 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Couplformer:Rethinking Vision Transformer with Coupling Attention Map
Dec 10, 2021
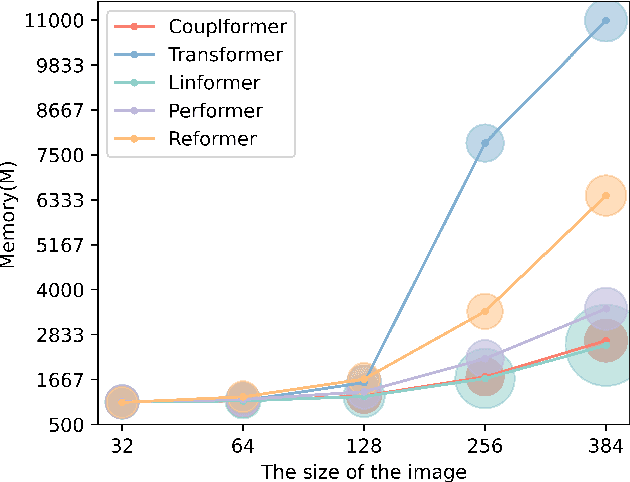

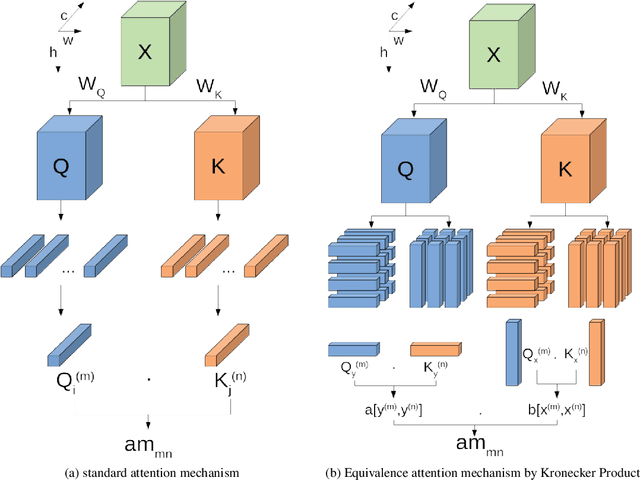
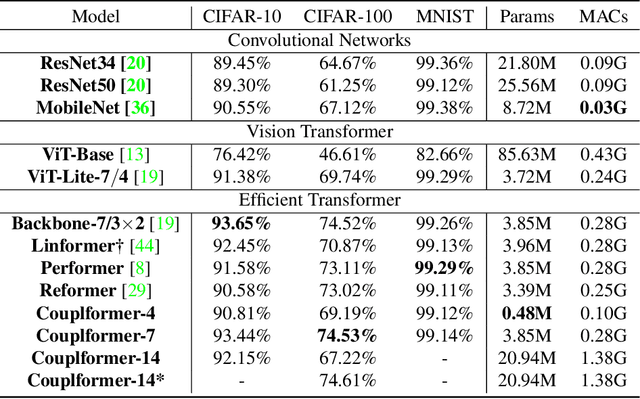
With the development of the self-attention mechanism, the Transformer model has demonstrated its outstanding performance in the computer vision domain. However, the massive computation brought from the full attention mechanism became a heavy burden for memory consumption. Sequentially, the limitation of memory reduces the possibility of improving the Transformer model. To remedy this problem, we propose a novel memory economy attention mechanism named Couplformer, which decouples the attention map into two sub-matrices and generates the alignment scores from spatial information. A series of different scale image classification tasks are applied to evaluate the effectiveness of our model. The result of experiments shows that on the ImageNet-1k classification task, the Couplformer can significantly decrease 28% memory consumption compared with regular Transformer while accessing sufficient accuracy requirements and outperforming 0.92% on Top-1 accuracy while occupying the same memory footprint. As a result, the Couplformer can serve as an efficient backbone in visual tasks, and provide a novel perspective on the attention mechanism for researchers.
