 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Exploring Fusion Strategies for Accurate RGBT Visual Object Tracking
Jan 21, 2022

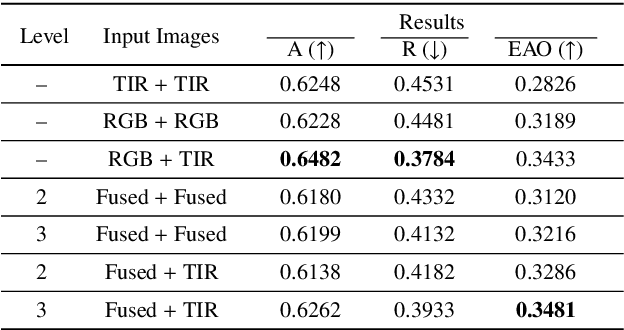
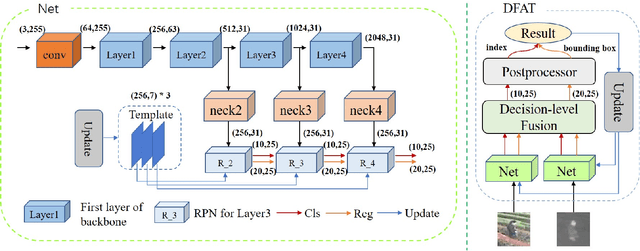
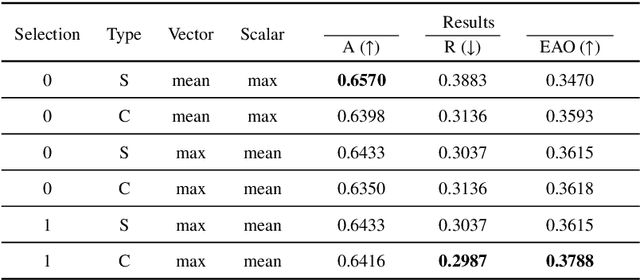
We address the problem of multi-modal object tracking in video and explore various options of fusing the complementary information conveyed by the visible (RGB) and thermal infrared (TIR) modalities including pixel-level, feature-level and decision-level fusion. Specifically, different from the existing methods, paradigm of image fusion task is heeded for fusion at pixel level. Feature-level fusion is fulfilled by attention mechanism with channels excited optionally. Besides, at decision level, a novel fusion strategy is put forward since an effortless averaging configuration has shown the superiority. The effectiveness of the proposed decision-level fusion strategy owes to a number of innovative contributions, including a dynamic weighting of the RGB and TIR contributions and a linear template update operation. A variant of which produced the winning tracker at the Visual Object Tracking Challenge 2020 (VOT-RGBT2020). The concurrent exploration of innovative pixel- and feature-level fusion strategies highlights the advantages of the proposed decision-level fusion method. Extensive experimental results on three challenging datasets, \textit{i.e.}, GTOT, VOT-RGBT2019, and VOT-RGBT2020, demonstrate the effectiveness and robustness of the proposed method, compared to the state-of-the-art approaches. Code will be shared at \textcolor{blue}{\emph{https://github.com/Zhangyong-Tang/DFAT}.
