 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Meta-Learning Sparse Implicit Neural Representations
Oct 27, 2021
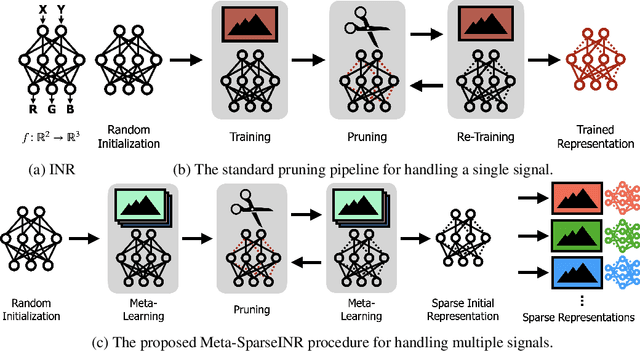

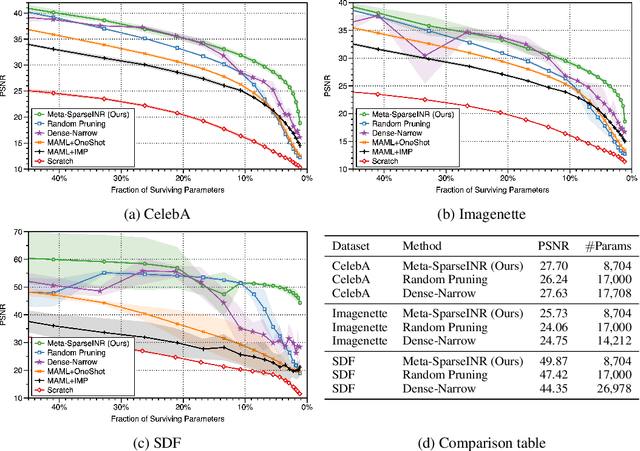
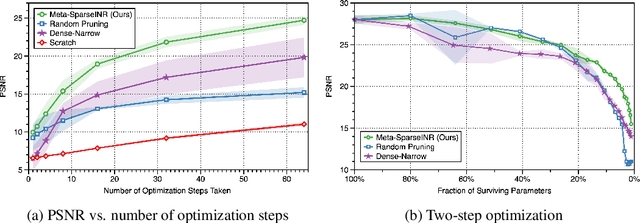
Implicit neural representations are a promising new avenue of representing general signals by learning a continuous function that, parameterized as a neural network, maps the domain of a signal to its codomain; the mapping from spatial coordinates of an image to its pixel values, for example. Being capable of conveying fine details in a high dimensional signal, unboundedly of its domain, implicit neural representations ensure many advantages over conventional discrete representations. However, the current approach is difficult to scale for a large number of signals or a data set, since learning a neural representation -- which is parameter heavy by itself -- for each signal individually requires a lot of memory and computations. To address this issue, we propose to leverage a meta-learning approach in combination with network compression under a sparsity constraint, such that it renders a well-initialized sparse parameterization that evolves quickly to represent a set of unseen signals in the subsequent training. We empirically demonstrate that meta-learned sparse neural representations achieve a much smaller loss than dense meta-learned models with the same number of parameters, when trained to fit each signal using the same number of optimization steps.
