 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Patch-Based Cervical Cancer Segmentation using Distance from Boundary of Tissue
Aug 19, 2021
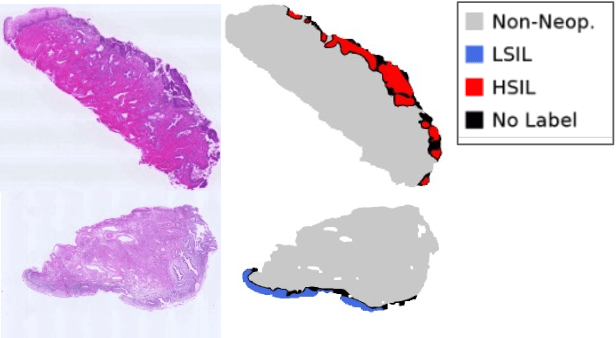
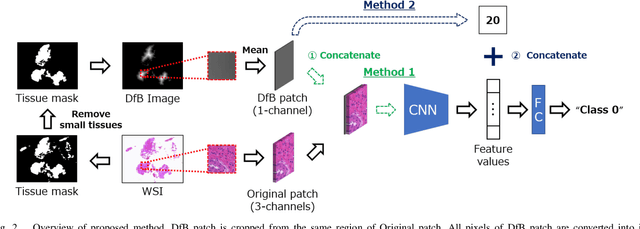
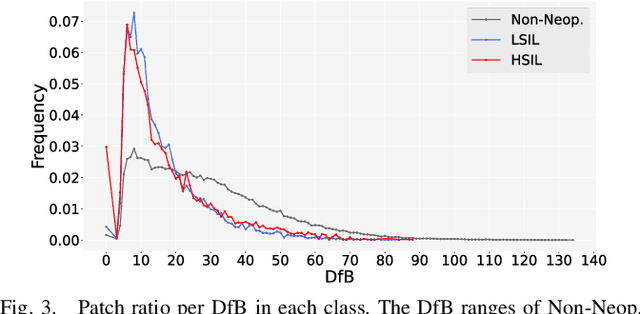

Pathological diagnosis is used for examining cancer in detail, and its automation is in demand. To automatically segment each cancer area, a patch-based approach is usually used since a Whole Slide Image (WSI) is huge. However, this approach loses the global information needed to distinguish between classes. In this paper, we utilized the Distance from the Boundary of tissue (DfB), which is global information that can be extracted from the original image. We experimentally applied our method to the three-class classification of cervical cancer, and found that it improved the total performance compared with the conventional method.
OVIS: Open-Vocabulary Visual Instance Search via Visual-Semantic Aligned Representation Learning
Aug 08, 2021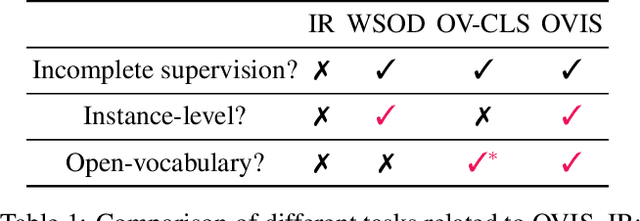
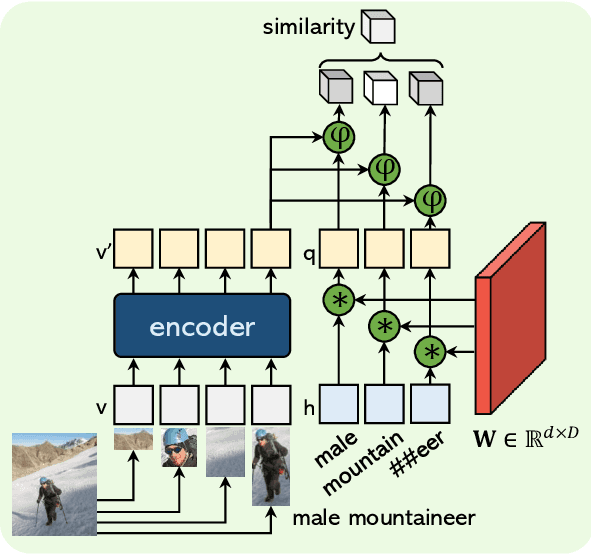

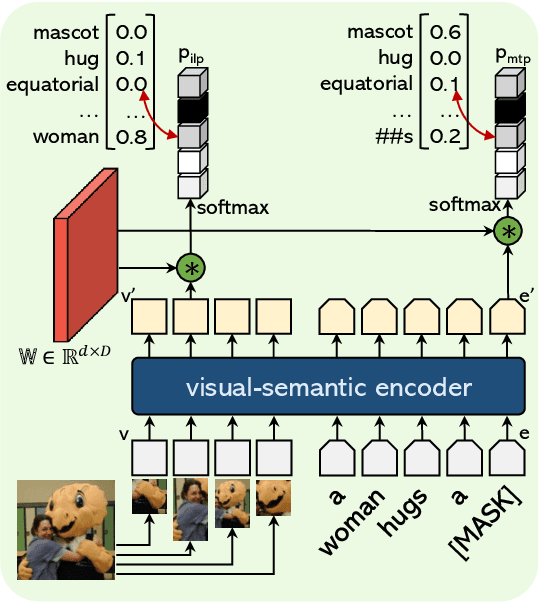
We introduce the task of open-vocabulary visual instance search (OVIS). Given an arbitrary textual search query, Open-vocabulary Visual Instance Search (OVIS) aims to return a ranked list of visual instances, i.e., image patches, that satisfies the search intent from an image database. The term "open vocabulary" means that there are neither restrictions to the visual instance to be searched nor restrictions to the word that can be used to compose the textual search query. We propose to address such a search challenge via visual-semantic aligned representation learning (ViSA). ViSA leverages massive image-caption pairs as weak image-level (not instance-level) supervision to learn a rich cross-modal semantic space where the representations of visual instances (not images) and those of textual queries are aligned, thus allowing us to measure the similarities between any visual instance and an arbitrary textual query. To