 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Nonlinear Intensity Sonar Image Matching based on Deep Convolution Features
Nov 17, 2021
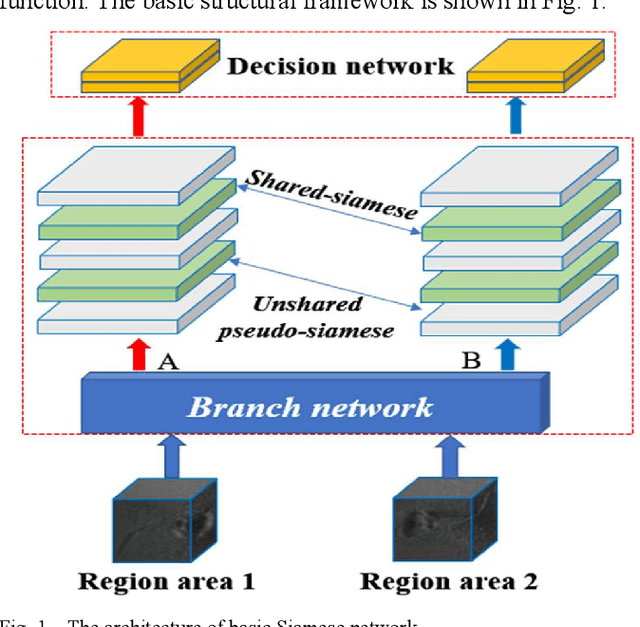
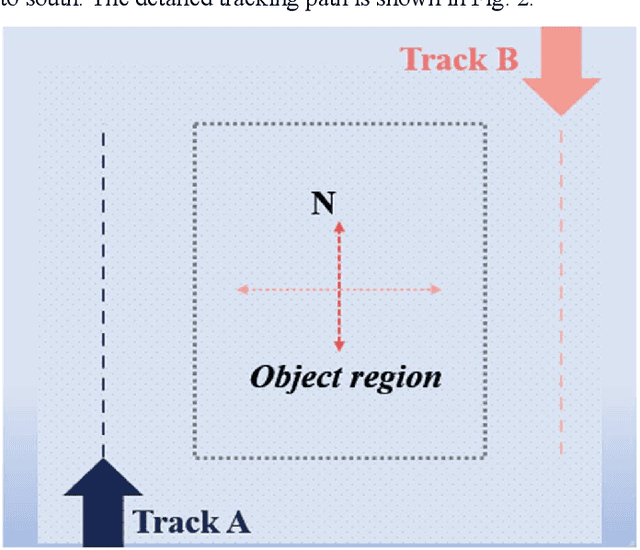
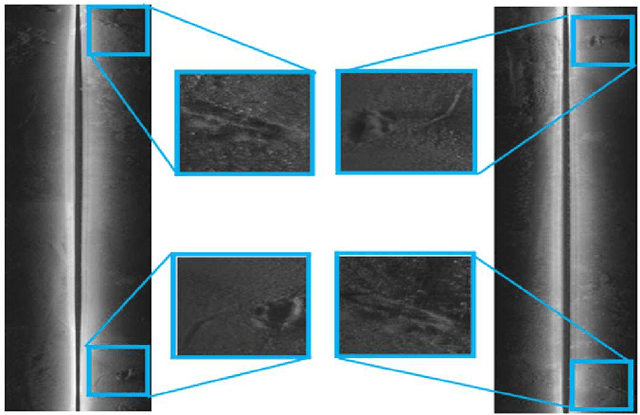
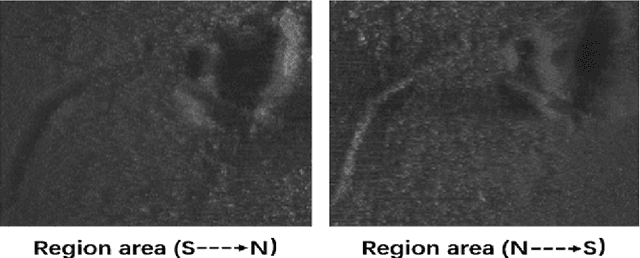
In the field of deep-sea exploration, sonar is presently the only efficient long-distance sensing device. The complicated underwater environment, such as noise interference, low target intensity or background dynamics, has brought many negative effects on sonar imaging. Among them, the problem of nonlinear intensity is extremely prevalent. It is also known as the anisotropy of acoustic imaging, that is, when AUVs carry sonar to detect the same target from different angles, the intensity difference between image pairs is sometimes very large, which makes the traditional matching algorithm almost ineffective. However, image matching is the basis of comprehensive tasks such as navigation, positioning, and mapping. Therefore, it is very valuable to obtain robust and accurate matching results. This paper proposes a combined matching method based on phase information and deep convolution features. It has two outstanding advantages: one is that deep convolution features could be used to measure the similarity of the local and global positions of the sonar image; the other is that local feature matching could be performed at the key target position of the sonar image. This method does not need complex manual design, and completes the matching task of nonlinear intensity sonar images in a close end-to-end manner. Feature matching experiments are carried out on the deep-sea sonar images captured by AUVs, and the results show that our proposal has good matching accuracy and robustness.
