 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
VTC: Improving Video-Text Retrieval with User Comments
Oct 19, 2022

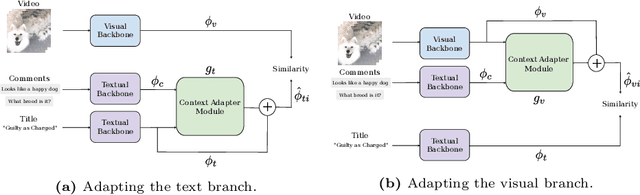
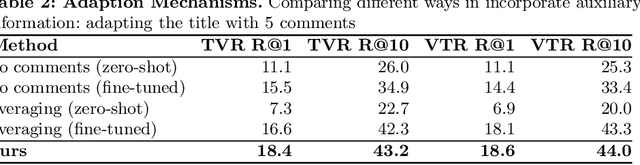
Multi-modal retrieval is an important problem for many applications, such as recommendation and search. Current benchmarks and even datasets are often manually constructed and consist of mostly clean samples where all modalities are well-correlated with the content. Thus, current video-text retrieval literature largely focuses on video titles or audio transcripts, while ignoring user comments, since users often tend to discuss topics only vaguely related to the video. Despite the ubiquity of user comments online, there is currently no multi-modal representation learning datasets that includes comments. In this paper, we a) introduce a new dataset of videos, titles and comments; b) present an attention-based mechanism that allows the model to learn from sometimes irrelevant data such as comments; c) show that by using comments, our method is able to learn better, more contextualised, representations for image, video and audio representations. Project page: https://unitaryai.github.io/vtc-paper.
Image-to-image Translation as a Unique Source of Knowledge
Dec 03, 2021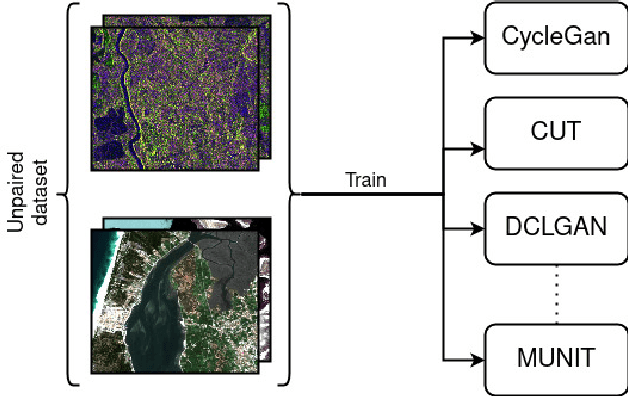
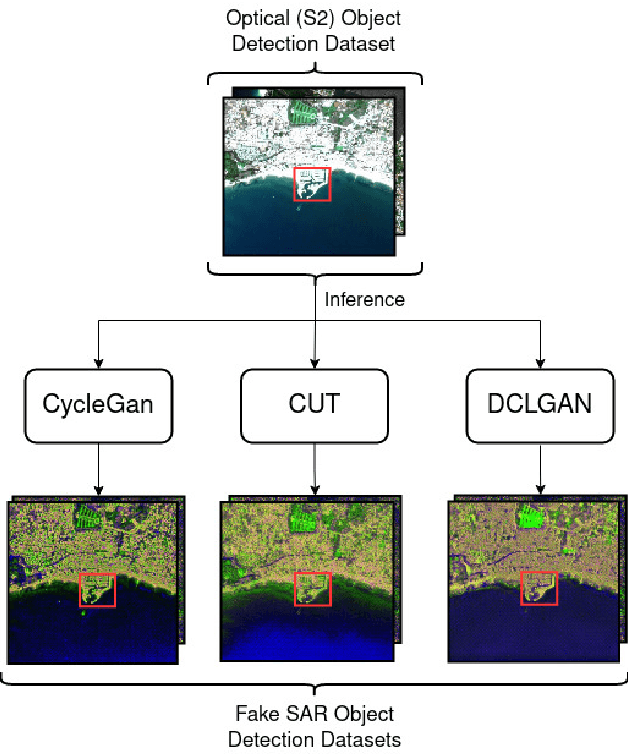
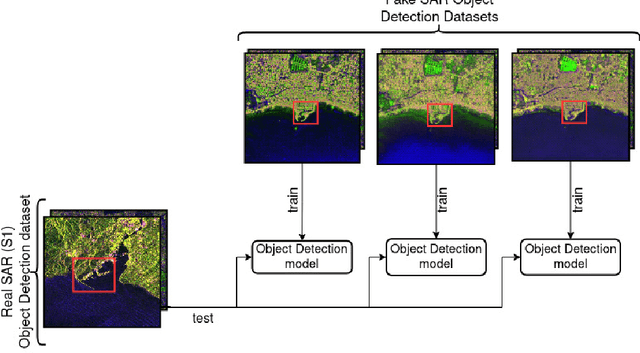
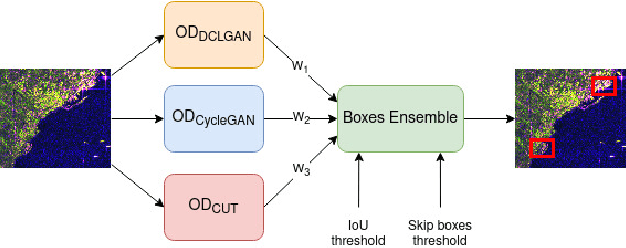
Image-to-image (I2I) translation is an established way of translating data from one domain to another but the usability of the translated images in the target domain when working with such dissimilar domains as the SAR/optical satellite imagery ones and how much of the origin domain is translated to the target domain is still not clear enough. This article address this