evaluate the performance of ViSA, we build two datasets named OVIS40 and OVIS1600 and also introduce a pipeline for error analysis. Through extensive experiments on the two datasets, we demonstrate ViSA's ability to search for visual instances in images not available during training given a wide range of textual queries including those composed of uncommon words. Experimental results show that ViSA achieves an mAP@50 of 21.9% on OVIS40 under the most challenging setting and achieves an mAP@6 of 14.9% on OVIS1600 dataset.
Measuring Complexity of Learning Schemes Using Hessian-Schatten Total-Variation
Dec 12, 2021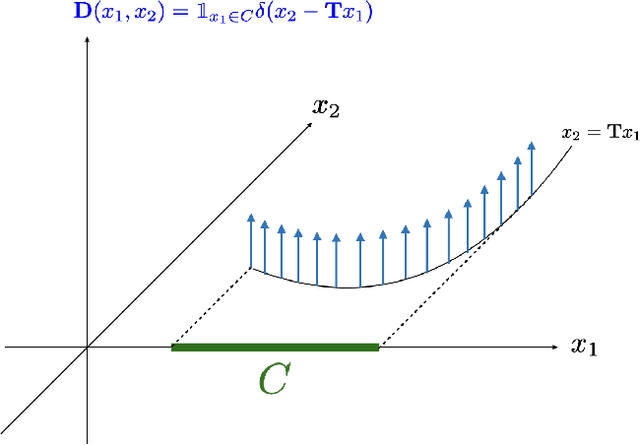
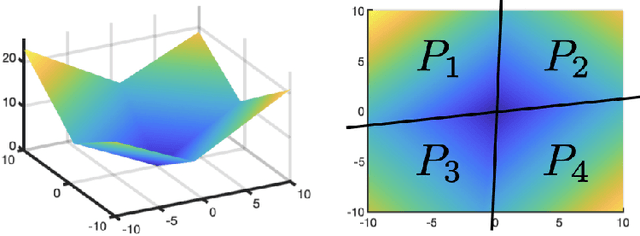
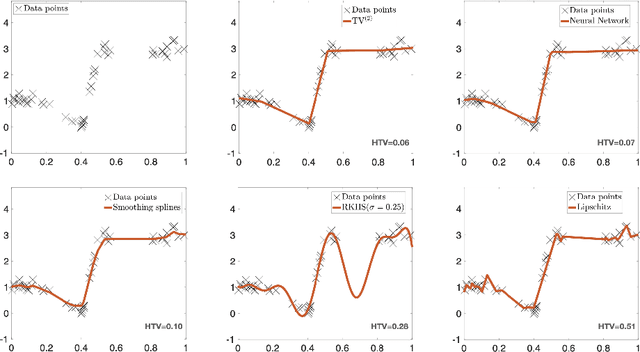

In this paper, we introduce the Hessian-Schatten total-variation (HTV) -- a novel seminorm that quantifies the total "rugosity" of multivariate functions. Our motivation for defining HTV is to assess the complexity of supervised learning schemes. We start by specifying the adequate matrix-valued Banach spaces that are equipped with suitable classes of mixed-norms. We then show that HTV is invariant to rotations, scalings, and translations. Additionally, its minimum value is achieved for linear mappings, supporting the common intuition that linear regression is the least complex learning model. Next, we present closed-form expressions for computing the HTV of two general classes of functions. The first one is the class of Sobolev functions with a certain degree of regularity, for which we show that HTV coincides with the Hessian-Schatten seminorm that is sometimes used as a regularizer for image reconstruction. The second one is the class of continuous and piecewise linear (CPWL) functions. In this case, we show that the HTV reflects the total change in slopes between linear regions that have a common facet. Hence, it can be viewed as a convex relaxation (l1-type) of the number of linear regions (l0-type) of CPWL mappings. Finally, we illustrate the use of our proposed seminorm with some concrete examples.