Explainable Semantic Space by Grounding Language to Vision with Cross-Modal Contrastive Learning
Nov 13, 2021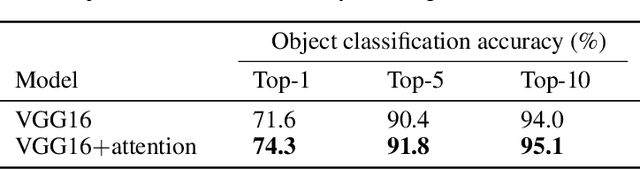
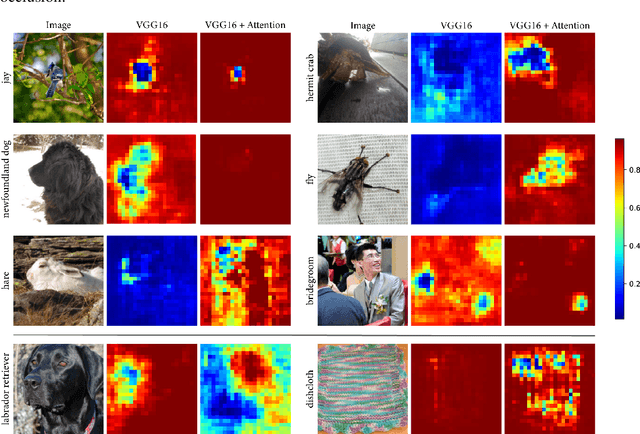
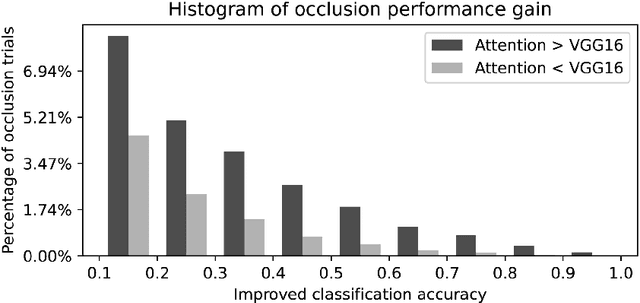

In natural language processing, most models try to learn semantic representations merely from texts. The learned representations encode the distributional semantics but fail to connect to any knowledge about the physical world. In contrast, humans learn language by grounding concepts in perception and action and the brain encodes grounded semantics for cognition. Inspired by this notion and recent work in vision-language learning, we design a two-stream model for grounding language learning in vision. The model includes a VGG-based visual stream and a Bert-based language stream. The two streams merge into a joint representational space. Through cross-modal contrastive learning, the model first learns to align visual and language representations with the MS COCO dataset. The model further learns to retrieve visual objects with language queries through a cross-modal attention module and to infer the visual relations between the retrieved objects through a bilinear operator with the Visual Genome dataset. After training, the language stream of this model is a stand-alone language model capable of embedding concepts in a visually grounded semantic space. This semantic space manifests principal dimensions explainable with human intuition and neurobiological knowledge. Word embeddings in this semantic space are predictive of human-defined norms of semantic features and are segregated into perceptually distinctive clusters. Furthermore, the visually grounded language model also enables compositional language understanding based on visual knowledge and multimodal image search with queries based on images, texts, or their combinations.