GLASS: Global to Local Attention for Scene-Text Spotting
Aug 05, 2022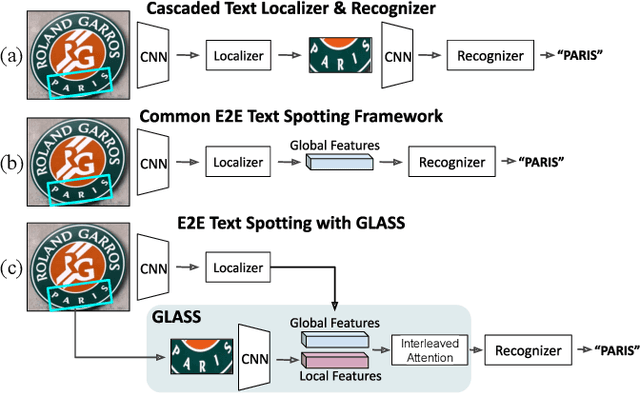
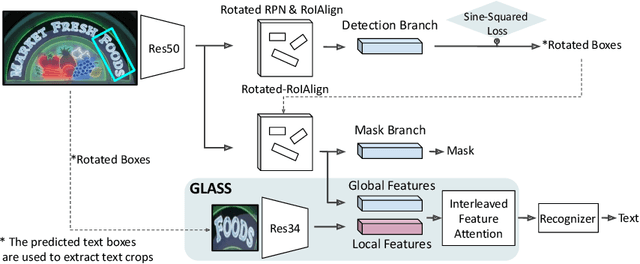
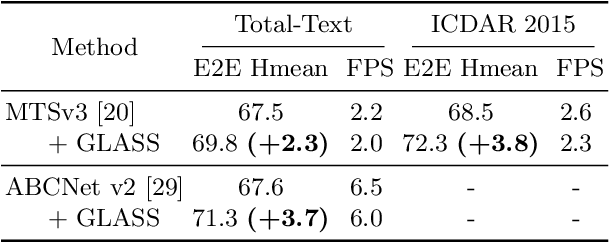
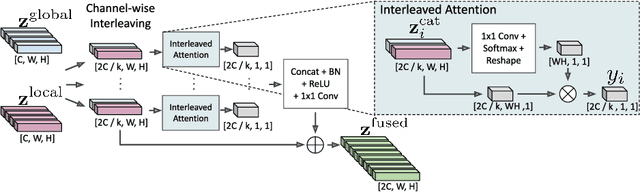
In recent years, the dominant paradigm for text spotting is to combine the tasks of text detection and recognition into a single end-to-end framework. Under this paradigm, both tasks are accomplished by operating over a shared global feature map extracted from the input image. Among the main challenges that end-to-end approaches face is the performance degradation when recognizing text across scale variations (smaller or larger text), and arbitrary word rotation angles. In this work, we address these challenges by proposing a novel global-to-local attention mechanism for text spotting, termed GLASS, that fuses together global and local features. The global features are extracted from the shared backbone, preserving contextual information from the entire image, while the local features are computed individually on resized, high-resolution rotated word crops. The information extracted from the local crops alleviates much of the inherent difficulties with scale and word rotation. We show a performance analysis across scales and angles, highlighting improvement over scale and angle extremities. In addition, we introduce an orientation-aware loss term supervising the detection task, and show its contribution to both detection and recognition performance across all angles. Finally, we show that GLASS is general by incorporating it into other leading text spotting architectures, improving their text spotting performance. Our method achieves state-of-the-art results on multiple benchmarks, including the newly released TextOCR.
