 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Denoising in FPGA using Generic Risk Estimation
Nov 16, 2021
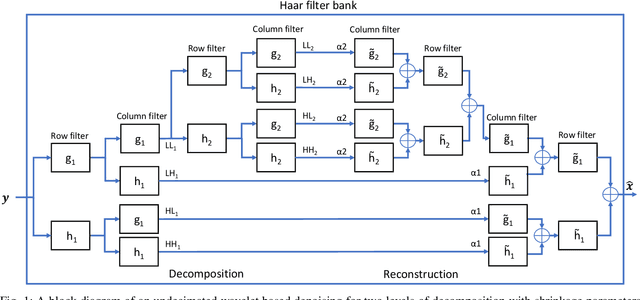
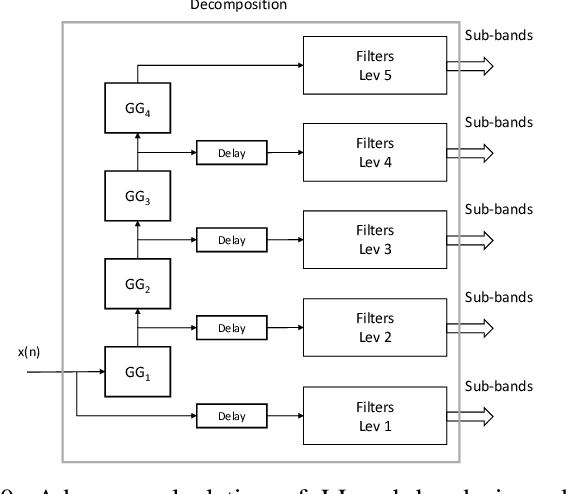
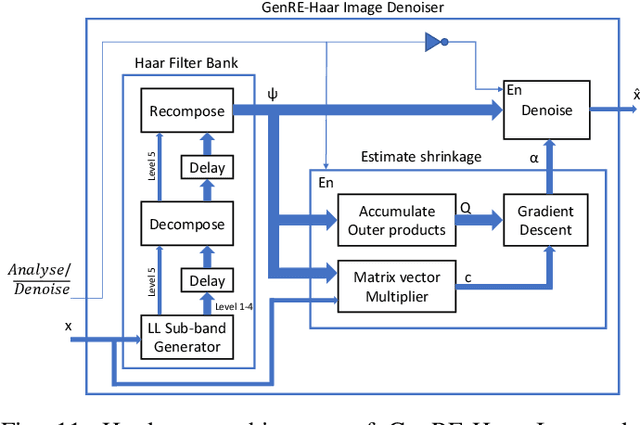

The generic risk estimator addresses the problem of denoising images corrupted by additive white noise without placing any restriction on the statistical distribution of the noise. In this paper, we discuss an efficient FPGA implementation of this algorithm. We use the undecimated Haar wavelet transform with shrinkage parameters for each sub-band as the denoising function. The computational complexity and memory requirement of the algorithm is first analyzed. To optimize the performance, a combination of convolution and recursion is employed to realize Haar filter bank and gradient descent algorithm is used to find the shrinkage parameters. A fully pipelined and parallel architecture is developed to achieve high throughput. The proposed design achieves an execution time of 3.5ms for an image of size 512x512. We also show that the recursive implementation of Haar wavelet is more expensive than the direct implementation in terms of hardware utilization.
