 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Event-driven Vision and Control for UAVs on a Neuromorphic Chip
Aug 08, 2021

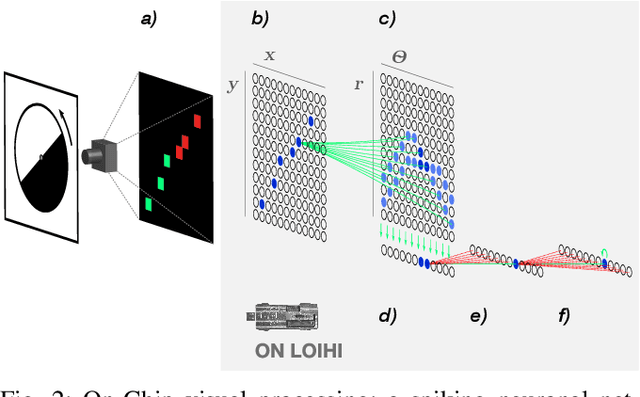
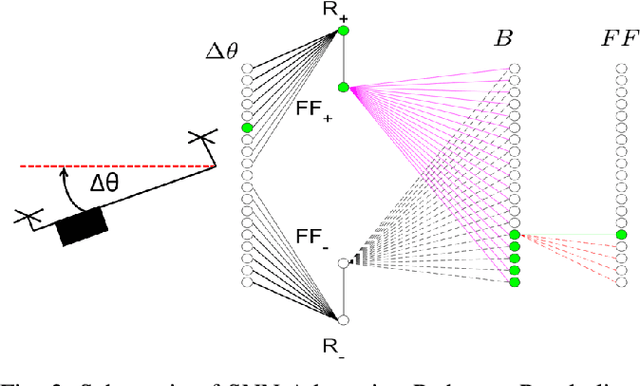
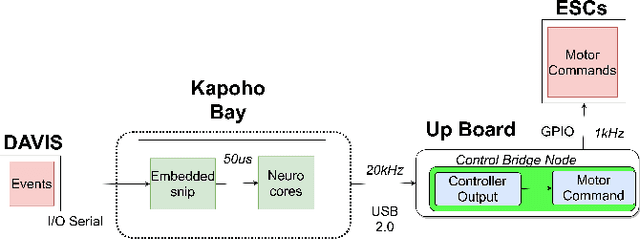
Event-based vision sensors achieve up to three orders of magnitude better speed vs. power consumption trade off in high-speed control of UAVs compared to conventional image sensors. Event-based cameras produce a sparse stream of events that can be processed more efficiently and with a lower latency than images, enabling ultra-fast vision-driven control. Here, we explore how an event-based vision algorithm can be implemented as a spiking neuronal network on a neuromorphic chip and used in a drone controller. We show how seamless integration of event-based perception on chip leads to even faster control rates and lower latency. In addition, we demonstrate how online adaptation of the SNN controller can be realised using on-chip learning. Our spiking neuronal network on chip is the first example of a neuromorphic vision-based controller solving a high-speed UAV control task. The excellent scalability of processing in neuromorphic hardware opens the possibility to solve more challenging visual tasks in the future and integrate visual perception in fast control loops.