Vision Transformers for Action Recognition: A Survey
Sep 13, 2022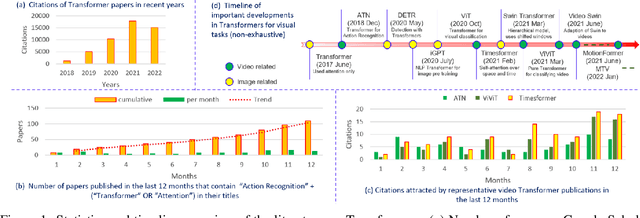
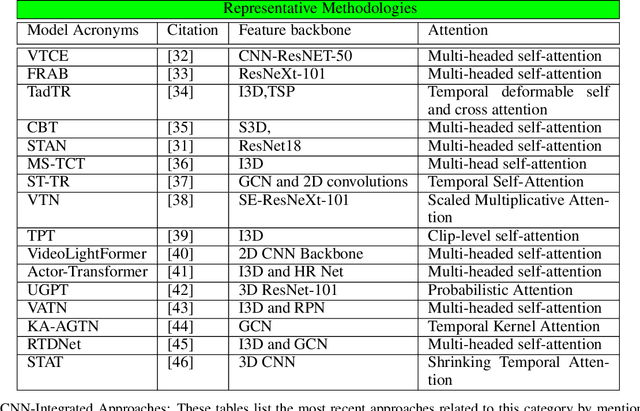
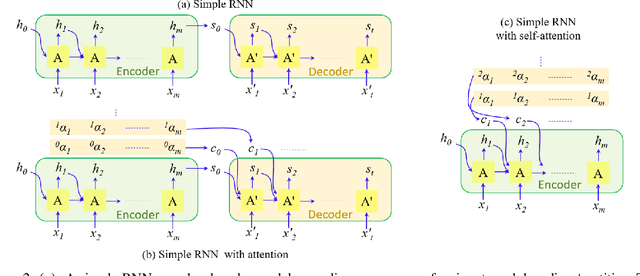
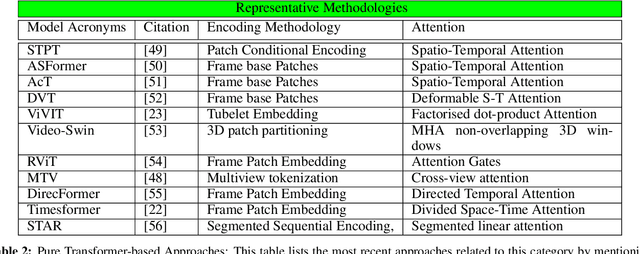
Vision transformers are emerging as a powerful tool to solve computer vision problems. Recent techniques have also proven the efficacy of transformers beyond the image domain to solve numerous video-related tasks. Among those, human action recognition is receiving special attention from the research community due to its widespread applications. This article provides the first comprehensive survey of vision transformer techniques for action recognition. We analyze and summarize the existing and emerging literature in this direction while highlighting the popular trends in adapting transformers for action recognition. Due to their specialized application, we collectively refer to these methods as ``action transformers''. Our literature review provides suitable taxonomies for action transformers based on their architecture, modality, and intended objective. Within the context of action transformers, we explore the techniques to encode spatio-temporal data, dimensionality reduction, frame patch and spatio-temporal cube construction, and various representation methods. We also investigate the optimization of spatio-temporal attention in transformer layers to handle longer sequences, typically by reducing the number of tokens in a single attention operation. Moreover, we also investigate different network learning strategies, such as self-supervised and zero-shot learning, along with their associated losses for transformer-based action recognition. This survey also summarizes the progress towards gaining grounds on evaluation metric scores on important benchmarks with action transformers. Finally, it provides a discussion on the challenges, outlook, and future avenues for this research direction.
