 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Developing Imperceptible Adversarial Patches to Camouflage Military Assets From Computer Vision Enabled Technologies
Feb 17, 2022



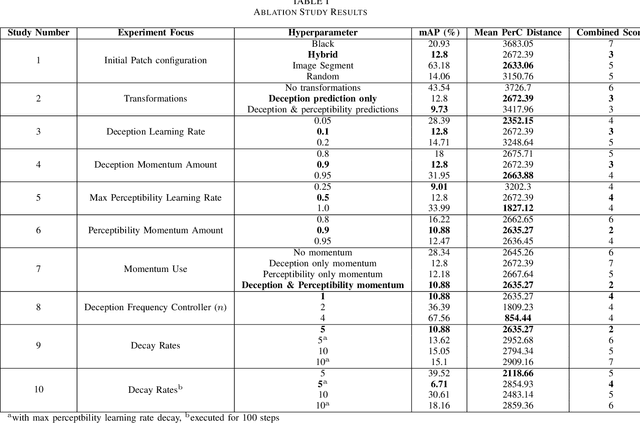
Convolutional neural networks (CNNs) have demonstrated rapid progress and a high level of success in object detection. However, recent evidence has highlighted their vulnerability to adversarial attacks. These attacks are calculated image perturbations or adversarial patches that result in object misclassification or detection suppression. Traditional camouflage methods are impractical when applied to disguise aircraft and other large mobile assets from autonomous detection in intelligence, surveillance and reconnaissance technologies and fifth generation missiles. In this paper we present a unique method that produces imperceptible patches capable of camouflaging large military assets from computer vision-enabled technologies. We developed these patches by maximising object detection loss whilst limiting the patch's colour perceptibility. This work also aims to further the understanding of adversarial examples and their effects on object detection algorithms.
New SST Optical Sensor of Pampilhosa da Serra: studies on image processing algorithms and multi-filter characterization of Space Debris
Jul 05, 2021

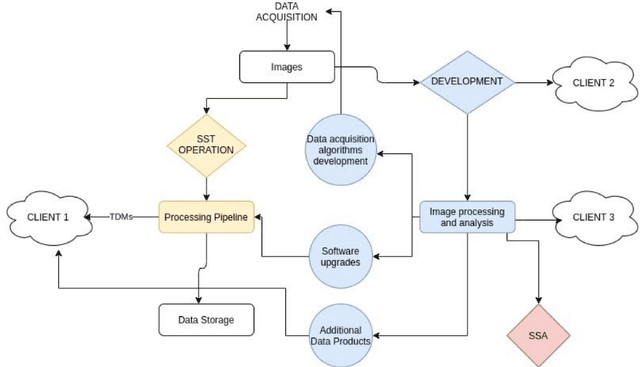
As part of the Portuguese Space Surveillance and Tracking (SST) System, two new Wide Field of View (2.3deg x 2.3deg) small aperture (30cm) telescopes will be deployed in 2021, at the Pampilhosa da Serra Space Observatory (PASO), located in the center of the continental Portuguese territory, in the heart of a certified Dark Sky area. These optical systems will provide added value capabilities to the Portuguese SST network, complementing the optical telescopes currently in commissioning in Madeira and Azores. These telescopes are optimized for GEO and MEO survey operations and besides the required SST operational capability, they will also provide an important development component to the Portuguese SST network. The telescopes will be equipped with filter wheels, being able to perform observations in several optical bands including white light, BVRI bands and narrow band filters such as H(alpha) and O[III] to study potential different objects' albedos. This configuration enables us to conduct a study on space debris classification$/$characterization using combinations of different colors aiming the production of improved color index schemes to be incorporated in the automatic pipelines for classification of space debris. This optical sensor will also be used to conduct studies on image processing algorithms, including source extraction and classification solutions through the application of machine learning techniques. Since SST dedicated telescopes produce a large quantity of data per observation night, fast, efficient and automatic image processing techniques are mandatory. A platform like this one, dedicated to the development of Space Surveillance studies, will add a critical capability to keep the Portuguese SST network updated, and as a consequence it may provide useful developments to the European SST network as well.
