 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Neighborhood Region Smoothing Regularization for Finding Flat Minima In Deep Neural Networks
Jan 16, 2022
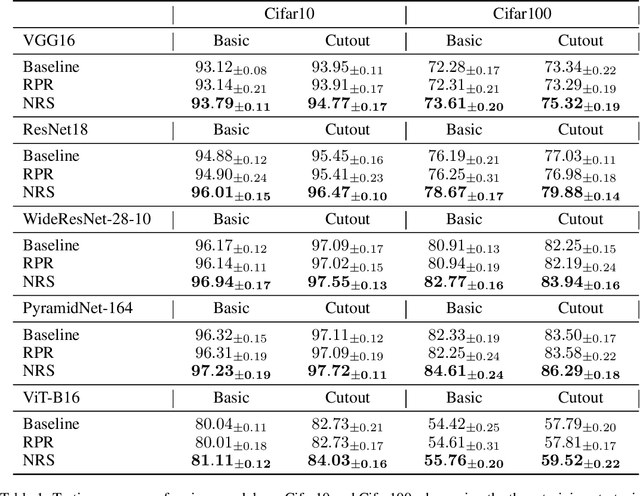
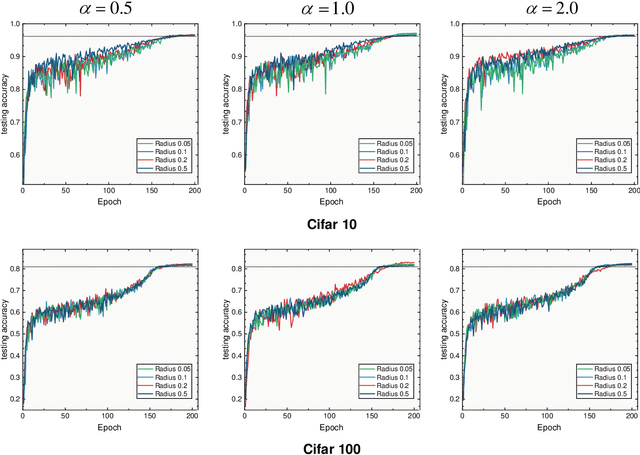
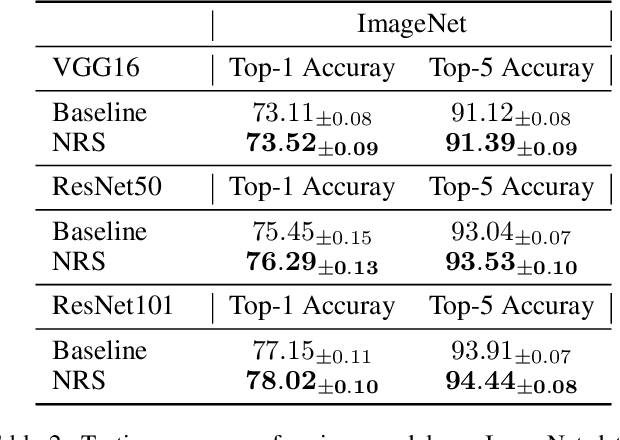
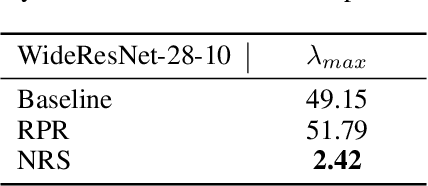
Due to diverse architectures in deep neural networks (DNNs) with severe overparameterization, regularization techniques are critical for finding optimal solutions in the huge hypothesis space. In this paper, we propose an effective regularization technique, called Neighborhood Region Smoothing (NRS). NRS leverages the finding that models would benefit from converging to flat minima, and tries to regularize the neighborhood region in weight space to yield approximate outputs. Specifically, gap between outputs of models in the neighborhood region is gauged by a defined metric based on Kullback-Leibler divergence. This metric provides similar insights with the minimum description length principle on interpreting flat minima. By minimizing both this divergence and empirical loss, NRS could explicitly drive the optimizer towards converging to flat minima. We confirm the effectiveness of NRS by performing image classification tasks across a wide range of model architectures on commonly-used datasets such as CIFAR and ImageNet, where generalization ability could be universally improved. Also, we empirically show that the minima found by NRS would have relatively smaller Hessian eigenvalues compared to the conventional method, which is considered as the evidence of flat minima.