by performing translations of labelled datasets from the optical domain to the SAR domain with different I2I algorithms from the state-of-the-art, learning from transferred features in the destination domain and evaluating later how much from the original dataset was transferred. Added to this, stacking is proposed as a way of combining the knowledge learned from the different I2I translations and evaluated against single models.
LWA-HAND: Lightweight Attention Hand for Interacting Hand Reconstruction
Aug 27, 2022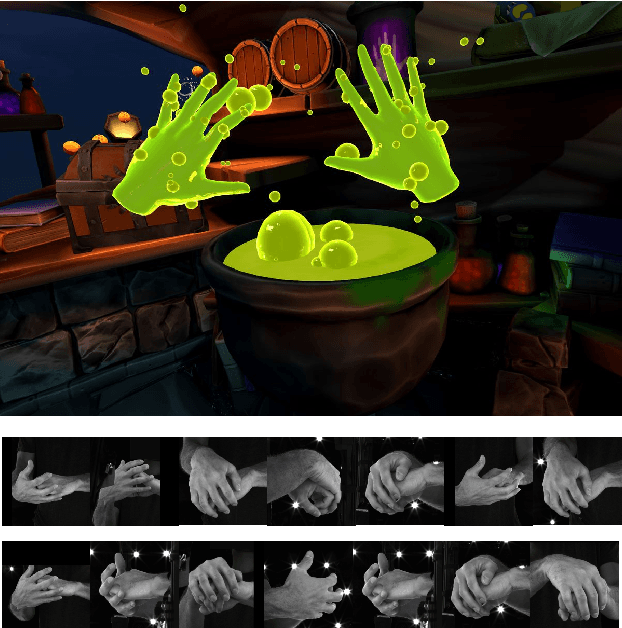

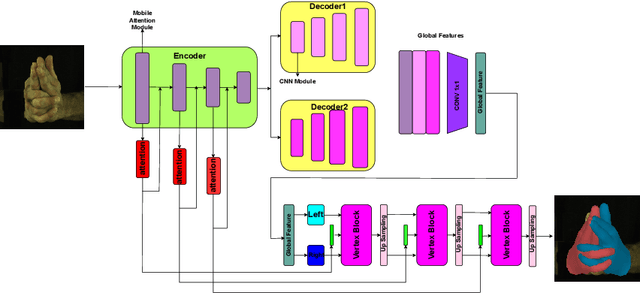

Recent years have witnessed great success for hand reconstruction in real-time applications such as visual reality and augmented reality while interacting with two-hand reconstruction through efficient transformers is left unexplored. In this paper, we propose a method called lightweight attention hand (LWA-HAND) to reconstruct hands in low flops from a single RGB image. To solve the occlusion and interaction problem in efficient attention architectures, we propose three mobile attention modules in this paper. The first module is a lightweight feature attention module that extracts both local occlusion representation and global image patch representation in a coarse-to-fine manner. The second module is a cross image and graph bridge module which fuses image context and hand vertex. The third module is a lightweight cross-attention mechanism that uses element-wise operation for the cross-attention of two hands in linear complexity. The resulting model achieves comparable performance on the InterHand2.6M benchmark in comparison with the state-of-the-art models. Simultaneously, it reduces the flops to $0.47GFlops$ while the state-of-the-art models have heavy computations between $10GFlops$ and $20GFlops$.
