 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Agents for Interactive Workflow Provenance: Reference Architecture and Evaluation Methodology
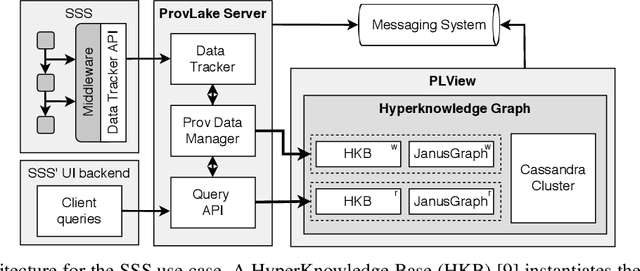
Sep 17, 2025Modern scientific discovery increasingly relies on workflows that process data across the Edge, Cloud, and High Performance Computing (HPC) continuum. Comprehensive and in-depth analyses of these data are critical for hypothesis validation, anomaly detection, reproducibility, and impactful findings. Although workflow provenance techniques support such analyses, at large scale, the provenance data become complex and difficult to analyze. Existing systems depend on custom scripts, structured queries, or static dashboards, limiting data interaction. In this work, we introduce an evaluation methodology, reference architecture, and open-source implementation that leverages interactive Large Language Model (LLM) agents for runtime data analysis. Our approach uses a lightweight, metadata-driven design that translates natural language into structured provenance queries. Evaluations across LLaMA, GPT, Gemini, and Claude, covering diverse query classes and a real-world chemistry workflow, show that modular design, prompt tuning, and Retrieval-Augmented Generation (RAG) enable accurate and insightful LLM agent responses beyond recorded provenance.
Towards Lightweight Data Integration using Multi-workflow Provenance and Data Observability
Aug 17, 2023



Modern large-scale scientific discovery requires multidisciplinary collaboration across diverse computing facilities, including High Performance Computing (HPC) machines and the Edge-to-Cloud continuum. Integrated data analysis plays a crucial role in scientific discovery, especially in the current AI era, by enabling Responsible AI development, FAIR, Reproducibility, and User Steering. However, the heterogeneous nature of science poses challenges such as dealing with multiple supporting tools, cross-facility environments, and efficient HPC execution. Building on data observability, adapter system design, and provenance, we propose MIDA: an approach for lightweight runtime Multi-workflow Integrated Data Analysis. MIDA defines data observability strategies and adaptability methods for various parallel systems and machine learning tools. With observability, it intercepts the dataflows in the background without requiring instrumentation while integrating domain, provenance, and telemetry data at runtime into a unified database ready for user steering queries. We conduct experiments showing end-to-end multi-workflow analysis integrating data from Dask and MLFlow in a real distributed deep learning use case for materials science that runs on multiple environments with up to 276 GPUs in parallel. We show near-zero overhead running up to 100,000 tasks on 1,680 CPU cores on the Summit supercomputer.
