 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Auto-encoder with Neural Response
Nov 30, 2021
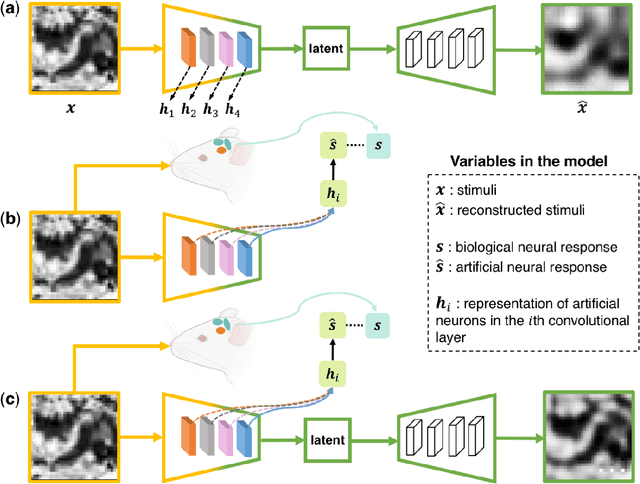
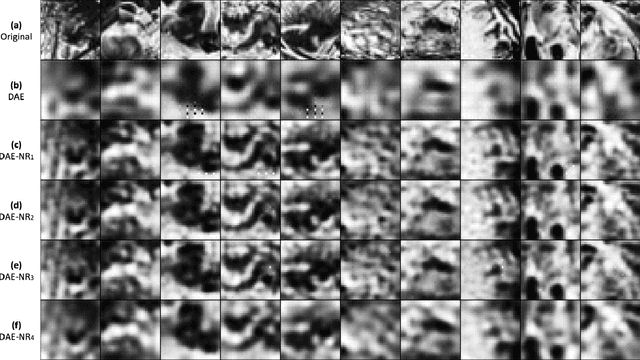
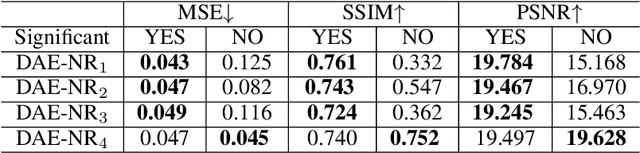
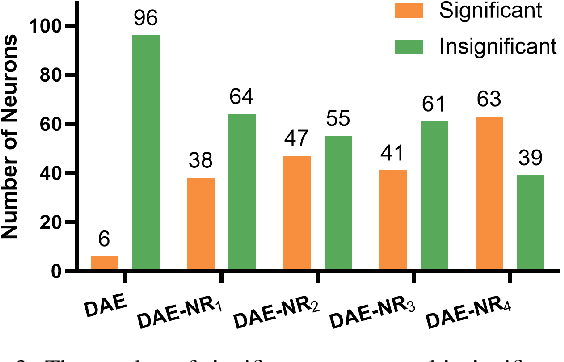
Artificial intelligence and neuroscience are deeply interactive. Artificial neural networks (ANNs) have been a versatile tool to study the neural representation in the ventral visual stream, and the knowledge in neuroscience in return inspires ANN models to improve performance in the task. However, how to merge these two directions into a unified model has less studied. Here, we propose a hybrid model, called deep auto-encoder with the neural response (DAE-NR), which incorporates the information from the visual cortex into ANNs to achieve better image reconstruction and higher neural representation similarity between biological and artificial neurons. Specifically, the same visual stimuli (i.e., natural images) are input to both the mice brain and DAE-NR. The DAE-NR jointly learns to map a specific layer of the encoder network to the biological neural responses in the ventral visual stream by a mapping function and to reconstruct the visual input by the decoder. Our experiments demonstrate that if and only if with the joint learning, DAE-NRs can (i) improve the performance of image reconstruction and (ii) increase the representational similarity between biological neurons and artificial neurons. The DAE-NR offers a new perspective on the integration of computer vision and visual neuroscience.