Creating A Coefficient of Change in the Built Environment After a Natural Disaster
Nov 09, 2021

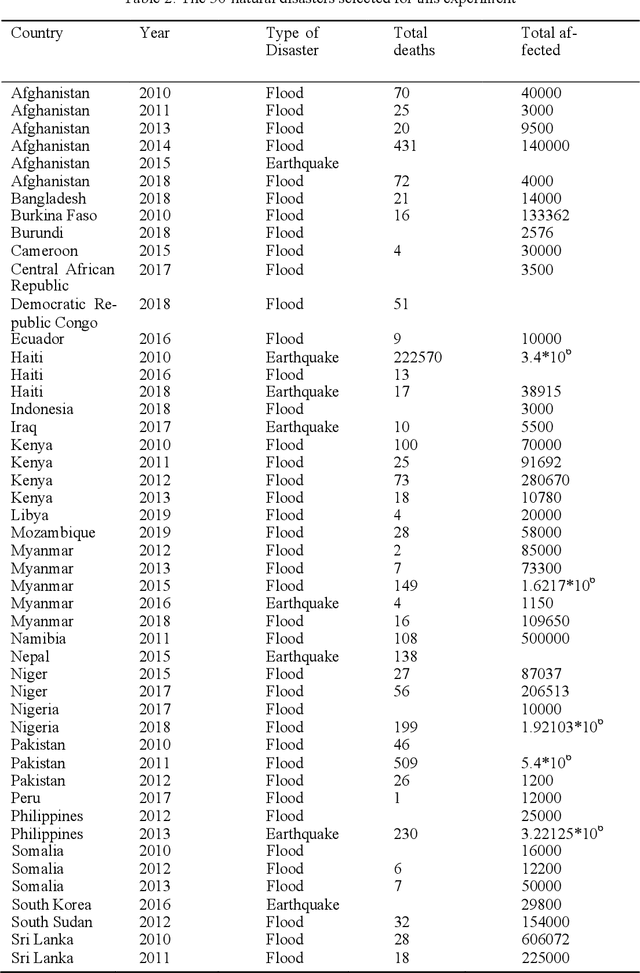
This study proposes a novel method to assess damages in the built environment using a deep learning workflow to quantify it. Thanks to an automated crawler, aerial images from before and after a natural disaster of 50 epicenters worldwide were obtained from Google Earth, generating a 10,000 aerial image database with a spatial resolution of 2 m per pixel. The study utilizes the algorithm Seg-Net to perform semantic segmentation of the built environment from the satellite images in both instances (prior and post-natural disasters). For image segmentation, Seg-Net is one of the most popular and general CNN architectures. The Seg-Net algorithm used reached an accuracy of 92% in the segmentation. After the segmentation, we compared the disparity between both cases represented as a percentage of change. Such coefficient of change represents the damage numerically an urban environment had to quantify the overall damage in the built environment. Such an index can give the government an estimate of the number of affected households and perhaps the extent of housing damage.
Pollen13K: A Large Scale Microscope Pollen Grain Image Dataset
Jul 09, 2020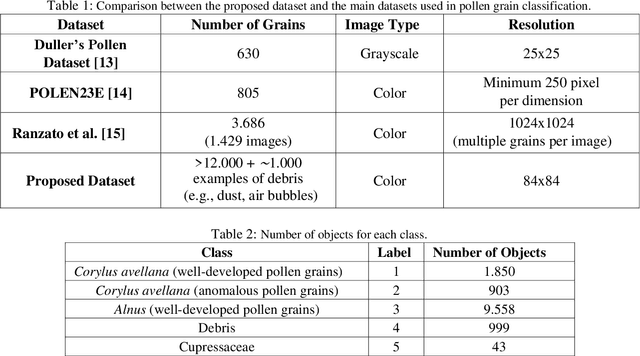



Pollen grain classification has a remarkable role in many fields from medicine to biology and agronomy. Indeed, automatic pollen grain classification is an important task for all related applications and areas. This work presents the first large-scale pollen grain image dataset, including more than 13 thousands objects. After an introduction to the problem of pollen grain classification and its motivations, the paper focuses on the employed data acquisition steps, which include aerobiological sampling, microscope image acquisition, object detection, segmentation and labelling. Furthermore, a baseline experimental assessment for the task of pollen classification on the built dataset, together with discussion on the achieved results, is presented.