PPT Fusion: Pyramid Patch Transformerfor a Case Study in Image Fusion
Jul 29, 2021

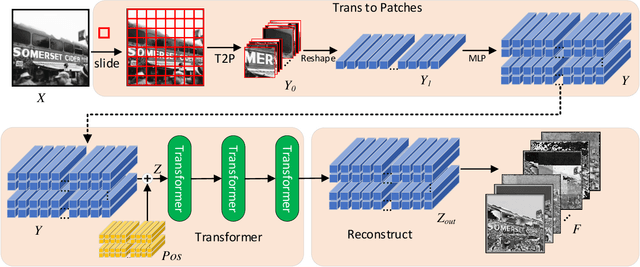
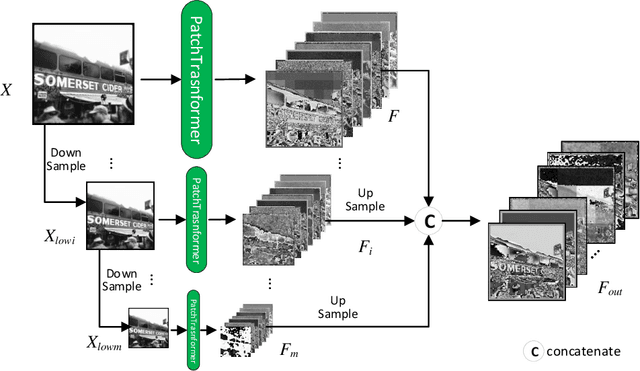
The Transformer architecture has achieved rapiddevelopment in recent years, outperforming the CNN archi-tectures in many computer vision tasks, such as the VisionTransformers (ViT) for image classification. However, existingvisual transformer models aim to extract semantic informationfor high-level tasks such as classification and detection, distortingthe spatial resolution of the input image, thus sacrificing thecapacity in reconstructing the input or generating high-resolutionimages. In this paper, therefore, we propose a Patch PyramidTransformer(PPT) to effectively address the above issues. Specif-ically, we first design a Patch Transformer to transform theimage into a sequence of patches, where transformer encodingis performed for each patch to extract local representations.In addition, we construct a Pyramid Transformer to effectivelyextract the non-local information from the entire image. Afterobtaining a set of multi-scale, multi-dimensional, and multi-anglefeatures of the original image, we design the image reconstructionnetwork to ensure that the features can be reconstructed intothe original input. To validate the effectiveness, we apply theproposed Patch Pyramid Transformer to the image fusion task.The experimental results demonstrate its superior performanceagainst the state-of-the-art fusion approaches, achieving the bestresults on several evaluation indicators. The underlying capacityof the PPT network is reflected by its universal power in featureextraction and image reconstruction, which can be directlyapplied to different image fusion tasks without redesigning orretraining the network.
Unveiling The Mask of Position-Information Pattern Through the Mist of Image Features
Jun 02, 2022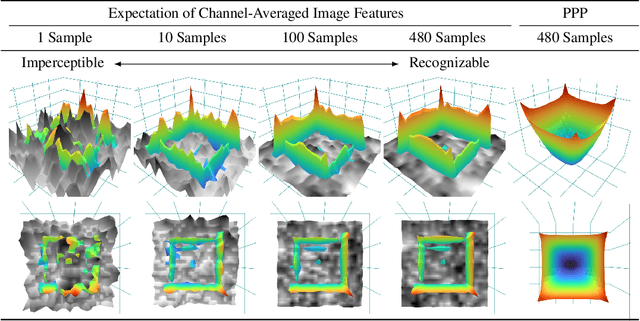
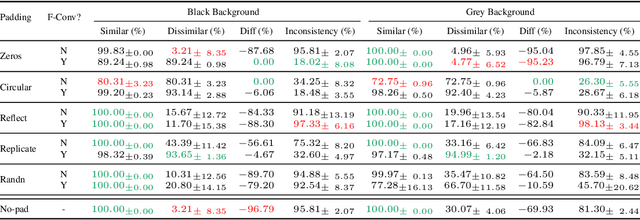
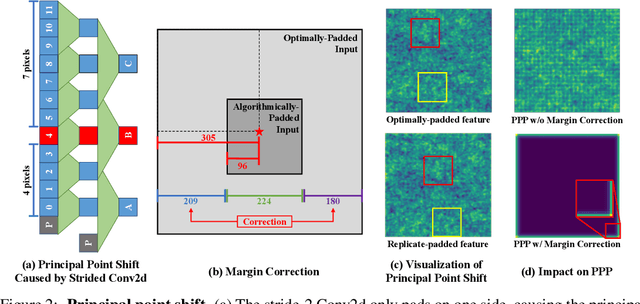