Egoshots, an ego-vision life-logging dataset and semantic fidelity metric to evaluate diversity in image captioning models
Mar 26, 2020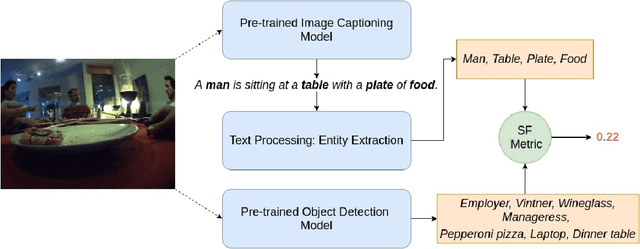

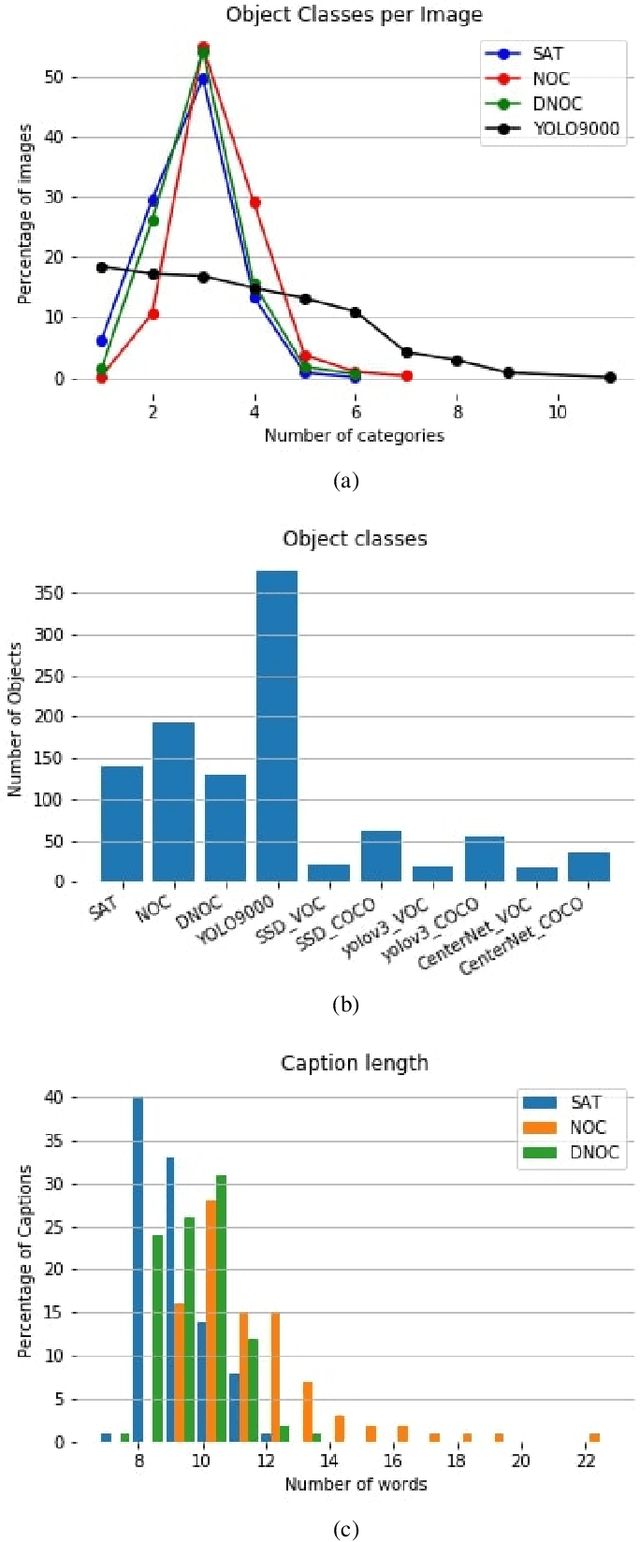
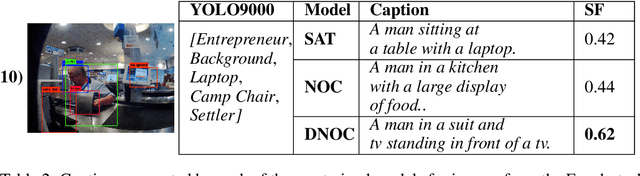
Image captioning models have been able to generate grammatically correct and human understandable sentences. However most of the captions convey limited information as the model used is trained on datasets that do not caption all possible objects existing in everyday life. Due to this lack of prior information most of the captions are biased to only a few objects present in the scene, hence limiting their usage in daily life. In this paper, we attempt to show the biased nature of the currently existing image captioning models and present a new image captioning dataset, Egoshots, consisting of 978 real life images with no captions. We further exploit the state of the art pre-trained image captioning and object recognition networks to annotate our images and show the limitations of existing works. Furthermore, in order to evaluate the quality of the generated captions, we propose a new image captioning metric, object based Semantic Fidelity (SF). Existing image captioning metrics can evaluate a caption only in the presence of their corresponding annotations; however, SF allows evaluating captions generated for images without annotations, making it highly useful for real life generated captions.