A Systematic Comparison of Encrypted Machine Learning Solutions for Image Classification
Nov 11, 2020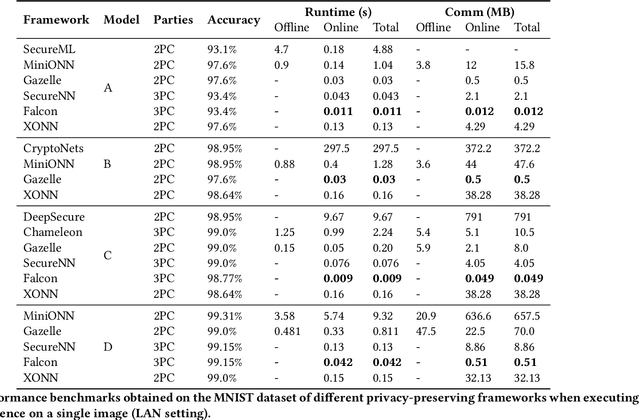
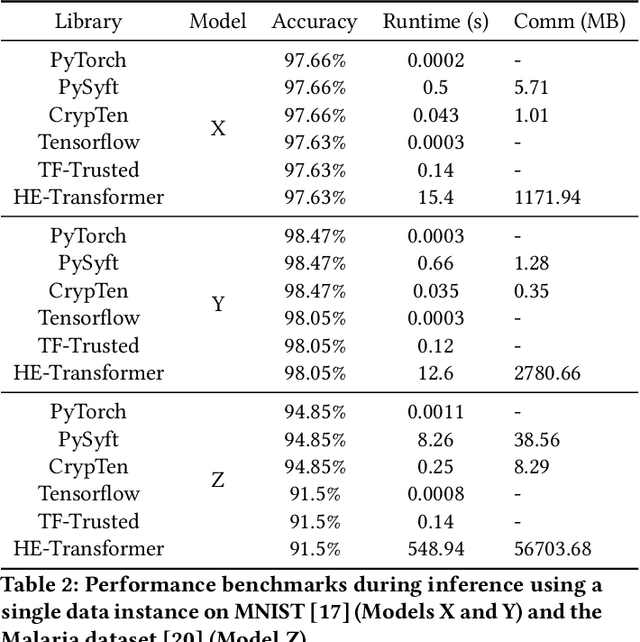
This work provides a comprehensive review of existing frameworks based on secure computing techniques in the context of private image classification. The in-depth analysis of these approaches is followed by careful examination of their performance costs, in particular runtime and communication overhead. To further illustrate the practical considerations when using different privacy-preserving technologies, experiments were conducted using four state-of-the-art libraries implementing secure computing at the heart of the data science stack: PySyft and CrypTen supporting private inference via Secure Multi-Party Computation, TF-Trusted utilising Trusted Execution Environments and HE- Transformer relying on Homomorphic encryption. Our work aims to evaluate the suitability of these frameworks from a usability, runtime requirements and accuracy point of view. In order to better understand the gap between state-of-the-art protocols and what is currently available in practice for a data scientist, we designed three neural network architecture to obtain secure predictions via each of the four aforementioned frameworks. Two networks were evaluated on the MNIST dataset and one on the Malaria Cell image dataset. We observed satisfying performances for TF-Trusted and CrypTen and noted that all frameworks perfectly preserved the accuracy of the corresponding plaintext model.
Self-supervised Enhancement of Latent Discovery in GANs
Dec 16, 2021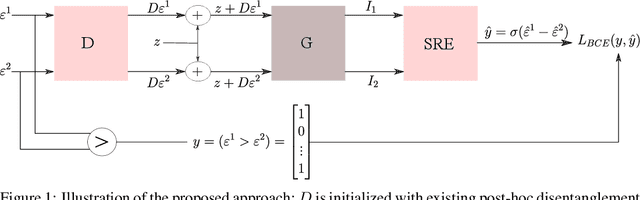


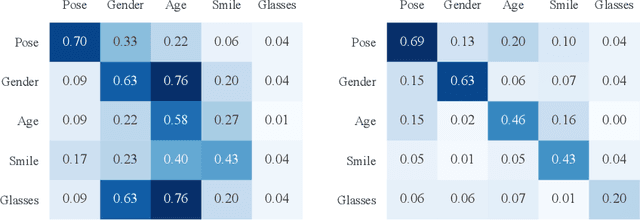
Several methods for discovering interpretable directions in the latent space of pre-trained GANs have been proposed. Latent semantics discovered by unsupervised methods are relatively less disentangled than supervised methods since they do not use pre-trained attribute classifiers. We propose Scale Ranking Estimator (SRE), which is trained using self-supervision. SRE enhances the disentanglement in directions obtained by existing unsupervised disentanglement techniques. These directions are updated to preserve the ordering of variation within each direction in latent space. Qualitative and quantitative evaluation of the discovered directions demonstrates that our proposed method significantly improves disentanglement in various datasets. We also show that the learned SRE can be used to perform Attribute-based image retrieval task without further training.