TMBuD: A dataset for urban scene building detection
Oct 27, 2021
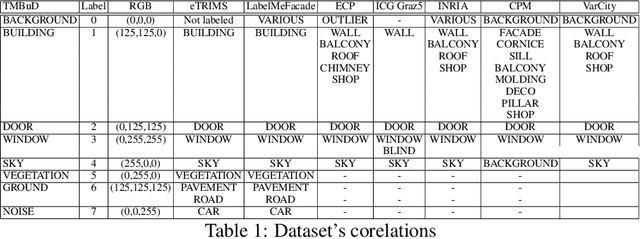


Building recognition and 3D reconstruction of human made structures in urban scenarios has become an interesting and actual topic in the image processing domain. For this research topic the Computer Vision and Augmented Reality areas intersect for creating a better understanding of the urban scenario for various topics. In this paper we aim to introduce a dataset solution, the TMBuD, that is better fitted for image processing on human made structures for urban scene scenarios. The proposed dataset will allow proper evaluation of salient edges and semantic segmentation of images focusing on the street view perspective of buildings. The images that form our dataset offer various street view perspectives of buildings from urban scenarios, which allows for evaluating complex algorithms. The dataset features 160 images of buildings from Timisoara, Romania, with a resolution of 768 x 1024 pixels each.
Learning with convolution and pooling operations in kernel methods
Nov 16, 2021
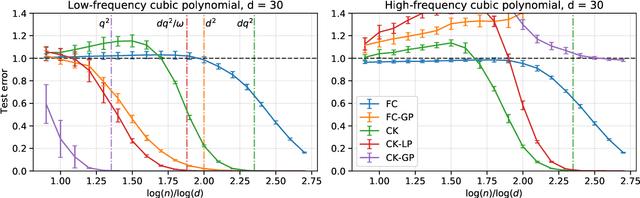
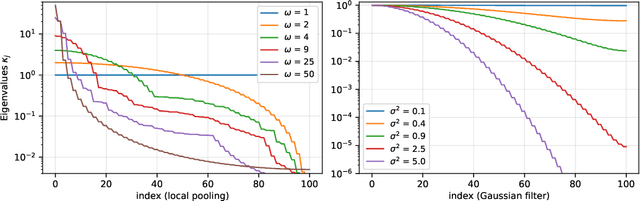
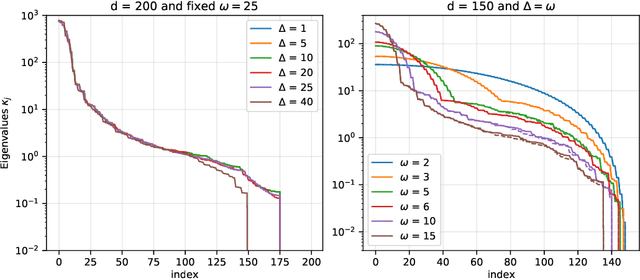
Recent empirical work has shown that hierarchical convolutional kernels inspired by convolutional neural networks (CNNs) significantly improve the performance of kernel methods in image classification tasks. A widely accepted explanation for the success of these architectures is that they encode hypothesis classes that are suitable for natural images. However, understanding the precise interplay between approximation and generalization in convolutional architectures remains a challenge. In this paper, we consider the stylized setting of covariates (image pixels) uniformly distributed on the hypercube, and fully characterize the RKHS of kernels composed of single layers of convolution, pooling, and downsampling operations. We then study the gain in sample efficiency of kernel methods using these kernels over standard inner-product kernels. In particular, we show that 1) the convolution layer breaks the curse of dimensionality by restricting the RKHS to `local' functions; 2) local pooling biases learning towards low-frequency functions, which are stable by small translations; 3) downsampling may modify the high-frequency eigenspaces but leaves the low-frequency part approximately unchanged. Notably, our results quantify how choosing an architecture adapted to the target function leads to a large improvement in the sample complexity.
