 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Integrating Heuristics and Learning in a Computational Architecture for Cognitive Trading
Aug 27, 2021
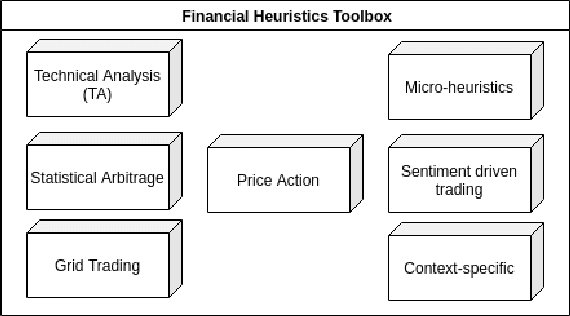
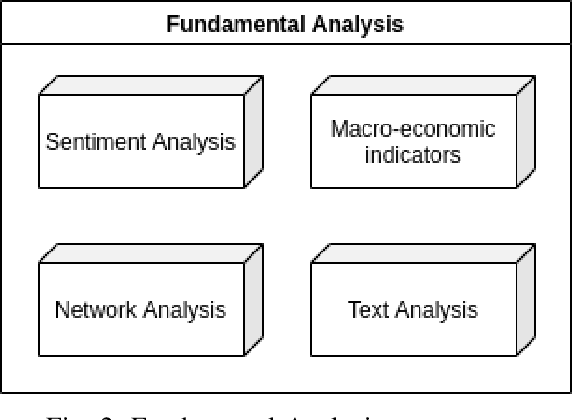
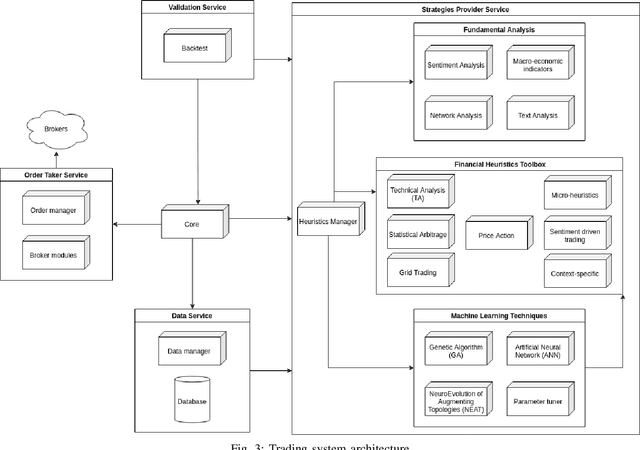
The successes of Artificial Intelligence in recent years in areas such as image analysis, natural language understanding and strategy games have sparked interest from the world of finance. Specifically, there are high expectations, and ongoing engineering projects, regarding the creation of artificial agents, known as robotic traders, capable of juggling the financial markets with the skill of experienced human traders. Obvious economic implications aside, this is certainly an area of great scientific interest, due to the challenges that such a real context poses to the use of AI techniques. Precisely for this reason, we must be aware that artificial agents capable of operating at such levels are not just round the corner, and that there will be no simple answers, but rather a concurrence of various technologies and methods to the success of the effort. In the course of this article, we review the issues inherent in the design of effective robotic traders as well as the consequently applicable solutions, having in view the general objective of bringing the current state of the art of robo-trading up to the next level of intelligence, which we refer to as Cognitive Trading. Key to our approach is the joining of two methodological and technological directions which, although both deeply rooted in the disciplinary field of artificial intelligence, have so far gone their separate ways: heuristics and learning.