Brain Tumor Classification by Cascaded Multiscale Multitask Learning Framework Based on Feature Aggregation
Dec 28, 2021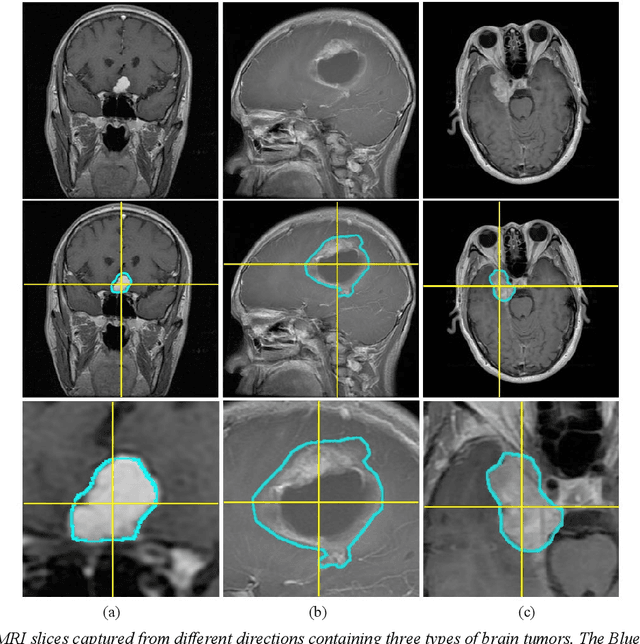

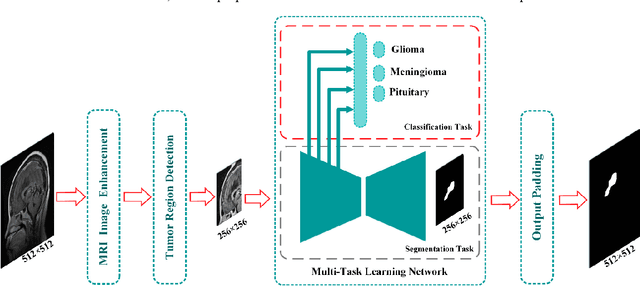

Brain tumor analysis in MRI images is a significant and challenging issue because misdiagnosis can lead to death. Diagnosis and evaluation of brain tumors in the early stages increase the probability of successful treatment. However, the complexity and variety of tumors, shapes, and locations make their segmentation and classification complex. In this regard, numerous researchers have proposed brain tumor segmentation and classification methods. This paper presents an approach that simultaneously segments and classifies brain tumors in MRI images using a framework that contains MRI image enhancement and tumor region detection. Eventually, a network based on a multitask learning approach is proposed. Subjective and objective results indicate that the segmentation and classification results based on evaluation metrics are better or comparable to the state-of-the-art.
Image to Bengali Caption Generation Using Deep CNN and Bidirectional Gated Recurrent Unit
Dec 22, 2020
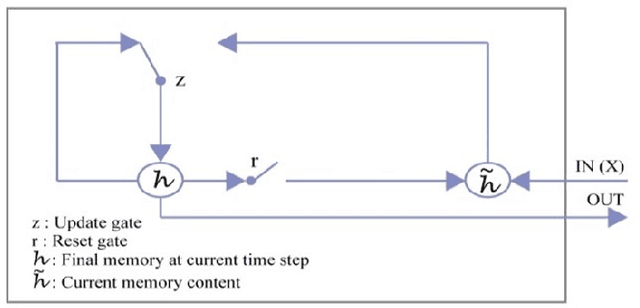

There is very little notable research on generating descriptions of the Bengali language. About 243 million people speak in Bengali, and it is the 7th most spoken language on the planet. The purpose of this research is to propose a CNN and Bidirectional GRU based architecture model that generates natural language captions in the Bengali language from an image. Bengali people can use this research to break the language barrier and better understand each other's perspectives. It will also help many blind people with their everyday lives. This paper used an encoder-decoder approach to generate captions. We used a pre-trained Deep convolutional neural network (DCNN) called InceptonV3image embedding model as the encoder for analysis, classification, and annotation of the dataset's images Bidirectional Gated Recurrent unit (BGRU) layer as the decoder to generate captions. Argmax and Beam search is used to produce the highest possible quality of the captions. A new dataset called BNATURE is used, which comprises 8000 images with five captions per image. It is used for training and testing the proposed model. We obtained BLEU-1, BLEU-2, BLEU-3, BLEU-4 and Meteor is 42.6, 27.95, 23, 66, 16.41, 28.7 respectively.