IAE-Net: Integral Autoencoders for Discretization-Invariant Learning
Mar 10, 2022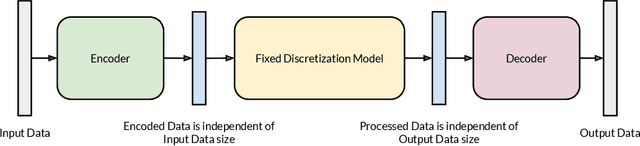

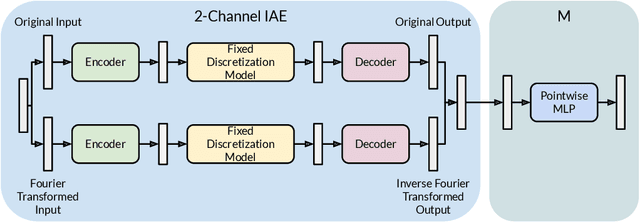

Discretization invariant learning aims at learning in the infinite-dimensional function spaces with the capacity to process heterogeneous discrete representations of functions as inputs and/or outputs of a learning model. This paper proposes a novel deep learning framework based on integral autoencoders (IAE-Net) for discretization invariant learning. The basic building block of IAE-Net consists of an encoder and a decoder as integral transforms with data-driven kernels, and a fully connected neural network between the encoder and decoder. This basic building block is applied in parallel in a wide multi-channel structure, which are repeatedly composed to form a deep and densely connected neural network with skip connections as IAE-Net. IAE-Net is trained with randomized data augmentation that generates training data with heterogeneous structures to facilitate the performance of discretization invariant learning. The proposed IAE-Net is tested with various applications in predictive data science, solving forward and inverse problems in scientific computing, and signal/image processing. Compared with alternatives in the literature, IAE-Net achieves state-of-the-art performance in existing applications and creates a wide range of new applications.
Meta Internal Learning
Oct 06, 2021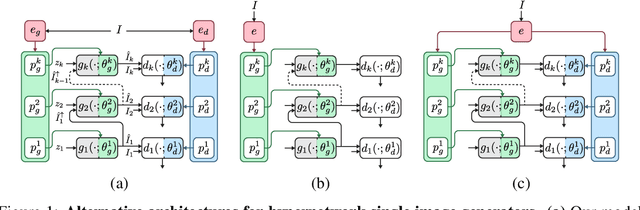


Internal learning for single-image generation is a framework, where a generator is trained to produce novel images based on a single image. Since these models are trained on a single image, they are limited in their scale and application. To overcome these issues, we propose a meta-learning approach that enables training over a collection of images, in order to model the internal statistics of the sample image more effectively. In the presented meta-learning approach, a single-image GAN model is generated given an input image, via a convolutional feedforward hypernetwork $f$. This network is trained over a dataset of images, allowing for feature sharing among different models, and for interpolation in the space of generative models. The generated single-image model contains a hierarchy of multiple generators and discriminators. It is therefore required to train the meta-learner in an adversarial manner, which requires careful design choices that we justify by a theoretical analysis. Our results show that the models obtained are as suitable as single-image GANs for many common image applications, significantly reduce the training time per image without loss in performance, and introduce novel capabilities, such as interpolation and feedforward modeling of novel images.