Finding Biological Plausibility for Adversarially Robust Features via Metameric Tasks
Feb 04, 2022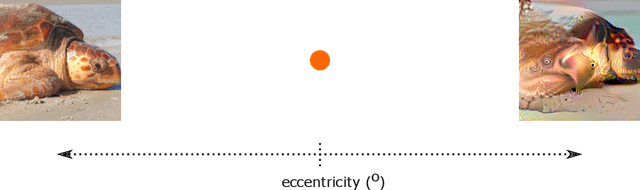
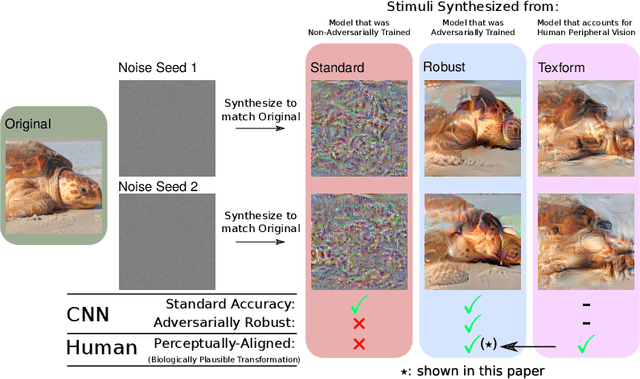
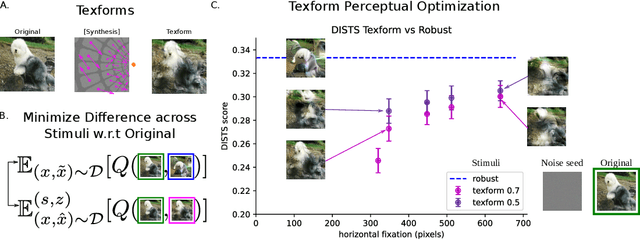
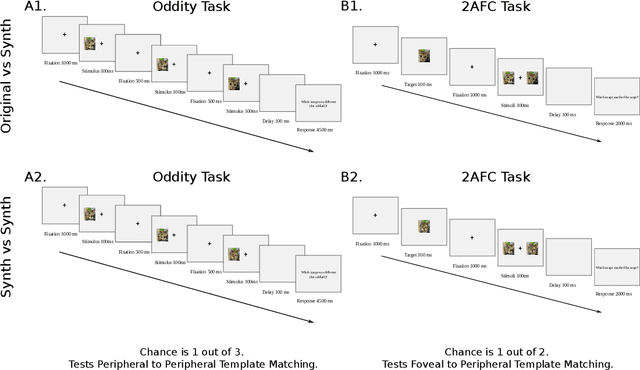
Recent work suggests that representations learned by adversarially robust networks are more human perceptually-aligned than non-robust networks via image manipulations. Despite appearing closer to human visual perception, it is unclear if the constraints in robust DNN representations match biological constraints found in human vision. Human vision seems to rely on texture-based/summary statistic representations in the periphery, which have been shown to explain phenomena such as crowding and performance on visual search tasks. To understand how adversarially robust optimizations/representations compare to human vision, we performed a psychophysics experiment using a set of metameric discrimination tasks where we evaluated how well human observers could distinguish between images synthesized to match adversarially robust representations compared to non-robust representations and a texture synthesis model of peripheral vision (Texforms). We found that the discriminability of robust representation and texture model images decreased to near chance performance as stimuli were presented farther in the periphery. Moreover, performance on robust and texture-model images showed similar trends within participants, while performance on non-robust representations changed minimally across the visual field. These results together suggest that (1) adversarially robust representations capture peripheral computation better than non-robust representations and (2) robust representations capture peripheral computation similar to current state-of-the-art texture peripheral vision models. More broadly, our findings support the idea that localized texture summary statistic representations may drive human invariance to adversarial perturbations and that the incorporation of such representations in DNNs could give rise to useful properties like adversarial robustness.
