 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TransMEF: A Transformer-Based Multi-Exposure Image Fusion Framework using Self-Supervised Multi-Task Learning
Dec 15, 2021
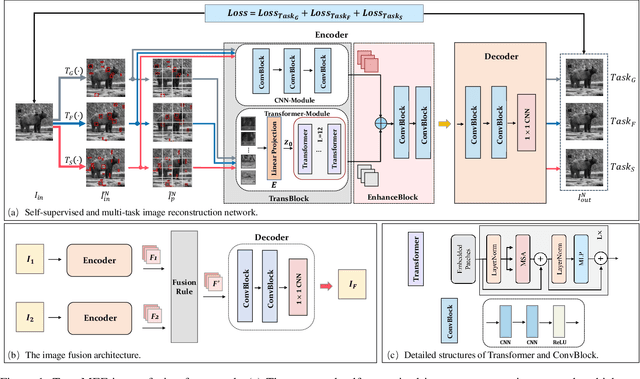
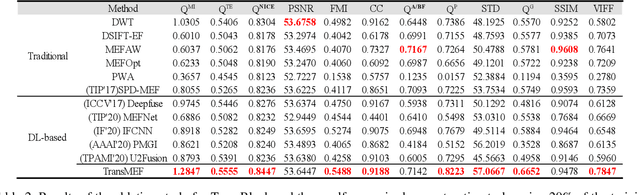


In this paper, we propose TransMEF, a transformer-based multi-exposure image fusion framework that uses self-supervised multi-task learning. The framework is based on an encoder-decoder network, which can be trained on large natural image datasets and does not require ground truth fusion images. We design three self-supervised reconstruction tasks according to the characteristics of multi-exposure images and conduct these tasks simultaneously using multi-task learning; through this process, the network can learn the characteristics of multi-exposure images and extract more generalized features. In addition, to compensate for the defect in establishing long-range dependencies in CNN-based architectures, we design an encoder that combines a CNN module with a transformer module. This combination enables the network to focus on both local and global information. We evaluated our method and compared it to 11 competitive traditional and deep learning-based methods on the latest released multi-exposure image fusion benchmark dataset, and our method achieved the best performance in both subjective and objective evaluations.
A photosensor employing data-driven binning for ultrafast image recognition
Nov 20, 2021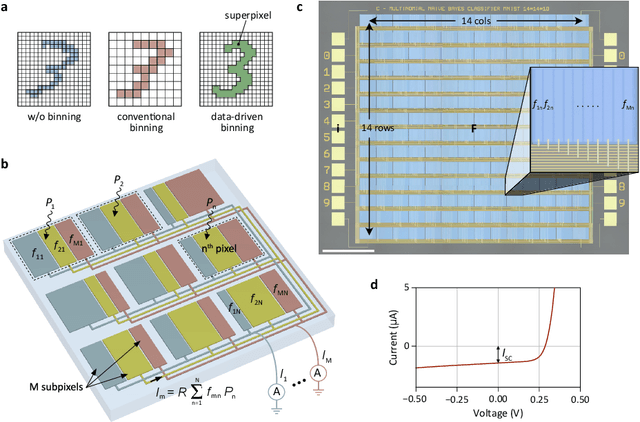
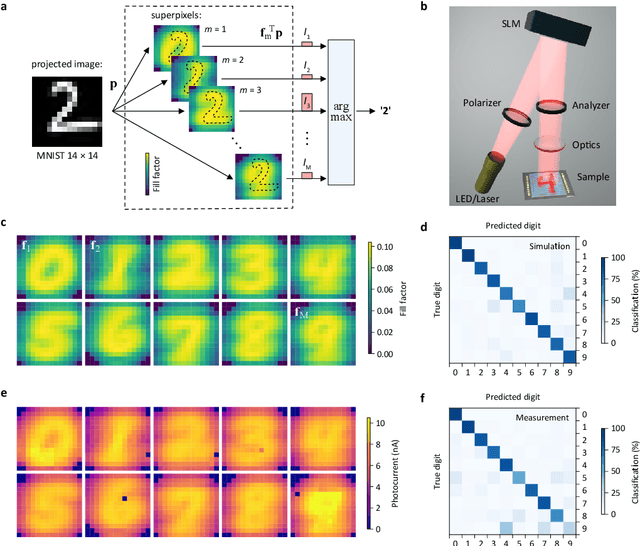
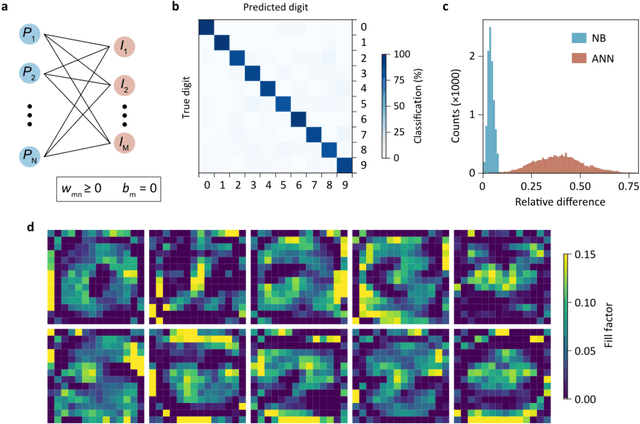
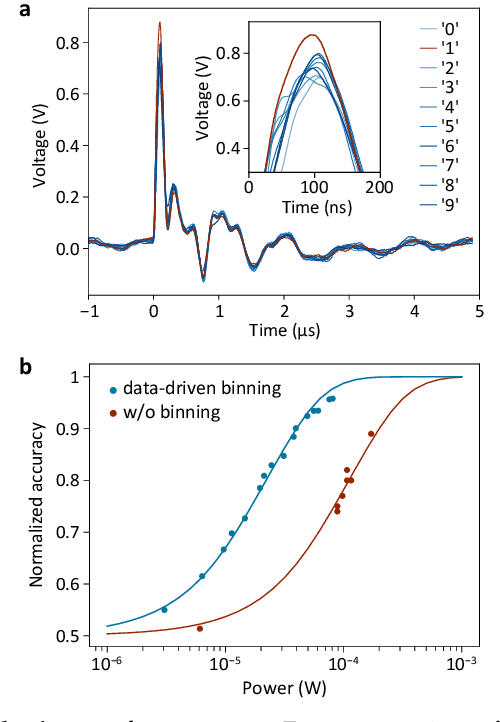