Deep Learning Based Framework for Iranian License Plate Detection and Recognition
Jan 18, 2022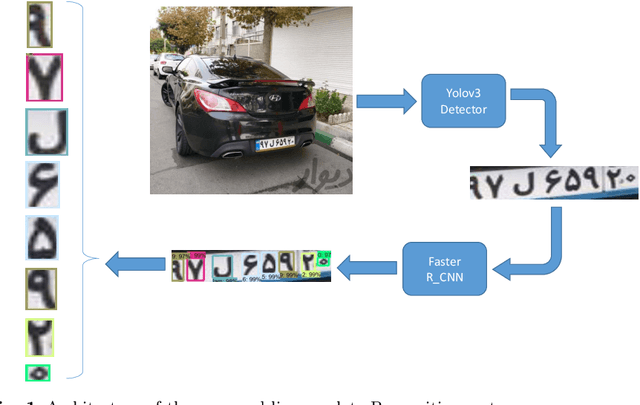
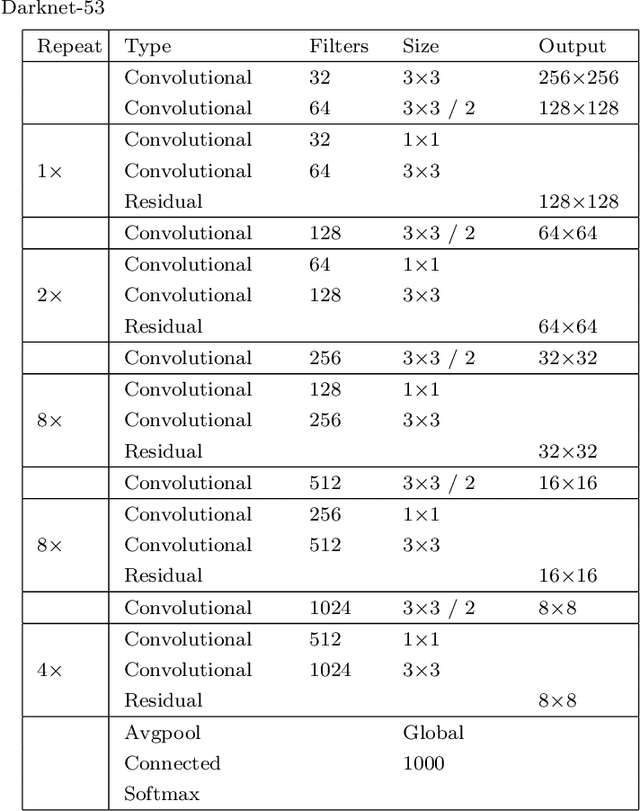
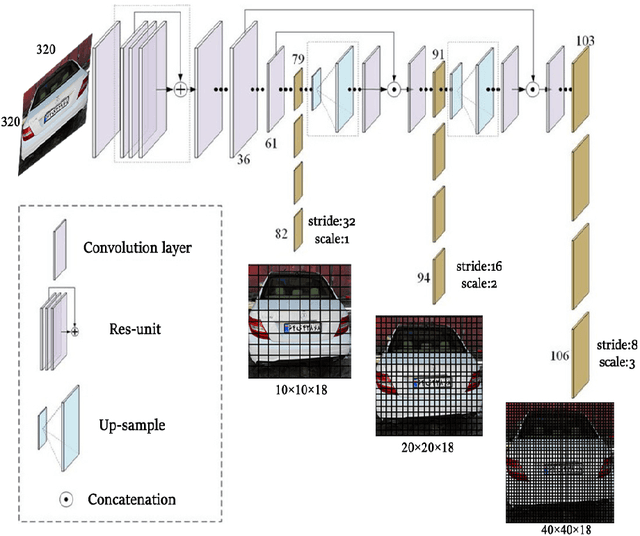
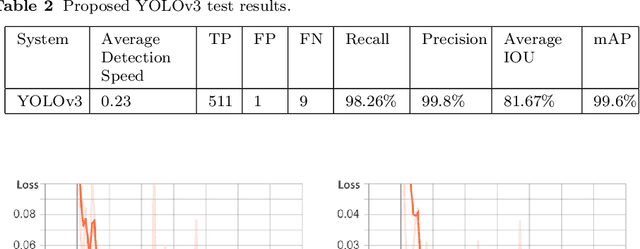
License plate recognition systems have a very important role in many applications such as toll management, parking control, and traffic management. In this paper, a framework of deep convolutional neural networks is proposed for Iranian license plate recognition. The first CNN is the YOLOv3 network that detects the Iranian license plate in the input image while the second CNN is a Faster R-CNN that recognizes and classifies the characters in the detected license plate. A dataset of Iranian license plates consisting of ill-conditioned images also developed in this paper. The YOLOv3 network achieved 99.6% mAP, 98.26% recall, 98.08% accuracy, and average detection speed is only 23ms. Also, the Faster R-CNN network trained and tested on the developed dataset and achieved 98.97% recall, 99.9% precision, and 98.8% accuracy. The proposed system can recognize the license plate in challenging situations like unwanted data on the license plate. Comparing this system with other Iranian license plate recognition systems shows that it is Faster, more accurate and also this system can work in an open environment.