Deep COVID-19 Recognition using Chest X-ray Images: A Comparative Analysis
Jul 26, 2022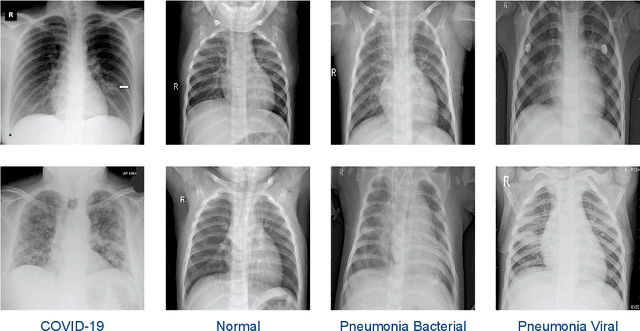
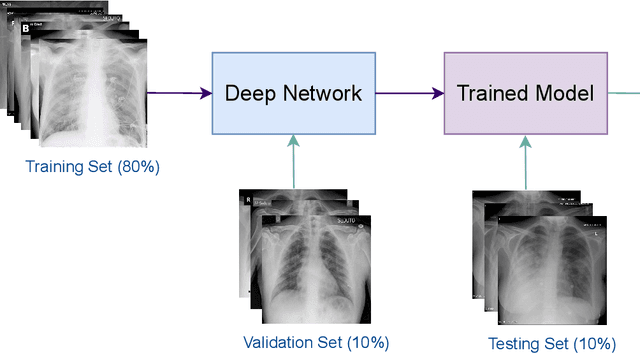
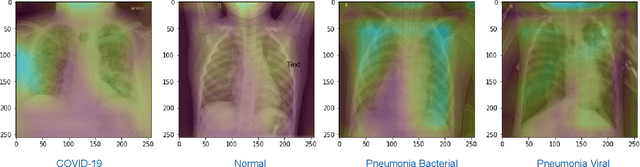
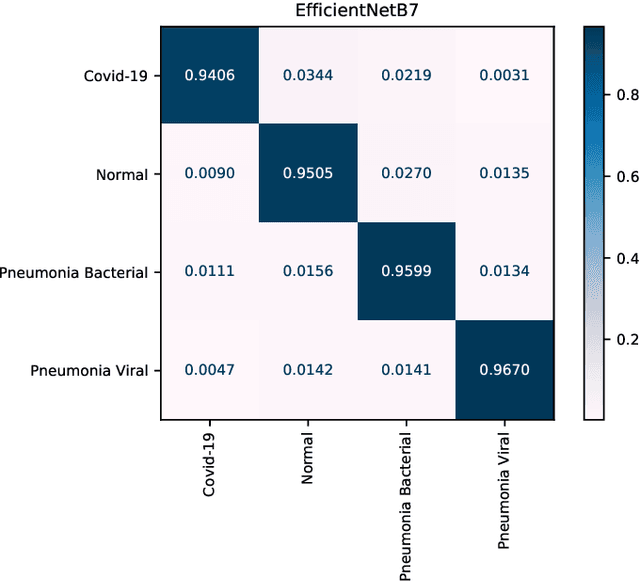
The novel coronavirus variant, which is also widely known as COVID-19, is currently a common threat to all humans across the world. Effective recognition of COVID-19 using advanced machine learning methods is a timely need. Although many sophisticated approaches have been proposed in the recent past, they still struggle to achieve expected performances in recognizing COVID-19 using chest X-ray images. In addition, the majority of them are involved with the complex pre-processing task, which is often challenging and time-consuming. Meanwhile, deep networks are end-to-end and have shown promising results in image-based recognition tasks during the last decade. Hence, in this work, some widely used state-of-the-art deep networks are evaluated for COVID-19 recognition with chest X-ray images. All the deep networks are evaluated on a publicly available chest X-ray image dataset. The evaluation results show that the deep networks can effectively recognize COVID-19 from chest X-ray images. Further, the comparison results reveal that the EfficientNetB7 network outperformed other existing state-of-the-art techniques.