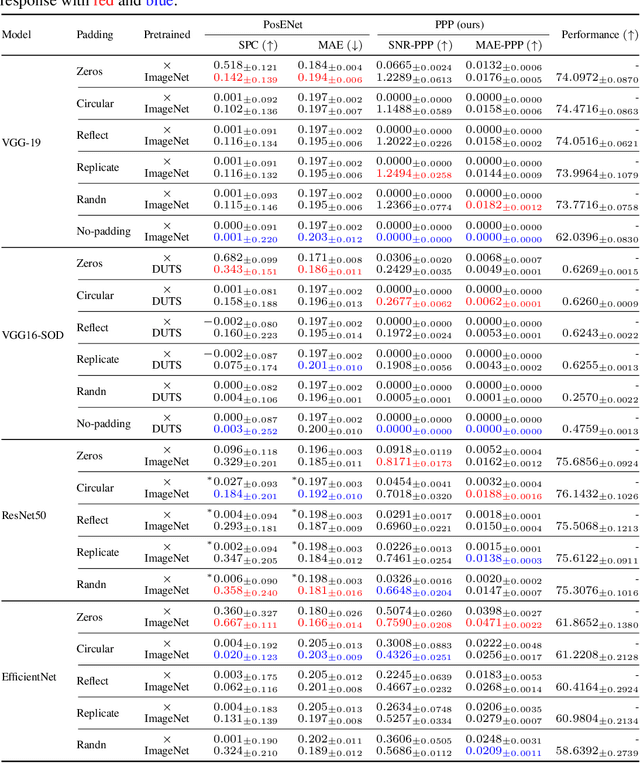
Recent studies show that paddings in convolutional neural networks encode absolute position information which can negatively affect the model performance for certain tasks. However, existing metrics for quantifying the strength of positional information remain unreliable and frequently lead to erroneous results. To address this issue, we propose novel metrics for measuring (and visualizing) the encoded positional information. We formally define the encoded information as PPP (Position-information Pattern from Padding) and conduct a series of experiments to study its properties as well as its formation. The proposed metrics measure the presence of positional information more reliably than the existing metrics based on PosENet and a test in F-Conv. We also demonstrate that for any extant (and proposed) padding schemes, PPP is primarily a learning artifact and is less dependent on the characteristics of the underlying padding schemes.
Sliced-Wasserstein normalizing flows: beyond maximum likelihood training
Jul 12, 2022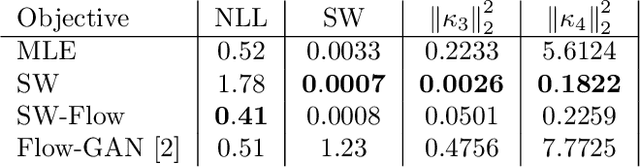
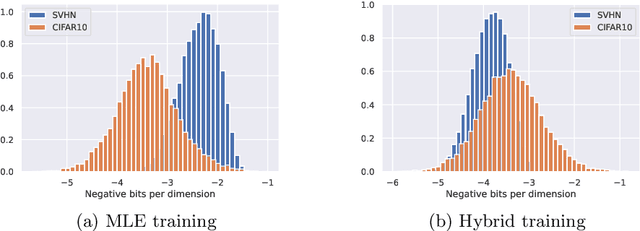

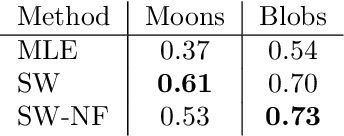
Despite their advantages, normalizing flows generally suffer from several shortcomings including their tendency to generate unrealistic data (e.g., images) and their failing to detect out-of-distribution data. One reason for these deficiencies lies in the training strategy which traditionally exploits a maximum likelihood principle only. This paper proposes a new training paradigm based on a hybrid objective function combining the maximum likelihood principle (MLE) and a sliced-Wasserstein distance. Results obtained on synthetic toy examples and real image data sets show better generative abilities in terms of both likelihood and visual aspects of the generated samples. Reciprocally, the proposed approach leads to a lower likelihood of out-of-distribution data, demonstrating a greater data fidelity of the resulting flows.