* 10 pages, 5 figures, 2 Listings, 42 references, Paper accepted at IEEE eScience'23
Context-aware Execution Migration Tool for Data Science Jupyter Notebooks on Hybrid Clouds
Jul 01, 2021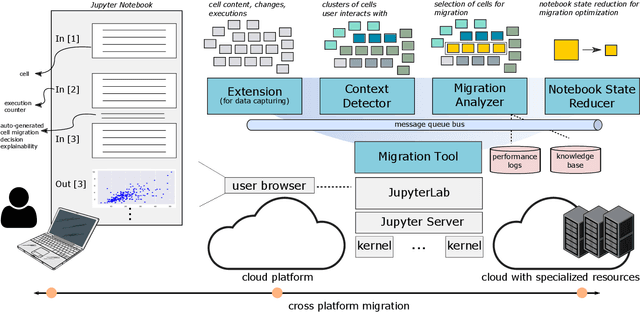
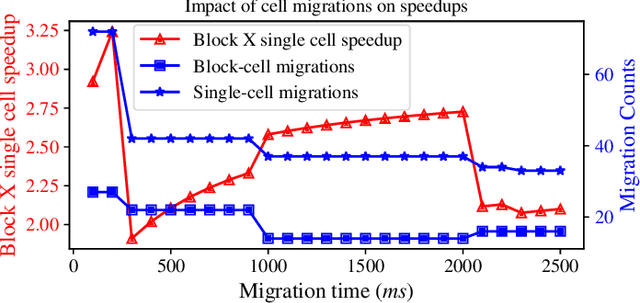
Interactive computing notebooks, such as Jupyter notebooks, have become a popular tool for developing and improving data-driven models. Such notebooks tend to be executed either in the user's own machine or in a cloud environment, having drawbacks and benefits in both approaches. This paper presents a solution developed as a Jupyter extension that automatically selects which cells, as well as in which scenarios, such cells should be migrated to a more suitable platform for execution. We describe how we reduce the execution state of the notebook to decrease migration time and we explore the knowledge of user interactivity patterns with the notebook to determine which blocks of cells should be migrated. Using notebooks from Earth science (remote sensing), image recognition, and hand written digit identification (machine learning), our experiments show notebook state reductions of up to 55x and migration decisions leading to performance gains of up to 3.25x when the user interactivity with the notebook is taken into consideration.
Workflow Provenance in the Lifecycle of Scientific Machine Learning
Sep 30, 2020


Machine Learning (ML) has already fundamentally changed several businesses. More recently, it has also been profoundly impacting the computational science and engineering domains, like geoscience, climate science, and health science. In these domains, users need to perform comprehensive data analyses combining scientific data and ML models to provide for critical requirements, such as reproducibility, model explainability, and experiment data understanding. However, scientific ML is multidisciplinary, heterogeneous, and affected by the physical constraints of the domain, making such analyses even more challenging. In this work, we leverage workflow provenance techniques to build a holistic view to support the lifecycle of scientific ML. We contribute with (i) characterization of the lifecycle and taxonomy for data analyses; (ii) design principles to build this view, with a W3C PROV compliant data representation and a reference system architecture; and (iii) lessons learned after an evaluation in an Oil & Gas case using an HPC cluster with 393 nodes and 946 GPUs. The experiments show that the principles enable queries that integrate domain semantics with ML models while keeping low overhead (<1%), high scalability, and an order of magnitude of query acceleration under certain workloads against without our representation.
Managing Data Lineage of O&G Machine Learning Models: The Sweet Spot for Shale Use Case
Mar 10, 2020
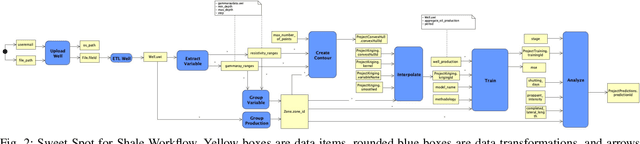
Machine Learning (ML) has increased its role, becoming essential in several industries. However, questions around training data lineage, such as "where has the dataset used to train this model come from?"; the introduction of several new data protection legislation; and, the need for data governance requirements, have hindered the adoption of ML models in the real world. In this paper, we discuss how data lineage can be leveraged to benefit the ML lifecycle to build ML models to discover sweet-spots for shale oil and gas production, a major application in the Oil and Gas O&G Industry.
