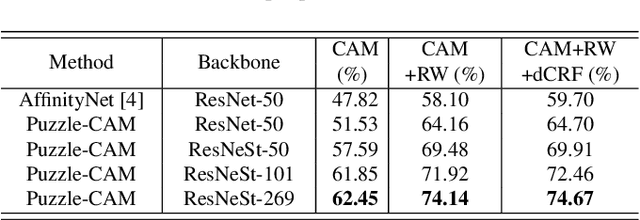
Weakly-supervised semantic segmentation (WSSS) is introduced to narrow the gap for semantic segmentation performance from pixel-level supervision to image-level supervision. Most advanced approaches are based on class activation maps (CAMs) to generate pseudo-labels to train the segmentation network. The main limitation of WSSS is that the process of generating pseudo-labels from CAMs that use an image classifier is mainly focused on the most discriminative parts of the objects. To address this issue, we propose Puzzle-CAM, a process that minimizes differences between the features from separate patches and the whole image. Our method consists of a puzzle module and two regularization terms to discover the most integrated region in an object. Puzzle-CAM can activate the overall region of an object using image-level supervision without requiring extra parameters. % In experiments, Puzzle-CAM outperformed previous state-of-the-art methods using the same labels for supervision on the PASCAL VOC 2012 test dataset. In experiments, Puzzle-CAM outperformed previous state-of-the-art methods using the same labels for supervision on the PASCAL VOC 2012 dataset. Code associated with our experiments is available at \url{https://github.com/OFRIN/PuzzleCAM}.
AIRD: Adversarial Learning Framework for Image Repurposing Detection
Apr 09, 2019
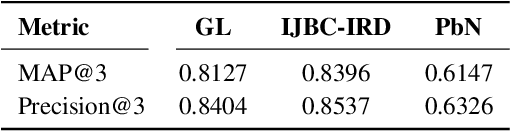
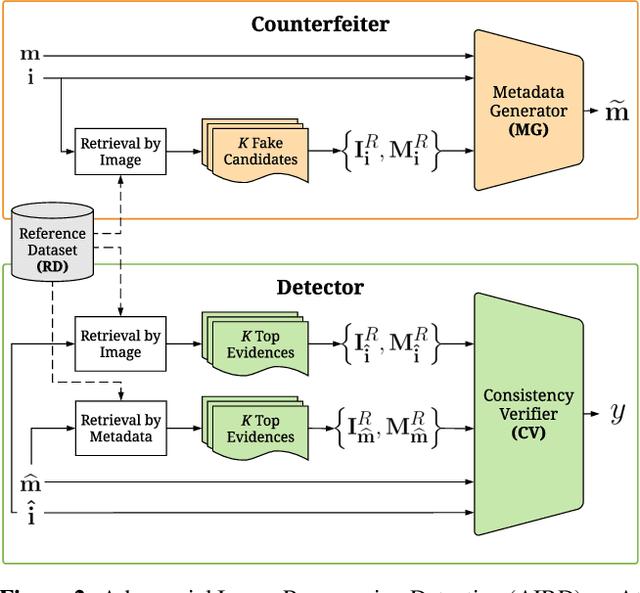
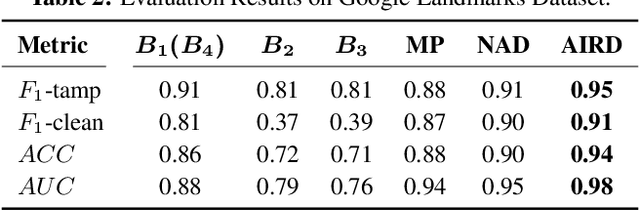
Image repurposing is a commonly used method for spreading misinformation on social media and online forums, which involves publishing untampered images with modified metadata to create rumors and further propaganda. While manual verification is possible, given vast amounts of verified knowledge available on the internet, the increasing prevalence and ease of this form of semantic manipulation call for the development of robust automatic ways of assessing the semantic integrity of multimedia data. In this paper, we present a novel method for image repurposing detection that is based on the real-world adversarial interplay between a bad actor who repurposes images with counterfeit metadata and a watchdog who verifies the semantic consistency between images and their accompanying metadata, where both players have access to a reference dataset of verified content, which they can use to achieve their goals. The proposed method exhibits state-of-the-art performance on location-identity, subject-identity and painting-artist verification, showing its efficacy across a diverse set of scenarios.
Continuous Face Aging via Self-estimated Residual Age Embedding
Apr 30, 2021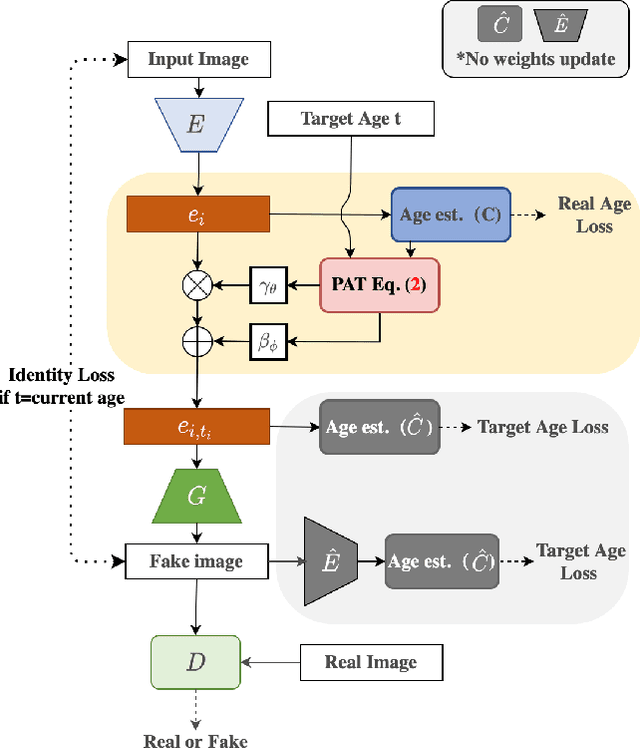
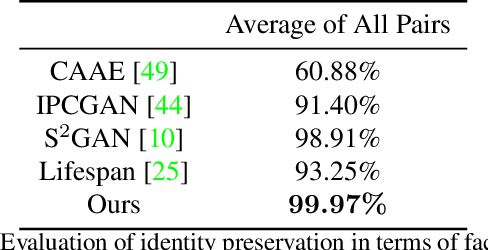


Face synthesis, including face aging, in particular, has been one of the major topics that witnessed a substantial improvement in image fidelity by using generative adversarial networks (GANs). Most existing face aging approaches divide the dataset into several age groups and leverage group-based training strategies, which lacks the ability to provide fine-controlled continuous aging synthesis in nature. In this work, we propose a unified network structure that embeds a linear age estimator into a GAN-based model, where the embedded age estimator is trained jointly with the encoder and decoder to estimate the age of a face image and provide a personalized target age embedding for age progression/regression. The personalized target age embedding is synthesized by incorporating both personalized residual age embedding of the current age and exemplar-face aging basis of the target age, where all preceding aging bases are derived from the learned weights of the linear age estimator. This formulation brings the unified perspective of estimating the age and generating personalized aged face, where self-estimated age embeddings can be learned for every single age. The qualitative and quantitative evaluations on different datasets further demonstrate the significant improvement in the continuous face aging aspect over the state-of-the-art.