Comprehensive evaluation of no-reference image quality assessment algorithms on KADID-10k database
Nov 09, 2020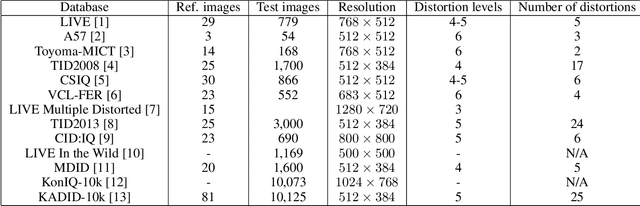
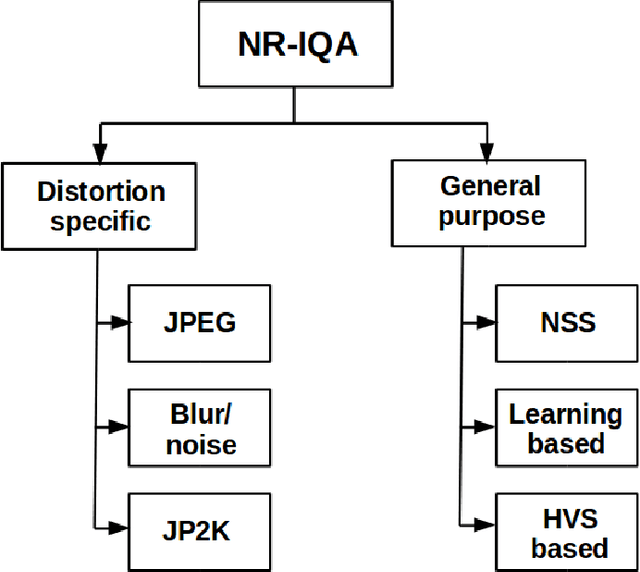

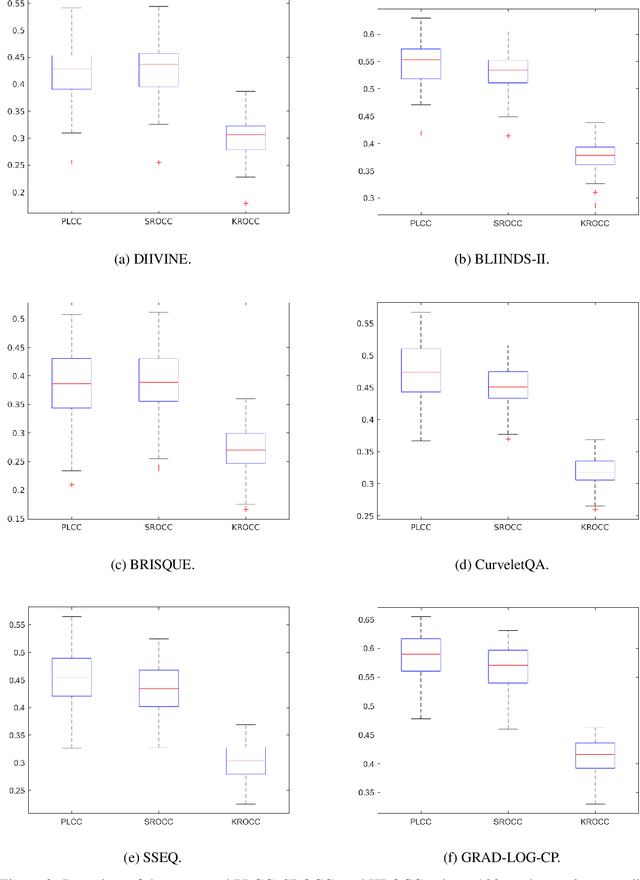
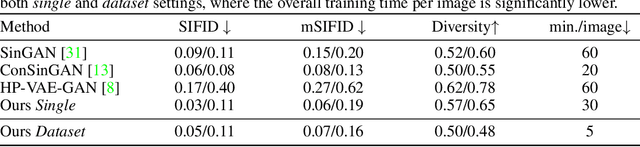
The main goal of objective image quality assessment is to devise computational, mathematical models which are able to predict perceptual image quality consistently with subjective evaluations. The evaluation of objective image quality assessment algorithms is based on experiments conducted on publicly available benchmark databases. In this study, our goal is to give a comprehensive evaluation about no-reference image quality assessment algorithms, whose original source codes are available online, using the recently published KADID-10k database which is one of the largest available benchmark databases. Specifically, average PLCC, SROCC, and KROCC are reported which were measured over 100 random train-test splits. Furthermore, the database was divided into a train (appx. 80\% of images) and a test set (appx. 20% of images) with respect to the reference images. So no semantic content overlap was between these two sets. Our evaluation results may be helpful to obtain a clear understanding about the status of state-of-the-art no-reference image quality assessment methods.