MEAL: Manifold Embedding-based Active Learning
Jul 20, 2021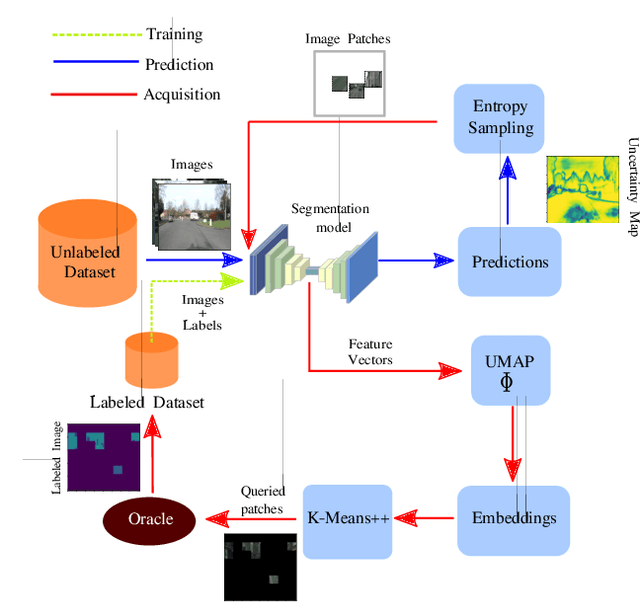

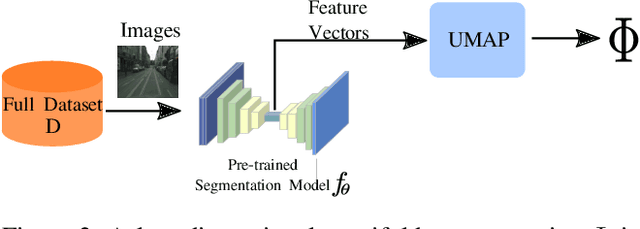
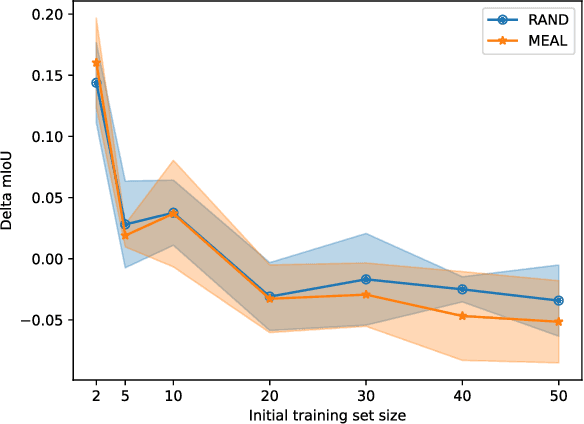
Image segmentation is a common and challenging task in autonomous driving. Availability of sufficient pixel-level annotations for the training data is a hurdle. Active learning helps learning from small amounts of data by suggesting the most promising samples for labeling. In this work, we propose a new pool-based method for active learning, which proposes promising patches extracted from full image, in each acquisition step. The problem is framed in an exploration-exploitation framework by combining an embedding based on Uniform Manifold Approximation to model representativeness with entropy as uncertainty measure to model informativeness. We applied our proposed method to the autonomous driving datasets CamVid and Cityscapes and performed a quantitative comparison with state-of-the-art baselines. We find that our active learning method achieves better performance compared to previous methods.
Boundary Guided Context Aggregation for Semantic Segmentation
Oct 27, 2021
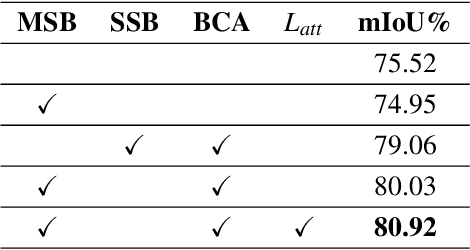
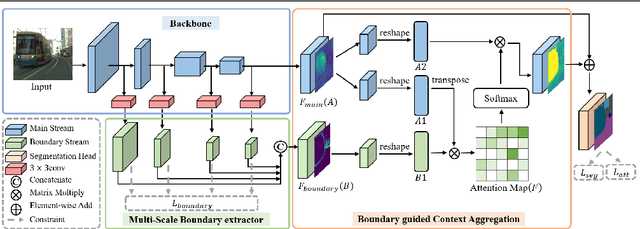

The recent studies on semantic segmentation are starting to notice the significance of the boundary information, where most approaches see boundaries as the supplement of semantic details. However, simply combing boundaries and the mainstream features cannot ensure a holistic improvement of semantics modeling. In contrast to the previous studies, we exploit boundary as a significant guidance for context aggregation to promote the overall semantic understanding of an image. To this end, we propose a Boundary guided Context Aggregation Network (BCANet), where a Multi-Scale Boundary extractor (MSB) borrowing the backbone features at multiple scales is specifically designed for accurate boundary detection. Based on which, a Boundary guided Context Aggregation module (BCA) improved from Non-local network is further proposed to capture long-range dependencies between the pixels in the boundary regions and the ones inside the objects. By aggregating the context information along the boundaries, the inner pixels of the same category achieve mutual gains and therefore the intra-class consistency is enhanced. We conduct extensive experiments on the Cityscapes and ADE20K databases, and comparable results are achieved with the state-of-the-art methods, clearly demonstrating the effectiveness of the proposed one.