Is Contrastive Learning Suitable for Left Ventricular Segmentation in Echocardiographic Images?
Jan 16, 2022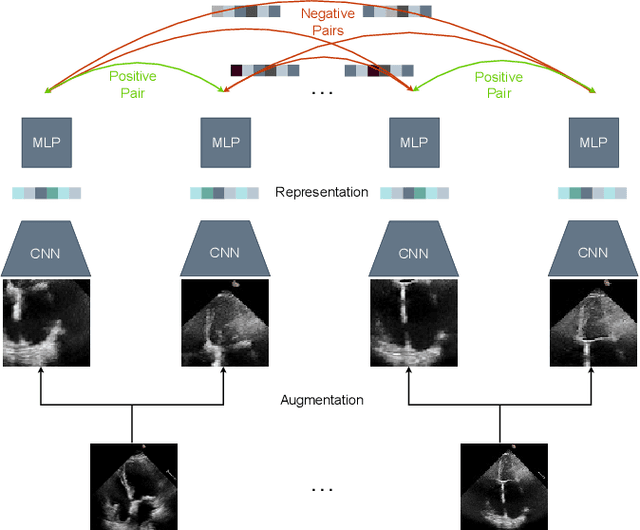
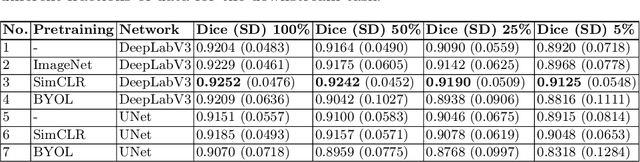
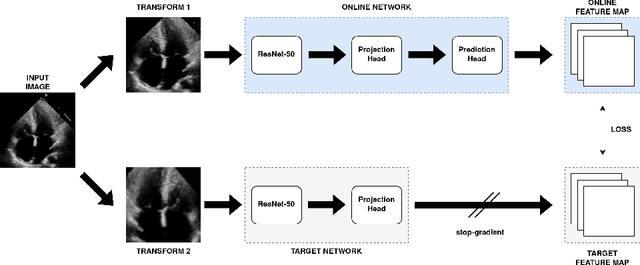
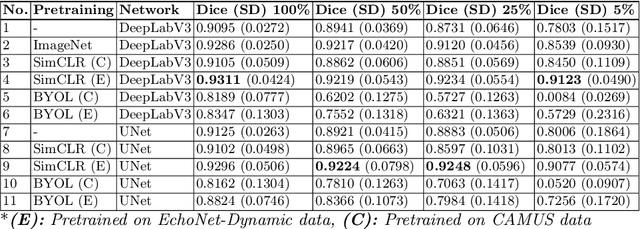
Contrastive learning has proven useful in many applications where access to labelled data is limited. The lack of annotated data is particularly problematic in medical image segmentation as it is difficult to have clinical experts manually annotate large volumes of data. One such task is the segmentation of cardiac structures in ultrasound images of the heart. In this paper, we argue whether or not contrastive pretraining is helpful for the segmentation of the left ventricle in echocardiography images. Furthermore, we study the effect of this on two segmentation networks, DeepLabV3, as well as the commonly used segmentation network, UNet. Our results show that contrastive pretraining helps improve the performance on left ventricle segmentation, particularly when annotated data is scarce. We show how to achieve comparable results to state-of-the-art fully supervised algorithms when we train our models in a self-supervised fashion followed by fine-tuning on just 5% of the data. We also show that our solution achieves better results than what is currently published on a large public dataset (EchoNet-Dynamic) and we compare the performance of our solution on another smaller dataset (CAMUS) as well.