Benchmarking Pedestrian Odometry: The Brown Pedestrian Odometry Dataset (BPOD)
Dec 24, 2021
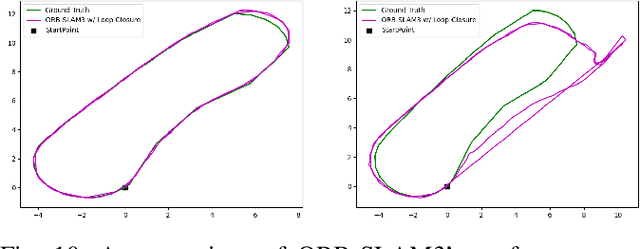
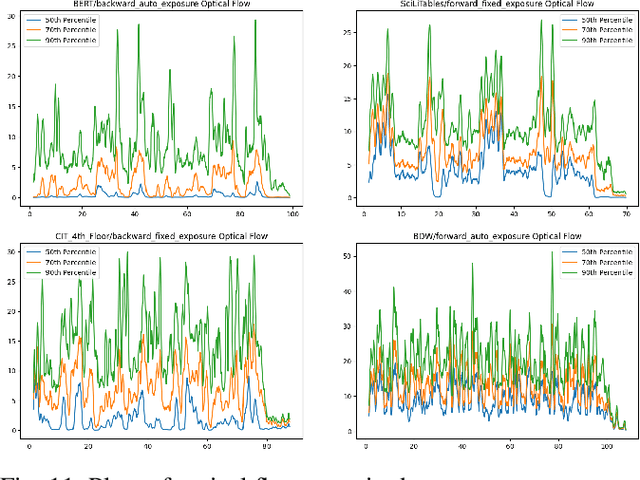

We present the Brown Pedestrian Odometry Dataset (BPOD) for benchmarking visual odometry algorithms in head-mounted pedestrian settings. This dataset was captured using synchronized global and rolling shutter stereo cameras in 12 diverse indoor and outdoor locations on Brown University's campus. Compared to existing datasets, BPOD contains more image blur and self-rotation, which are common in pedestrian odometry but rare elsewhere. Ground-truth trajectories are generated from stick-on markers placed along the pedestrian's path, and the pedestrian's position is documented using a third-person video. We evaluate the performance of representative direct, feature-based, and learning-based VO methods on BPOD. Our results show that significant development is needed to successfully capture pedestrian trajectories. The link to the dataset is here: \url{https://doi.org/10.26300/c1n7-7p93
Region-level Active Learning for Cluttered Scenes
Aug 20, 2021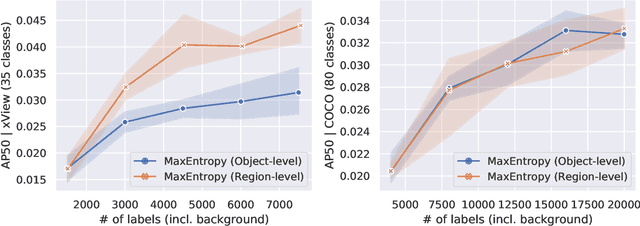
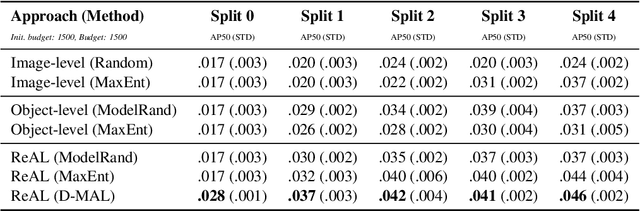
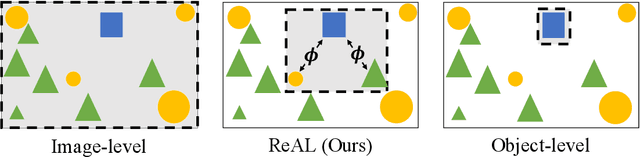
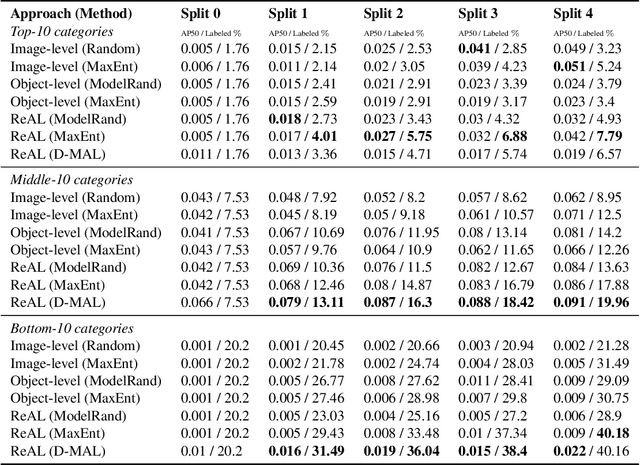
Active learning for object detection is conventionally achieved by applying techniques developed for classification in a way that aggregates individual detections into image-level selection criteria. This is typically coupled with the costly assumption that every image selected for labelling must be exhaustively annotated. This yields incremental