Next-Best-View Estimation based on Deep Reinforcement Learning for Active Object Classification
Oct 13, 2021
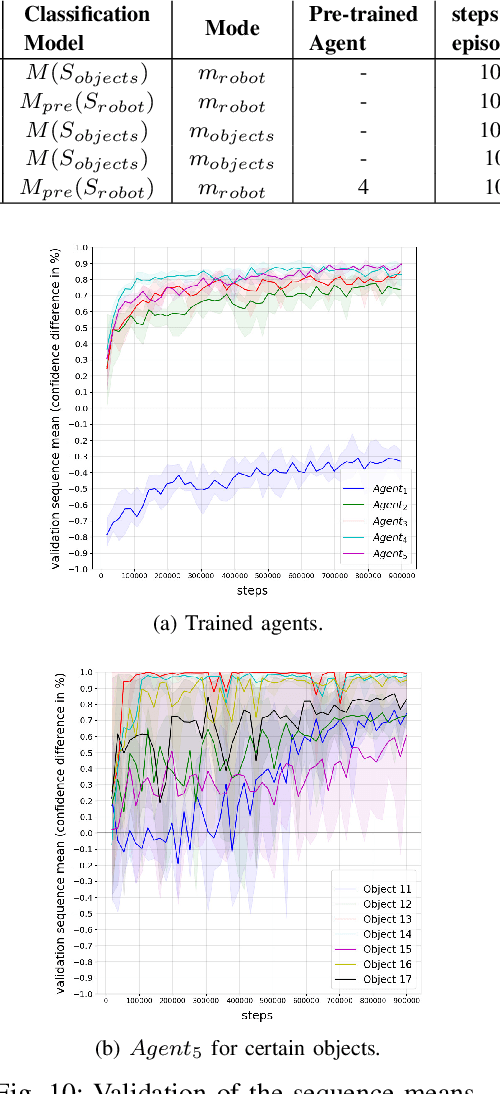
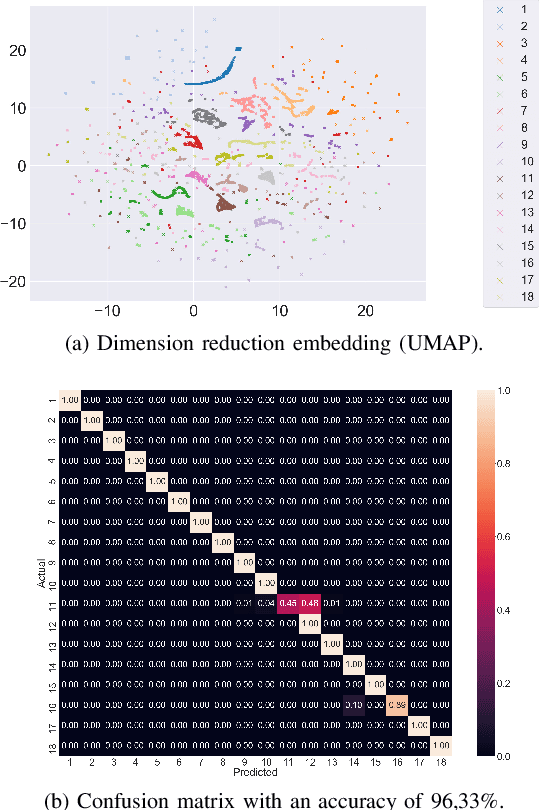
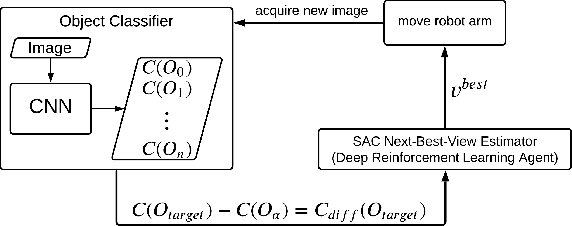
The presentation and analysis of image data from a single viewpoint are often not sufficient to solve a task. Several viewpoints are necessary to obtain more information. The $\textit{next-best-view}$ problem attempts to find the optimal viewpoint with the greatest information gain for the underlying task. In this work, a robot arm holds an object in its end-effector and searches for a sequence of next-best-view to explicitly identify the object. We use Soft Actor-Critic (SAC), a method of deep reinforcement learning, to learn these next-best-views for a specific set of objects. The evaluation shows that an agent can learn to determine an object pose to which the robot arm should move an object. This leads to a viewpoint that provides a more accurate prediction to distinguish such an object from other objects better. We make the code publicly available for the scientific community and for reproducibility under $\href{https://github.com/ckorbach/nbv_rl}{\text{this https link}}$.