Pixel binning is a technique, widely used in optical image acquisition and spectroscopy, in which adjacent detector elements of an image sensor are combined into larger pixels. This reduces the amount of data to be processed as well as the impact of noise, but comes at the cost of a loss of information. Here, we push the concept of binning to its limit by combining a large fraction of the sensor elements into a single superpixel that extends over the whole face of the chip. For a given pattern recognition task, its optimal shape is determined from training data using a machine learning algorithm. We demonstrate the classification of optically projected images from the MNIST dataset on a nanosecond timescale, with enhanced sensitivity and without loss of classification accuracy. Our concept is not limited to imaging alone but can also be applied in optical spectroscopy or other sensing applications.
3rd Place: A Global and Local Dual Retrieval Solution to Facebook AI Image Similarity Challenge
Dec 04, 2021
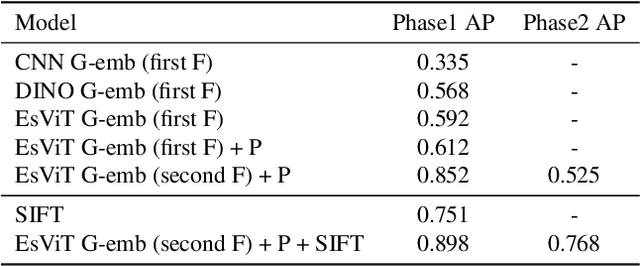
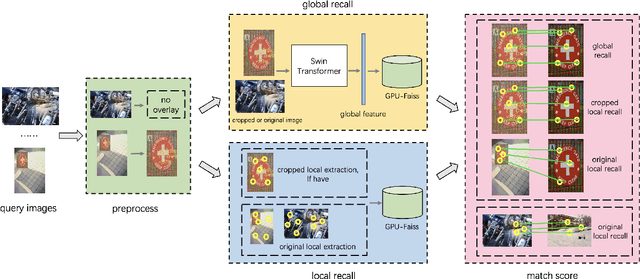
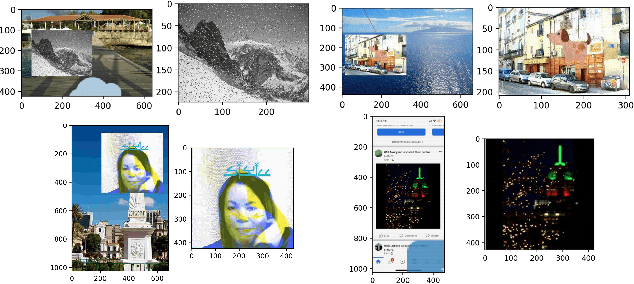
As a basic task of computer vision, image similarity retrieval is facing the challenge of large-scale data and image copy attacks. This paper presents our 3rd place solution to the matching track of Image Similarity Challenge (ISC) 2021 organized by Facebook AI. We propose a multi-branch retrieval method of combining global descriptors and local descriptors to cover all attack cases. Specifically, we attempt many strategies to optimize global descriptors, including abundant data augmentations, self-supervised learning with a single Transformer model, overlay detection preprocessing. Moreover, we introduce the robust SIFT feature and GPU Faiss for local retrieval which makes up for the shortcomings of the global retrieval. Finally, KNN-matching algorithm is used to judge the match and merge scores. We show some ablation experiments of our method, which reveals the complementary advantages of global and local features.