Classifying Image Sequences of Astronomical Transients with Deep Neural Networks
Apr 28, 2020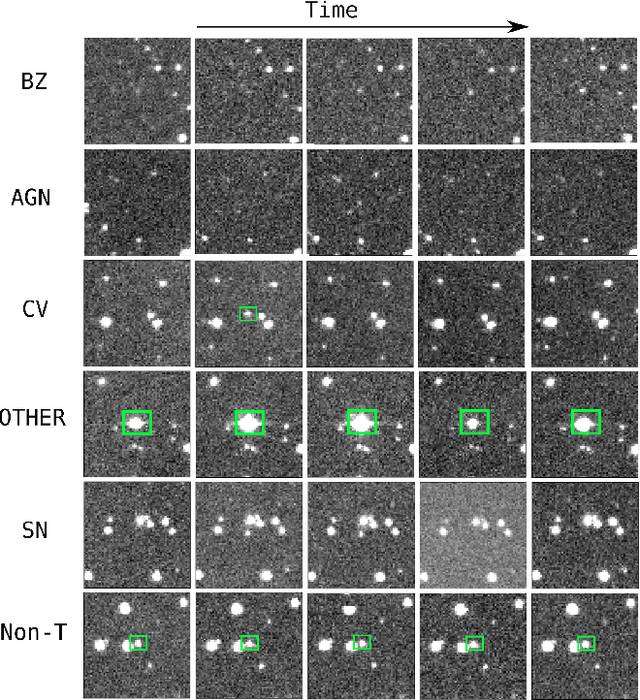


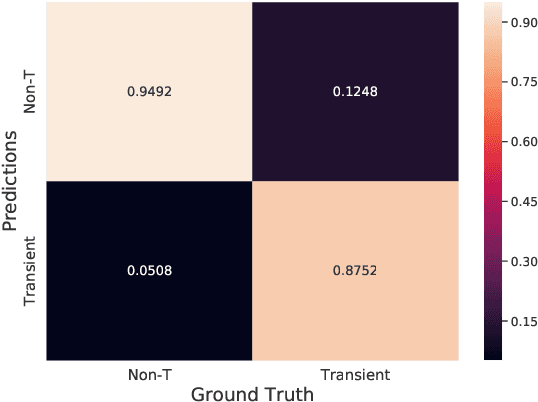
Supervised classification of temporal sequences of astronomical images into meaningful transient astrophysical phenomena has been considered a hard problem because it requires the intervention of human experts. The classifier uses the expert's knowledge to find heuristic features to process the images, for instance, by performing image subtraction or by extracting sparse information such as flux time series in the form of light curves. We present a successful deep learning approach that learns directly from imaging data. Our method models explicitly the spatio-temporal patterns with Deep Convolutional Neural Networks and Gated Recurrent Units. We train these deep neural networks using 1.3 million real astronomical images from the Catalina Real-Time Transient Survey to classify the sequences into five different types of astronomical transient classes. The TAO-Net (for Transient Astronomical Objects Network) architecture achieves on the five-type classification task an average F1-score of 54.58$\pm$13.32, almost nine points higher than the F1-score of 45.49 $\pm$ 13.75 from the random forest classification on light curves. The achievement TAO-Net opens the possibility to develop new deep-learning architectures for early transient detection. We make available the training dataset and trained models of TAO-Net to allow for future extensions of this work.
Gastric histopathology image segmentation using a hierarchical conditional random field
Mar 04, 2020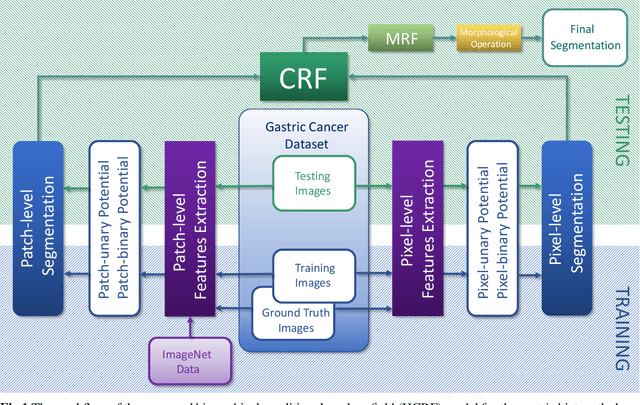

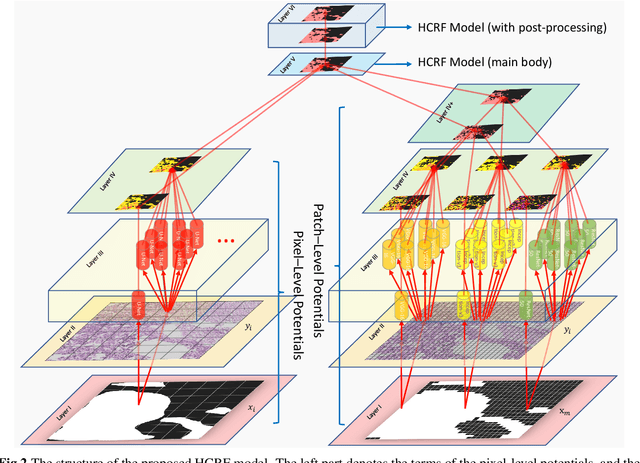

In this paper, a Hierarchical Conditional Random Field (HCRF) model based Gastric Histopathology Image Segmentation (GHIS) method is proposed, which can localize abnormal (cancer) regions in gastric histopathology images obtained by optical microscope to assist histopathologists in medical work. First, to obtain pixel-level segmentation information, we retrain a Convolutional Neural Network (CNN) to build up our pixel-level potentials. Then, in order to obtain abundant spatial segmentation information in patch-level, we fine-tune another three CNNs to build up our patch-level potentials. Thirdly, based on the pixel- and patch-level potentials, our HCRF model is structured. Finally, graph-based post-processing is applied to further improve our segmentation performance. In the experiment, a segmentation accuracy of 78.91% is achieved on a Hematoxylin and Eosin (H&E) stained gastric histopathological dataset with 560 images, showing the effectiveness and future potential of the proposed GHIS method.