* Author preprint of paper accepted at the 2020 European Association of Geoscientists and Engineers (EAGE) Digitalization Conference and Exhibition
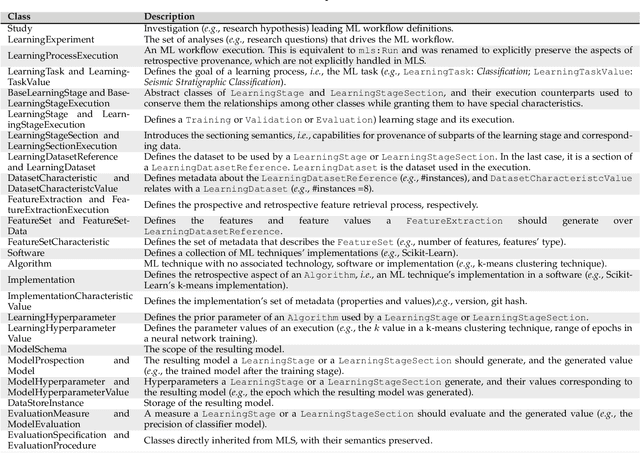
Provenance Data in the Machine Learning Lifecycle in Computational Science and Engineering
Oct 21, 2019
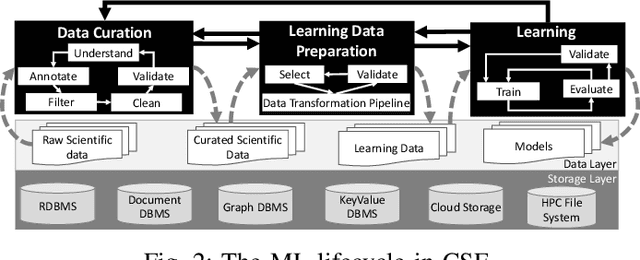
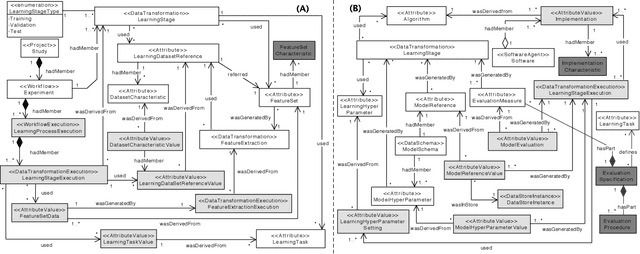
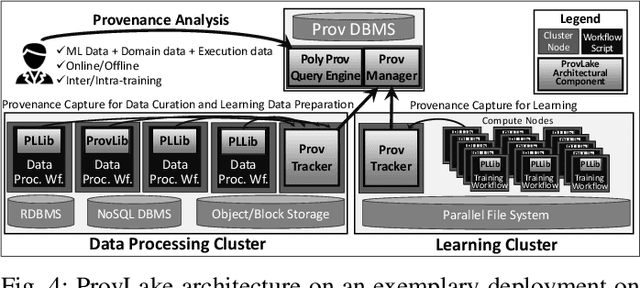
Machine Learning (ML) has become essential in several industries. In Computational Science and Engineering (CSE), the complexity of the ML lifecycle comes from the large variety of data, scientists' expertise, tools, and workflows. If data are not tracked properly during the lifecycle, it becomes unfeasible to recreate a ML model from scratch or to explain to stakeholders how it was created. The main limitation of provenance tracking solutions is that they cannot cope with provenance capture and integration of domain and ML data processed in the multiple workflows in the lifecycle while keeping the provenance capture overhead low. To handle this problem, in this paper we contribute with a detailed characterization of provenance data in the ML lifecycle in CSE; a new provenance data representation, called PROV-ML, built on top of W3C PROV and ML Schema; and extensions to a system that tracks provenance from multiple workflows to address the characteristics of ML and CSE, and to allow for provenance queries with a standard vocabulary. We show a practical use in a real case in the Oil and Gas industry, along with its evaluation using 48 GPUs in parallel.