A Quality Index Metric and Method for Online Self-Assessment of Autonomous Vehicles Sensory Perception
Mar 04, 2022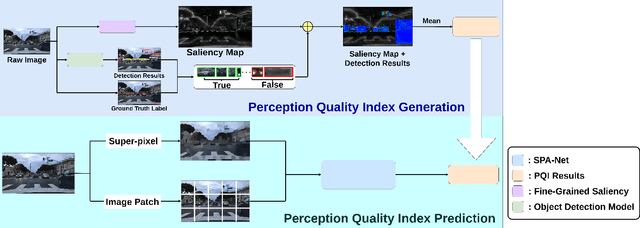

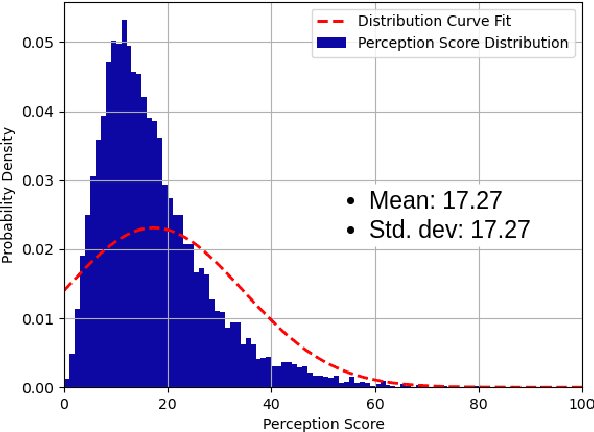
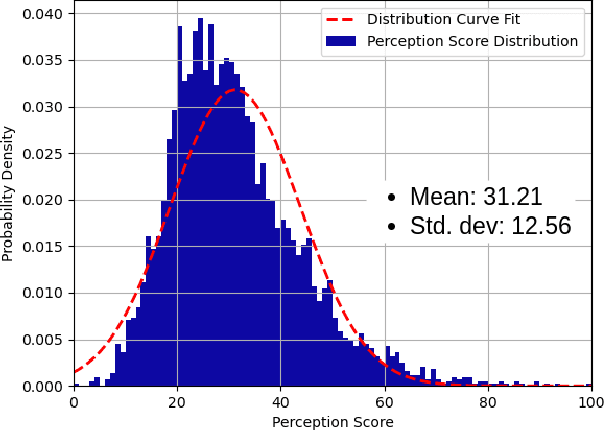
Perception is critical to autonomous driving safety. Camera-based object detection is one of the most important methods for autonomous vehicle perception. Current camera-based object detection solutions for autonomous driving cannot provide feedback on the detection performance for each frame. We propose an evaluation metric, namely the perception quality index (PQI), to assess the camera-based object detection algorithm performance and provide the perception quality feedback frame by frame. The method of the PQI generation is by combining the fine-grained saliency map intensity with the object detection algorithm's output results. Furthermore, we developed a superpixel-based attention network (SPA-NET) to predict the proposed PQI evaluation metric by using raw image pixels and superpixels as input. The proposed evaluation metric and prediction network are tested on three open-source datasets. The proposed evaluation metric can correctly assess the camera-based perception quality under the autonomous driving environment according to the experiment results. The network regression R-square values determine the comparison among models. It is shown that a Perception Quality Index is useful in self-evaluating a cameras visual scene perception.