Transferability of Adversarial Examples to Attack Cloud-based Image Classifier Service
Jan 16, 2020

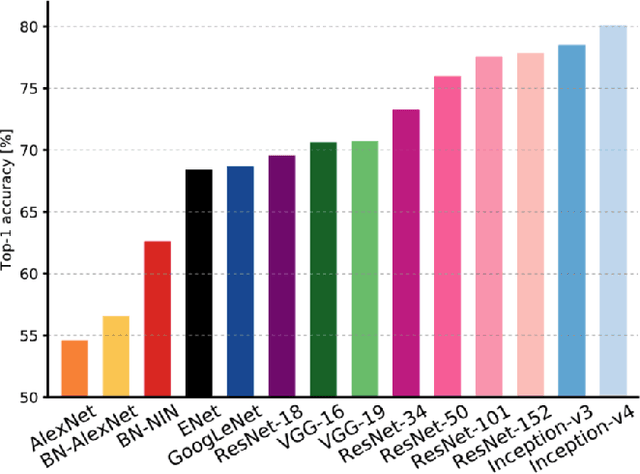
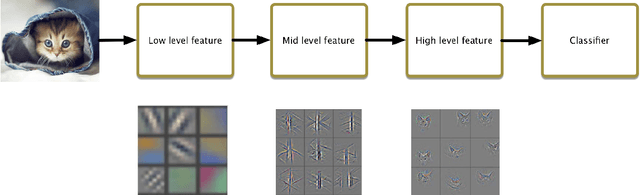
In recent years, Deep Learning(DL) techniques have been extensively deployed for computer vision tasks, particularly visual classification problems, where new algorithms reported to achieve or even surpass the human performance . While many recent works demonstrated that DL models are vulnerable to adversarial examples.Fortunately, generating adversarial examples usually requires white-box access to the victim model, and real-world cloud-based image classification services are more complex than white-box classifier,the architecture and parameters of DL models on cloud platforms cannot be obtained by the attacker. The attacker can only access the APIs opened by cloud platforms. Thus, keeping models in the cloud can usually give a (false) sense of security.In this paper, we mainly focus on studying the security of real-world cloud-based image classification services. Specifically, (1) We propose two novel attack methods, Image Fusion(IF) attack and Fast Featuremap Loss PGD (FFL-PGD) attack based on Substitution model ,which achieve a high bypass rate with a very limited number of queries. Instead of millions of queries in previous studies, our methods find the adversarial examples using only two queries per image ; and (2) we make the first attempt to conduct an extensive empirical study of black-box attacks against real-world cloud-based classification services. Through evaluations on four popular cloud platforms including Amazon, Google, Microsoft, Clarifai, we demonstrate that Spatial Transformation (ST) attack has a success rate of approximately 100\% except Amazon approximately 50\%, IF and FFL-PGD attack have a success rate over 90\% among different classification services. (3) We discuss the possible defenses to address these security challenges in cloud-based classification services.Our defense technology is mainly divided into model training stage and image preprocessing stage.