improvements on well-curated vision datasets and struggles in the presence of data imbalance and visual clutter that occurs in real-world imagery. Alternatives to the image-level approach are surprisingly under-explored in the literature. In this work, we introduce a new strategy that subsumes previous Image-level and Object-level approaches into a generalized, Region-level approach that promotes spatial-diversity by avoiding nearby redundant queries from the same image and minimizes context-switching for the labeler. We show that this approach significantly decreases labeling effort and improves rare object search on realistic data with inherent class-imbalance and cluttered scenes.
Self-Supervision based Task-Specific Image Collection Summarization
Dec 19, 2020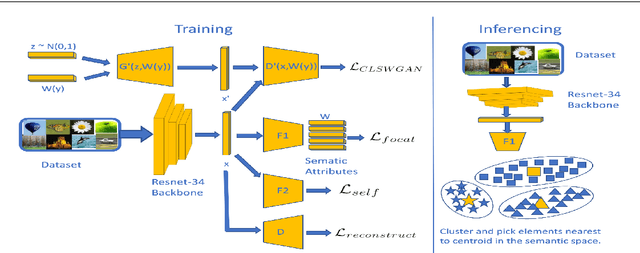
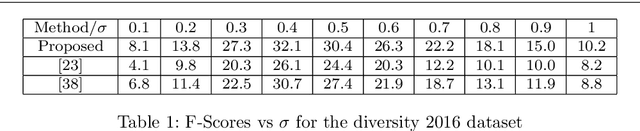
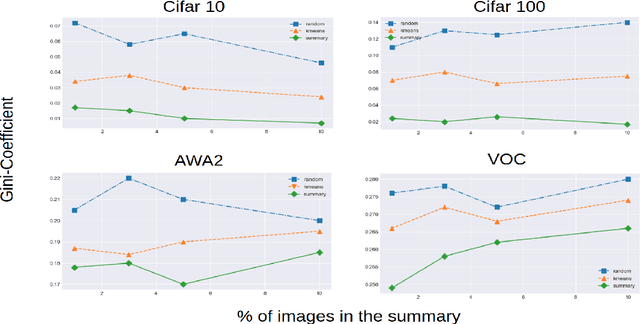
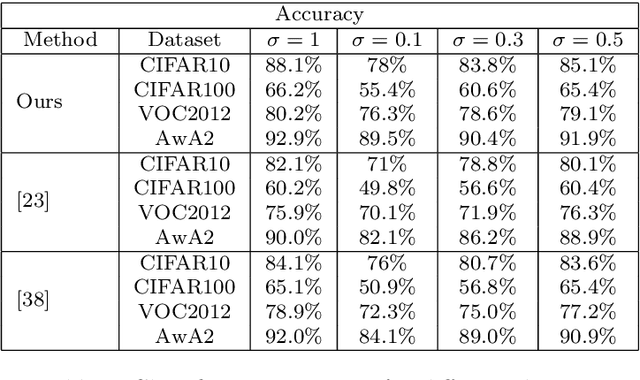
Successful applications of deep learning (DL) requires large amount of annotated data. This often restricts the benefits of employing DL to businesses and individuals with large budgets for data-collection and computation. Summarization offers a possible solution by creating much smaller representative datasets that can allow real-time deep learning and analysis of big data and thus democratize use of DL. In the proposed work, our aim is to explore a novel approach to task-specific image corpus summarization using semantic information and self-supervision. Our method uses a classification-based Wasserstein generative adversarial network (CLSWGAN) as a feature generating network. The model also leverages