ChangeChip: A Reference-Based Unsupervised Change Detection for PCB Defect Detection
Sep 13, 2021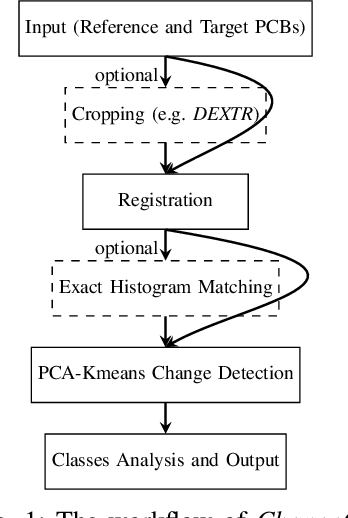



The usage of electronic devices increases, and becomes predominant in most aspects of life. Surface Mount Technology (SMT) is the most common industrial method for manufacturing electric devices in which electrical components are mounted directly onto the surface of a Printed Circuit Board (PCB). Although the expansion of electronic devices affects our lives in a productive way, failures or defects in the manufacturing procedure of those devices might also be counterproductive and even harmful in some cases. It is therefore desired and sometimes crucial to ensure zero-defect quality in electronic devices and their production. While traditional Image Processing (IP) techniques are not sufficient to produce a complete solution, other promising methods like Deep Learning (DL) might also be challenging for PCB inspection, mainly because such methods require big adequate datasets which are missing, not available or not updated in the rapidly growing field of PCBs. Thus, PCB inspection is conventionally performed manually by human experts. Unsupervised Learning (UL) methods may potentially be suitable for PCB inspection, having learning capabilities on the one hand, while not relying on large datasets on the other. In this paper, we introduce ChangeChip, an automated and integrated change detection system for defect detection in PCBs, from soldering defects to missing or misaligned electronic elements, based on Computer Vision (CV) and UL. We achieve good quality defect detection by applying an unsupervised change detection between images of a golden PCB (reference) and the inspected PCB under various setting. In this work, we also present CD-PCB, a synthesized labeled dataset of 20 pairs of PCB images for evaluation of defect detection algorithms.
Self-Supervised Multi-Modal Alignment for Whole Body Medical Imaging
Aug 06, 2021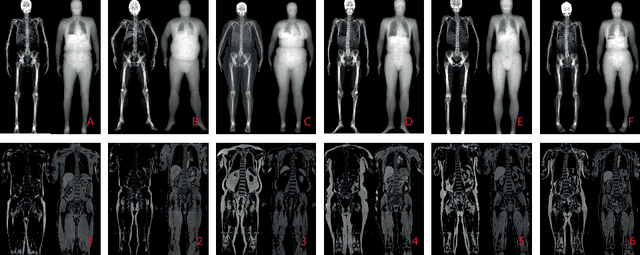
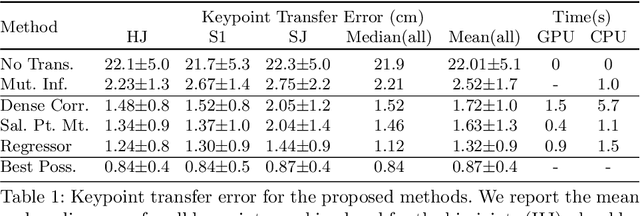
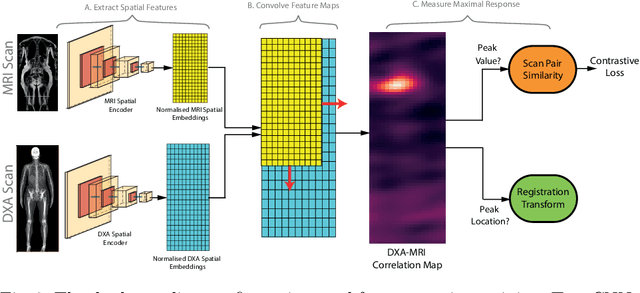
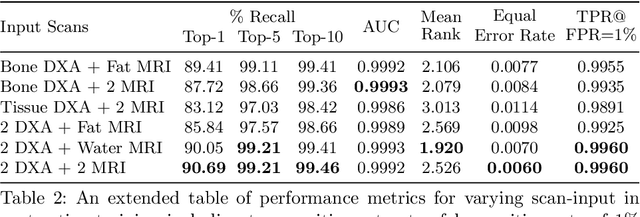
This paper explores the use of self-supervised deep learning in medical imaging in cases where two scan modalities are available for the same subject. Specifically, we use a large publicly-available dataset of over 20,000 subjects from the UK Biobank with both whole body Dixon technique magnetic resonance (MR) scans and also dual-energy x-ray absorptiometry (DXA) scans. We make three contributions: (i) We introduce a multi-modal image-matching contrastive framework, that is able to learn to match different-modality scans of the same subject with high accuracy. (ii) Without any adaption, we show that the correspondences learnt during this contrastive training step can be used to perform automatic cross-modal scan registration in a completely unsupervised manner. (iii) Finally, we use these registrations to transfer segmentation maps from the DXA scans to the MR scans where they are used to train a network to segment anatomical regions without requiring ground-truth MR examples. To aid further research, our code will be made publicly available.