Image-Based Multi-UAV Tracking System in a Cluttered Environment
Sep 15, 2021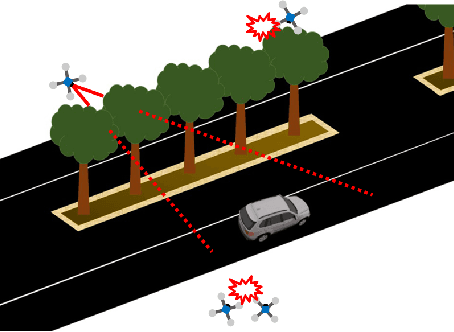
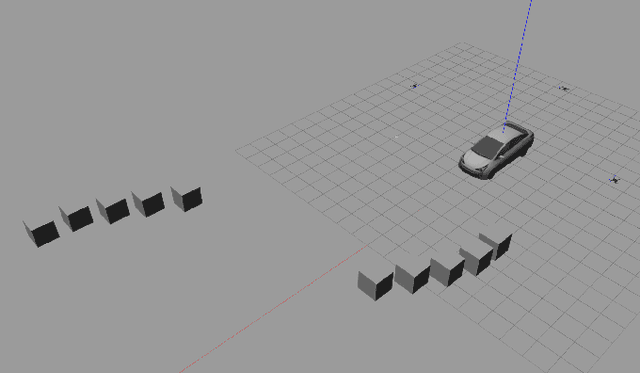
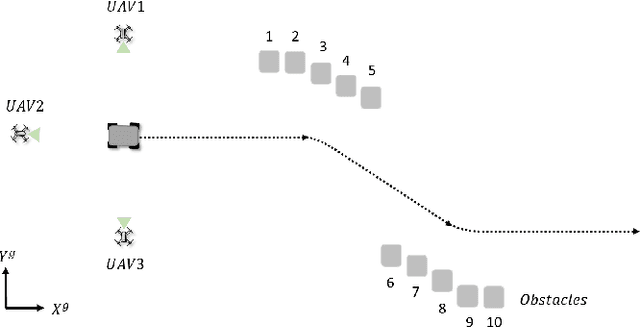
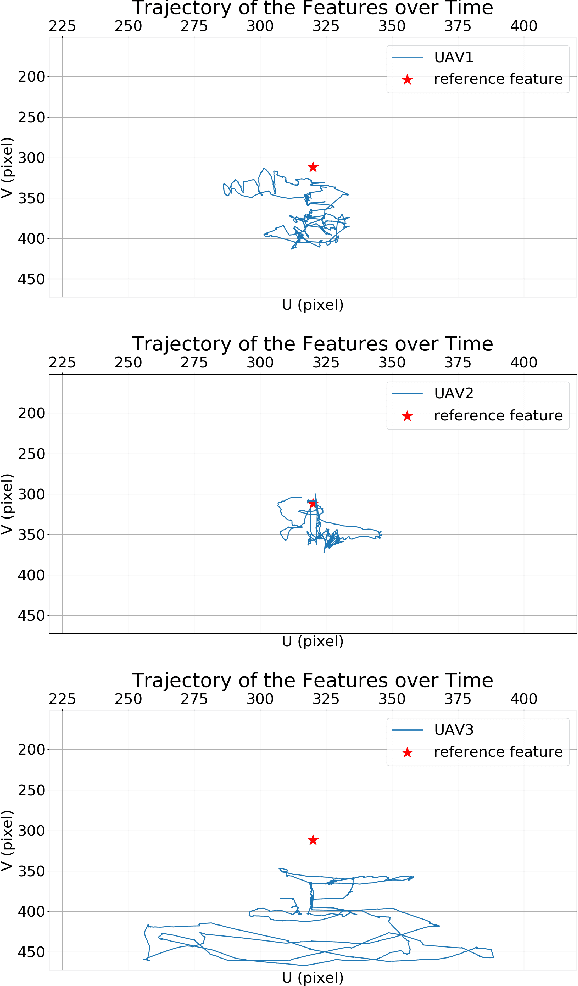
A tracking controller for unmanned aerial vehicles (UAVs) is developed to track moving targets undergoing unknown translational and rotational motions. The main challenges are to control both the relative positions and angles between the target and the UAVs to within desired values, and to guarantee that the generated control inputs to the UAVs are feasible (i.e., within their motion capabilities). Moreover, the UAVs are controlled to ensure that the target always remains within the fields of view of their onboard cameras. To the best of our knowledge, this is the first work to apply multiple UAVs to cooperatively track a dynamic target while ensuring that the UAVs remain connected and that both occlusion and collisions are avoided. To achieve these control objectives, a designed controller solved based on the aforementioned tracking controller using quadratic programming can generate minimally invasive control actions to achieve occlusion avoidance and collision avoidance. Furthermore, control barrier functions (CBFs) with a distributed design are developed in order to reduce the amount of inter-UAV communication. Simulations were performed to assess the efficacy and performance of the developed CBF-based controller for the multi-UAV system in tracking a target.