FastSurferVINN: Building Resolution-Independence into Deep Learning Segmentation Methods -- A Solution for HighRes Brain MRI
Dec 17, 2021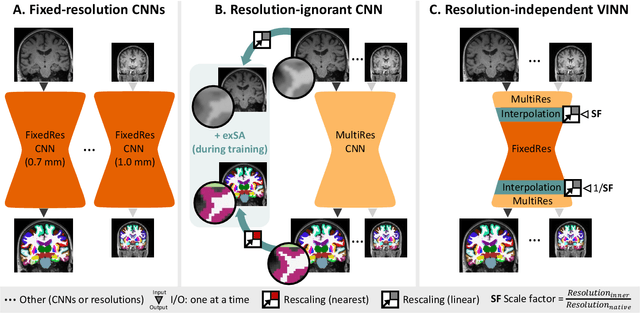

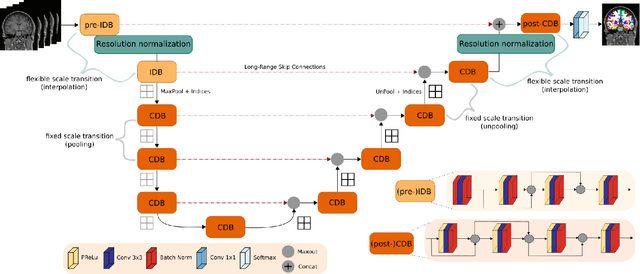
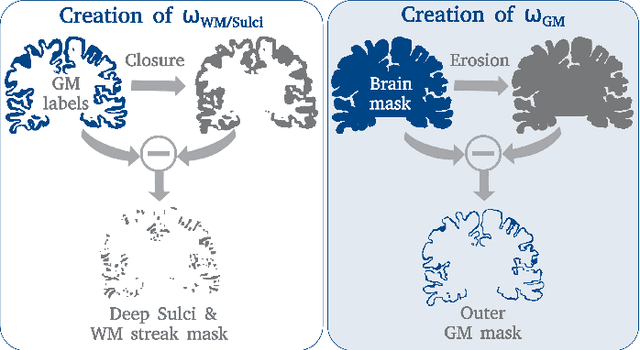
Leading neuroimaging studies have pushed 3T MRI acquisition resolutions below 1.0 mm for improved structure definition and morphometry. Yet, only few, time-intensive automated image analysis pipelines have been validated for high-resolution (HiRes) settings. Efficient deep learning approaches, on the other hand, rarely support more than one fixed resolution (usually 1.0 mm). Furthermore, the lack of a standard submillimeter resolution as well as limited availability of diverse HiRes data with sufficient coverage of scanner, age, diseases, or genetic variance poses additional, unsolved challenges for training HiRes networks. Incorporating resolution-independence into deep learning-based segmentation, i.e., the ability to segment images at their native resolution across a range of different voxel sizes, promises to overcome these challenges, yet no such approach currently exists. We now fill this gap by introducing a Voxelsize Independent Neural Network (VINN) for resolution-independent segmentation tasks and present FastSurferVINN, which (i) establishes and implements resolution-independence for deep learning as the first method simultaneously supporting 0.7-1.0 mm whole brain segmentation, (ii) significantly outperforms state-of-the-art methods across resolutions, and (iii) mitigates the data imbalance problem present in HiRes datasets. Overall, internal resolution-independence mutually benefits both HiRes and 1.0 mm MRI segmentation. With our rigorously validated FastSurferVINN we distribute a rapid tool for morphometric neuroimage analysis. The VINN architecture, furthermore, represents an efficient resolution-independent segmentation method for wider application