Semi-supervised Contrastive Learning for Label-efficient Medical Image Segmentation
Sep 28, 2021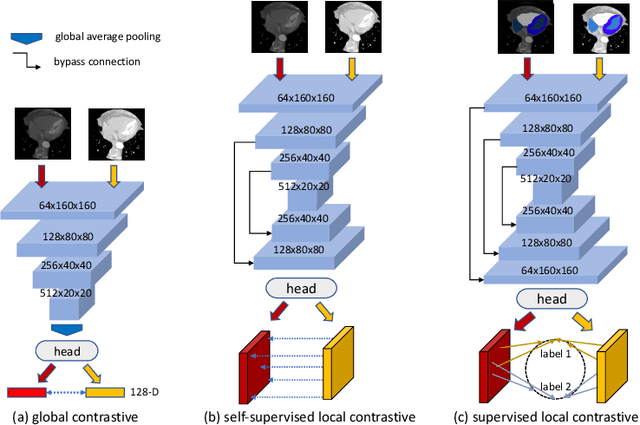
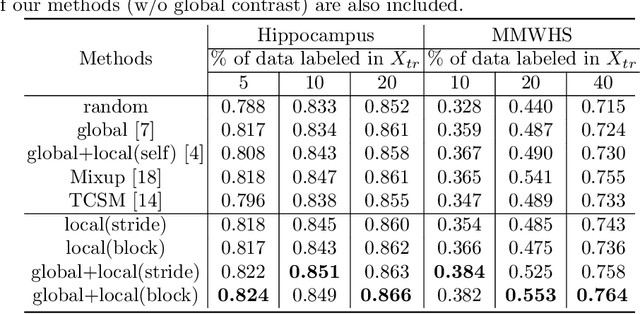
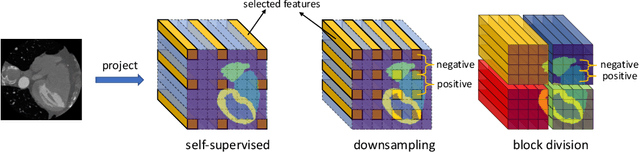
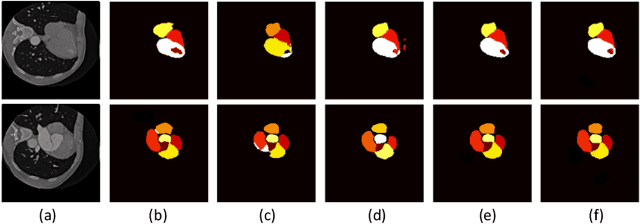
The success of deep learning methods in medical image segmentation tasks heavily depends on a large amount of labeled data to supervise the training. On the other hand, the annotation of biomedical images requires domain knowledge and can be laborious. Recently, contrastive learning has demonstrated great potential in learning latent representation of images even without any label. Existing works have explored its application to biomedical image segmentation where only a small portion of data is labeled, through a pre-training phase based on self-supervised contrastive learning without using any labels followed by a supervised fine-tuning phase on the labeled portion of data only. In this paper, we establish that by including the limited label in formation in the pre-training phase, it is possible to boost the performance of contrastive learning. We propose a supervised local contrastive loss that leverages limited pixel-wise annotation to force pixels with the same label to gather around in the embedding space. Such loss needs pixel-wise computation which can be expensive for large images, and we further propose two strategies, downsampling and block division, to address the issue. We evaluate our methods on two public biomedical image datasets of different modalities. With different amounts of labeled data, our methods consistently outperform the state-of-the-art contrast-based methods and other semi-supervised learning techniques.