GeneAnnotator: A Semi-automatic Annotation Tool for Visual Scene Graph
Sep 06, 2021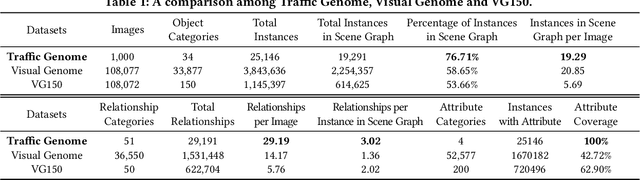
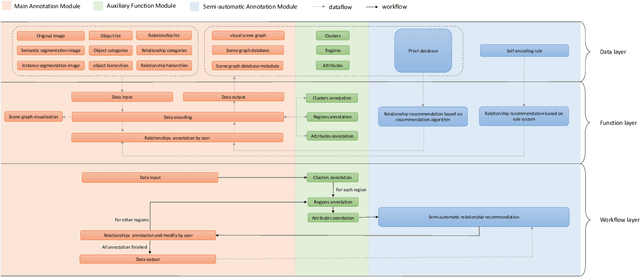
In this manuscript, we introduce a semi-automatic scene graph annotation tool for images, the GeneAnnotator. This software allows human annotators to describe the existing relationships between participators in the visual scene in the form of directed graphs, hence enabling the learning and reasoning on visual relationships, e.g., image captioning, VQA and scene graph generation, etc. The annotations for certain image datasets could either be merged in a single VG150 data-format file to support most existing models for scene graph learning or transformed into a separated annotation file for each single image to build customized datasets. Moreover, GeneAnnotator provides a rule-based relationship recommending algorithm to reduce the heavy annotation workload. With GeneAnnotator, we propose Traffic Genome, a comprehensive scene graph dataset with 1000 diverse traffic images, which in return validates the effectiveness of the proposed software for scene graph annotation. The project source code, with usage examples and sample data is available at https://github.com/Milomilo0320/A-Semi-automatic-Annotation-Software-for-Scene-Graph, under the Apache open-source license.
Trustworthy Medical Segmentation with Uncertainty Estimation
Nov 10, 2021
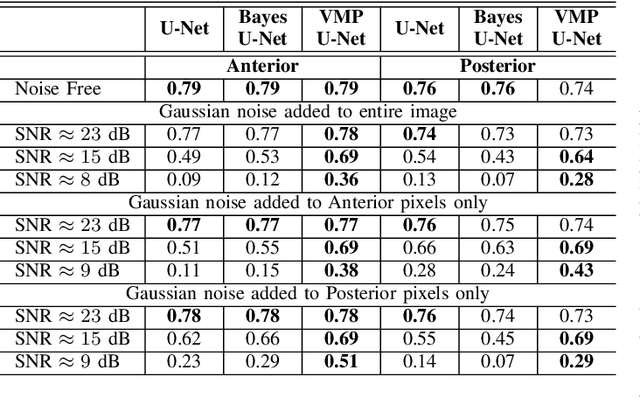
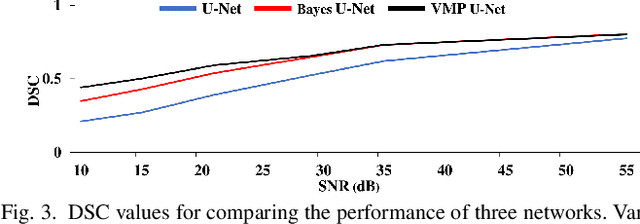

Deep Learning (DL) holds great promise in reshaping the healthcare systems given its precision, efficiency, and objectivity. However, the brittleness of DL models to noisy and out-of-distribution inputs is ailing their deployment in the clinic. Most systems produce point estimates without further information about model uncertainty or confidence. This paper introduces a new Bayesian deep learning framework for uncertainty quantification in segmentation neural networks, specifically encoder-decoder architectures. The proposed framework uses the first-order Taylor series approximation to propagate and learn the first two moments (mean and covariance) of the distribution of the model parameters given the training data by maximizing the evidence lower bound. The output consists of two maps: the segmented image and the uncertainty map of the segmentation. The uncertainty in the segmentation decisions is captured by the covariance matrix of the predictive distribution. We evaluate the proposed framework on medical image segmentation data from Magnetic Resonances Imaging and Computed Tomography scans. Our experiments on multiple benchmark datasets demonstrate that the proposed framework is more robust to noise and adversarial attacks as compared to state-of-the-art segmentation models. Moreover, the uncertainty map of the proposed framework associates low confidence (or equivalently high uncertainty) to patches in the test input images that are corrupted with noise, artifacts or adversarial attacks. Thus, the model can self-assess its segmentation decisions when it makes an erroneous prediction or misses part of the segmentation structures, e.g., tumor, by presenting higher values in the uncertainty map.