rotational invariance as self-supervision and classification on another task. All these objectives are added on a features from resnet34 to make it discriminative and robust. The model then generates a summary at inference time by using K-means clustering in the semantic embedding space. Thus, another main advantage of this model is that it does not need to be retrained each time to obtain summaries of different lengths which is an issue with current end-to-end models. We also test our model efficacy by means of rigorous experiments both qualitatively and quantitatively.
EPNet: Enhancing Point Features with Image Semantics for 3D Object Detection
Jul 17, 2020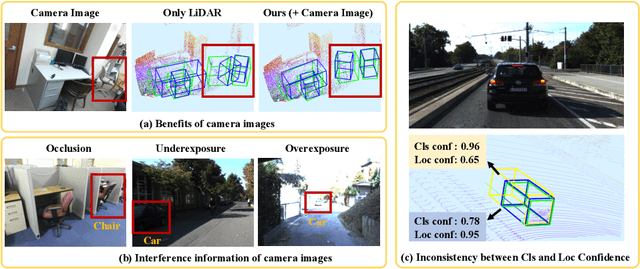
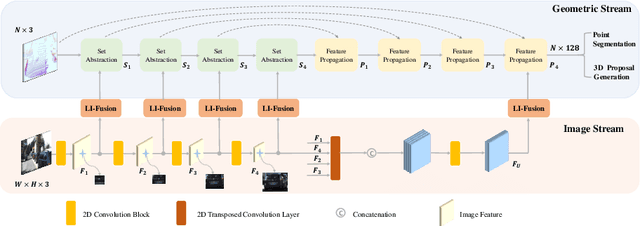
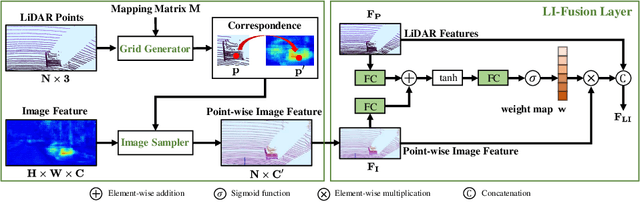

In this paper, we aim at addressing two critical issues in the 3D detection task, including the exploitation of multiple sensors~(namely LiDAR point cloud and camera image), as well as the inconsistency between the localization and classification confidence. To this end, we propose a novel fusion module to enhance the point features with semantic image features in a point-wise manner without any image annotations. Besides, a consistency enforcing loss is employed to explicitly encourage the consistency of both the localization and classification confidence. We design an end-to-end learnable framework named EPNet to integrate these two components. Extensive experiments on the KITTI and SUN-RGBD datasets demonstrate the superiority of EPNet over the state-of-the-art methods. Codes and models are available at: \url{https://github.com/happinesslz/EPNet}.