Efficient Certified Defenses Against Patch Attacks on Image Classifiers
Feb 08, 2021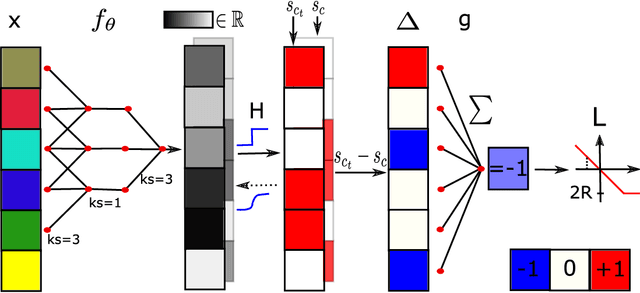

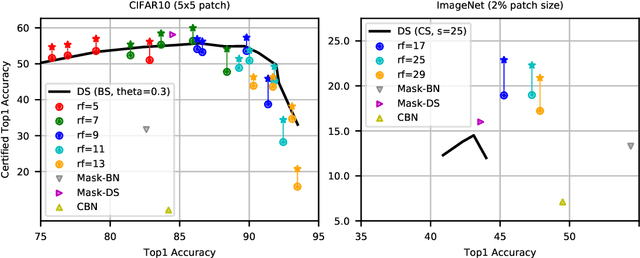
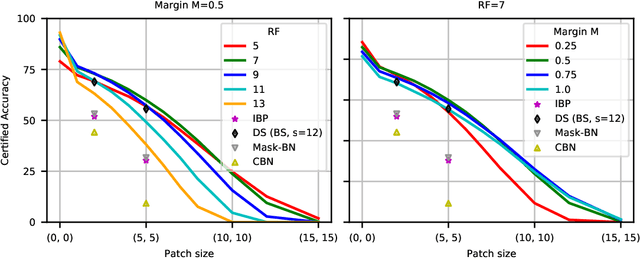
Adversarial patches pose a realistic threat model for physical world attacks on autonomous systems via their perception component. Autonomous systems in safety-critical domains such as automated driving should thus contain a fail-safe fallback component that combines certifiable robustness against patches with efficient inference while maintaining high performance on clean inputs. We propose BagCert, a novel combination of model architecture and certification procedure that allows efficient certification. We derive a loss that enables end-to-end optimization of certified robustness against patches of different sizes and locations. On CIFAR10, BagCert certifies 10.000 examples in 43 seconds on a single GPU and obtains 86% clean and 60% certified accuracy against 5x5 patches.
An Image Segmentation Model Based on a Variational Formulation
Oct 13, 2019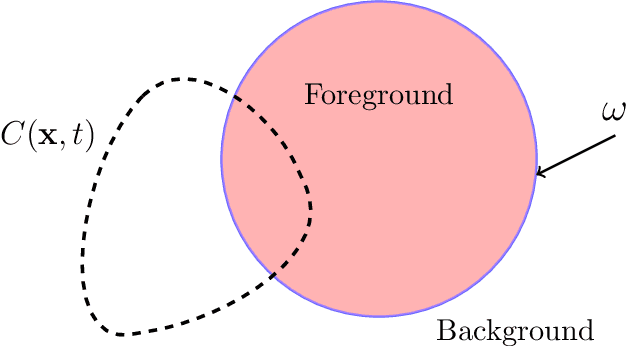


Starting from a variational formulation, we present a model for image segmentation that employs both region statistics and edge information. This combination allows for improved flexibility, making the proposed model suitable to process a wider class of images than purely region-based and edge-based models. We perform several simulations with real images that attest to the versatility of the model. We also show another set of experiments on images with certain pathologies that suggest opportunities for improvement.