Automated Segmentation and Recurrence Risk Prediction of Surgically Resected Lung Tumors with Adaptive Convolutional Neural Networks
Sep 17, 2022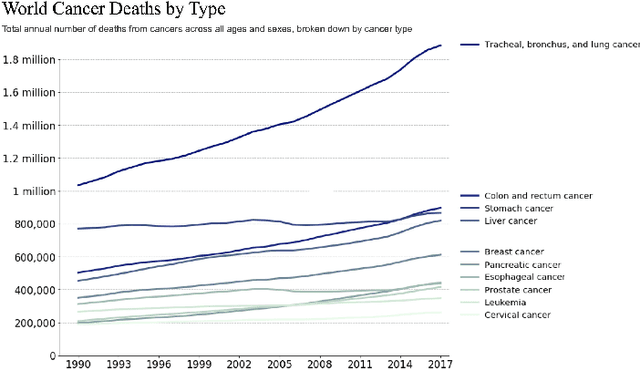

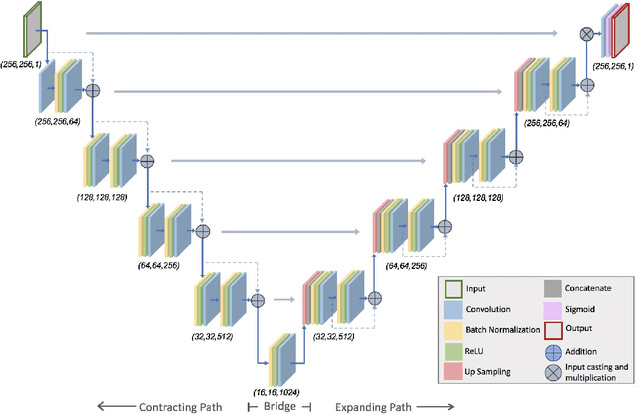

Lung cancer is the leading cause of cancer related mortality by a significant margin. While new technologies, such as image segmentation, have been paramount to improved detection and earlier diagnoses, there are still significant challenges in treating the disease. In particular, despite an increased number of curative resections, many postoperative patients still develop recurrent lesions. Consequently, there is a significant need for prognostic tools that can more accurately predict a patient's risk for recurrence. In this paper, we explore the use of convolutional neural networks (CNNs) for the segmentation and recurrence risk prediction of lung tumors that are present in preoperative computed tomography (CT) images. First, expanding upon recent progress in medical image segmentation, a residual U-Net is used to localize and characterize each nodule. Then, the identified tumors are passed to a second CNN for recurrence risk prediction. The system's final results are produced with a random forest classifier that synthesizes the predictions of the second network with clinical attributes. The segmentation stage uses the LIDC-IDRI dataset and achieves a dice score of 70.3%. The recurrence risk stage uses the NLST dataset from the National Cancer institute and achieves an AUC of 73.0%. Our proposed framework demonstrates that first, automated nodule segmentation methods can generalize to enable pipelines for a wide range of multitask systems and second, that deep learning and image processing have the potential to improve current prognostic tools. To the best of our knowledge, it is the first fully automated segmentation and recurrence risk prediction system.