Information-theoretic stochastic contrastive conditional GAN: InfoSCC-GAN
Dec 17, 2021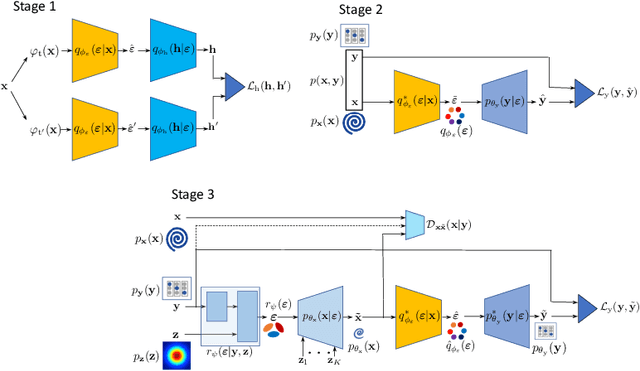
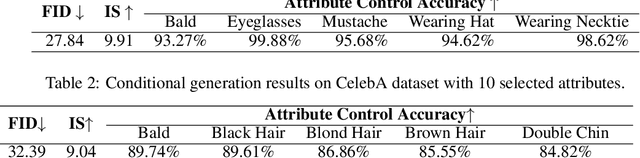
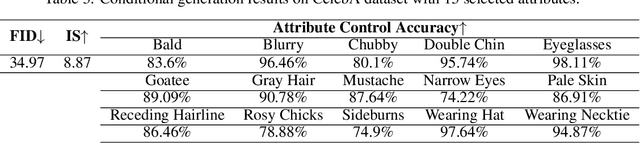
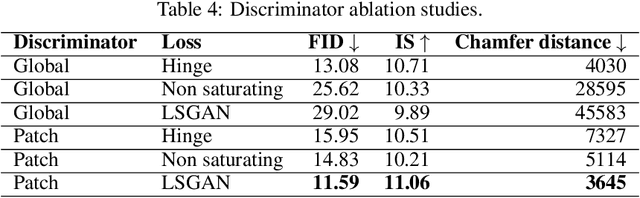
Conditional generation is a subclass of generative problems where the output of the generation is conditioned by the attribute information. In this paper, we present a stochastic contrastive conditional generative adversarial network (InfoSCC-GAN) with an explorable latent space. The InfoSCC-GAN architecture is based on an unsupervised contrastive encoder built on the InfoNCE paradigm, an attribute classifier and an EigenGAN generator. We propose a novel training method, based on generator regularization using external or internal attributes every $n$-th iteration, using a pre-trained contrastive encoder and a pre-trained classifier. The proposed InfoSCC-GAN is derived based on an information-theoretic formulation of mutual information maximization between input data and latent space representation as well as latent space and generated data. Thus, we demonstrate a link between the training objective functions and the above information-theoretic formulation. The experimental results show that InfoSCC-GAN outperforms the "vanilla" EigenGAN in the image generation on AFHQ and CelebA datasets. In addition, we investigate the impact of discriminator architectures and loss functions by performing ablation studies. Finally, we demonstrate that thanks to the EigenGAN generator, the proposed framework enjoys a stochastic generation in contrast to vanilla deterministic GANs yet with the independent training of encoder, classifier, and generator in contrast to existing frameworks. Code, experimental results, and demos are available online at https://github.com/vkinakh/InfoSCC-GAN.
