 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLYSTO: The Lymphocyte Assessment Hackathon and Benchmark Dataset
Jan 16, 2023



We introduce LYSTO, the Lymphocyte Assessment Hackathon, which was held in conjunction with the MICCAI 2019 Conference in Shenzen (China). The competition required participants to automatically assess the number of lymphocytes, in particular T-cells, in histopathological images of colon, breast, and prostate cancer stained with CD3 and CD8 immunohistochemistry. Differently from other challenges setup in medical image analysis, LYSTO participants were solely given a few hours to address this problem. In this paper, we describe the goal and the multi-phase organization of the hackathon; we describe the proposed methods and the on-site results. Additionally, we present post-competition results where we show how the presented methods perform on an independent set of lung cancer slides, which was not part of the initial competition, as well as a comparison on lymphocyte assessment between presented methods and a panel of pathologists. We show that some of the participants were capable to achieve pathologist-level performance at lymphocyte assessment. After the hackathon, LYSTO was left as a lightweight plug-and-play benchmark dataset on grand-challenge website, together with an automatic evaluation platform. LYSTO has supported a number of research in lymphocyte assessment in oncology. LYSTO will be a long-lasting educational challenge for deep learning and digital pathology, it is available at https://lysto.grand-challenge.org/.
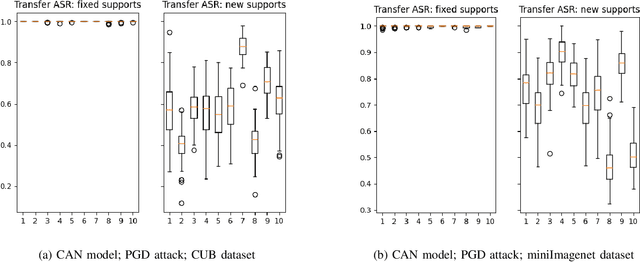
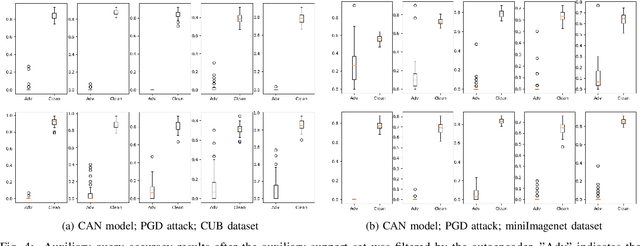
Towards A Conceptually Simple Defensive Approach for Few-shot classifiers Against Adversarial Support Samples
Oct 24, 2021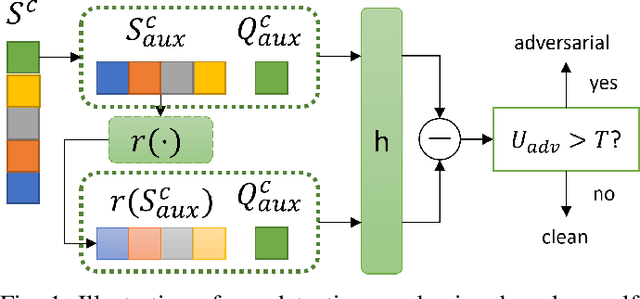
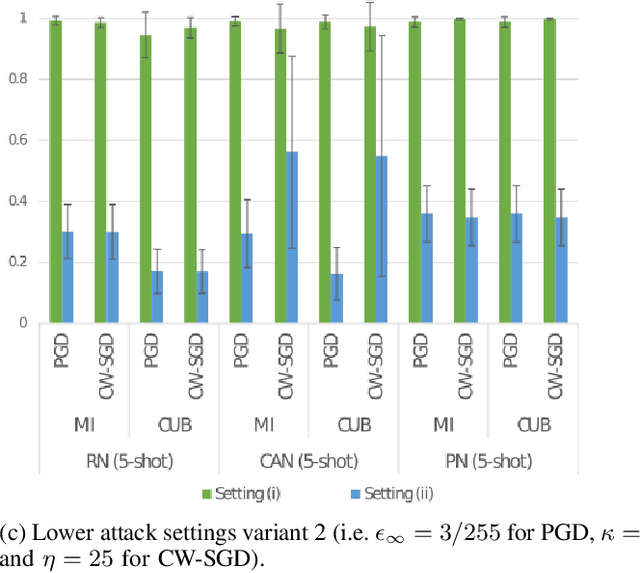
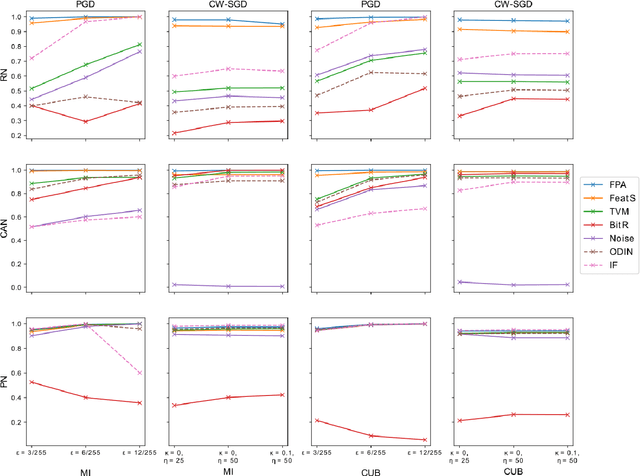
Few-shot classifiers have been shown to exhibit promising results in use cases where user-provided labels are scarce. These models are able to learn to predict novel classes simply by training on a non-overlapping set of classes. This can be largely attributed to the differences in their mechanisms as compared to conventional deep networks. However, this also offers new opportunities for novel attackers to induce integrity attacks against such models, which are not present in other machine learning setups. In this work, we aim to close this gap by studying a conceptually simple approach to defend few-shot classifiers against adversarial attacks. More specifically, we propose a simple attack-agnostic detection method, using the concept of self-similarity and filtering, to flag out adversarial support sets which destroy the understanding of a victim classifier for a certain class. Our extended evaluation on the miniImagenet (MI) and CUB datasets exhibit good attack detection performance, across three different few-shot classifiers and across different attack strengths, beating baselines. Our observed results allow our approach to establishing itself as a strong detection method for support set poisoning attacks. We also show that our approach constitutes a generalizable concept, as it can be paired with other filtering functions. Finally, we provide an analysis of our results when we vary two components found in our detection approach.