Learned Spatial Representations for Few-shot Talking-Head Synthesis
Apr 29, 2021
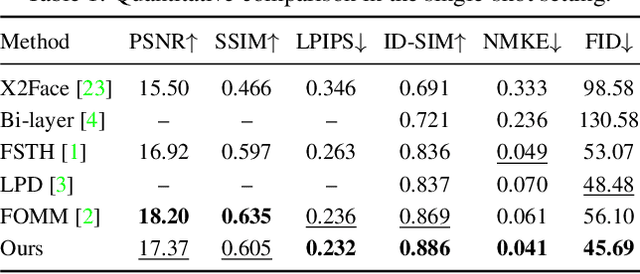
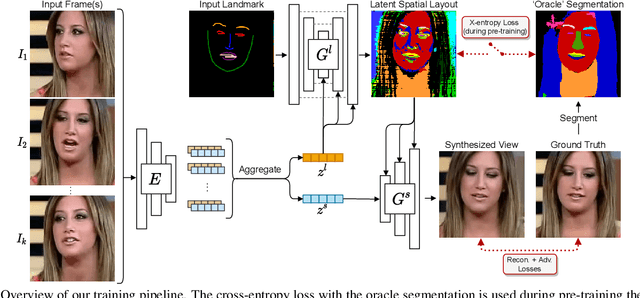
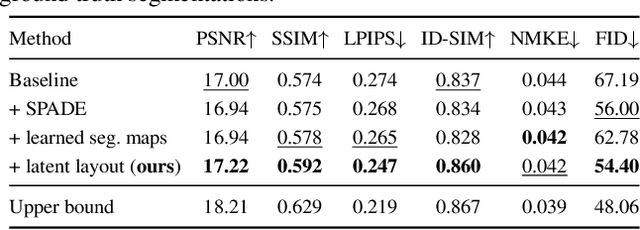
We propose a novel approach for few-shot talking-head synthesis. While recent works in neural talking heads have produced promising results, they can still produce images that do not preserve the identity of the subject in source images. We posit this is a result of the entangled representation of each subject in a single latent code that models 3D shape information, identity cues, colors, lighting and even background details. In contrast, we propose to factorize the representation of a subject into its spatial and style components. Our method generates a target frame in two steps. First, it predicts a dense spatial layout for the target image. Second, an image generator utilizes the predicted layout for spatial denormalization and synthesizes the target frame. We experimentally show that this disentangled representation leads to a significant improvement over previous methods, both quantitatively and qualitatively.