Comprehensive Dataset of Face Manipulations for Development and Evaluation of Forensic Tools
Aug 24, 2022
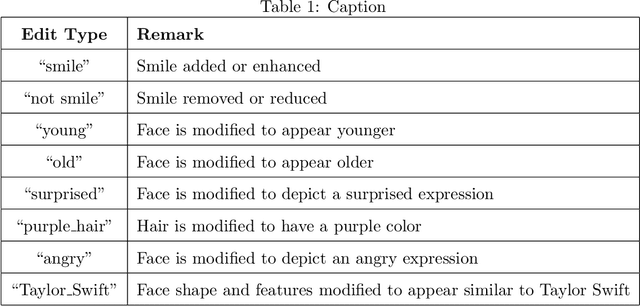


Digital media (e.g., photographs, video) can be easily created, edited, and shared. Tools for editing digital media are capable of doing so while also maintaining a high degree of photo-realism. While many types of edits to digital media are generally benign, others can also be applied for malicious purposes. State-of-the-art face editing tools and software can, for example, artificially make a person appear to be smiling at an inopportune time, or depict authority figures as frail and tired in order to discredit individuals. Given the increasing ease of editing digital media and the potential risks from misuse, a substantial amount of effort has gone into media forensics. To this end, we created a challenge dataset of edited facial images to assist the research community in developing novel approaches to address and classify the authenticity of digital media. Our dataset includes edits applied to controlled, portrait-style frontal face images and full-scene in-the-wild images that may include multiple (i.e., more than one) face per image. The goals of our dataset is to address the following challenge questions: (1) Can we determine the authenticity of a given image (edit detection)? (2) If an image has been edited, can we \textit{localize} the edit region? (3) If an image has been edited, can we deduce (classify) what edit type was performed? The majority of research in image forensics generally attempts to answer item (1), detection. To the best of our knowledge, there are no formal datasets specifically curated to evaluate items (2) and (3), localization and classification, respectively. Our hope is that our prepared evaluation protocol will assist researchers in improving the state-of-the-art in image forensics as they pertain to these challenges.
Distance Map Supervised Landmark Localization for MR-TRUS Registration
Oct 11, 2022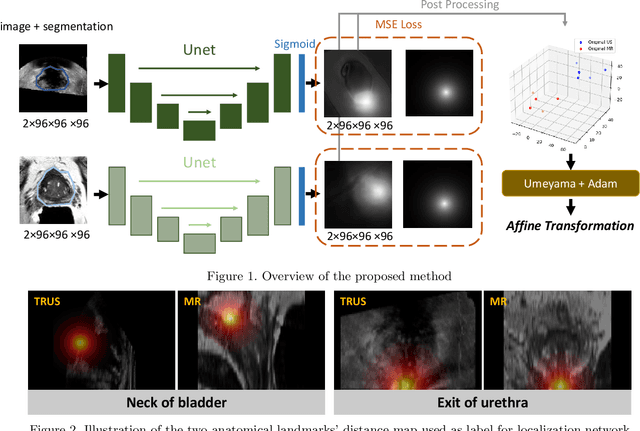
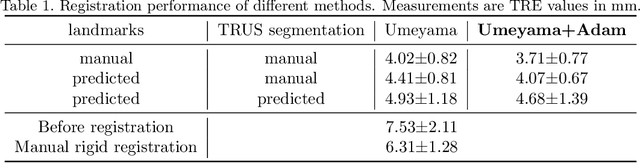

In this work, we propose to explicitly use the landmarks of prostate to guide the MR-TRUS image registration. We first train a deep neural network to automatically localize a set of meaningful landmarks, and then directly generate the affine registration matrix from the location of these landmarks. For landmark localization, instead of directly training a network to predict the landmark coordinates, we propose to regress a full-resolution distance map of the landmark, which is demonstrated effective in avoiding statistical bias to unsatisfactory performance and thus improving performance. We then use the predicted landmarks to generate the affine transformation matrix, which outperforms the clinicians' manual rigid registration by a significant margin in terms of TRE.
Open-source High-precision Autonomous Suturing Framework With Visual Guidance
Oct 04, 2022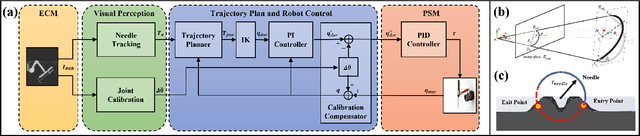
Autonomous surgery has attracted increasing attention for revolutionizing robotic patient care, yet remains a distant and challenging goal. In this paper, we propose an image-based framework for high-precision autonomous suturing operation. We first build an algebraic geometric algorithm to achieve accurate needle pose estimation, then design the corresponding keypoint-based calibration network for joint-offset compensation, and further plan and control suture trajectory. Our solution ranked first among all competitors in the AccelNet Surgical Robotics Challenge. The source code is opened here to accelerate future autonomous surgery research.