Pyramid Real Image Denoising Network
Aug 01, 2019
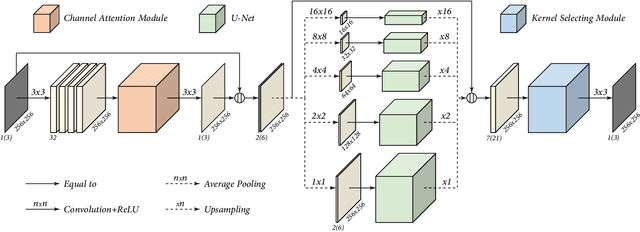
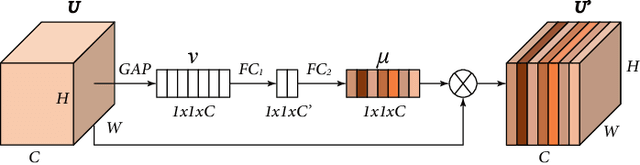
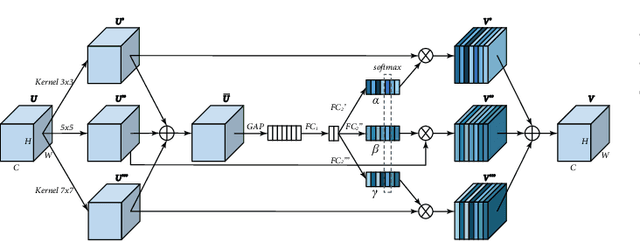
While deep Convolutional Neural Networks (CNNs) have shown extraordinary capability of modelling specific noise and denoising, they still perform poorly on real-world noisy images. The main reason is that the real-world noise is more sophisticated and diverse. To tackle the issue of blind denoising, in this paper, we propose a novel pyramid real image denoising network (PRIDNet), which contains three stages. First, the noise estimation stage uses channel attention mechanism to recalibrate the channel importance of input noise. Second, at the multi-scale denoising stage, pyramid pooling is utilized to extract multi-scale features. Third, the stage of feature fusion adopts a kernel selecting operation to adaptively fuse multi-scale features. Experiments on two datasets of real noisy photographs demonstrate that our approach can achieve competitive performance in comparison with state-of-the-art denoisers in terms of both quantitative measure and visual perception quality.
NLH: A Blind Pixel-level Non-local Method for Real-world Image Denoising
Jul 04, 2019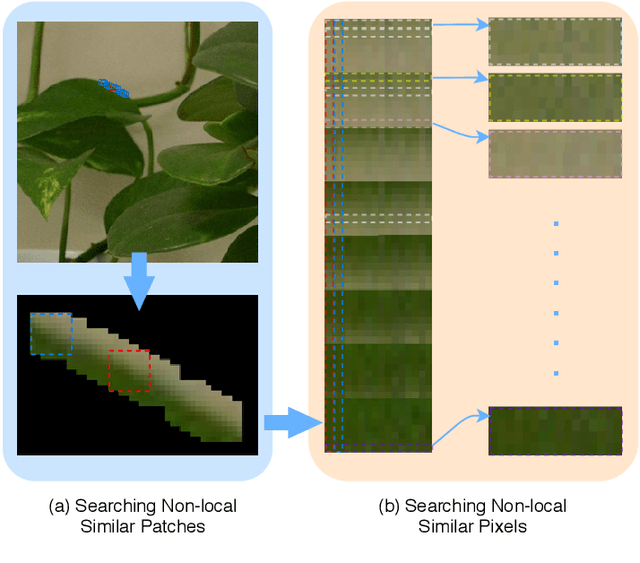
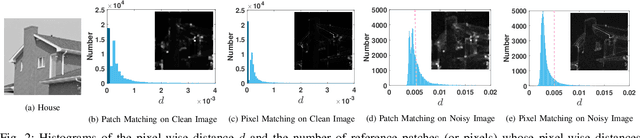
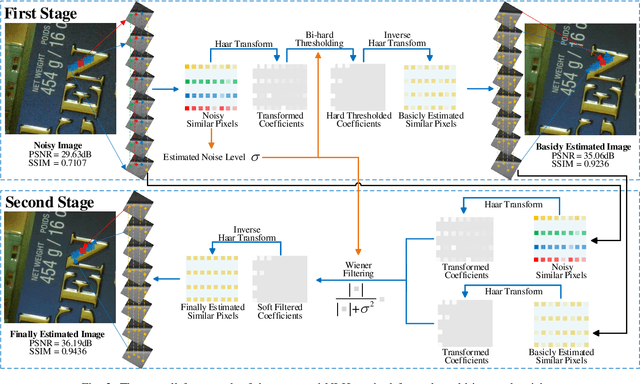

Non-local self similarity (NSS) is a powerful prior of natural images for image denoising. Most of existing denoising methods employ similar patches, which is a patch-level NSS prior. In this paper, we take one step forward by introducing a pixel-level NSS prior, i.e., searching similar pixels across a non-local region. This is motivated by the fact that finding closely similar pixels is more feasible than similar patches in natural images, which can be used to enhance image denoising performance. With the introduced pixel-level NSS prior, we propose an accurate noise level estimation method, and then develop a blind image denoising method based on the lifting Haar transform and Wiener filtering techniques. Experiments on benchmark datasets demonstrate that, the proposed method achieves much better performance than state-of-the-art methods on real-world image denoising. The code will be released.