NeRFReN: Neural Radiance Fields with Reflections
Nov 30, 2021
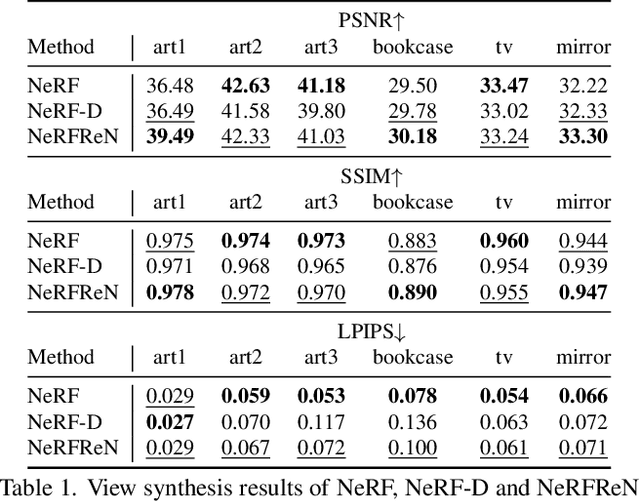
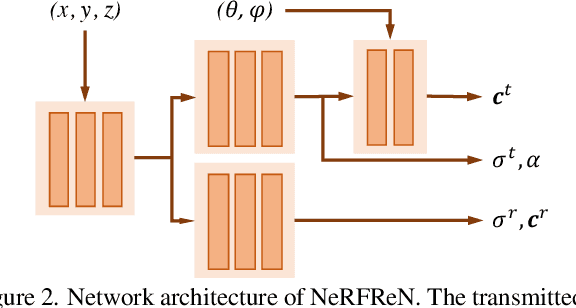
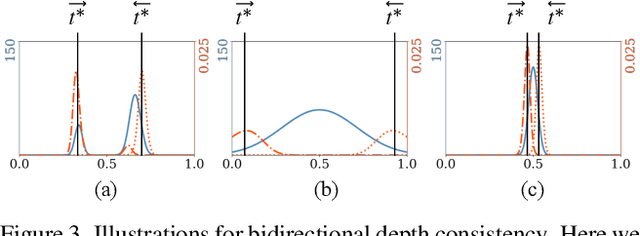
Neural Radiance Fields (NeRF) has achieved unprecedented view synthesis quality using coordinate-based neural scene representations. However, NeRF's view dependency can only handle simple reflections like highlights but cannot deal with complex reflections such as those from glass and mirrors. In these scenarios, NeRF models the virtual image as real geometries which leads to inaccurate depth estimation, and produces blurry renderings when the multi-view consistency is violated as the reflected objects may only be seen under some of the viewpoints. To overcome these issues, we introduce NeRFReN, which is built upon NeRF to model scenes with reflections. Specifically, we propose to split a scene into transmitted and reflected components, and model the two components with separate neural radiance fields. Considering that this decomposition is highly under-constrained, we exploit geometric priors and apply carefully-designed training strategies to achieve reasonable decomposition results. Experiments on various self-captured scenes show that our method achieves high-quality novel view synthesis and physically sound depth estimation results while enabling scene editing applications. Code and data will be released.
Frequency Pooling: Shift-Equivalent and Anti-Aliasing Downsampling
Sep 24, 2021
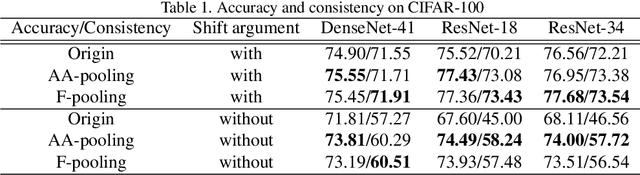
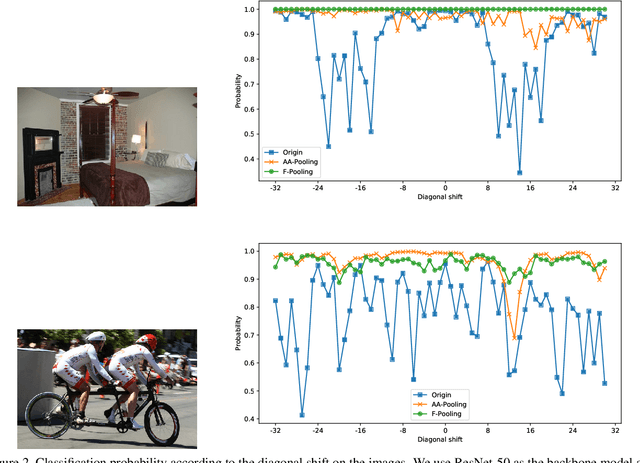
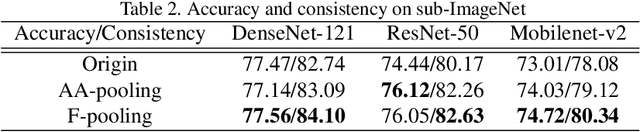
Convolution utilizes a shift-equivalent prior of images, thus leading to great success in image processing tasks. However, commonly used poolings in convolutional neural networks (CNNs), such as max-pooling, average-pooling, and strided-convolution, are not shift-equivalent. Thus, the shift-equivalence of CNNs is destroyed when convolutions and poolings are stacked. Moreover, anti-aliasing is another essential property of poolings from the perspective of signal processing. However, recent poolings are neither shift-equivalent nor anti-aliasing. To address this issue, we propose a new pooling method that is shift-equivalent and anti-aliasing, named frequency pooling. Frequency pooling first transforms the features into the frequency domain, and then removes the frequency components beyond the Nyquist frequency. Finally, it transforms the features back to the spatial domain. We prove that frequency pooling is shift-equivalent and anti-aliasing based on the property of Fourier transform and Nyquist frequency. Experiments on image classification show that frequency pooling improves accuracy and robustness with respect to the shifts of CNNs.