* 5 pages
SUES-200: A Multi-height Multi-scene Cross-view Image Benchmark Across Drone and Satellite
Apr 22, 2022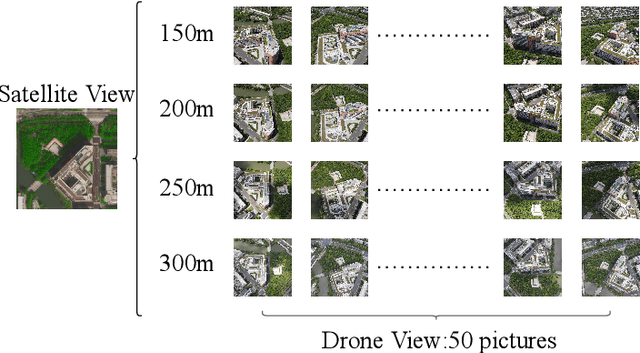
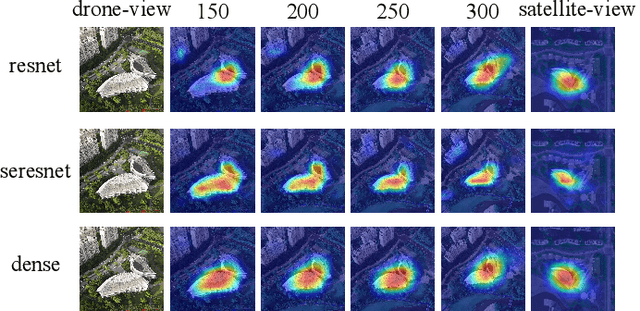
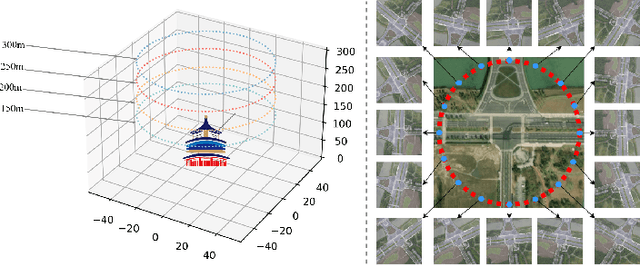
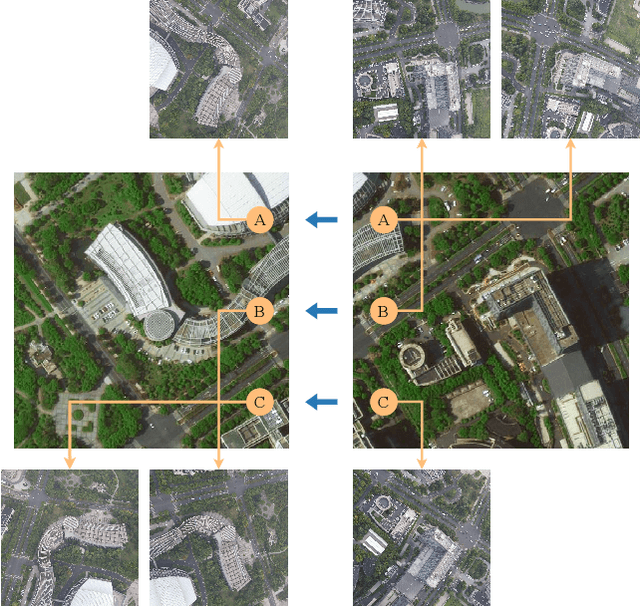
The purpose of cross-view image matching is to match images acquired from the different platforms of the same target scene and then help positioning system to infer the location of the target scene. With the rapid development of drone technology, how to help Drone positioning or navigation through cross-view matching technology has become a challenging research topic. However, the accuracy of current cross-view matching models is still low, mainly because the existing public datasets do not include the differences in images obtained by drones at different heights, and the types of scenes are relatively homogeneous, which makes the models unable to adapt to complex and changing scenes. We propose a new cross-view dataset, SUES-200, to address these issues.SUES-200 contains images acquired by the drone at four flight heights and the corresponding satellite view images under the same target scene. To our knowledge, SUES-200 is the first dataset that considers the differences generated by aerial photography of drones at different flight heights. In addition, we build a pipeline for efficient training testing and evaluation of cross-view matching models. Then, we comprehensively evaluate the performance of feature extractors with different CNN architectures on SUES-200 through an evaluation system for cross-view matching models and propose a robust baseline model. The experimental results show that SUES-200 can help the model learn features with high discrimination at different heights. Evaluating indicators of the matching system improves as the drone flight height gets higher because the drone camera pose and the surrounding environment have less influence on aerial photography.
