 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Joint Hand-object 3D Reconstruction from a Single Image with Cross-branch Feature Fusion
Jun 28, 2020
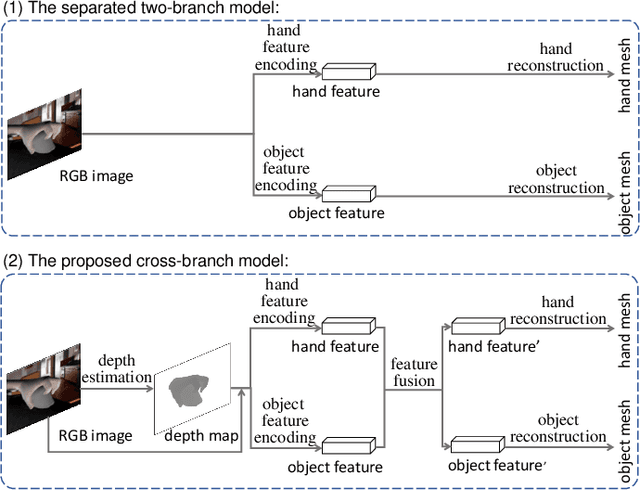

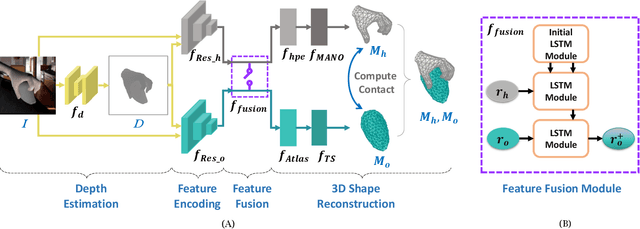
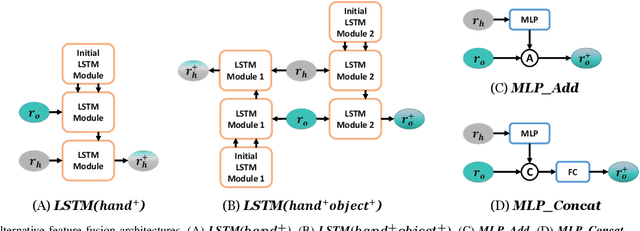
Accurate 3D reconstruction of the hand and object shape from a hand-object image is important for understanding human-object interaction as well as human daily activities. Different from bare hand pose estimation, hand-object interaction poses a strong constraint on both the hand and its manipulated object, which suggests that hand configuration may be crucial contextual information for the object, and vice versa. However, current approaches address this task by training a two-branch network to reconstruct the hand and object separately with little communication between the two branches. In this work, we propose to consider hand and object jointly in feature space and explore the reciprocity of the two branches. We extensively investigate cross-branch feature fusion architectures with MLP or LSTM units. Among the investigated architectures, a variant with LSTM units that enhances object feature with hand feature shows the best performance gain. Moreover, we employ an auxiliary depth estimation module to augment the input RGB image with the estimated depth map, which further improves the reconstruction accuracy. Experiments conducted on public datasets demonstrate that our approach significantly outperforms existing approaches in terms of the reconstruction accuracy of objects.