Using Adaptive Gradient for Texture Learning in Single-View 3D Reconstruction
Apr 29, 2021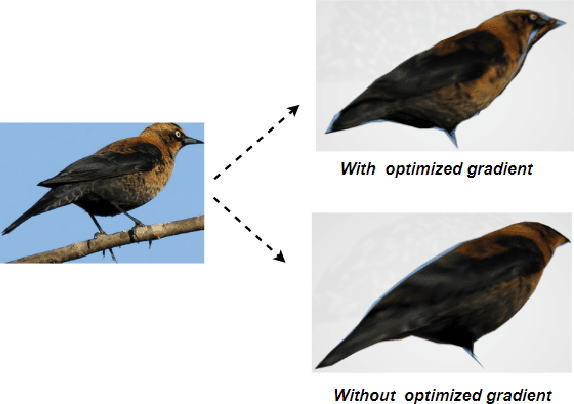
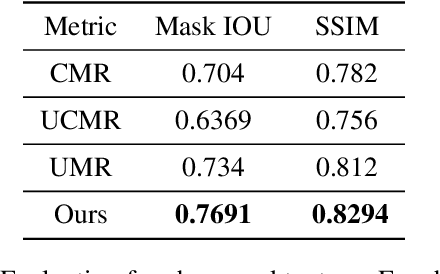
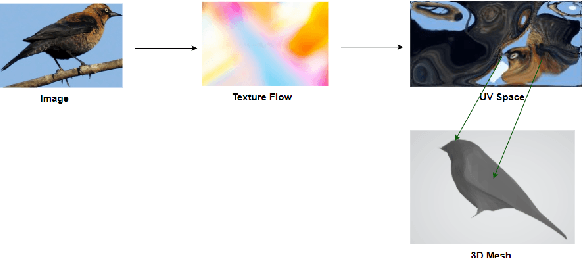
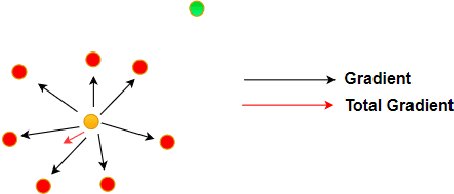
Recently, learning-based approaches for 3D model reconstruction have attracted attention owing to its modern applications such as Extended Reality(XR), robotics and self-driving cars. Several approaches presented good performance on reconstructing 3D shapes by learning solely from images, i.e., without using 3D models in training. Challenges, however, remain in texture generation due to the gap between 2D and 3D modals. In previous work, the grid sampling mechanism from Spatial Transformer Networks was adopted to sample color from an input image to formulate texture. Despite its success, the existing framework has limitations on searching scope in sampling, resulting in flaws in generated texture and consequentially on rendered 3D models. In this paper, to solve that issue, we present a novel sampling algorithm by optimizing the gradient of predicted coordinates based on the variance on the sampling image. Taking into account the semantics of the image, we adopt Frechet Inception Distance (FID) to form a loss function in learning, which helps bridging the gap between rendered images and input images. As a result, we greatly improve generated texture. Furthermore, to optimize 3D shape reconstruction and to accelerate convergence at training, we adopt part segmentation and template learning in our model. Without any 3D supervision in learning, and with only a collection of single-view 2D images, the shape and texture learned by our model outperform those from previous work. We demonstrate the performance with experimental results on a publically available dataset.
Image Enhancement Network Trained by Using HDR images
Jan 25, 2019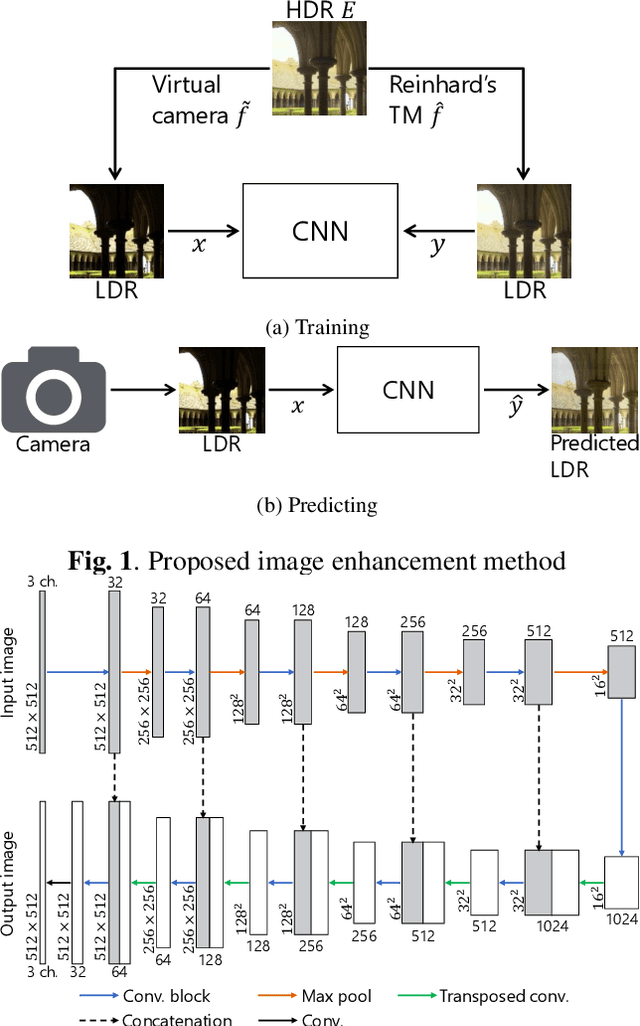

In this paper, a novel image enhancement network is proposed, where HDR images are used for generating training data for our network. Most of conventional image enhancement methods, including Retinex based methods, do not take into account restoring lost pixel values caused by clipping and quantizing. In addition, recently proposed CNN based methods still have a limited scope of application or a limited performance, due to network architectures. In contrast, the proposed method have a higher performance and a simpler network architecture than existing CNN based methods. Moreover, the proposed method enables us to restore lost pixel values. Experimental results show that the proposed method can provides higher-quality images than conventional image enhancement methods including a CNN based method, in terms of TMQI and NIQE.