Image Data collection and implementation of deep learning-based model in detecting Monkeypox disease using modified VGG16
Jun 04, 2022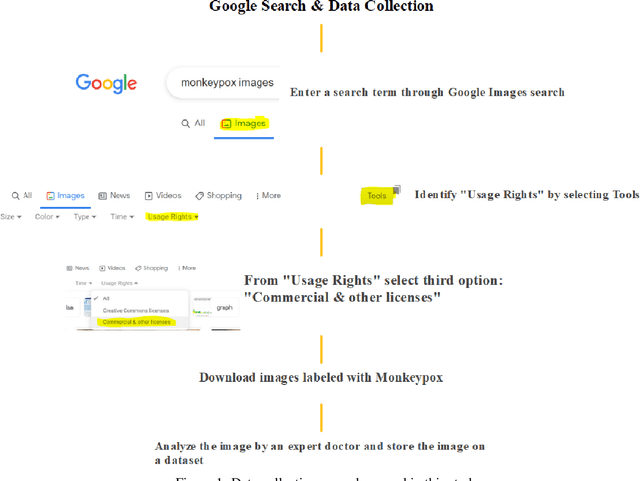
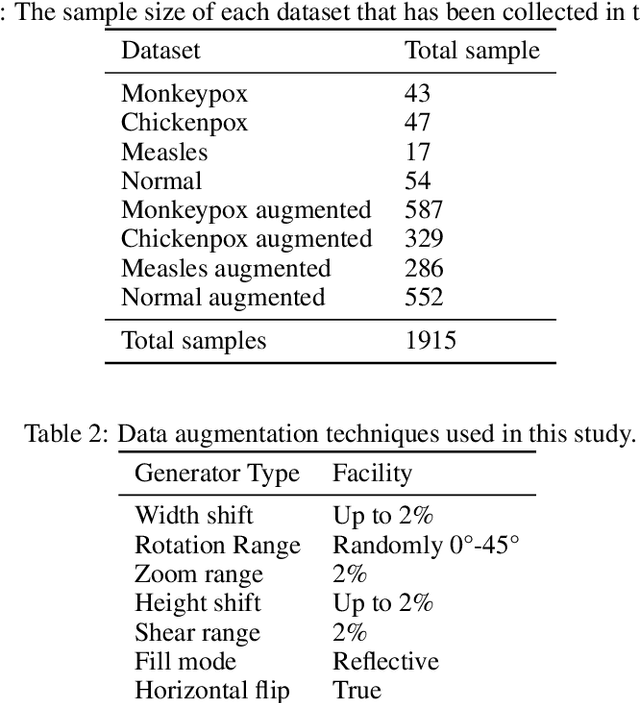
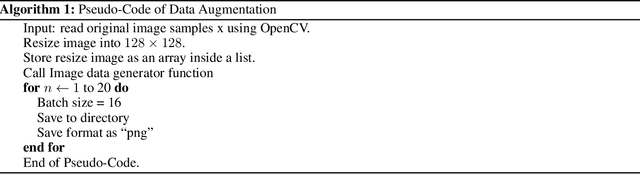
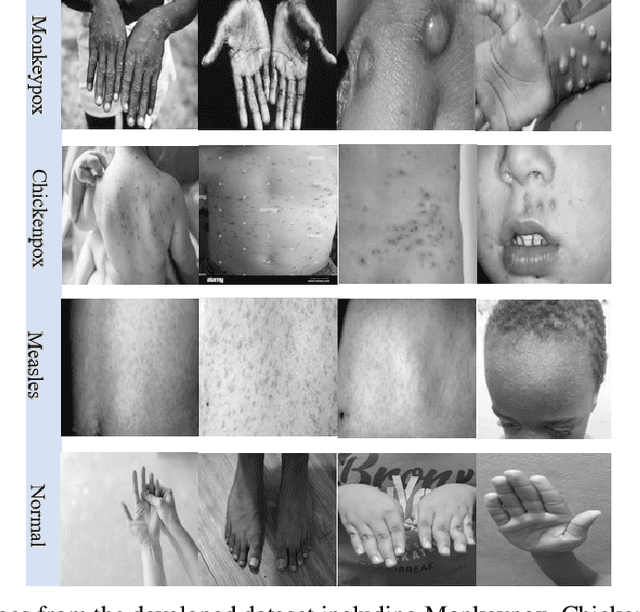
While the world is still attempting to recover from the damage caused by the broad spread of COVID-19, the Monkeypox virus poses a new threat of becoming a global pandemic. Although the Monkeypox virus itself is not deadly and contagious as COVID-19, still every day, new patients case has been reported from many nations. Therefore, it will be no surprise if the world ever faces another global pandemic due to the lack of proper precautious steps. Recently, Machine learning (ML) has demonstrated huge potential in image-based diagnoses such as cancer detection, tumor cell identification, and COVID-19 patient detection. Therefore, a similar application can be adopted to diagnose the Monkeypox-related disease as it infected the human skin, which image can be acquired and further used in diagnosing the disease. Considering this opportunity, in this work, we introduce a newly developed "Monkeypox2022" dataset that is publicly available to use and can be obtained from our shared GitHub repository. The dataset is created by collecting images from multiple open-source and online portals that do not impose any restrictions on use, even for commercial purposes, hence giving a safer path to use and disseminate such data when constructing and deploying any type of ML model. Further, we propose and evaluate a modified VGG16 model, which includes two distinct studies: Study One and Two. Our exploratory computational results indicate that our suggested model can identify Monkeypox patients with an accuracy of $97\pm1.8\%$ (AUC=97.2) and $88\pm0.8\%$ (AUC=0.867) for Study One and Two, respectively. Additionally, we explain our model's prediction and feature extraction utilizing Local Interpretable Model-Agnostic Explanations (LIME) help to a deeper insight into specific features that characterize the onset of the Monkeypox virus.