A bone suppression model ensemble to improve COVID-19 detection in chest X-rays
Nov 05, 2021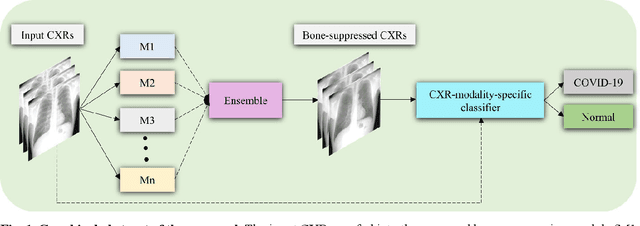
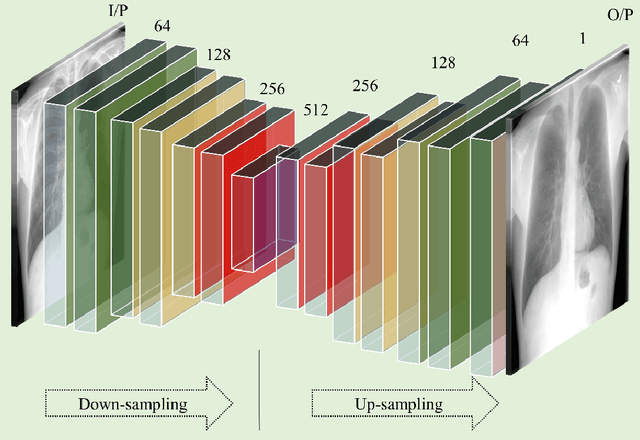
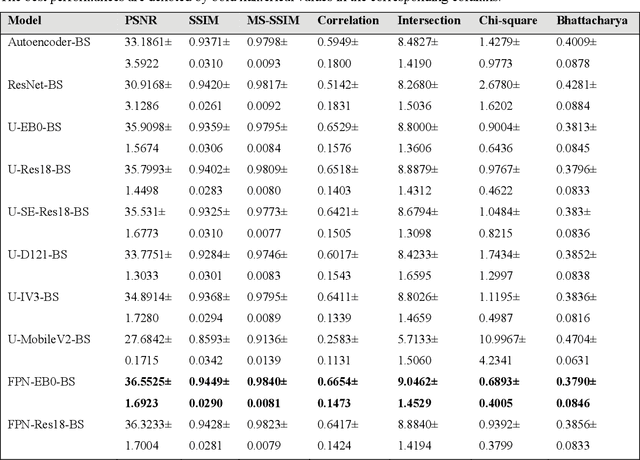
Chest X-ray (CXR) is a widely performed radiology examination that helps to detect abnormalities in the tissues and organs in the thoracic cavity. Detecting pulmonary abnormalities like COVID-19 may become difficult due to that they are obscured by the presence of bony structures like the ribs and the clavicles, thereby resulting in screening/diagnostic misinterpretations. Automated bone suppression methods would help suppress these bony structures and increase soft tissue visibility. In this study, we propose to build an ensemble of convolutional neural network models to suppress bones in frontal CXRs, improve classification performance, and reduce interpretation errors related to COVID-19 detection. The ensemble is constructed by (i) measuring the multi-scale structural similarity index (MS-SSIM) score between the sub-blocks of the bone-suppressed image predicted by each of the top-3 performing bone-suppression models and the corresponding sub-blocks of its respective ground truth soft-tissue image, and (ii) performing a majority voting of the MS-SSIM score computed in each sub-block to identify the sub-block with the maximum MS-SSIM score and use it in constructing the final bone-suppressed image. We empirically determine the sub-block size that delivers superior bone suppression performance. It is observed that the bone suppression model ensemble outperformed the individual models in terms of MS-SSIM and other metrics. A CXR modality-specific classification model is retrained and evaluated on the non-bone-suppressed and bone-suppressed images to classify them as showing normal lungs or other COVID-19-like manifestations. We observed that the bone-suppressed model training significantly outperformed the model trained on non-bone-suppressed images toward detecting COVID-19 manifestations.