A Hybrid Architecture for Multi-Party Conversational Systems
May 04, 2017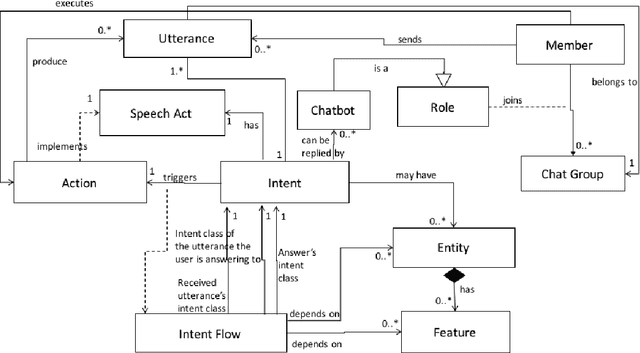
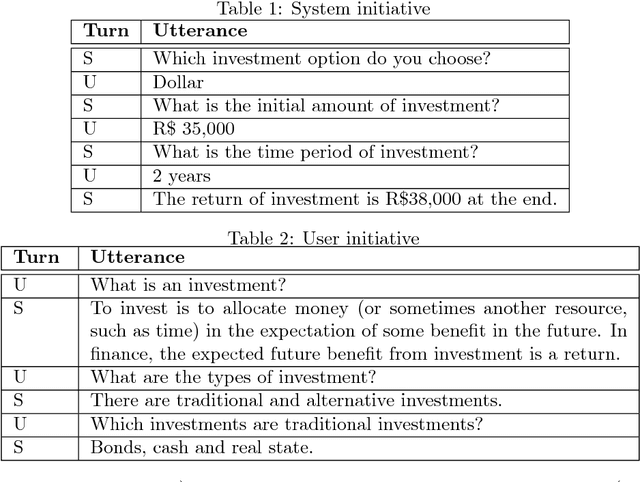
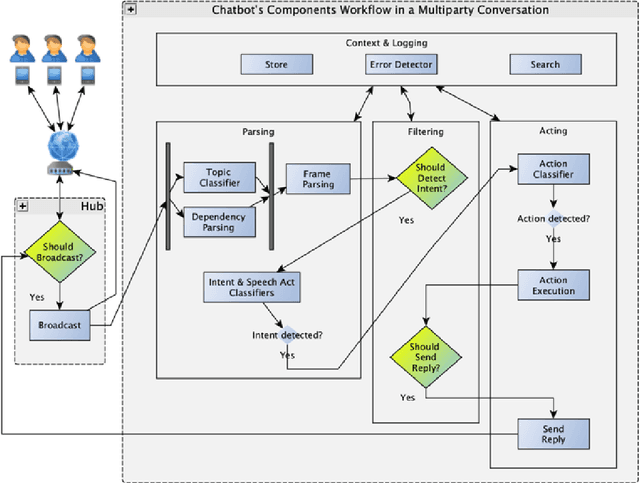
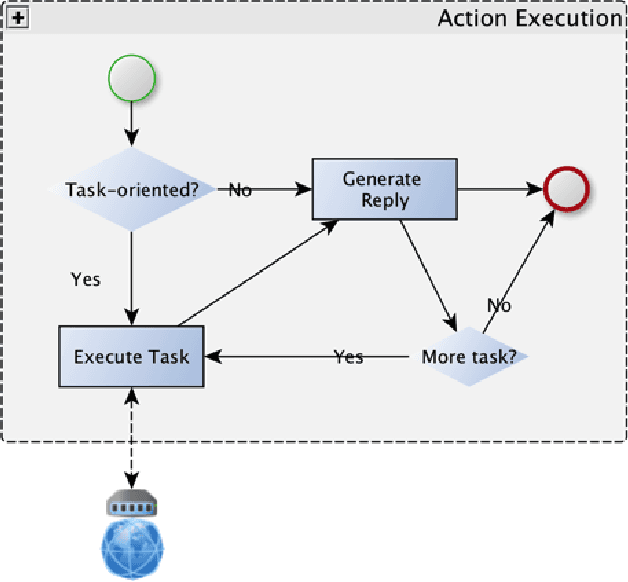
Multi-party Conversational Systems are systems with natural language interaction between one or more people or systems. From the moment that an utterance is sent to a group, to the moment that it is replied in the group by a member, several activities must be done by the system: utterance understanding, information search, reasoning, among others. In this paper we present the challenges of designing and building multi-party conversational systems, the state of the art, our proposed hybrid architecture using both rules and machine learning and some insights after implementing and evaluating one on the finance domain.