Online Learning of Reusable Abstract Models for Object Goal Navigation
Mar 04, 2022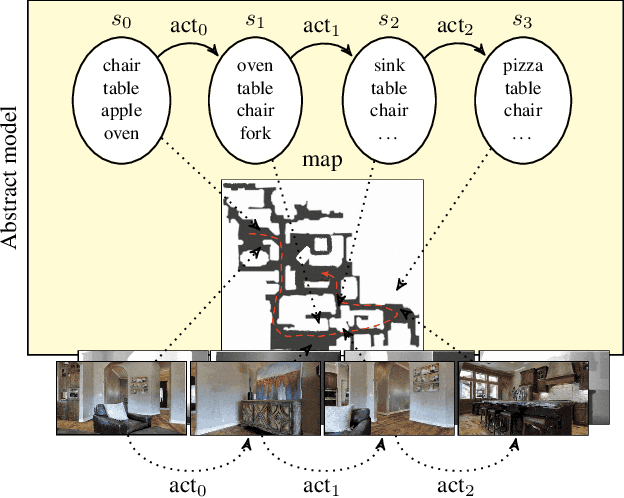
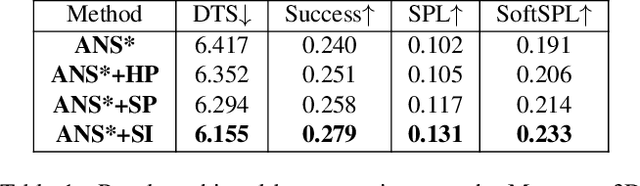
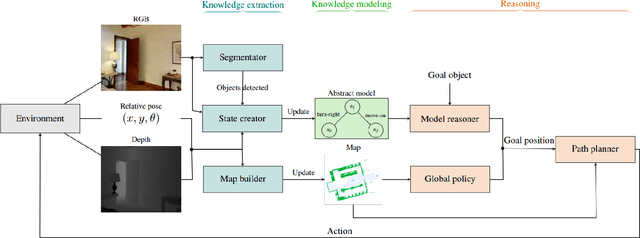
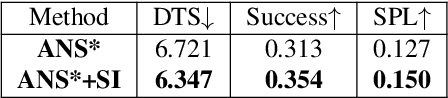
In this paper, we present a novel approach to incrementally learn an Abstract Model of an unknown environment, and show how an agent can reuse the learned model for tackling the Object Goal Navigation task. The Abstract Model is a finite state machine in which each state is an abstraction of a state of the environment, as perceived by the agent in a certain position and orientation. The perceptions are high-dimensional sensory data (e.g., RGB-D images), and the abstraction is reached by exploiting image segmentation and the Taskonomy model bank. The learning of the Abstract Model is accomplished by executing actions, observing the reached state, and updating the Abstract Model with the acquired information. The learned models are memorized by the agent, and they are reused whenever it recognizes to be in an environment that corresponds to the stored model. We investigate the effectiveness of the proposed approach for the Object Goal Navigation task, relying on public benchmarks. Our results show that the reuse of learned Abstract Models can boost performance on Object Goal Navigation.
PIINET: A 360-degree Panoramic Image Inpainting Network Using a Cube Map
Oct 30, 2020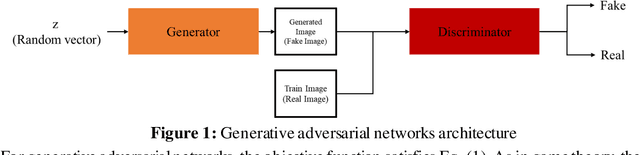

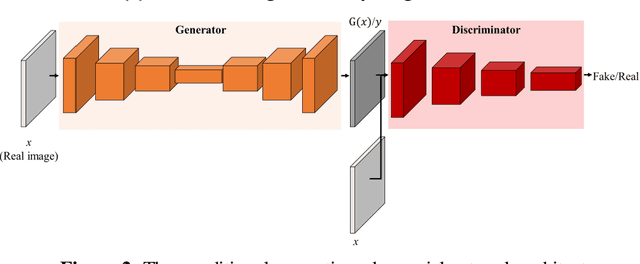

Inpainting has been continuously studied in the field of computer vision. As artificial intelligence technology developed, deep learning technology was introduced in inpainting research, helping to improve performance. Currently, the input target of an inpainting algorithm using deep learning has been studied from a single image to a video. However, deep learning-based inpainting technology for panoramic images has not been actively studied. We propose a 360-degree panoramic image inpainting method using generative adversarial networks (GANs). The proposed network inputs a 360-degree equirectangular format panoramic image converts it into a cube map format, which has relatively little distortion and uses it as a training network. Since the cube map format is used, the correlation of the six sides of the cube map should be considered. Therefore, all faces of the cube map are used as input for the whole discriminative network, and each face of the cube map is used as input for the slice discriminative network to determine the authenticity of the generated image. The proposed network performed qualitatively better than existing single-image inpainting algorithms and baseline algorithms.