Seeing Far in the Dark with Patterned Flash
Jul 25, 2022
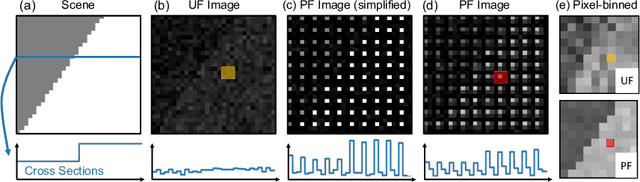
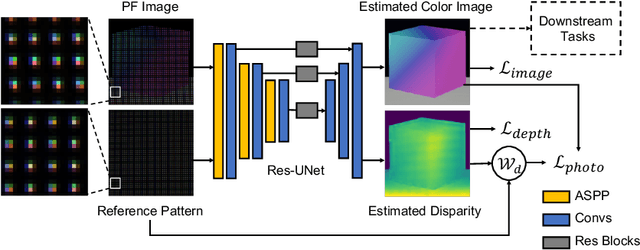
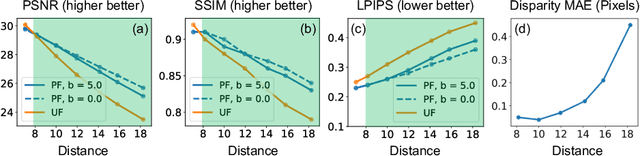
Flash illumination is widely used in imaging under low-light environments. However, illumination intensity falls off with propagation distance quadratically, which poses significant challenges for flash imaging at a long distance. We propose a new flash technique, named ``patterned flash'', for flash imaging at a long distance. Patterned flash concentrates optical power into a dot array. Compared with the conventional uniform flash where the signal is overwhelmed by the noise everywhere, patterned flash provides stronger signals at sparsely distributed points across the field of view to ensure the signals at those points stand out from the sensor noise. This enables post-processing to resolve important objects and details. Additionally, the patterned flash projects texture onto the scene, which can be treated as a structured light system for depth perception. Given the novel system, we develop a joint image reconstruction and depth estimation algorithm with a convolutional neural network. We build a hardware prototype and test the proposed flash technique on various scenes. The experimental results demonstrate that our patterned flash has significantly better performance at long distances in low-light environments.
A Shading-Guided Generative Implicit Model for Shape-Accurate 3D-Aware Image Synthesis
Nov 01, 2021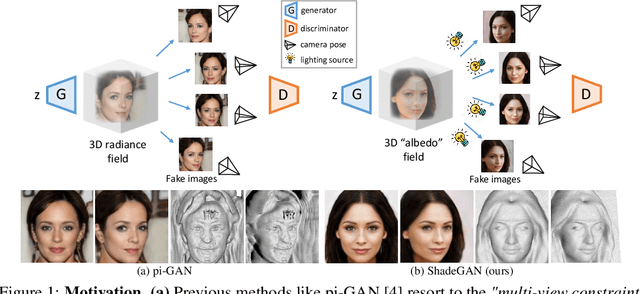
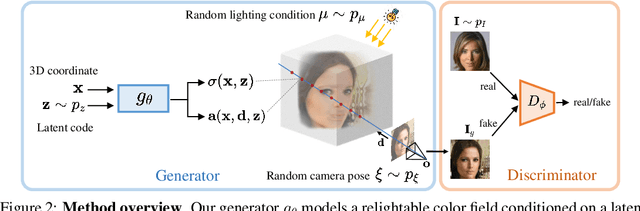
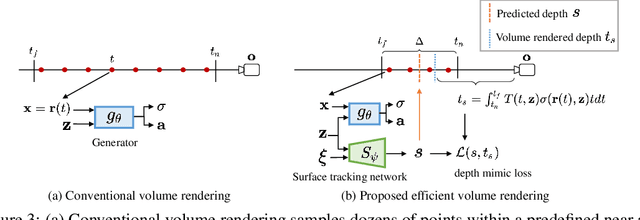

The advancement of generative radiance fields has pushed the boundary of 3D-aware image synthesis. Motivated by the observation that a 3D object should look realistic from multiple viewpoints, these methods introduce a multi-view constraint as regularization to learn valid 3D radiance fields from 2D images. Despite the progress, they often fall short of capturing accurate 3D shapes due to the shape-color ambiguity, limiting their applicability in downstream tasks. In this work, we address this ambiguity by proposing a novel shading-guided generative implicit model that is able to learn a starkly improved shape representation. Our key insight is that an accurate 3D shape should also yield a realistic rendering under different lighting conditions. This multi-lighting constraint is realized by modeling illumination explicitly and performing shading with various lighting conditions. Gradients are derived by feeding the synthesized images to a discriminator. To compensate for the additional computational burden of calculating surface normals, we further devise an efficient volume rendering strategy via surface tracking, reducing the training and inference time by 24% and 48%, respectively. Our experiments on multiple datasets show that the proposed approach achieves photorealistic 3D-aware image synthesis while capturing accurate underlying 3D shapes. We demonstrate improved performance of our approach on 3D shape reconstruction against existing methods, and show its applicability on image relighting. Our code will be released at https://github.com/XingangPan/ShadeGAN.