Long-Short Temporal Contrastive Learning of Video Transformers
Jul 08, 2021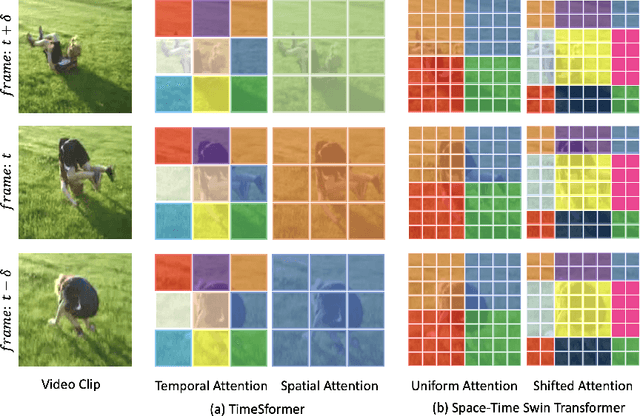

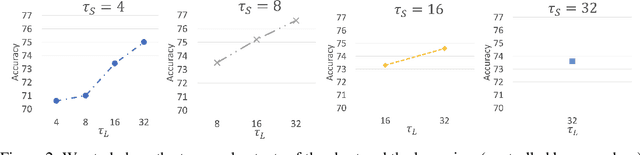
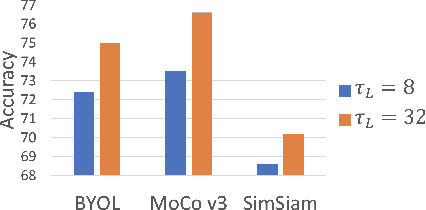
Video transformers have recently emerged as a competitive alternative to 3D CNNs for video understanding. However, due to their large number of parameters and reduced inductive biases, these models require supervised pretraining on large-scale image datasets to achieve top performance. In this paper, we empirically demonstrate that self-supervised pretraining of video transformers on video-only datasets can lead to action recognition results that are on par or better than those obtained with supervised pretraining on large-scale image datasets, even massive ones such as ImageNet-21K. Since transformer-based models are effective at capturing dependencies over extended temporal spans, we propose a simple learning procedure that forces the model to match a long-term view to a short-term view of the same video. Our approach, named Long-Short Temporal Contrastive Learning (LSTCL), enables video transformers to learn an effective clip-level representation by predicting temporal context captured from a longer temporal extent. To demonstrate the generality of our findings, we implement and validate our approach under three different self-supervised contrastive learning frameworks (MoCo v3, BYOL, SimSiam) using two distinct video-transformer architectures, including an improved variant of the Swin Transformer augmented with space-time attention. We conduct a thorough ablation study and show that LSTCL achieves competitive performance on multiple video benchmarks and represents a convincing alternative to supervised image-based pretraining.
Estimating a Null Model of Scientific Image Reuse to Support Research Integrity Investigations
Feb 22, 2020



When there is a suspicious figure reuse case in science, research integrity investigators often find it difficult to rebut authors claiming that "it happened by chance". In other words, when there is a "collision" of image features, it is difficult to justify whether it appears rarely or not. In this article, we provide a method to predict the rarity of an image feature by statistically estimating the chance of it randomly occurring across all scientific imagery. Our method is based on high-dimensional density estimation of ORB features using 7+ million images in the PubMed Open Access Subset dataset. We show that this method can lead to meaningful feedback during research integrity investigations by providing a null hypothesis for scientific image reuse and thus a p-value during deliberations. We apply the model to a sample of increasingly complex imagery and confirm that it produces decreasingly smaller p-values as expected. We discuss applications to research integrity investigations as well as future work.
Field-Based Plot Extraction Using UAV RGB Images
Sep 01, 2021


Unmanned Aerial Vehicles (UAVs) have become popular for use in plant phenotyping of field based crops, such as maize and sorghum, due to their ability to acquire high resolution data over field trials. Field experiments, which may comprise thousands of plants, are planted according to experimental designs to evaluate varieties or management practices. For many types of phenotyping analysis, we examine smaller groups of plants known as "plots." In this paper, we propose a new plot extraction method that will segment a UAV image into plots. We will demonstrate that our method achieves higher plot extraction accuracy than existing approaches.