Generalized Rank Minimization based Group Sparse Coding for Low-level Image Restoration via Dictionary Learning
Jul 13, 2019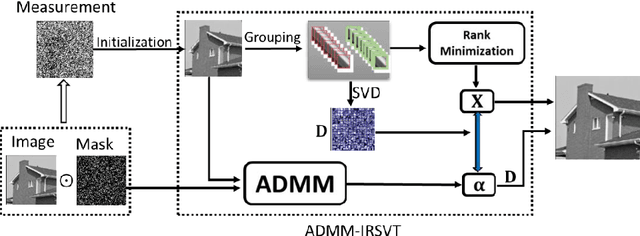
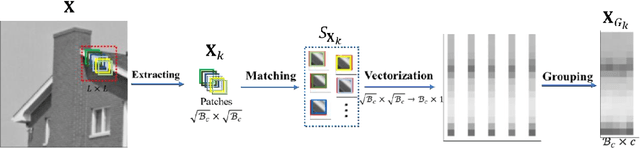


Recently, low-rank matrix recovery theory has been emerging as a significant progress for various image processing problems. Meanwhile, the group sparse coding (GSC) theory has led to great successes in image restoration with group contains low-rank property. In this paper, we introduce a novel GSC framework using generalized rank minimization for image restoration tasks via an effective adaptive dictionary learning scheme. For a more accurate approximation of the rank of group matrix, we proposed a generalized rank minimization model with a generalized and flexible weighted scheme and the generalized nonconvex nonsmooth relaxation function. Then an efficient generalized iteratively reweighted singular-value function thresholding (GIR-SFT) algorithm is proposed to handle the resulting minimization problem of GSC. Our proposed model is connected to image restoration (IR) problems via an alternating direction method of multipliers (ADMM) strategy. Extensive experiments on typical IR problems of image compressive sensing (CS) reconstruction, inpainting, deblurring and impulsive noise removal demonstrate that our proposed GSC framework can enhance the image restoration quality compared with many state-of-the-art methods.
Learning deep multiresolution representations for pansharpening
Feb 16, 2021



Retaining spatial characteristics of panchromatic image and spectral information of multispectral bands is a critical issue in pansharpening. This paper proposes a pyramid based deep fusion framework that preserves spectral and spatial characteristics at different scales. The spectral information is preserved by passing the corresponding low resolution multispectral image as residual component of the network at each scale. The spatial information is preserved by training the network at each scale with the high frequencies of panchromatic image alongside the corresponding low resolution multispectral image. The parameters of different networks are shared across the pyramid in order to add spatial details consistently across scales. The parameters are also shared across fusion layers within a network at a specific scale. Experiments suggest that the proposed architecture outperforms state of the art pansharpening models. The proposed model, code and dataset is publicly available at https://github.com/sohaibali01/deep_pyramid_fusion.