Understanding Image Captioning Models beyond Visualizing Attention
Jan 04, 2020

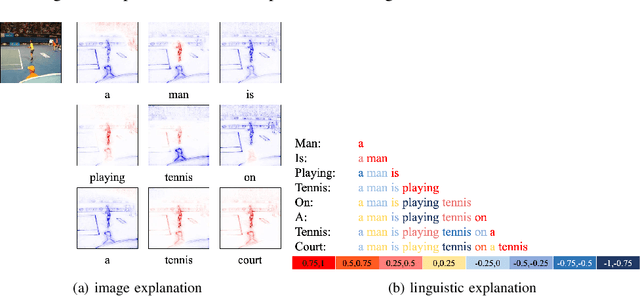
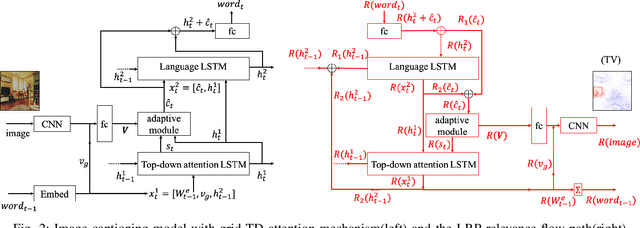
This paper explains predictions of image captioning models with attention mechanisms beyond visualizing the attention itself. In this paper, we develop variants of layer-wise relevance backpropagation (LRP) and gradient backpropagation, tailored to image captioning with attention. The result provides simultaneously pixel-wise image explanation and linguistic explanation for each word in the captions. We show that given a word in the caption to be explained, explanation methods such as LRP reveal supporting and opposing pixels as well as words. We compare the properties of attention heatmaps systematically against those computed with explanation methods such as LRP, Grad-CAM and Guided Grad-CAM. We show that explanation methods, firstly, correlate to object locations with higher precision than attention, secondly, are able to identify object words that are unsupported by image content, and thirdly, provide guidance to debias and improve the model. Results are reported for image captioning using two different attention models trained with Flickr30K and MSCOCO2017 datasets. Experimental analyses show the strength of explanation methods for understanding image captioning attention models.