Big Data in Astroinformatics -- Compression of Scanned Astronomical Photographic Plates
Aug 24, 2021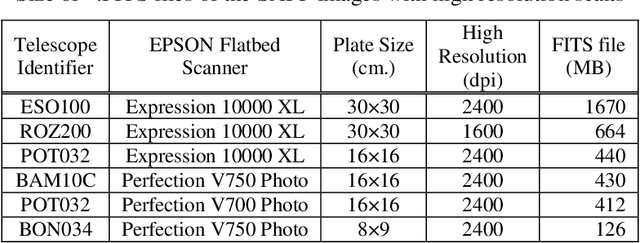
Construction of Scanned Astronomical Photographic Plates(SAPPs) databases and SVD image compression algorithm are considered. Some examples of compression with different plates are shown.
Adversarial Machine Learning in Image Classification: A Survey Towards the Defender's Perspective
Sep 08, 2020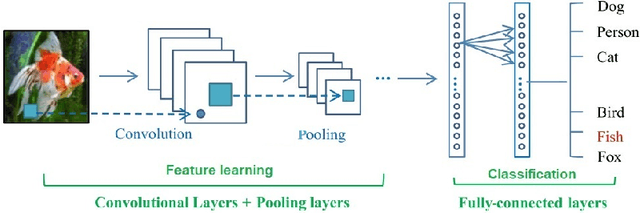
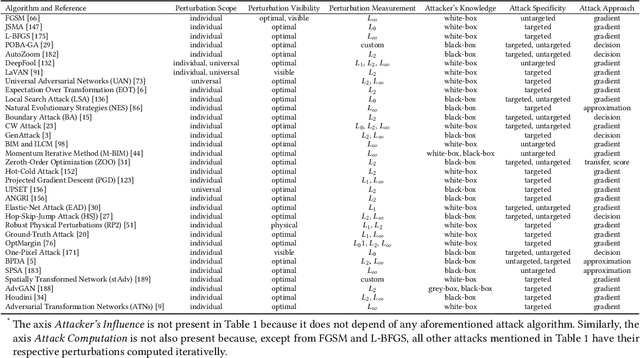
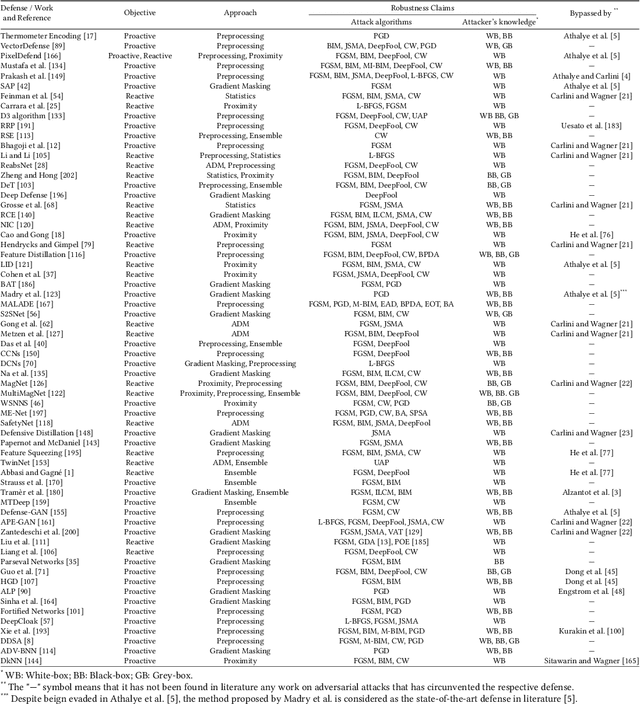
Deep Learning algorithms have achieved the state-of-the-art performance for Image Classification and have been used even in security-critical applications, such as biometric recognition systems and self-driving cars. However, recent works have shown those algorithms, which can even surpass the human capabilities, are vulnerable to adversarial examples. In Computer Vision, adversarial examples are images containing subtle perturbations generated by malicious optimization algorithms in order to fool classifiers. As an attempt to mitigate these vulnerabilities, numerous countermeasures have been constantly proposed in literature. Nevertheless, devising an efficient defense mechanism has proven to be a difficult task, since many approaches have already shown to be ineffective to adaptive attackers. Thus, this self-containing paper aims to provide all readerships with a review of the latest research progress on Adversarial Machine Learning in Image Classification, however with a defender's perspective. Here, novel taxonomies for categorizing adversarial attacks and defenses are introduced and discussions about the existence of adversarial examples are provided. Further, in contrast to exisiting surveys, it is also given relevant guidance that should be taken into consideration by researchers when devising and evaluating defenses. Finally, based on the reviewed literature, it is discussed some promising paths for future research.