Sickle Cell Disease Severity Prediction from Percoll Gradient Images using Graph Convolutional Networks
Sep 11, 2021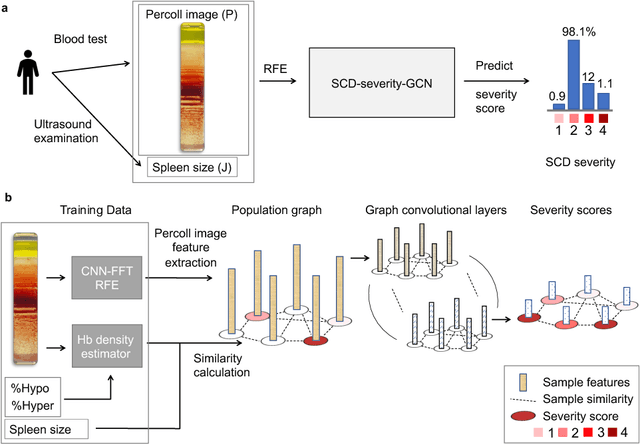
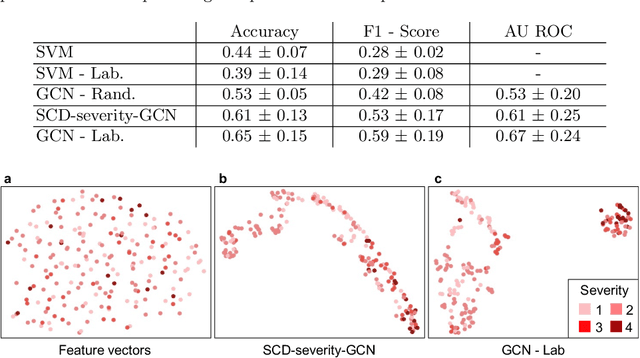


Sickle cell disease (SCD) is a severe genetic hemoglobin disorder that results in premature destruction of red blood cells. Assessment of the severity of the disease is a challenging task in clinical routine since the causes of broad variance in SCD manifestation despite the common genetic cause remain unclear. Identification of the biomarkers that would predict the severity grade is of importance for prognosis and assessment of responsiveness of patients to therapy. Detection of the changes in red blood cell (RBC) density through separation of Percoll density gradient could be such marker as it allows to resolve intercellular differences and follow the most damaged dense cells prone to destruction and vaso-occlusion. Quantification of the images obtained from the distribution of RBCs in Percoll gradient and interpretation of the obtained is an important prerequisite for establishment of this approach. Here, we propose a novel approach combining a graph convolutional network, a convolutional neural network, fast Fourier transform, and recursive feature elimination to predict the severity of SCD directly from a Percoll image. Two important but expensive laboratory blood test parameters measurements are used for training the graph convolutional network. To make the model independent from such tests during prediction, the two parameters are estimated by a neural network from the Percoll image directly. On a cohort of 216 subjects, we achieve a prediction performance that is only slightly below an approach where the groundtruth laboratory measurements are used. Our proposed method is the first computational approach for the difficult task of SCD severity prediction. The two-step approach relies solely on inexpensive and simple blood analysis tools and can have a significant impact on the patients' survival in underdeveloped countries where access to medical instruments and doctors is limited
Progressively Select and Reject Pseudo-labelled Samples for Open-Set Domain Adaptation
Oct 25, 2021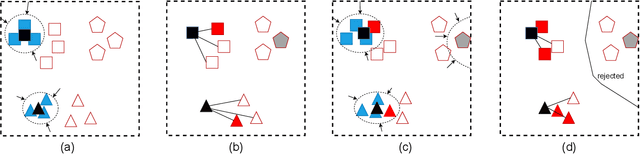

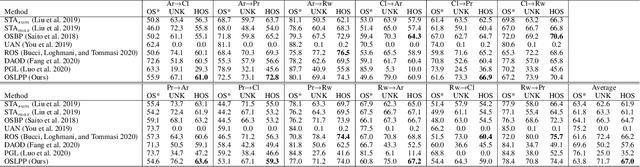
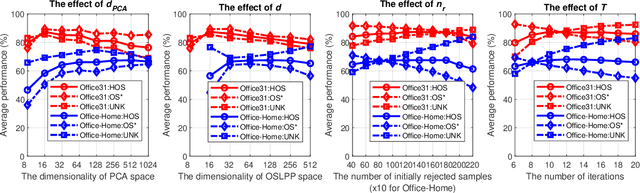
Domain adaptation solves image classification problems in the target domain by taking advantage of the labelled source data and unlabelled target data. Usually, the source and target domains share the same set of classes. As a special case, Open-Set Domain Adaptation (OSDA) assumes there exist additional classes in the target domain but not present in the source domain. To solve such a domain adaptation problem, our proposed method learns discriminative common subspaces for the source and target domains using a novel Open-Set Locality Preserving Projection (OSLPP) algorithm. The source and target domain data are aligned in the learned common spaces class-wisely. To handle the open-set classification problem, our method progressively selects target samples to be pseudo-labelled as known classes and rejects the outliers if they are detected as from unknown classes. The common subspace learning algorithm OSLPP simultaneously aligns the labelled source data and pseudo-labelled target data from known classes and pushes the rejected target data away from the known classes. The common subspace learning and the pseudo-labelled sample selection/rejection facilitate each other in an iterative learning framework and achieves state-of-the-art performance on benchmark datasets Office-31 and Office-Home with the average HOS of 87.4% and 67.0% respectively.