Detection of Adversarial Supports in Few-shot Classifiers Using Feature Preserving Autoencoders and Self-Similarity
Dec 09, 2020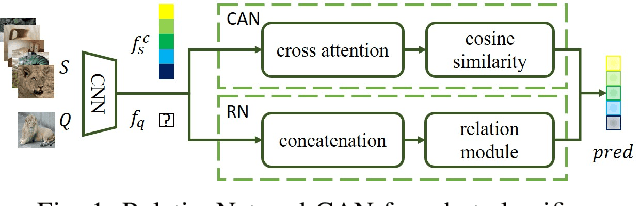
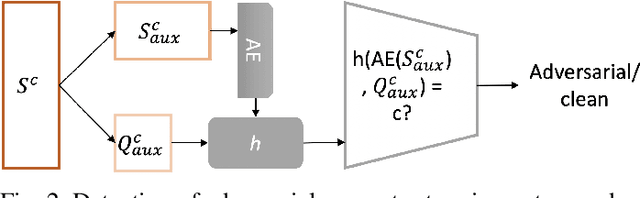
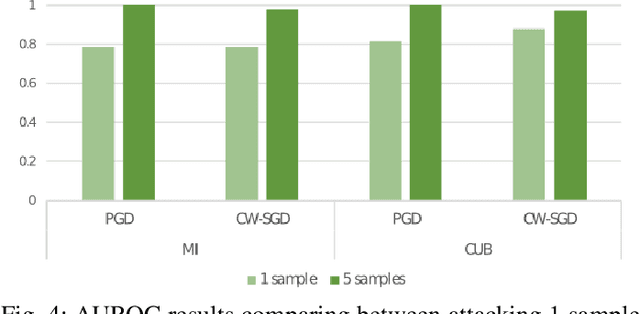
Few-shot classifiers excel under limited training samples, making it useful in real world applications. However, the advent of adversarial samples threatens the efficacy of such classifiers. For them to remain reliable, defences against such attacks must be explored. However, closer examination to prior literature reveals a big gap in this domain. Hence, in this work, we propose a detection strategy to highlight adversarial support sets, aiming to destroy a few-shot classifier's understanding of a certain class of objects. We make use of feature preserving autoencoder filtering and also the concept of self-similarity of a support set to perform this detection. As such, our method is attack-agnostic and also the first to explore detection for few-shot classifiers to the best of our knowledge. Our evaluation on the miniImagenet and CUB datasets exhibit optimism when employing our proposed approach, showing high AUROC scores for detection in general.