Transformers with multi-modal features and post-fusion context for e-commerce session-based recommendation
Jul 11, 2021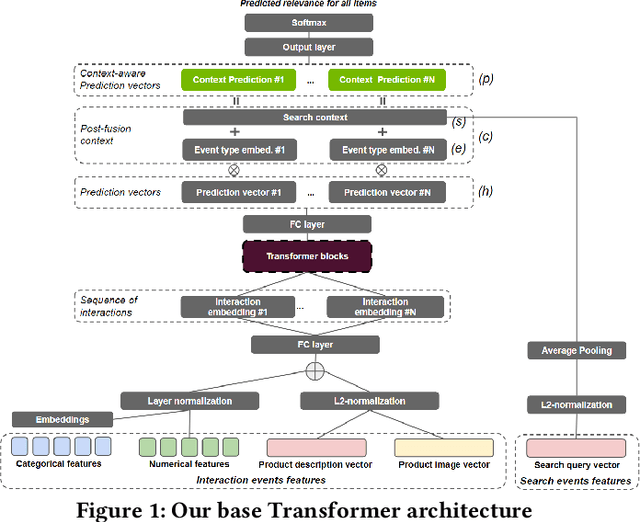
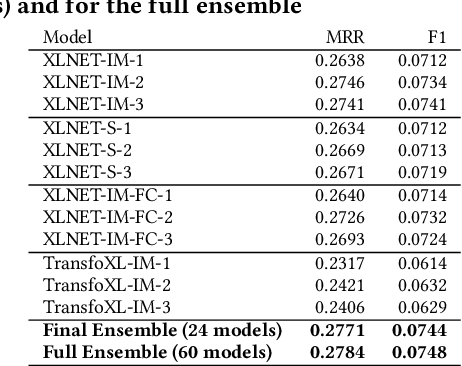
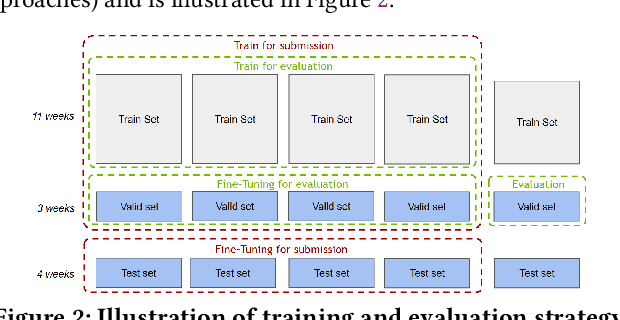
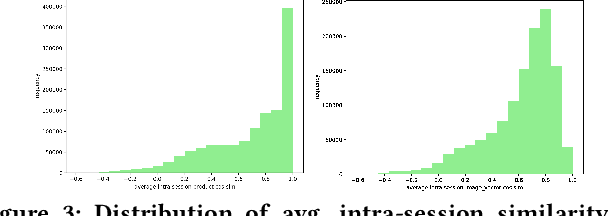
Session-based recommendation is an important task for e-commerce services, where a large number of users browse anonymously or may have very distinct interests for different sessions. In this paper we present one of the winning solutions for the Recommendation task of the SIGIR 2021 Workshop on E-commerce Data Challenge. Our solution was inspired by NLP techniques and consists of an ensemble of two Transformer architectures - Transformer-XL and XLNet - trained with autoregressive and autoencoding approaches. To leverage most of the rich dataset made available for the competition, we describe how we prepared multi-model features by combining tabular events with textual and image vectors. We also present a model prediction analysis to better understand the effectiveness of our architectures for the session-based recommendation.
Generalization Error Analysis of Neural networks with Gradient Based Regularization
Jul 06, 2021
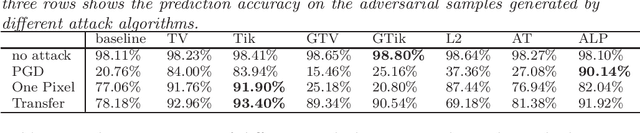

We study gradient-based regularization methods for neural networks. We mainly focus on two regularization methods: the total variation and the Tikhonov regularization. Applying these methods is equivalent to using neural networks to solve some partial differential equations, mostly in high dimensions in practical applications. In this work, we introduce a general framework to analyze the generalization error of regularized networks. The error estimate relies on two assumptions on the approximation error and the quadrature error. Moreover, we conduct some experiments on the image classification tasks to show that gradient-based methods can significantly improve the generalization ability and adversarial robustness of neural networks. A graphical extension of the gradient-based methods are also considered in the experiments.