Deep Models for Visual Sentiment Analysis of Disaster-related Multimedia Content
Nov 30, 2021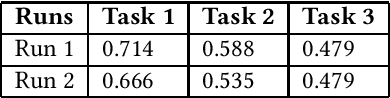
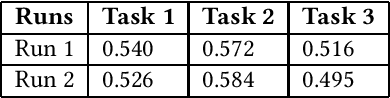
This paper presents a solutions for the MediaEval 2021 task namely "Visual Sentiment Analysis: A Natural Disaster Use-case". The task aims to extract and classify sentiments perceived by viewers and the emotional message conveyed by natural disaster-related images shared on social media. The task is composed of three sub-tasks including, one single label multi-class image classification task, and, two multi-label multi-class image classification tasks, with different sets of labels. In our proposed solutions, we rely mainly on two different state-of-the-art models namely, Inception-v3 and VggNet-19, pre-trained on ImageNet, which are fine-tuned for each of the three task using different strategies. Overall encouraging results are obtained on all the three tasks. On the single-label classification task (i.e. Task 1), we obtained the weighted average F1-scores of 0.540 and 0.526 for the Inception-v3 and VggNet-19 based solutions, respectively. On the multi-label classification i.e., Task 2 and Task 3, the weighted F1-score of our Inception-v3 based solutions was 0.572 and 0.516, respectively. Similarly, the weighted F1-score of our VggNet-19 based solution on Task 2 and Task 3 was 0.584 and 0.495, respectively.
C2G-Net: Exploiting Morphological Properties for Image Classification
Jul 07, 2020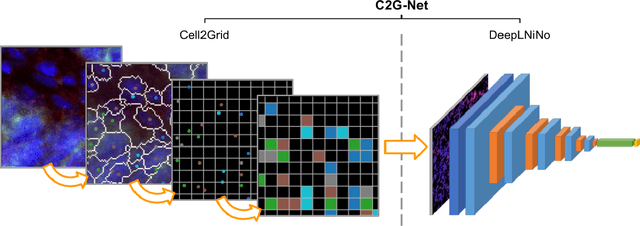
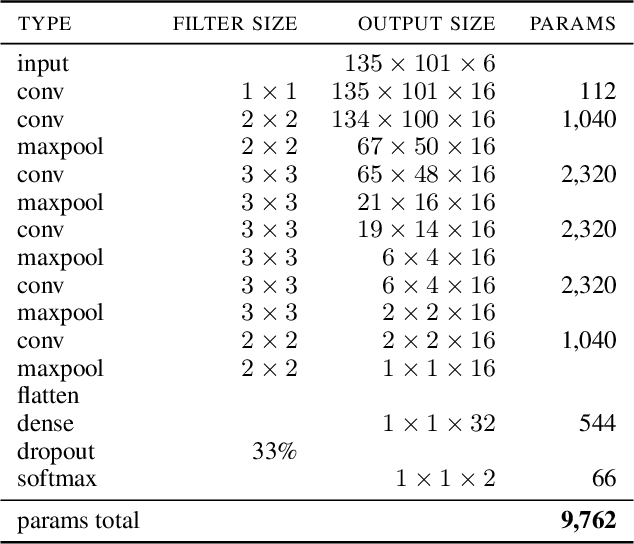
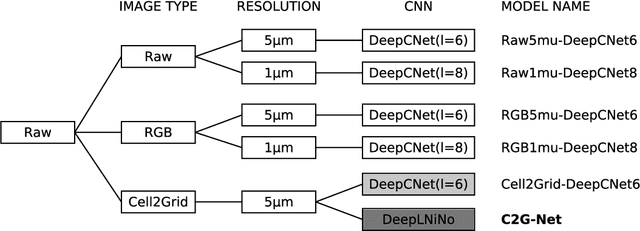

In this paper we propose C2G-Net, a pipeline for image classification that exploits the morphological properties of images containing a large number of similar objects like biological cells. C2G-Net consists of two components: (1) Cell2Grid, an image compression algorithm that identifies objects using segmentation and arranges them on a grid, and (2) DeepLNiNo, a CNN architecture with less than 10,000 trainable parameters aimed at facilitating model interpretability. To test the performance of C2G-Net we used multiplex immunohistochemistry images for predicting relapse risk in colon cancer. Compared to conventional CNN architectures trained on raw images, C2G-Net achieved similar prediction accuracy while training time was reduced by 85% and its model was is easier to interpret.