Irrelevant Pixels are Everywhere: Find and Exclude Them for More Efficient Computer Vision
Jul 21, 2022

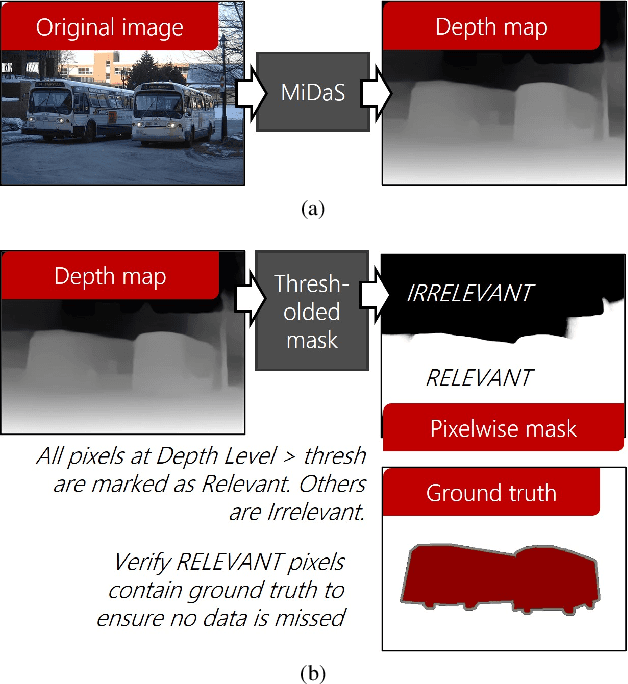
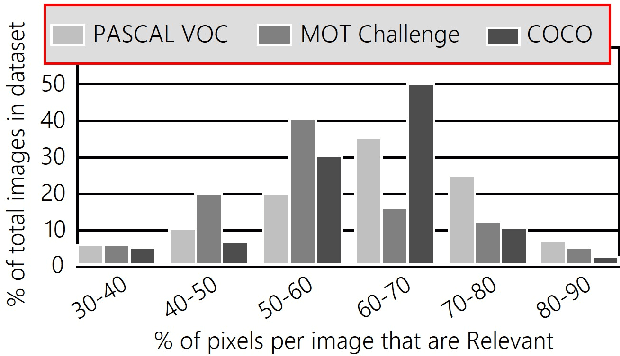
Computer vision is often performed using Convolutional Neural Networks (CNNs). CNNs are compute-intensive and challenging to deploy on power-contrained systems such as mobile and Internet-of-Things (IoT) devices. CNNs are compute-intensive because they indiscriminately compute many features on all pixels of the input image. We observe that, given a computer vision task, images often contain pixels that are irrelevant to the task. For example, if the task is looking for cars, pixels in the sky are not very useful. Therefore, we propose that a CNN be modified to only operate on relevant pixels to save computation and energy. We propose a method to study three popular computer vision datasets, finding that 48% of pixels are irrelevant. We also propose the focused convolution to modify a CNN's convolutional layers to reject the pixels that are marked irrelevant. On an embedded device, we observe no loss in accuracy, while inference latency, energy consumption, and multiply-add count are all reduced by about 45%.