Multiple Selection Extrapolation for Improved Spatial Error Concealment
Jul 14, 2022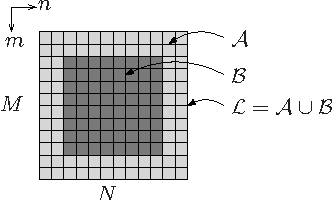
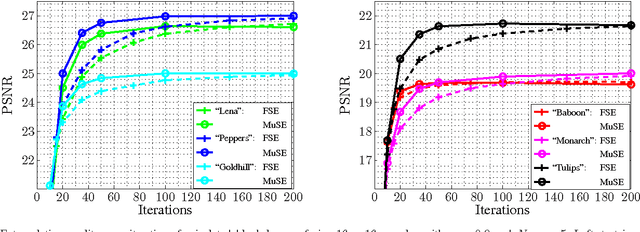
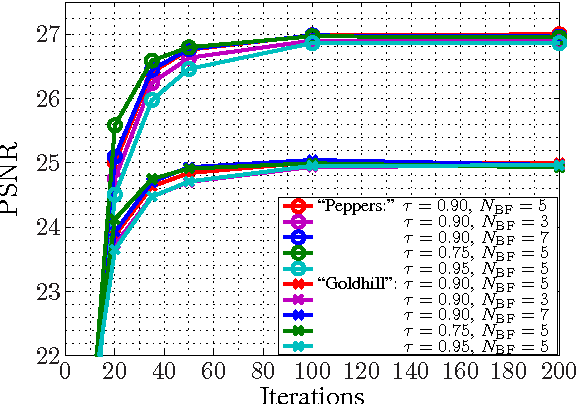

This contribution introduces a novel signal extrapolation algorithm and its application to image error concealment. The signal extrapolation is carried out by iteratively generating a model of the signal suffering from distortion. Thereby, the model results from a weighted superposition of two-dimensional basis functions whereas in every iteration step a set of these is selected and the approximation residual is projected onto the subspace they span. The algorithm is an improvement to the Frequency Selective Extrapolation that has proven to be an effective method for concealing lost or distorted image regions. Compared to this algorithm, the novel algorithm is able to reduce the processing time by a factor larger than three, by still preserving the very high extrapolation quality.
Make It Move: Controllable Image-to-Video Generation with Text Descriptions
Dec 06, 2021
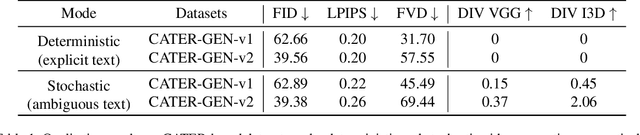
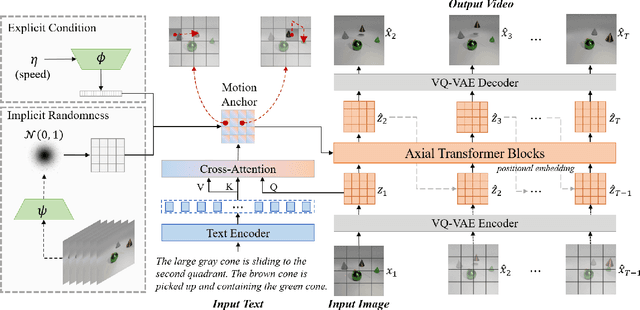
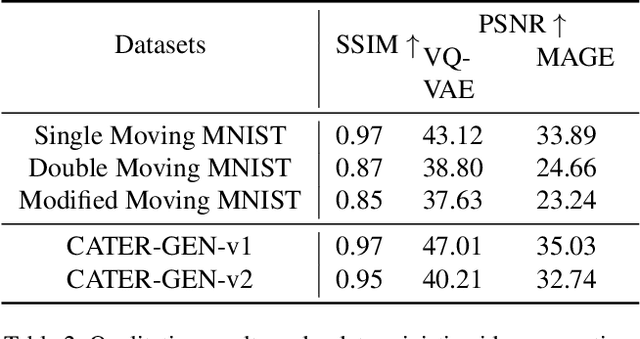
Generating controllable videos conforming to user intentions is an appealing yet challenging topic in computer vision. To enable maneuverable control in line with user intentions, a novel video generation task, named Text-Image-to-Video generation (TI2V), is proposed. With both controllable appearance and motion, TI2V aims at generating videos from a static image and a text description. The key challenges of TI2V task lie both in aligning appearance and motion from different modalities, and in handling uncertainty in text descriptions. To address these challenges, we propose a Motion Anchor-based video GEnerator (MAGE) with an innovative motion anchor (MA) structure to store appearance-motion aligned representation. To model