Desmoking laparoscopy surgery images using an image-to-image translation guided by an embedded dark channel
Apr 19, 2020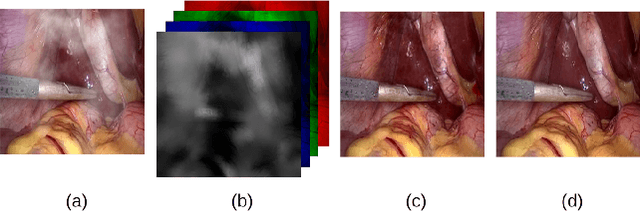
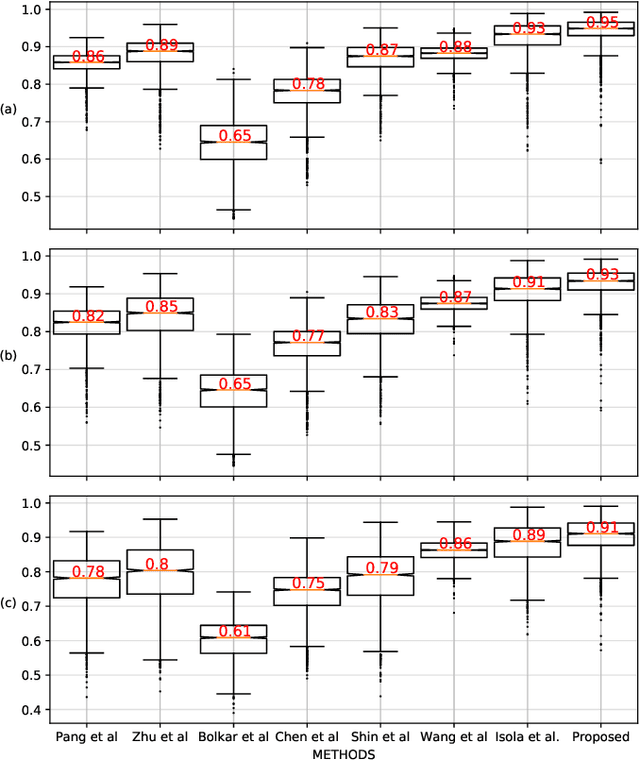
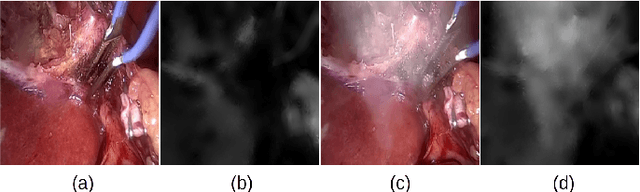
In laparoscopic surgery, the visibility in the image can be severely degraded by the smoke caused by the $CO_2$ injection, and dissection tools, thus reducing the visibility of organs and tissues. This lack of visibility increases the surgery time and even the probability of mistakes conducted by the surgeon, then producing negative consequences on the patient's health. In this paper, a novel computational approach to remove the smoke effects is introduced. The proposed method is based on an image-to-image conditional generative adversarial network in which a dark channel is used as an embedded guide mask. Obtained experimental results are evaluated and compared quantitatively with other desmoking and dehazing state-of-art methods using the metrics of the Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity (SSIM) index. Based on these metrics, it is found that the proposed method has improved performance compared to the state-of-the-art. Moreover, the processing time required by our method is 92 frames per second, and thus, it can be applied in a real-time medical system trough an embedded device.