OptGAN: Optimizing and Interpreting the Latent Space of the Conditional Text-to-Image GANs
Feb 25, 2022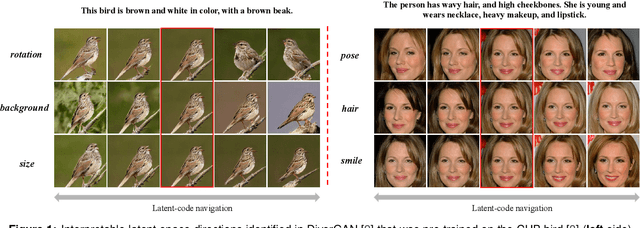

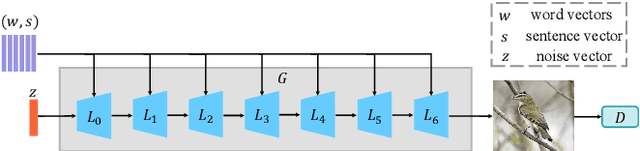
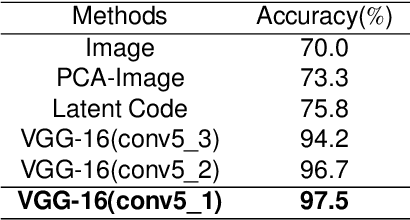
Text-to-image generation intends to automatically produce a photo-realistic image, conditioned on a textual description. It can be potentially employed in the field of art creation, data augmentation, photo-editing, etc. Although many efforts have been dedicated to this task, it remains particularly challenging to generate believable, natural scenes. To facilitate the real-world applications of text-to-image synthesis, we focus on studying the following three issues: 1) How to ensure that generated samples are believable, realistic or natural? 2) How to exploit the latent space of the generator to edit a synthesized image? 3) How to improve the explainability of a text-to-image generation framework? In this work, we constructed two novel data sets (i.e., the Good & Bad bird and face data sets) consisting of successful as well as unsuccessful generated samples, according to strict criteria. To effectively and efficiently acquire high-quality images by increasing the probability of generating Good latent codes, we use a dedicated Good/Bad classifier for generated images. It is based on a pre-trained front end and fine-tuned on the basis of the proposed Good & Bad data set. After that, we present a novel algorithm which identifies semantically-understandable directions in the latent space of a conditional text-to-image GAN architecture by performing independent component analysis on the pre-trained weight values of the generator. Furthermore, we develop a background-flattening loss (BFL), to improve the background appearance in the edited image. Subsequently, we introduce linear interpolation analysis between pairs of keywords. This is extended into a similar triangular `linguistic' interpolation in order to take a deep look into what a text-to-image synthesis model has learned within the linguistic embeddings. Our data set is available at https://zenodo.org/record/6283798#.YhkN_ujMI2w.