Coarse-to-Fine Reasoning for Visual Question Answering
Oct 06, 2021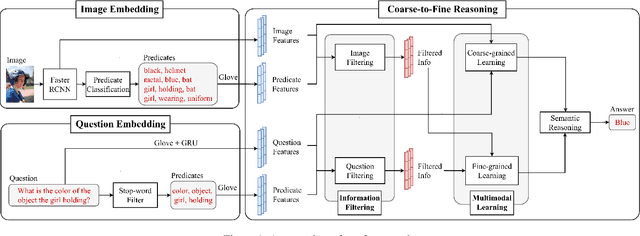
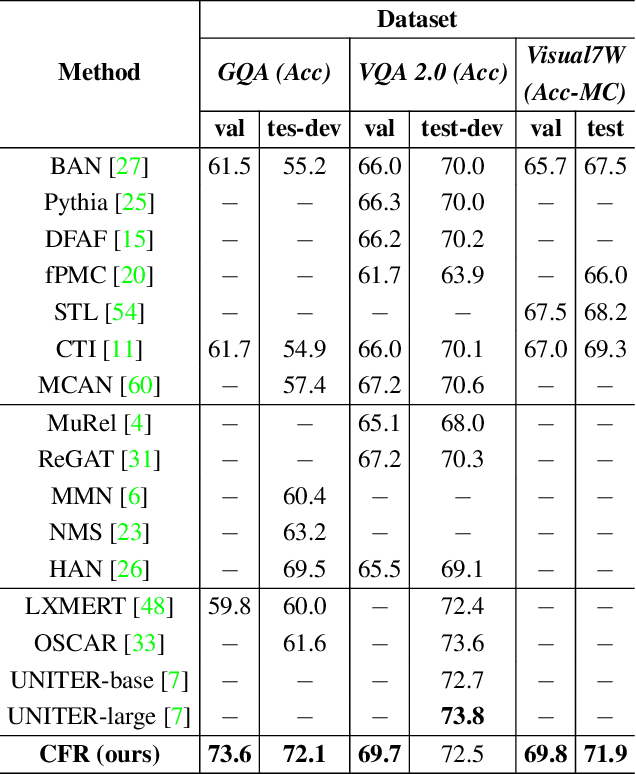
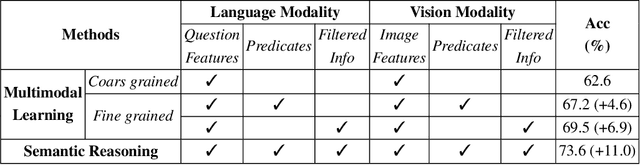
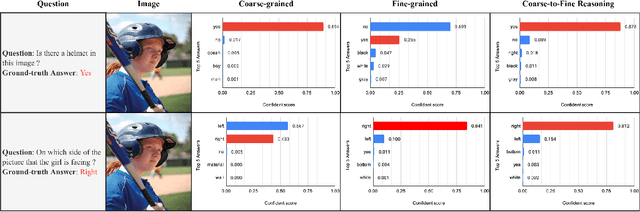
Bridging the semantic gap between image and question is an important step to improve the accuracy of the Visual Question Answering (VQA) task. However, most of the existing VQA methods focus on attention mechanisms or visual relations for reasoning the answer, while the features at different semantic levels are not fully utilized. In this paper, we present a new reasoning framework to fill the gap between visual features and semantic clues in the VQA task. Our method first extracts the features and predicates from the image and question. We then propose a new reasoning framework to effectively jointly learn these features and predicates in a coarse-to-fine manner. The intensively experimental results on three large-scale VQA datasets show that our proposed approach achieves superior accuracy comparing with other state-of-the-art methods. Furthermore, our reasoning framework also provides an explainable way to understand the decision of the deep neural network when predicting the answer.