FCSN: Global Context Aware Segmentation by Learning the Fourier Coefficients of Objects in Medical Images
Jul 29, 2022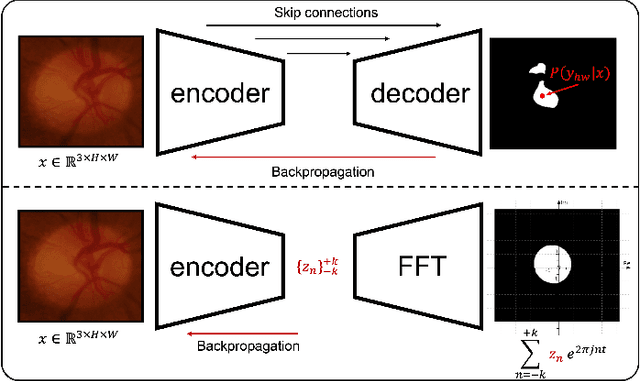
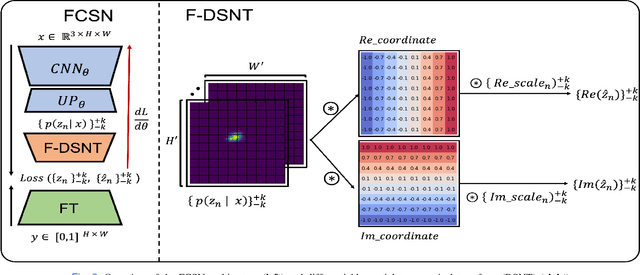

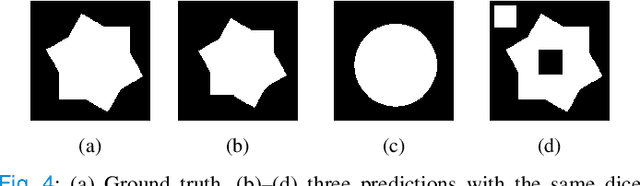
The encoder-decoder model is a commonly used Deep Neural Network (DNN) model for medical image segmentation. Conventional encoder-decoder models make pixel-wise predictions focusing heavily on local patterns around the pixel. This makes it challenging to give segmentation that preserves the object's shape and topology, which often requires an understanding of the global context of the object. In this work, we propose a Fourier Coefficient Segmentation Network~(FCSN) -- a novel DNN-based model that segments an object by learning the complex Fourier coefficients of the object's masks. The Fourier coefficients are calculated by integrating over the whole contour. Therefore, for our model to make a precise estimation of the coefficients, the model is motivated to incorporate the global context of the object, leading to a more accurate segmentation of the object's shape. This global context awareness also makes our model robust to unseen local perturbations during inference, such as additive noise or motion blur that are prevalent in medical images. When FCSN is compared with other state-of-the-art models (UNet+, DeepLabV3+, UNETR) on 3 medical image segmentation tasks (ISIC\_2018, RIM\_CUP, RIM\_DISC), FCSN attains significantly lower Hausdorff scores of 19.14 (6\%), 17.42 (6\%), and 9.16 (14\%) on the 3 tasks, respectively. Moreover, FCSN is lightweight by discarding the decoder module, which incurs significant computational overhead. FCSN only requires 22.2M parameters, 82M and 10M fewer parameters than UNETR and DeepLabV3+. FCSN attains inference and training speeds of 1.6ms/img and 6.3ms/img, that is 8$\times$ and 3$\times$ faster than UNet and UNETR.