3DStyleNet: Creating 3D Shapes with Geometric and Texture Style Variations
Aug 30, 2021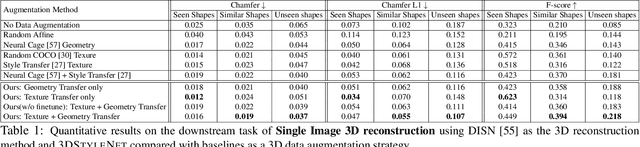
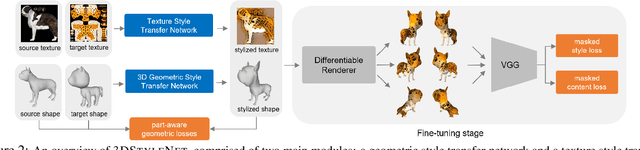
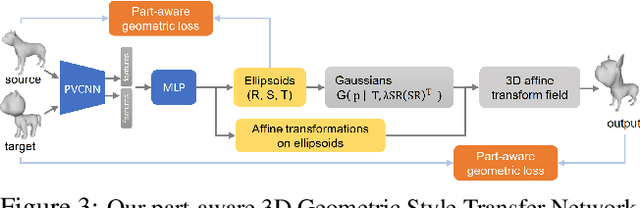
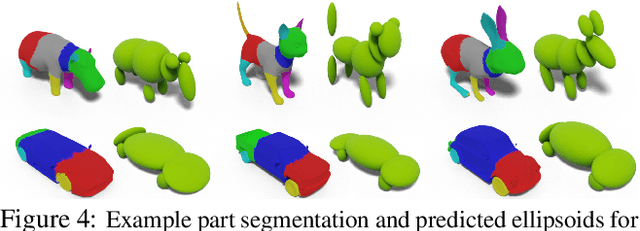
We propose a method to create plausible geometric and texture style variations of 3D objects in the quest to democratize 3D content creation. Given a pair of textured source and target objects, our method predicts a part-aware affine transformation field that naturally warps the source shape to imitate the overall geometric style of the target. In addition, the texture style of the target is transferred to the warped source object with the help of a multi-view differentiable renderer. Our model, 3DStyleNet, is composed of two sub-networks trained in two stages. First, the geometric style network is trained on a large set of untextured 3D shapes. Second, we jointly optimize our geometric style network and a pre-trained image style transfer network with losses defined over both the geometry and the rendering of the result. Given a small set of high-quality textured objects, our method can create many novel stylized shapes, resulting in effortless 3D content creation and style-ware data augmentation. We showcase our approach qualitatively on 3D content stylization, and provide user studies to validate the quality of our results. In addition, our method can serve as a valuable tool to create 3D data augmentations for computer vision tasks. Extensive quantitative analysis shows that 3DStyleNet outperforms alternative data augmentation techniques for the downstream task of single-image 3D reconstruction.
Visualisation of Medical Image Fusion and Translation for Accurate Diagnosis of High Grade Gliomas
Jan 28, 2020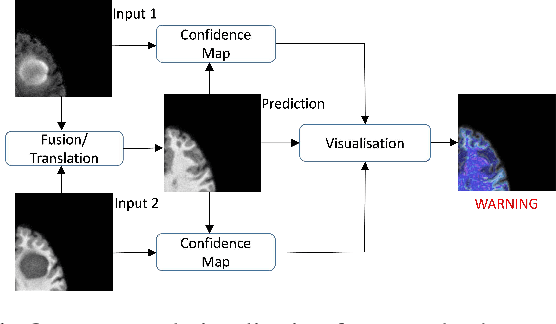
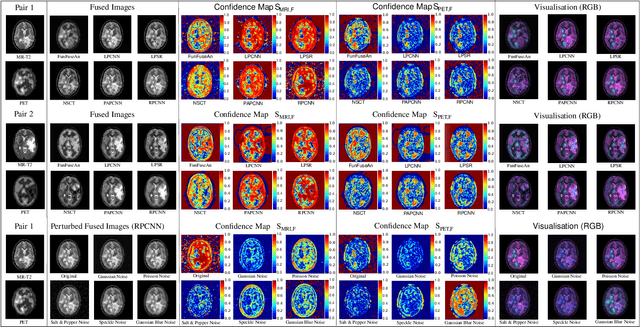
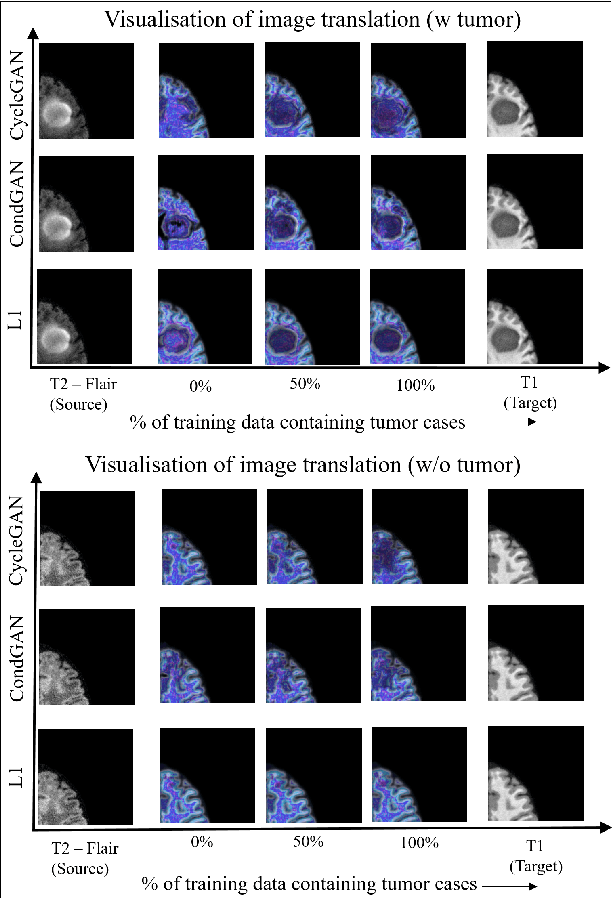