Explanation-Guided Training for Cross-Domain Few-Shot Classification
Jul 17, 2020
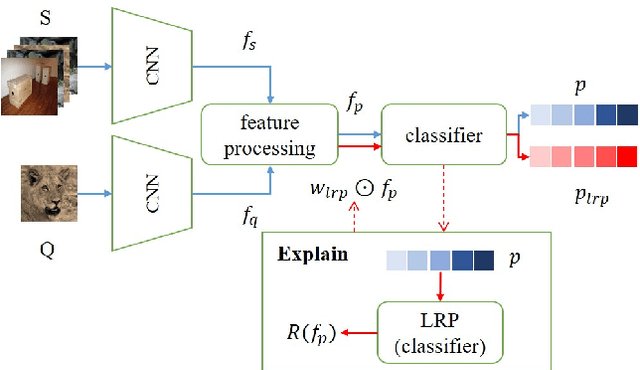
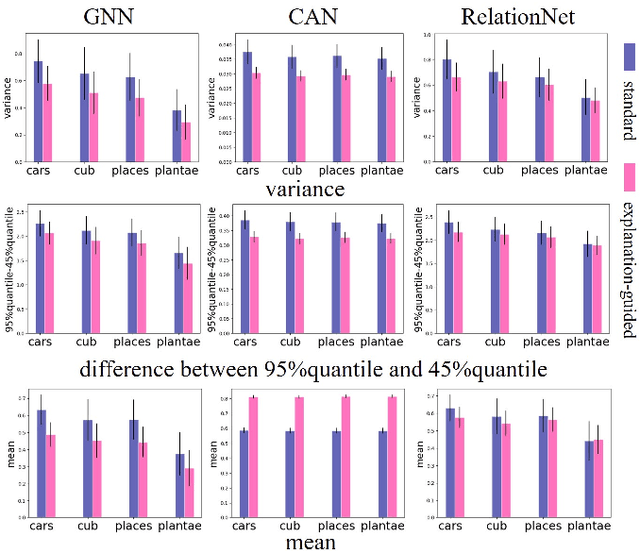
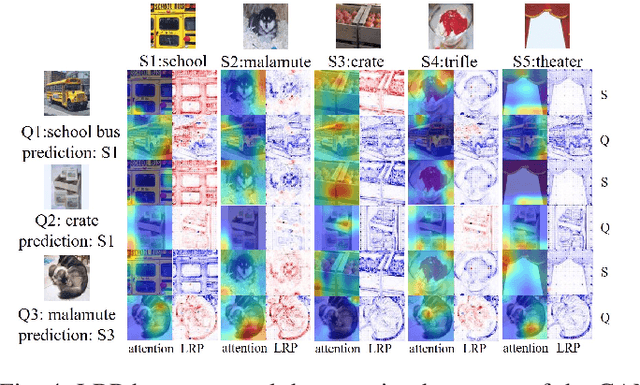
Cross-domain few-shot classification task (CD-FSC) combines few-shot classification with the requirement to generalize across domains represented by datasets. This setup faces challenges originating from the limited labeled data in each class and, additionally, from the domain shift between training and test sets. In this paper, we introduce a novel training approach for existing FSC models. It leverages on the explanation scores, obtained from existing explanation methods when applied to the predictions of FSC models, computed for intermediate feature maps of the models. Firstly, we tailor the layer-wise relevance propagation (LRP) method to explain the prediction outcomes of FSC models. Secondly, we develop a model-agnostic explanation-guided training strategy that dynamically finds and emphasizes the features which are important for the predictions. Our contribution does not target a novel explanation method but lies in a novel application of explanations for the training phase. We show that explanation-guided training effectively improves the model generalization. We observe improved accuracy for three different FSC models: RelationNet, cross attention network, and a graph neural network-based formulation, on five few-shot learning datasets: miniImagenet, CUB, Cars, Places, and Plantae.
Understanding Image Captioning Models beyond Visualizing Attention
Jan 22, 2020

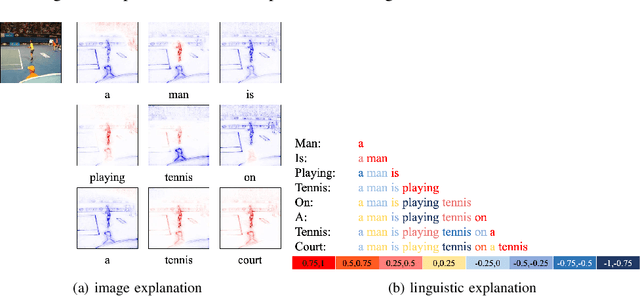
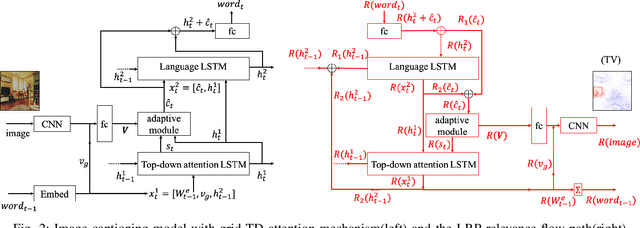
This paper explains predictions of image captioning models with attention mechanisms beyond visualizing the attention itself. In this paper, we develop variants of layer-wise relevance backpropagation (LRP) and gradient backpropagation, tailored to image captioning with attention. The result provides simultaneously pixel-wise image explanation and linguistic explanation for each word in the captions. We show that given a word in the caption to be explained, explanation methods such as LRP reveal supporting and opposing pixels as well as words. We compare the properties of attention heatmaps systematically against those computed with explanation methods such as LRP, Grad-CAM and Guided Grad-CAM. We show that explanation methods, firstly, correlate to object locations with higher precision than attention, secondly, are able to identify object words that are unsupported by image content, and thirdly, provide guidance to debias and improve the model. Results are reported for image captioning using two different attention models trained with Flickr30K and MSCOCO2017 datasets. Experimental analyses show the strength of explanation methods for understanding image captioning attention models.