Each Attribute Matters: Contrastive Attention for Sentence-based Image Editing
Oct 21, 2021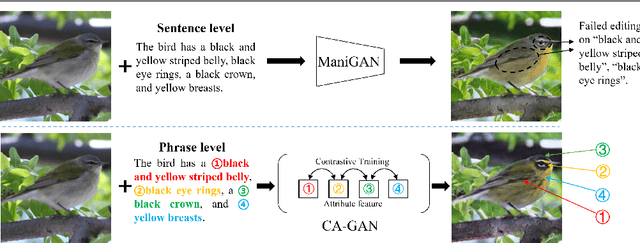

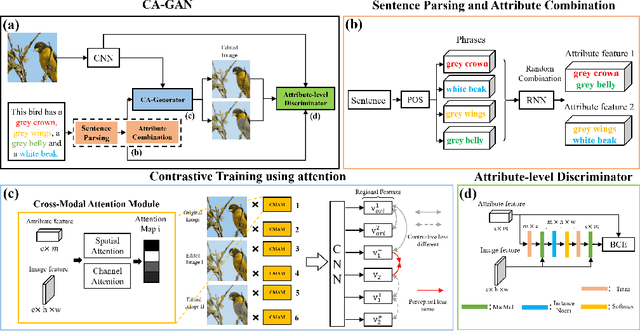
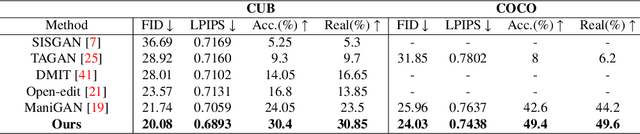
Sentence-based Image Editing (SIE) aims to deploy natural language to edit an image. Offering potentials to reduce expensive manual editing, SIE has attracted much interest recently. However, existing methods can hardly produce accurate editing and even lead to failures in attribute editing when the query sentence is with multiple editable attributes. To cope with this problem, by focusing on enhancing the difference between attributes, this paper proposes a novel model called Contrastive Attention Generative Adversarial Network (CA-GAN), which is inspired from contrastive training. Specifically, we first design a novel contrastive attention module to enlarge the editing difference between random combinations of attributes which are formed during training. We then construct an attribute discriminator to ensure effective editing on each attribute. A series of experiments show that our method can generate very encouraging results in sentence-based image editing with multiple attributes on CUB and COCO dataset. Our code is available at https://github.com/Zlq2021/CA-GAN
Fundamentals of Task-Agnostic Data Valuation
Aug 25, 2022
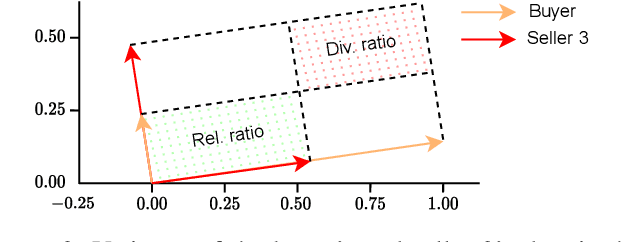
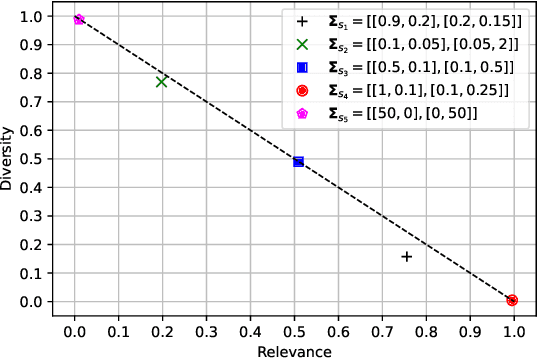
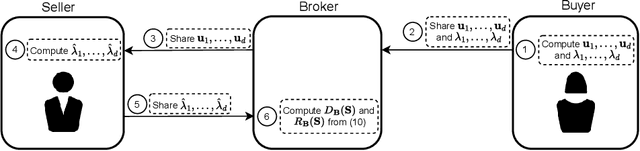
We study valuing the data of a data owner/seller for a data seeker/buyer. Data valuation is often carried out for a specific task assuming a particular utility metric, such as test accuracy on a validation set, that may not exist in practice. In this work, we focus on task-agnostic data valuation without any validation requirements. The data buyer has access to a limited amount of data (which could be publicly available) and seeks more data samples from a data seller. We formulate the problem as estimating the differences in the statistical properties of the data at the seller with respect to the baseline data available at the buyer. We capture these statistical differences through second moment by measuring diversity and relevance of the seller's data for the buyer; we estimate these measures through queries to the seller without requesting raw data. We design the queries with the proposed approach so that the seller is blind to the buyer's raw data and has no knowledge to fabricate responses to queries to obtain a desired outcome of the diversity and relevance trade-off.We will show through extensive experiments on real tabular and image datasets that the proposed estimates capture the diversity and relevance of the seller's data for the buyer.