CLIP Meets Video Captioners: Attribute-Aware Representation Learning Promotes Accurate Captioning
Nov 30, 2021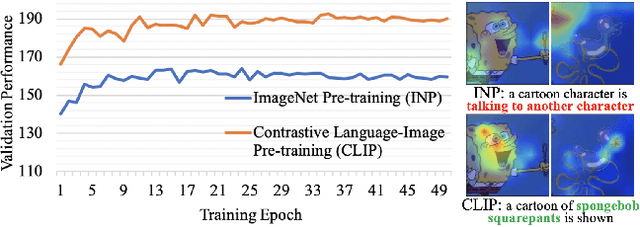
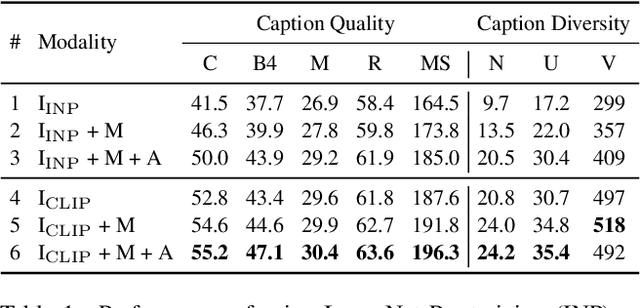
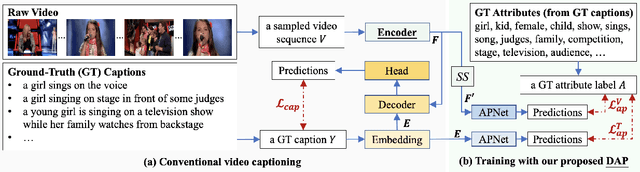

For video captioning, "pre-training and fine-tuning" has become a de facto paradigm, where ImageNet Pre-training (INP) is usually used to help encode the video content, and a task-oriented network is fine-tuned from scratch to cope with caption generation. Comparing INP with the recently proposed CLIP (Contrastive Language-Image Pre-training), this paper investigates the potential deficiencies of INP for video captioning and explores the key to generating accurate descriptions. Specifically, our empirical study on INP vs. CLIP shows that INP makes video caption models tricky to capture attributes' semantics and sensitive to irrelevant background information. By contrast, CLIP's significant boost in caption quality highlights the importance of attribute-aware representation learning. We are thus motivated to introduce Dual Attribute Prediction, an auxiliary task requiring a video caption model to learn the correspondence between video content and attributes and the co-occurrence relations between attributes. Extensive experiments on benchmark datasets demonstrate that our approach enables better learning of attribute-aware representations, bringing consistent improvements on models with different architectures and decoding algorithms.