Intrinsic Autoencoders for Joint Neural Rendering and Intrinsic Image Decomposition
Jun 29, 2020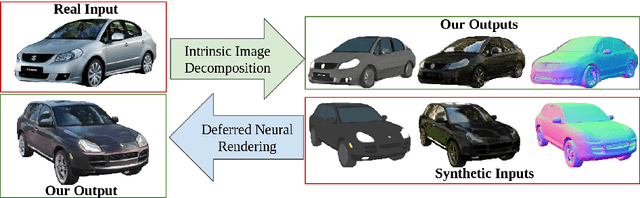

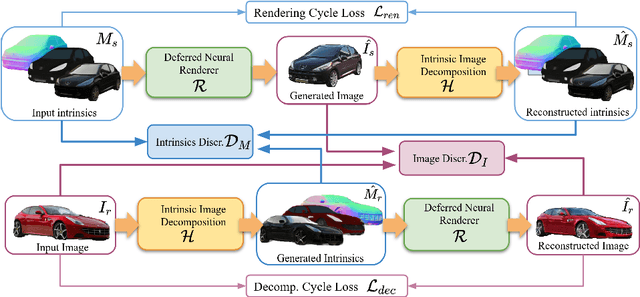
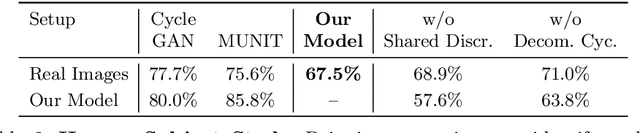
Neural rendering techniques promise efficient photo-realistic image synthesis while at the same time providing rich control over scene parameters by learning the physical image formation process. While several supervised methods have been proposed for this task, acquiring a dataset of images with accurately aligned 3D models is very difficult. The main contribution of this work is to lift this restriction by training a neural rendering algorithm from unpaired data. More specifically, we propose an autoencoder for joint generation of realistic images from synthetic 3D models while simultaneously decomposing real images into their intrinsic shape and appearance properties. In contrast to a traditional graphics pipeline, our approach does not require to specify all scene properties, such as material parameters and lighting by hand. Instead, we learn photo-realistic deferred rendering from a small set of 3D models and a larger set of unaligned real images, both of which are easy to acquire in practice. Simultaneously, we obtain accurate intrinsic decompositions of real images while not requiring paired ground truth. Our experiments confirm that a joint treatment of rendering and decomposition is indeed beneficial and that our approach outperforms state-of-the-art image-to-image translation baselines both qualitatively and quantitatively.
Pollen13K: A Large Scale Microscope Pollen Grain Image Dataset
Jul 09, 2020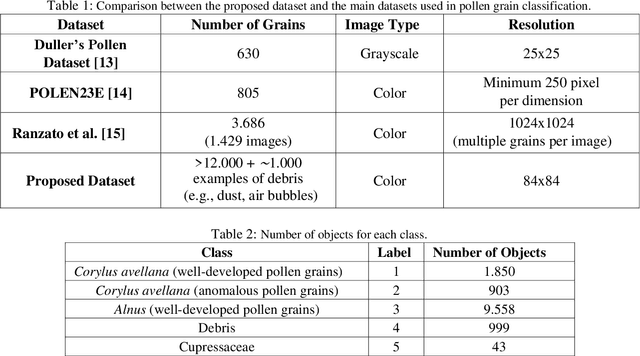



Pollen grain classification has a remarkable role in many fields from medicine to biology and agronomy. Indeed, automatic pollen grain classification is an important task for all related applications and areas. This work presents the first large-scale pollen grain image dataset, including more than 13 thousands objects. After an introduction to the problem of pollen grain classification and its motivations, the paper focuses on the employed data acquisition steps, which include aerobiological sampling, microscope image acquisition, object detection, segmentation and labelling. Furthermore, a baseline experimental assessment for the task of pollen classification on the built dataset, together with discussion on the achieved results, is presented.