the uncertainty and increase the diversity, it further allows the injection of explicit condition and implicit randomness. Through three-dimensional axial transformers, MA is interacted with given image to generate next frames recursively with satisfying controllability and diversity. Accompanying the new task, we build two new video-text paired datasets based on MNIST and CATER for evaluation. Experiments conducted on these datasets verify the effectiveness of MAGE and show appealing potentials of TI2V task. Source code for model and datasets will be available soon.
Segmentation of Weakly Visible Environmental Microorganism Images Using Pair-wise Deep Learning Features
Aug 31, 2022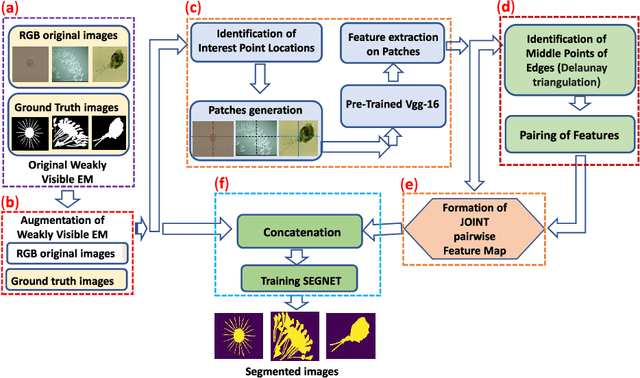



The use of Environmental Microorganisms (EMs) offers a highly efficient, low cost and harmless remedy to environmental pollution, by monitoring and decomposing of pollutants. This relies on how the EMs are correctly segmented and identified. With the aim of enhancing the segmentation of weakly visible EM images which are transparent, noisy and have low contrast, a Pairwise Deep Learning Feature Network (PDLF-Net) is proposed in this study. The use of PDLFs enables the network to focus more on the foreground (EMs) by concatenating the pairwise deep learning features of each image to different blocks of the base model SegNet. Leveraging the Shi and Tomas descriptors, we extract each image's deep features on the patches, which are centered at each descriptor using the VGG-16 model. Then, to learn the intermediate characteristics between the descriptors, pairing of the features is performed based on the Delaunay triangulation theorem to form pairwise deep learning features. In this experiment, the PDLF-Net achieves outstanding segmentation results of 89.24%, 63.20%, 77.27%, 35.15%, 89.72%, 91.44% and 89.30% on the accuracy, IoU, Dice, VOE, sensitivity, precision and specificity, respectively.