The medical image fusion combines two or more modalities into a single view while medical image translation synthesizes new images and assists in data augmentation. Together, these methods help in faster diagnosis of high grade malignant gliomas. However, they might be untrustworthy due to which neurosurgeons demand a robust visualisation tool to verify the reliability of the fusion and translation results before they make pre-operative surgical decisions. In this paper, we propose a novel approach to compute a confidence heat map between the source-target image pair by estimating the information transfer from the source to the target image using the joint probability distribution of the two images. We evaluate several fusion and translation methods using our visualisation procedure and showcase its robustness in enabling neurosurgeons to make finer clinical decisions.
Quantitative phase imaging of single particles from a cryoEM micrograph
May 26, 2021
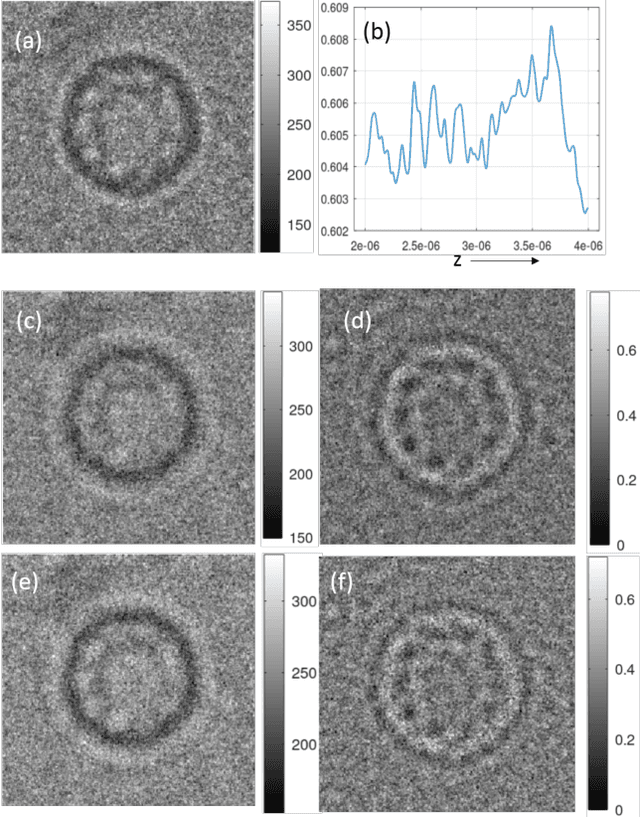

We show that de-focused single particle images recorded using a cryo-electron microscope (cryoEM) system may be processed like a Fresnel zone in-line hologram to obtain physically meaningful quantitative phase maps associated with individual particles. In particular, a region-of-interest (ROI) of the de-focused image surrounding a particle can be numerically back-propagated, in order to determine accurate de-focus information based on the sparsity-of-gradient merit function. Further with the knowledge of de-focus information, an iterative Fresnel zone phase retrieval algorithm using image sparsity constraints can accurately estimate the quantitative phase information associated with a single particle. The proposed methodology which can correct for both de-focus and spherical aberrations is a deviation from the image processing chain currently used in single particle cryoEM reconstructions. Our illustrations as presented here suggest that the phase retrieval approach applies uniformly to de-focused image data recorded using the traditional CCD detectors as well as the newer direct electron detectors.