Application of Video-to-Video Translation Networks to Computational Fluid Dynamics
Sep 12, 2021
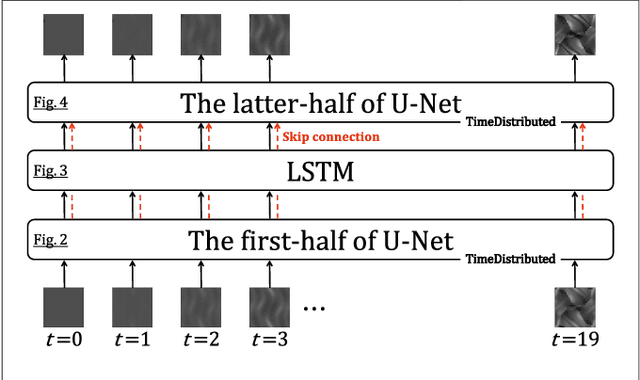
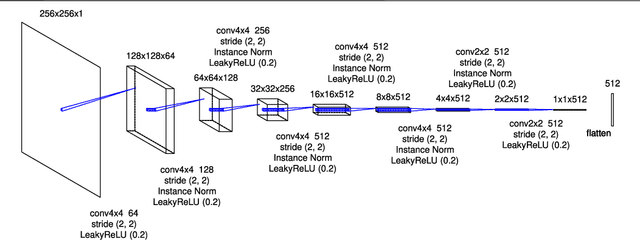

In recent years, the evolution of artificial intelligence, especially deep learning, has been remarkable, and its application to various fields has been growing rapidly. In this paper, I report the results of the application of generative adversarial networks (GANs), specifically video-to-video translation networks, to computational fluid dynamics (CFD) simulations. The purpose of this research is to reduce the computational cost of CFD simulations with GANs. The architecture of GANs in this research is a combination of the image-to-image translation networks (the so-called "pix2pix") and Long Short-Term Memory (LSTM). It is shown that the results of high-cost and high-accuracy simulations (with high-resolution computational grids) can be estimated from those of low-cost and low-accuracy simulations (with low-resolution grids). In particular, the time evolution of density distributions in the cases of a high-resolution grid is reproduced from that in the cases of a low-resolution grid through GANs, and the density inhomogeneity estimated from the image generated by GANs recovers the ground truth with good accuracy. Qualitative and quantitative comparisons of the results of the proposed method with those of several super-resolution algorithms are also presented.
Talking Head Generation with Audio and Speech Related Facial Action Units
Oct 19, 2021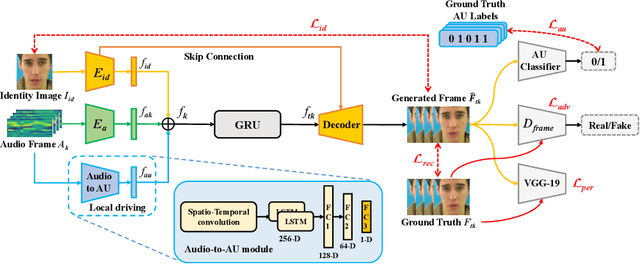
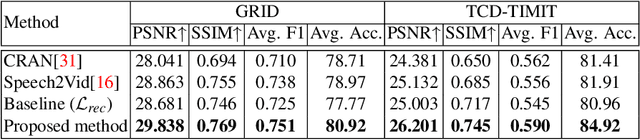


The task of talking head generation is to synthesize a lip synchronized talking head video by inputting an arbitrary face image and audio clips. Most existing methods ignore the local driving information of the mouth muscles. In this paper, we propose a novel recurrent generative network that uses both audio and speech-related facial action units (AUs) as the driving information. AU information related to the mouth can guide the movement of the mouth more accurately. Since speech is highly correlated with speech-related AUs, we propose an Audio-to-AU module in our system to predict the speech-related AU information from speech. In addition, we use AU classifier to ensure that the generated images contain correct AU information. Frame discriminator is also constructed for adversarial training to improve the realism of the generated face. We verify the effectiveness of our model on the GRID dataset and TCD-TIMIT dataset. We also conduct an ablation study to verify the contribution of each component in our model. Quantitative and qualitative experiments demonstrate that our method outperforms existing methods in both image quality and lip-sync accuracy.