Towards Robust Low Light Image Enhancement
May 17, 2022
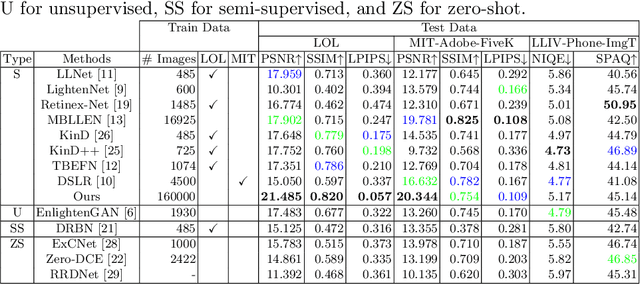

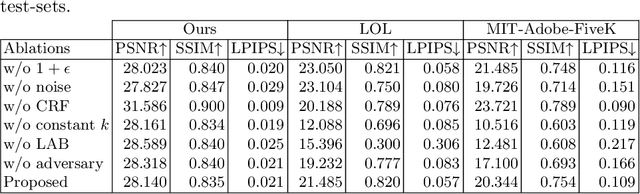
In this paper, we study the problem of making brighter images from dark images found in the wild. The images are dark because they are taken in dim environments. They suffer from color shifts caused by quantization and from sensor noise. We don't know the true camera reponse function for such images and they are not RAW. We use a supervised learning method, relying on a straightforward simulation of an imaging pipeline to generate usable dataset for training and testing. On a number of standard datasets, our approach outperforms the state of the art quantitatively. Qualitative comparisons suggest strong improvements in reconstruction accuracy.
Image Style Transfer and Content-Style Disentanglement
Nov 25, 2021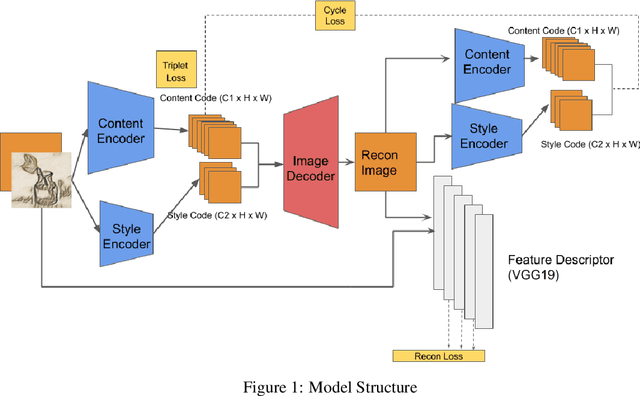
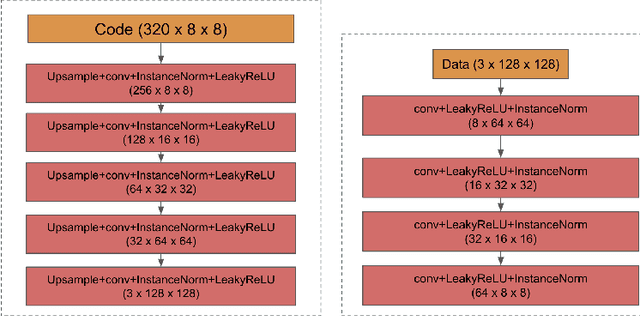

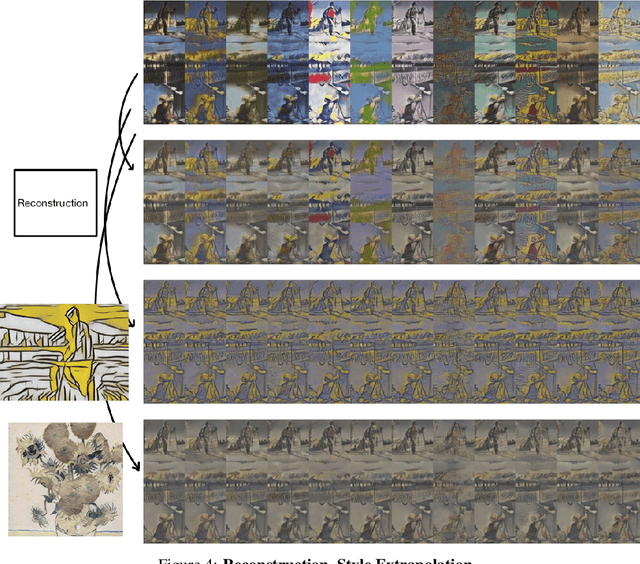
We propose a way of learning disentangled content-style representation of image, allowing us to extrapolate images to any style as well as interpolate between any pair of styles. By augmenting data set in a supervised setting and imposing triplet loss, we ensure the separation of information encoded by content and style representation. We also make use of cycle-consistency loss to guarantee that images could be reconstructed faithfully by their representation.