A Technical Report for ICCV 2021 VIPriors Re-identification Challenge
Sep 30, 2021

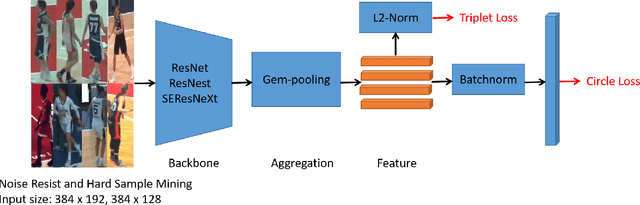
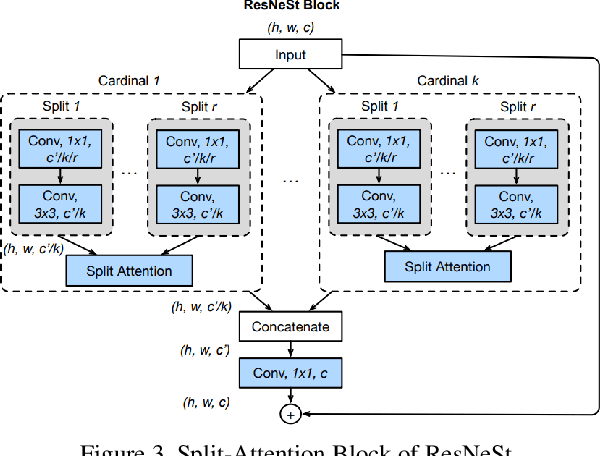
Person re-identification has always been a hot and challenging task. This paper introduces our solution for the re-identification track in VIPriors Challenge 2021. In this challenge, the difficulty is how to train the model from scratch without any pretrained weight. In our method, we show use state-of-the-art data processing strategies, model designs, and post-processing ensemble methods, it is possible to overcome the difficulty of data shortage and obtain competitive results. (1) Both image augmentation strategy and novel pre-processing method for occluded images can help the model learn more discriminative features. (2) Several strong backbones and multiple loss functions are used to learn more representative features. (3) Post-processing techniques including re-ranking, automatic query expansion, ensemble learning, etc., significantly improve the final performance. The final score of our team (ALONG) is 96.5154% mAP, ranking first in the leaderboard.
Recurrent Off-policy Baselines for Memory-based Continuous Control
Oct 25, 2021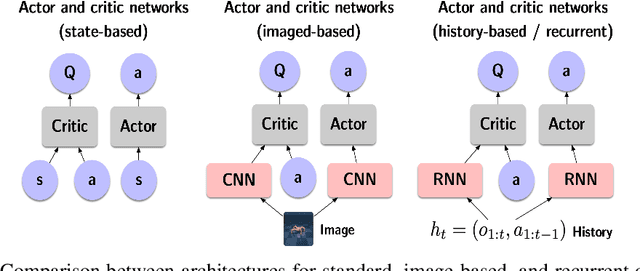
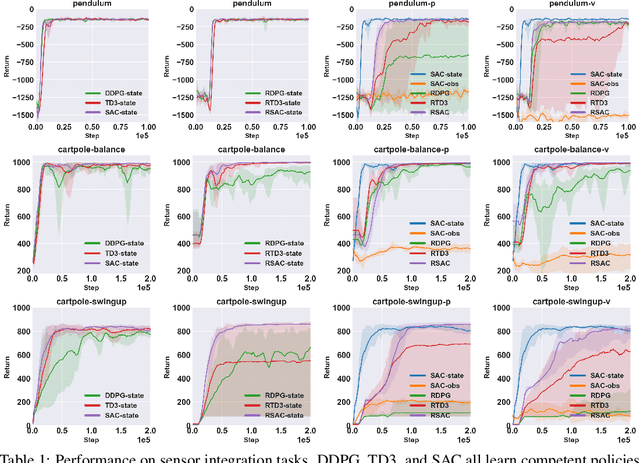
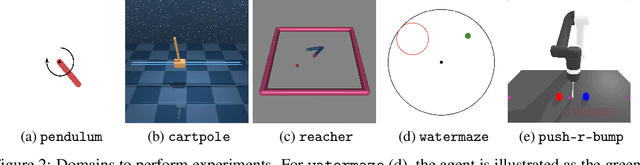
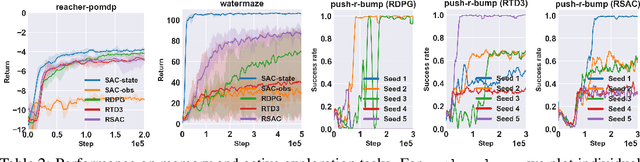
When the environment is partially observable (PO), a deep reinforcement learning (RL) agent must learn a suitable temporal representation of the entire history in addition to a strategy to control. This problem is not novel, and there have been model-free and model-based algorithms proposed for this problem. However, inspired by recent success in model-free image-based RL, we noticed the absence of a model-free baseline for history-based RL that (1) uses full history and (2) incorporates recent advances in off-policy continuous control. Therefore, we implement recurrent versions of DDPG, TD3, and SAC (RDPG, RTD3, and RSAC) in this work, evaluate them on short-term and long-term PO domains, and investigate key design choices. Our experiments show that RDPG and RTD3 can surprisingly fail on some domains and that RSAC is the most reliable, reaching near-optimal performance on nearly all domains. However, one task that requires systematic exploration still proved to be difficult, even for RSAC. These results show that model-free RL can learn good temporal representation using only reward signals; the primary difficulty seems to be computational cost and exploration. To facilitate future research, we have made our PyTorch implementation publicly available at https://github.com/zhihanyang2022/off-policy-continuous-control.