Analysis of Multiscale Wavelet-based Fractional Gradient-Anisotropic Diffusion Fusion for single hazy and underwater image enhancement
Nov 10, 2021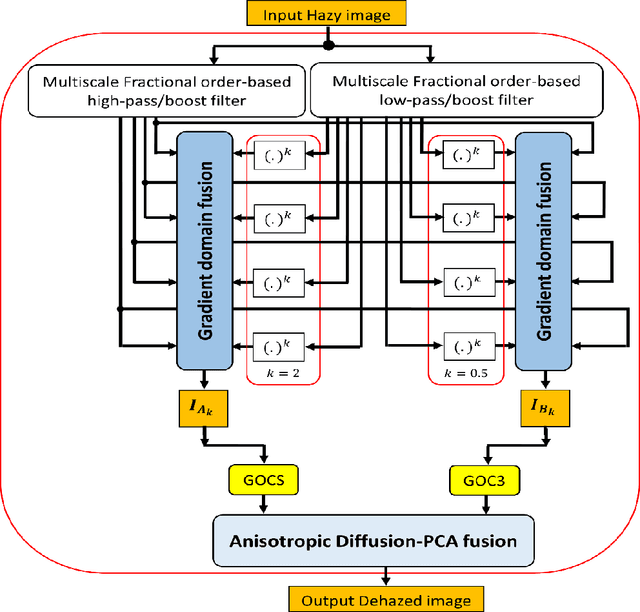
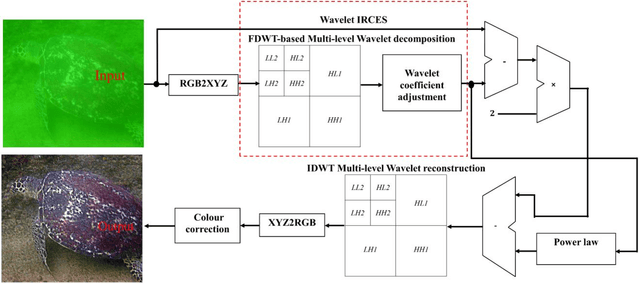


This report presents the results of a multi-scale wavelet based scheme for single image de-hazing and underwater image enhancement. The scheme is fast and highly localized in addition to global enhancement of hazy images. A PDE-based formulation enables additional versatility as the iterative nature allows more flexibility for various types of images. Visual and objective results from experiments indicate that the proposed approach competes favourably or surpasses most of the state-of-the-art approaches.
Convolutional Neural Processes for Inpainting Satellite Images
May 24, 2022

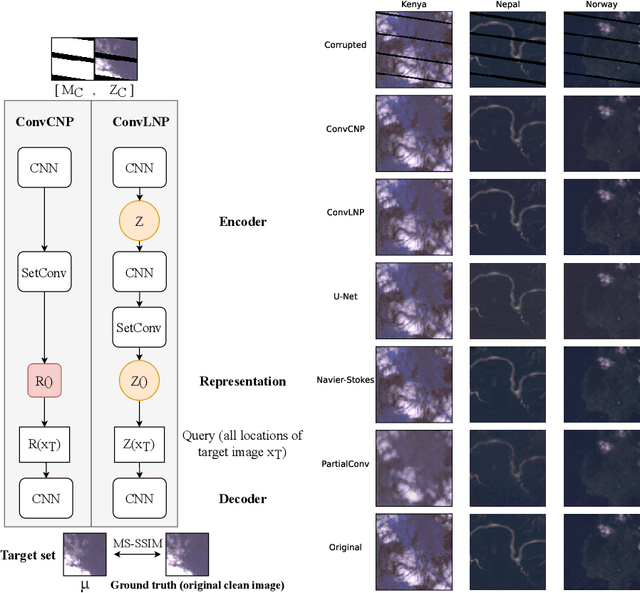
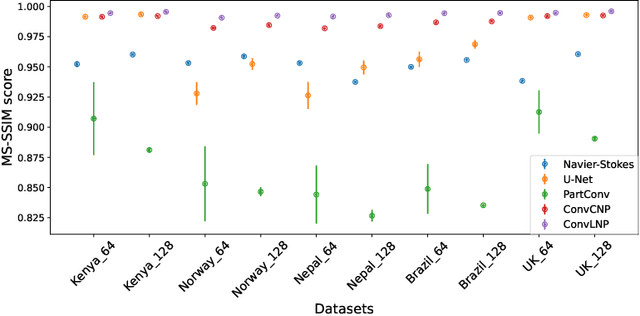
The widespread availability of satellite images has allowed researchers to model complex systems such as disease dynamics. However, many satellite images have missing values due to measurement defects, which render them unusable without data imputation. For example, the scanline corrector for the LANDSAT 7 satellite broke down in 2003, resulting in a loss of around 20\% of its data. Inpainting involves predicting what is missing based on the known pixels and is an old problem in image processing, classically based on PDEs or interpolation methods, but recent deep learning approaches have shown promise. However, many of these methods do not explicitly take into account the inherent spatiotemporal structure of satellite images. In this work, we cast satellite image inpainting as a natural meta-learning problem, and propose using convolutional neural processes (ConvNPs) where we frame each satellite image as its own task or 2D regression problem. We show ConvNPs can outperform classical methods and state-of-the-art deep learning inpainting models on a scanline inpainting problem for LANDSAT 7 satellite images, assessed on a variety of in and out-of-distribution images.