Exploring Latent Dimensions of Crowd-sourced Creativity
Dec 13, 2021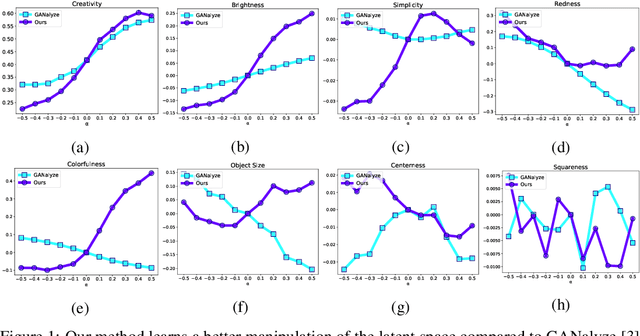

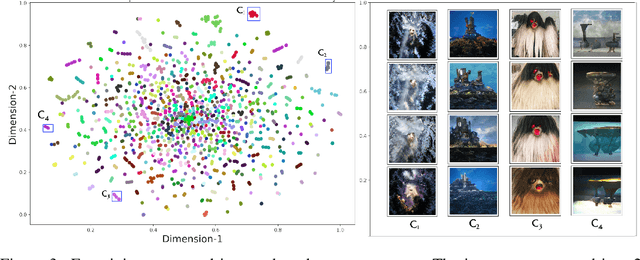
Recently, the discovery of interpretable directions in the latent spaces of pre-trained GANs has become a popular topic. While existing works mostly consider directions for semantic image manipulations, we focus on an abstract property: creativity. Can we manipulate an image to be more or less creative? We build our work on the largest AI-based creativity platform, Artbreeder, where users can generate images using pre-trained GAN models. We explore the latent dimensions of images generated on this platform and present a novel framework for manipulating images to make them more creative. Our code and dataset are available at http://github.com/catlab-team/latentcreative.
Guided Image-to-Image Translation with Bi-Directional Feature Transformation
Oct 24, 2019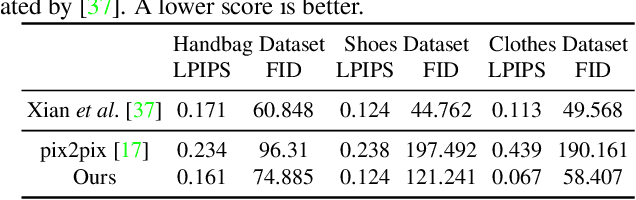
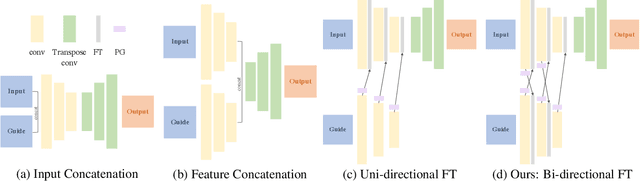
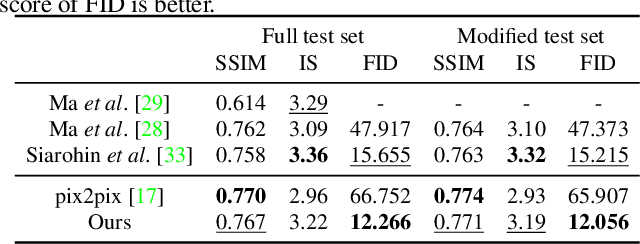
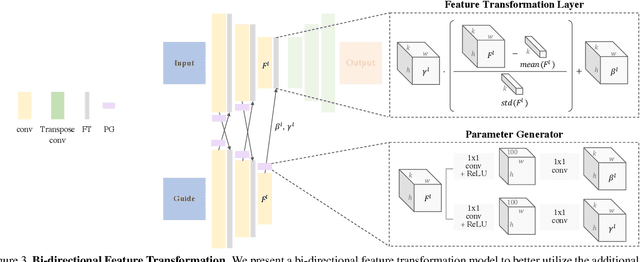
We address the problem of guided image-to-image translation where we translate an input image into another while respecting the constraints provided by an external, user-provided guidance image. Various conditioning methods for leveraging the given guidance image have been explored, including input concatenation , feature concatenation, and conditional affine transformation of feature activations. All these conditioning mechanisms, however, are uni-directional, i.e., no information flow from the input image back to the guidance. To better utilize the constraints of the guidance image, we present a bi-directional feature transformation (bFT) scheme. We show that our bFT scheme outperforms other conditioning schemes and has comparable results to state-of-the-art methods on different tasks.