Automatic 2D-3D Registration without Contrast Agent during Neurovascular Interventions
Jun 08, 2021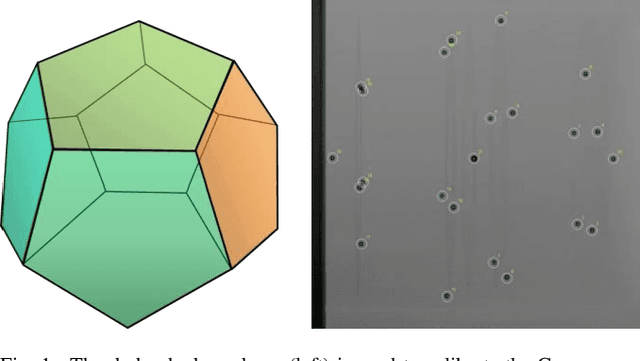
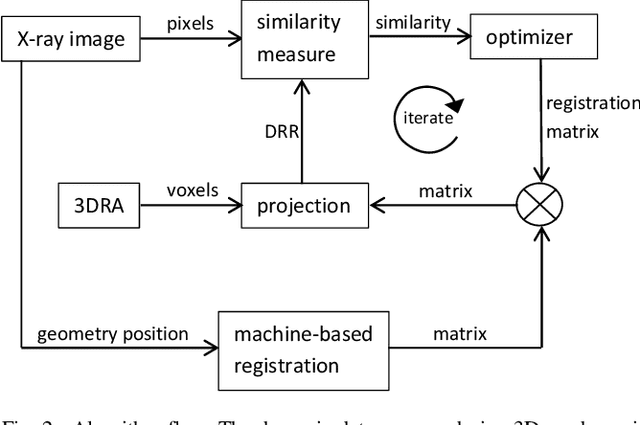
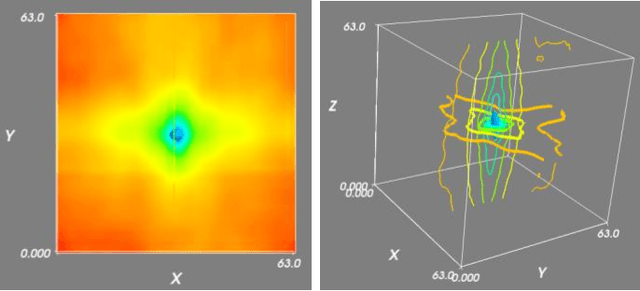
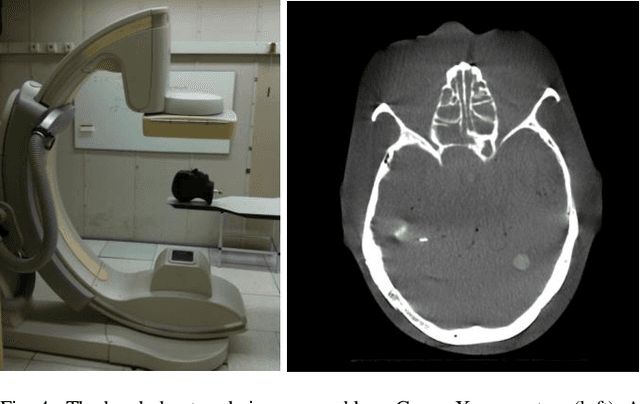
Fusing live fluoroscopy images with a 3D rotational reconstruction of the vasculature allows to navigate endovascular devices in minimally invasive neuro-vascular treatment, while reducing the usage of harmful iodine contrast medium. The alignment of the fluoroscopy images and the 3D reconstruction is initialized using the sensor information of the X-ray C-arm geometry. Patient motion is then corrected by an image-based registration algorithm, based on a gradient difference similarity measure using digital reconstructed radiographs of the 3D reconstruction. This algorithm does not require the vessels in the fluoroscopy image to be filled with iodine contrast agent, but rather relies on gradients in the image (bone structures, sinuses) as landmark features. This paper investigates the accuracy, robustness and computation time aspects of the image-based registration algorithm. Using phantom experiments 97% of the registration attempts passed the success criterion of a residual registration error of less than 1 mm translation and 3{\deg} rotation. The paper establishes a new method for validation of 2D-3D registration without requiring changes to the clinical workflow, such as attaching fiducial markers. As a consequence, this method can be retrospectively applied to pre-existing clinical data. For clinical data experiments, 87% of the registration attempts passed the criterion of a residual translational error of < 1 mm, and 84% possessed a rotational error of < 3{\deg}.