SparseAlign: A Super-Resolution Algorithm for Automatic Marker Localization and Deformation Estimation in Cryo-Electron Tomography
Jan 21, 2022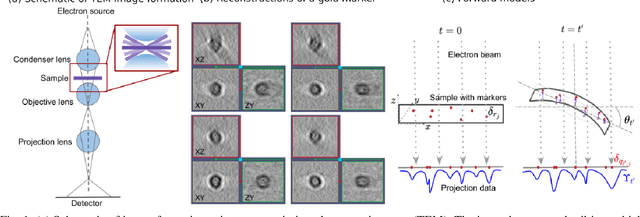
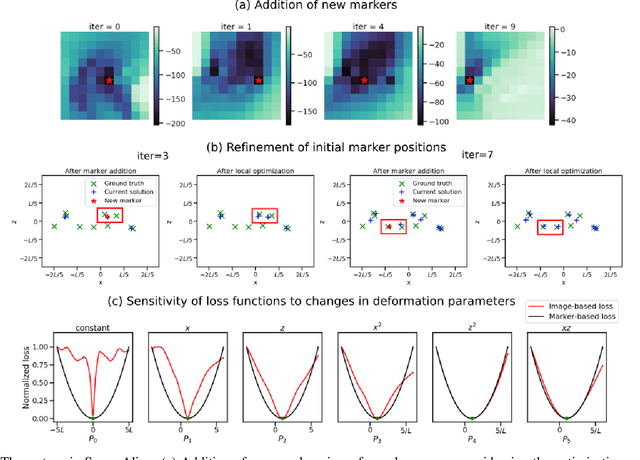
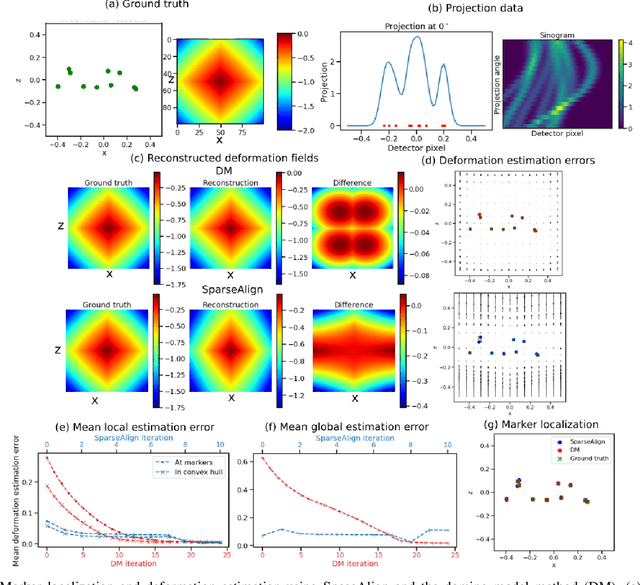
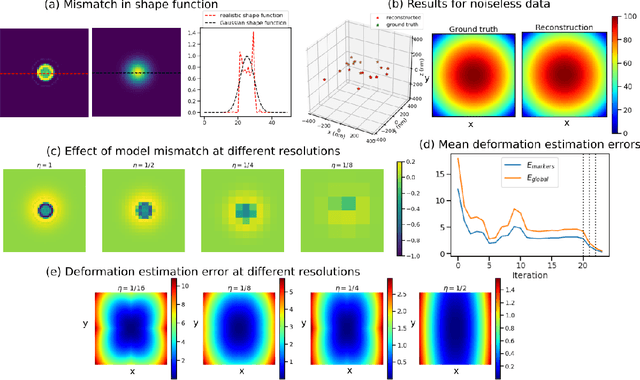
Tilt-series alignment is crucial to obtaining high-resolution reconstructions in cryo-electron tomography. Beam-induced local deformation of the sample is hard to estimate from the low-contrast sample alone, and often requires fiducial gold bead markers. The state-of-the-art approach for deformation estimation uses (semi-)manually labelled marker locations in projection data to fit the parameters of a polynomial deformation model. Manually-labelled marker locations are difficult to obtain when data are noisy or markers overlap in projection data. We propose an alternative mathematical approach for simultaneous marker localization and deformation estimation by extending a grid-free super-resolution algorithm first proposed in the context of single-molecule localization microscopy. Our approach does not require labelled marker locations; instead, we use an image-based loss where we compare the forward projection of markers with the observed data. We equip this marker localization scheme with an additional deformation estimation component and solve for a reduced number of deformation parameters. Using extensive numerical studies on marker-only samples, we show that our approach automatically finds markers and reliably estimates sample deformation without labelled marker data. We further demonstrate the applicability of our approach for a broad range of model mismatch scenarios, including experimental electron tomography data of gold markers on ice.