Towards Photorealistic Colorization by Imagination
Aug 20, 2021


We present a novel approach to automatic image colorization by imitating the imagination process of human experts. Our imagination module is designed to generate color images that are context-correlated with black-and-white photos. Given a black-and-white image, our imagination module firstly extracts the context information, which is then used to synthesize colorful and diverse images using a conditional image synthesis network (e.g., semantic image synthesis model). We then design a colorization module to colorize the black-and-white images with the guidance of imagination for photorealistic colorization. Experimental results show that our work produces more colorful and diverse results than state-of-the-art image colorization methods. Our source codes will be publicly available.
Robust photon-efficient imaging using a pixel-wise residual shrinkage network
Jan 05, 2022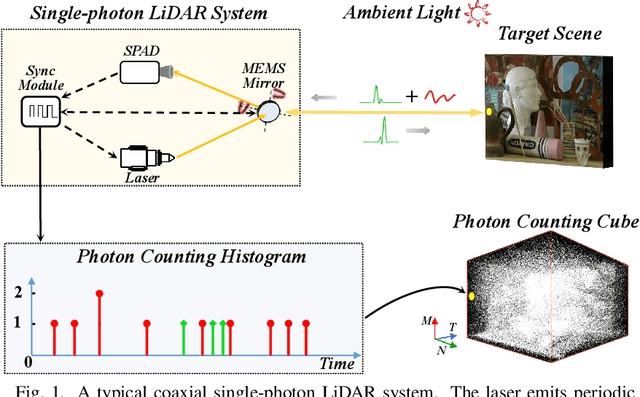
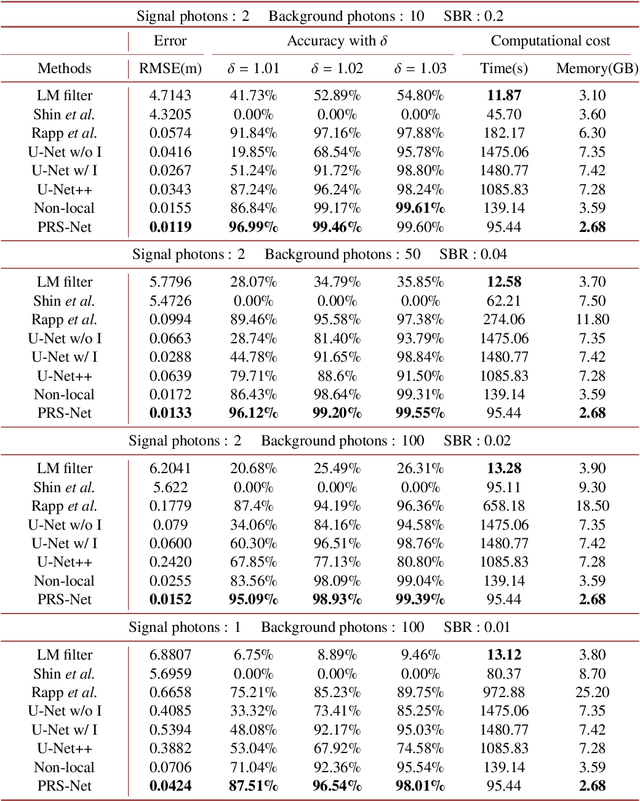

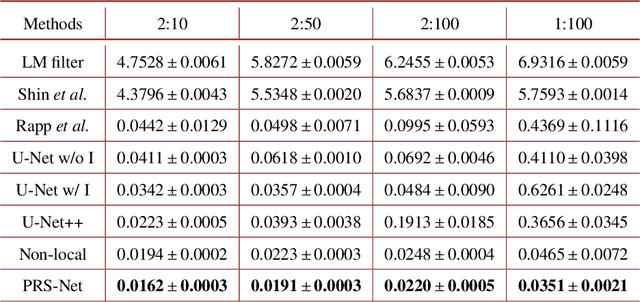
Single-photon light detection and ranging (LiDAR) has been widely applied to 3D imaging in challenging scenarios. However, limited signal photon counts and high noises in the collected data have posed great challenges for predicting the depth image precisely. In this paper, we propose a pixel-wise residual shrinkage network for photon-efficient imaging from high-noise data, which adaptively generates the optimal thresholds for each pixel and denoises the intermediate features by soft thresholding. Besides, redefining the optimization target as pixel-wise classification provides a sharp advantage in producing confident and accurate depth estimation when compared with existing research. Comprehensive experiments conducted on both simulated and real-world datasets demonstrate that the proposed model outperforms the state-of-the-arts and maintains robust imaging performance under different signal-to-noise ratios including the extreme case of 1:100.