TnT Attacks! Universal Naturalistic Adversarial Patches Against Deep Neural Network Systems
Nov 19, 2021

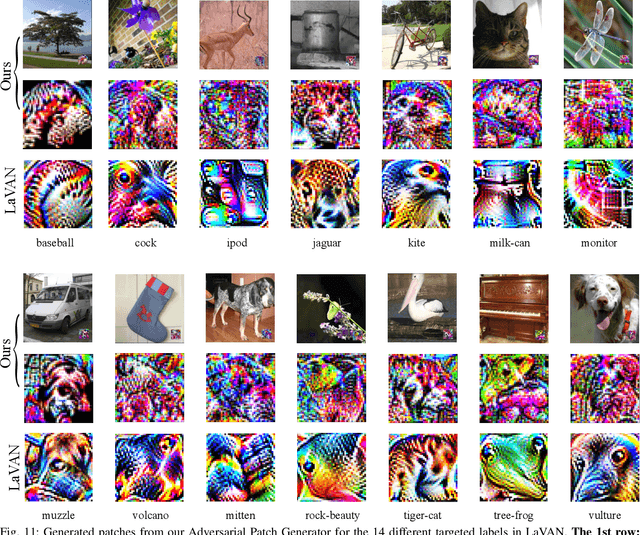
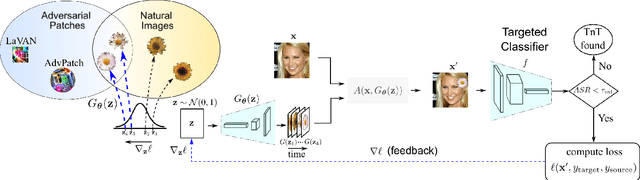
Deep neural networks are vulnerable to attacks from adversarial inputs and, more recently, Trojans to misguide or hijack the decision of the model. We expose the existence of an intriguing class of bounded adversarial examples -- Universal NaTuralistic adversarial paTches -- we call TnTs, by exploring the superset of the bounded adversarial example space and the natural input space within generative adversarial networks. Now, an adversary can arm themselves with a patch that is naturalistic, less malicious-looking, physically realizable, highly effective -- achieving high attack success rates, and universal. A TnT is universal because any input image captured with a TnT in the scene will: i) misguide a network (untargeted attack); or ii) force the network to make a malicious decision (targeted attack). Interestingly, now, an adversarial patch attacker has the potential to exert a greater level of control -- the ability to choose a location independent, natural-looking patch as a trigger in contrast to being constrained to noisy perturbations -- an ability is thus far shown to be only possible with Trojan attack methods needing to interfere with the model building processes to embed a backdoor at the risk discovery; but, still realize a patch deployable in the physical world. Through extensive experiments on the large-scale visual classification task, ImageNet with evaluations across its entire validation set of 50,000 images, we demonstrate the realistic threat from TnTs and the robustness of the attack. We show a generalization of the attack to create patches achieving higher attack success rates than existing state-of-the-art methods. Our results show the generalizability of the attack to different visual classification tasks (CIFAR-10, GTSRB, PubFig) and multiple state-of-the-art deep neural networks such as WideResnet50, Inception-V3 and VGG-16.