On Out-of-distribution Detection with Energy-based Models
Jul 03, 2021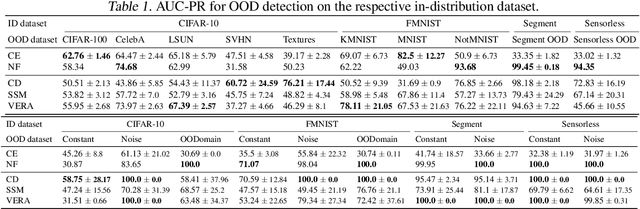
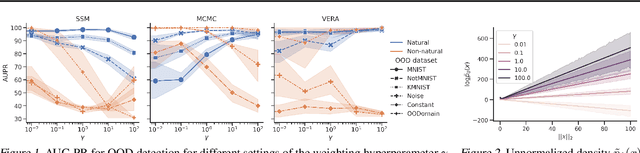
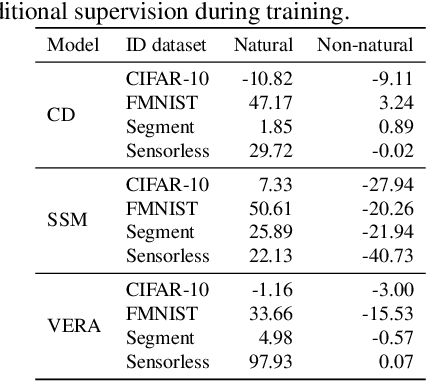
Several density estimation methods have shown to fail to detect out-of-distribution (OOD) samples by assigning higher likelihoods to anomalous data. Energy-based models (EBMs) are flexible, unnormalized density models which seem to be able to improve upon this failure mode. In this work, we provide an extensive study investigating OOD detection with EBMs trained with different approaches on tabular and image data and find that EBMs do not provide consistent advantages. We hypothesize that EBMs do not learn semantic features despite their discriminative structure similar to Normalizing Flows. To verify this hypotheses, we show that supervision and architectural restrictions improve the OOD detection of EBMs independent of the training approach.
Integrative Use of Computer Vision and Unmanned Aircraft Technologies in Public Inspection: Foreign Object Debris Image Collection
Jun 01, 2021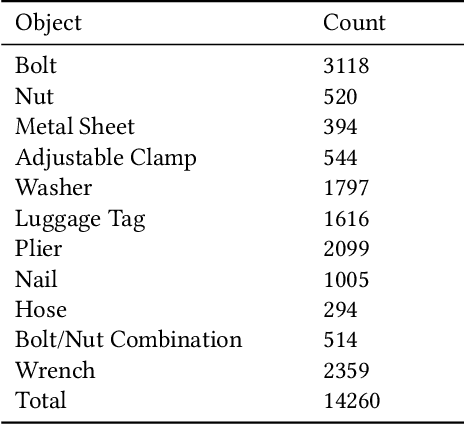

Unmanned Aircraft Systems (UAS) have become an important resource for public service providers and smart cities. The purpose of this study is to expand this research area by integrating computer vision and UAS technology to automate public inspection. As an initial case study for this work, a dataset of common foreign object debris (FOD) is developed to assess the potential of light-weight automated detection. This paper presents the rationale and creation of this dataset. Future iterations of our work will include further technical details analyzing experimental implementation. At a local airport, UAS and portable cameras are used to collect the data contained in the initial version of this dataset. After collecting these videos of FOD, they were split into individual frames and stored as several thousand images. These frames are then annotated following standard computer vision format and stored in a folder-structure that reflects our creation method. The dataset annotations are validated using a custom tool that could be abstracted to fit future applications. Initial detection models were successfully created using the famous You Only Look Once algorithm, which indicates the practicality of the proposed data. Finally, several potential scenarios that could utilize either this dataset or similar methods for other public service are presented.
PDC: Piecewise Depth Completion utilizing Superpixels
Jul 14, 2021



Depth completion from sparse LiDAR and high-resolution RGB data is one of the foundations for autonomous driving techniques. Current approaches often rely on CNN-based methods with several known drawbacks: flying pixel at depth discontinuities, overfitting to both a given data set as well as error metric, and many more. Thus, we propose our novel Piecewise Depth Completion (PDC), which works completely without deep learning. PDC segments the RGB image into superpixels corresponding the regions with similar depth value. Superpixels corresponding to same objects are gathered using a cost map. At the end, we receive detailed depth images with state of the art accuracy. In our evaluation, we can show both the influence of the individual proposed processing steps and the overall performance of our method on the challenging KITTI dataset.