GraphTTA: Test Time Adaptation on Graph Neural Networks
Aug 19, 2022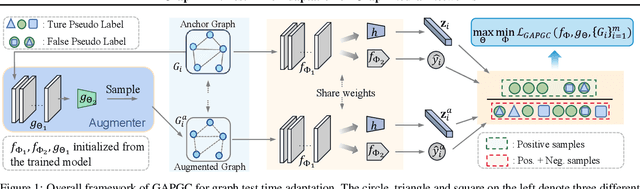
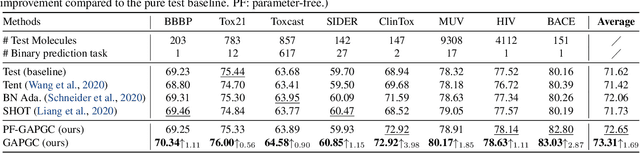
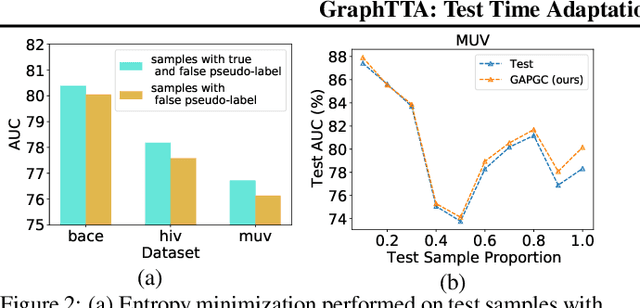

Recently, test time adaptation (TTA) has attracted increasing attention due to its power of handling the distribution shift issue in the real world. Unlike what has been developed for convolutional neural networks (CNNs) for image data, TTA is less explored for Graph Neural Networks (GNNs). There is still a lack of efficient algorithms tailored for graphs with irregular structures. In this paper, we present a novel test time adaptation strategy named Graph Adversarial Pseudo Group Contrast (GAPGC), for graph neural networks TTA, to better adapt to the Out Of Distribution (OOD) test data. Specifically, GAPGC employs a contrastive learning variant as a self-supervised task during TTA, equipped with Adversarial Learnable Augmenter and Group Pseudo-Positive Samples to enhance the relevance between the self-supervised task and the main task, boosting the performance of the main task. Furthermore, we provide theoretical evidence that GAPGC can extract minimal sufficient information for the main task from information theory perspective. Extensive experiments on molecular scaffold OOD dataset demonstrated that the proposed approach achieves state-of-the-art performance on GNNs.