G-VAE: A Continuously Variable Rate Deep Image Compression Framework
Mar 04, 2020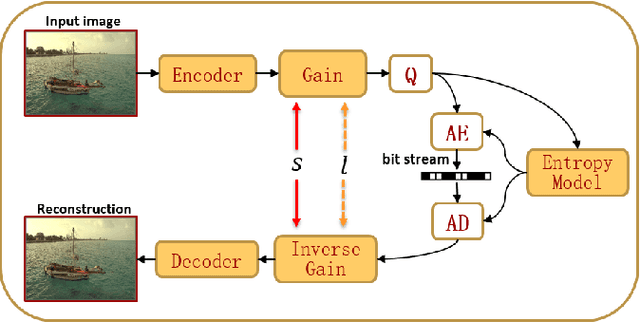

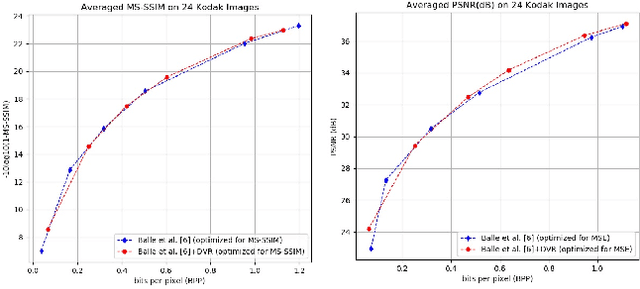
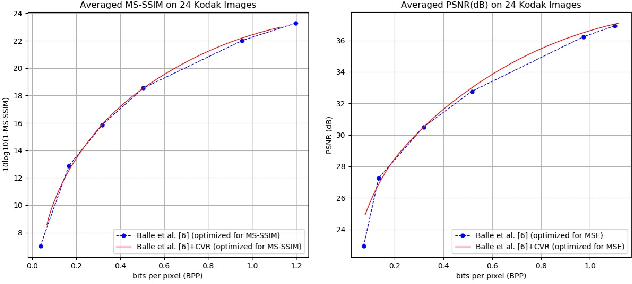
Rate adaption of deep image compression in a single model will become one of the decisive factors competing with the classical image compression codecs. However, until now, there is no perfect solution that neither increases the computation nor affects the compression performance. In this paper, we propose a novel image compression framework G-VAE (Gained Variational Autoencoder), which could achieve continuously variable rate in a single model. Unlike the previous solutions that encode progressively or change the internal unit of the network, G-VAE only adds a pair of gain units at the output of encoder and the input of decoder. It is so concise that G-VAE could be applied to almost all the image compression methods and achieve continuously variable rate with negligible additional parameters and computation. We also propose a new deep image compression framework, which outperforms all the published results on Kodak datasets in PSNR and MS-SSIM metrics. Experimental results show that adding a pair of gain units will not affect the performance of the basic models while endowing them with continuously variable rate.
Semantic-Based Few-Shot Learning by Interactive Psychometric Testing
Dec 16, 2021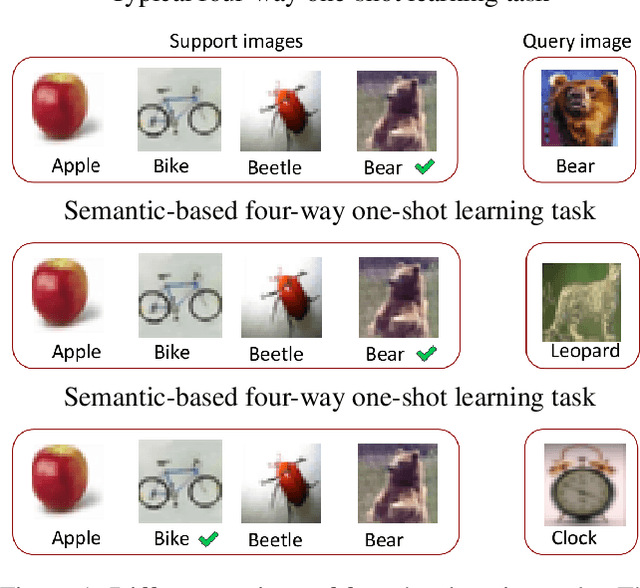

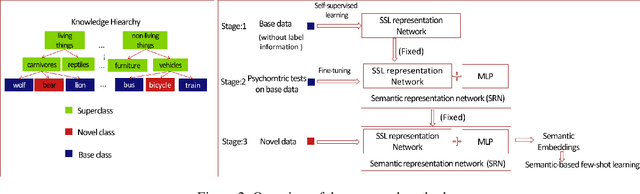

Few-shot classification tasks aim to classify images in query sets based on only a few labeled examples in support sets. Most studies usually assume that each image in a task has a single and unique class association. Under these assumptions, these algorithms may not be able to identify the proper class assignment when there is no exact matching between support and query classes. For example, given a few images of lions, bikes, and apples to classify a tiger. However, in a more general setting, we could consider the higher-level concept of large carnivores to match the tiger to the lion for semantic classification. Existing studies rarely considered this situation due to the incompatibility of label-based supervision with complex conception relationships. In this work, we advanced the few-shot learning towards this more challenging scenario, the semantic-based few-shot learning, and proposed a method to address the paradigm by capturing the inner semantic relationships using interactive psychometric learning. We evaluate our method on the CIFAR-100 dataset. The results show the merits of our proposed method.