Low-resource Neural Machine Translation with Cross-modal Alignment
Oct 13, 2022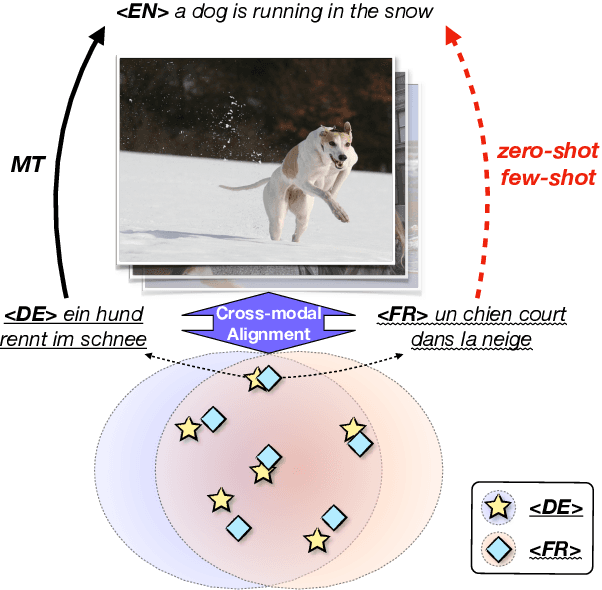
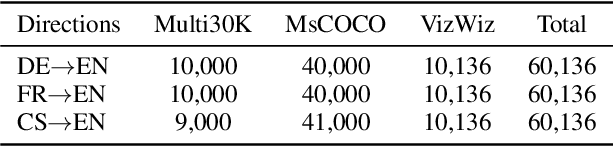
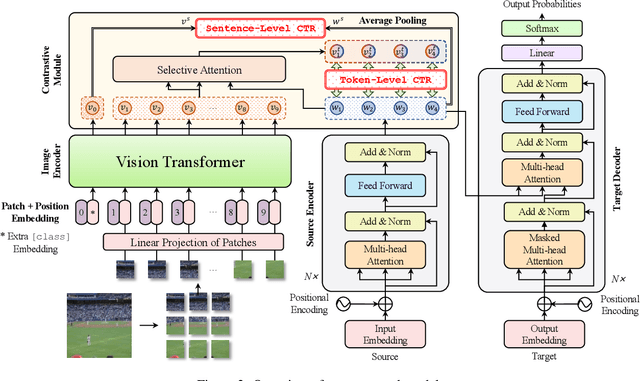
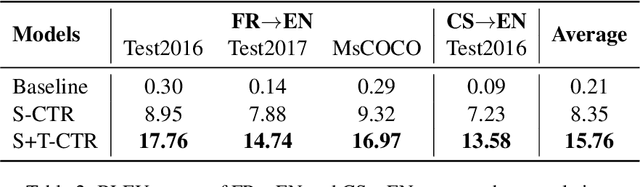
How to achieve neural machine translation with limited parallel data? Existing techniques often rely on large-scale monolingual corpora, which is impractical for some low-resource languages. In this paper, we turn to connect several low-resource languages to a particular high-resource one by additional visual modality. Specifically, we propose a cross-modal contrastive learning method to learn a shared space for all languages, where both a coarse-grained sentence-level objective and a fine-grained token-level one are introduced. Experimental results and further analysis show that our method can effectively learn the cross-modal and cross-lingual alignment with a small amount of image-text pairs and achieves significant improvements over the text-only baseline under both zero-shot and few-shot scenarios.