Stacked Deep Multi-Scale Hierarchical Network for Fast Bokeh Effect Rendering from a Single Image
May 15, 2021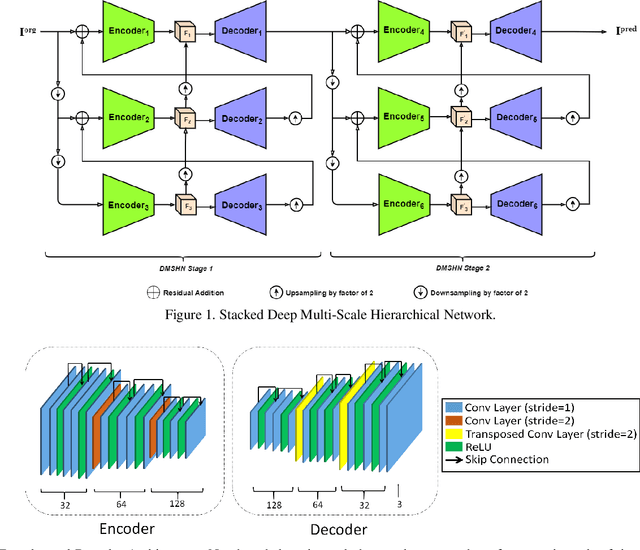
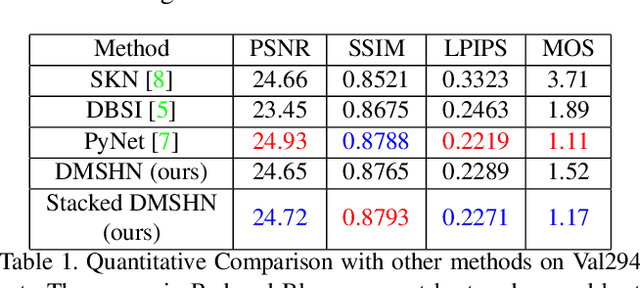
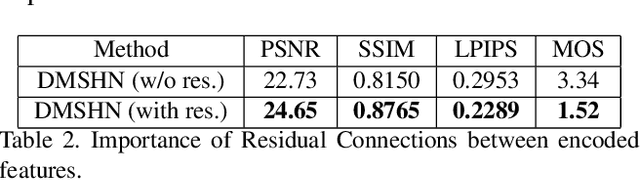

The Bokeh Effect is one of the most desirable effects in photography for rendering artistic and aesthetic photos. Usually, it requires a DSLR camera with different aperture and shutter settings and certain photography skills to generate this effect. In smartphones, computational methods and additional sensors are used to overcome the physical lens and sensor limitations to achieve such effect. Most of the existing methods utilized additional sensor's data or pretrained network for fine depth estimation of the scene and sometimes use portrait segmentation pretrained network module to segment salient objects in the image. Because of these reasons, networks have many parameters, become runtime intensive and unable to run in mid-range devices. In this paper, we used an end-to-end Deep Multi-Scale Hierarchical Network (DMSHN) model for direct Bokeh effect rendering of images captured from the monocular camera. To further improve the perceptual quality of such effect, a stacked model consisting of two DMSHN modules is also proposed. Our model does not rely on any pretrained network module for Monocular Depth Estimation or Saliency Detection, thus significantly reducing the size of model and run time. Stacked DMSHN achieves state-of-the-art results on a large scale EBB! dataset with around 6x less runtime compared to the current state-of-the-art model in processing HD quality images.