Topological structure of complex predictions
Aug 06, 2022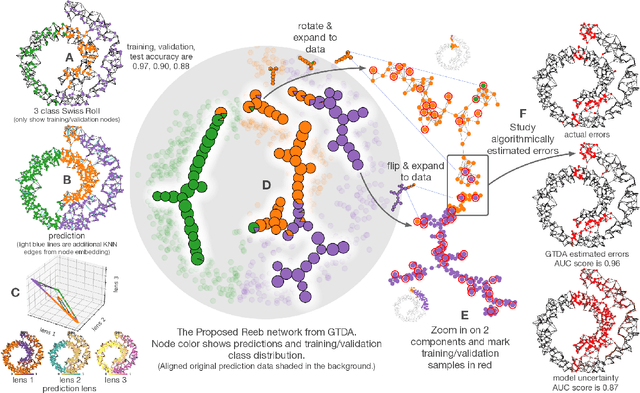

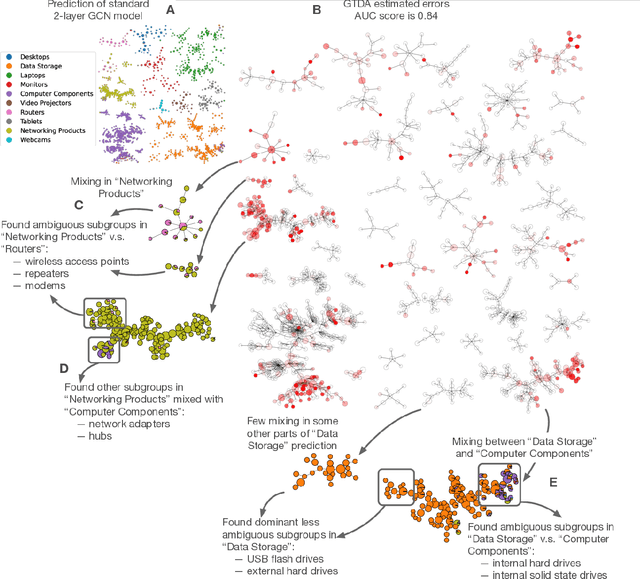
Complex prediction models such as deep learning are the output from fitting machine learning, neural networks, or AI models to a set of training data. These are now standard tools in science. A key challenge with the current generation of models is that they are highly parameterized, which makes describing and interpreting the prediction strategies difficult. We use topological data analysis to transform these complex prediction models into pictures representing a topological view. The result is a map of the predictions that enables inspection. The methods scale up to large datasets across different domains and enable us to detect labeling errors in training data, understand generalization in image classification, and inspect predictions of likely pathogenic mutations in the BRCA1 gene.
Transferring Knowledge with Attention Distillation for Multi-Domain Image-to-Image Translation
Aug 17, 2021



Gradient-based attention modeling has been used widely as a way to visualize and understand convolutional neural networks. However, exploiting these visual explanations during the training of generative adversarial networks (GANs) is an unexplored area in computer vision research. Indeed, we argue that this kind of information can be used to influence GANs training in a positive way. For this reason, in this paper, it is shown how gradient based attentions can be used as knowledge to be conveyed in a teacher-student paradigm for multi-domain image-to-image translation tasks in order to improve the results of the student architecture. Further, it is demonstrated how "pseudo"-attentions can also be employed during training when teacher and student networks are trained on different domains which share some similarities. The approach is validated on multi-domain facial attributes transfer and human expression synthesis showing both qualitative and quantitative results.
Bilateral Spectrum Weighted Total Variation for Noisy-Image Super-Resolution and Image Denoising
Jun 05, 2021


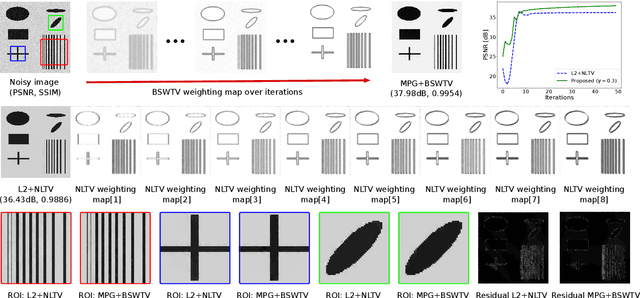
In this paper, we propose a regularization technique for noisy-image super-resolution and image denoising. Total variation (TV) regularization is adopted in many image processing applications to preserve the local smoothness. However, TV prior is prone to oversmoothness, staircasing effect, and contrast losses. Nonlocal TV (NLTV) mitigates the contrast losses by adaptively weighting the smoothness based on the similarity measure of image patches. Although it suppresses the noise effectively in the flat regions, it might leave residual noise surrounding the edges especially when the image is not oversmoothed. To address this problem, we propose the bilateral spectrum weighted total variation (BSWTV). Specially, we apply a locally adaptive shrink coefficient to the image gradients and employ the eigenvalues of the covariance matrix of the weighted image gradients to effectively refine the weighting map and suppress the residual noise. In conjunction with the data fidelity term derived from a mixed Poisson-Gaussian noise model, the objective function is decomposed and solved by the alternating direction method of multipliers (ADMM) algorithm. In order to remove outliers and facilitate the convergence stability, the weighting map is smoothed by a Gaussian filter with an iteratively decreased kernel width and updated in a momentum-based manner in each ADMM iteration. We benchmark our method with the state-of-the-art approaches on the public real-world datasets for super-resolution and image denoising. Experiments show that the proposed method obtains outstanding performance for super-resolution and achieves promising results for denoising on real-world images.