Automated Seed Quality Testing System using GAN & Active Learning
Oct 02, 2021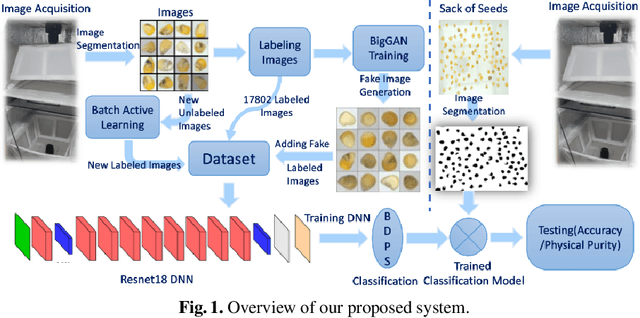
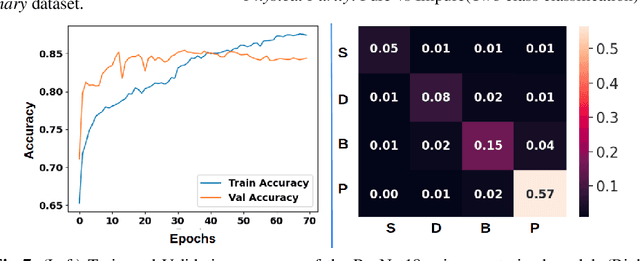


Quality assessment of agricultural produce is a crucial step in minimizing food stock wastage. However, this is currently done manually and often requires expert supervision, especially in smaller seeds like corn. We propose a novel computer vision-based system for automating this process. We build a novel seed image acquisition setup, which captures both the top and bottom views. Dataset collection for this problem has challenges of data annotation costs/time and class imbalance. We address these challenges by i.) using a Conditional Generative Adversarial Network (CGAN) to generate real-looking images for the classes with lesser images and ii.) annotate a large dataset with minimal expert human intervention by using a Batch Active Learning (BAL) based annotation tool. We benchmark different image classification models on the dataset obtained. We are able to get accuracies of up to 91.6% for testing the physical purity of seed samples.
High Fidelity Visualization of What Your Self-Supervised Representation Knows About
Dec 16, 2021


Discovering what is learned by neural networks remains a challenge. In self-supervised learning, classification is the most common task used to evaluate how good a representation is. However, relying only on such downstream task can limit our understanding of how much information is retained in the representation of a given input. In this work, we showcase the use of a conditional diffusion based generative model (RCDM) to visualize representations learned with self-supervised models. We further demonstrate how this model's generation quality is on par with state-of-the-art generative models while being faithful to the representation used as conditioning. By using this new tool to analyze self-supervised models, we can show visually that i) SSL (backbone) representation are not really invariant to many data augmentation they were trained on. ii) SSL projector embedding appear too invariant for tasks like classifications. iii) SSL representations are more robust to small adversarial perturbation of their inputs iv) there is an inherent structure learned with SSL model that can be used for image manipulation.