 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ExpansionNet v2: Block Static Expansion in fast end to end training for Image Captioning
Aug 19, 2022
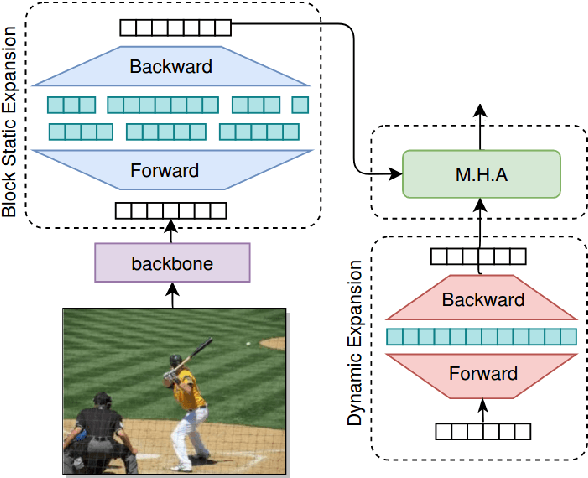
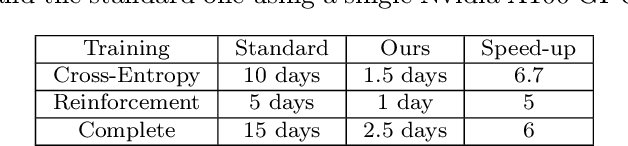
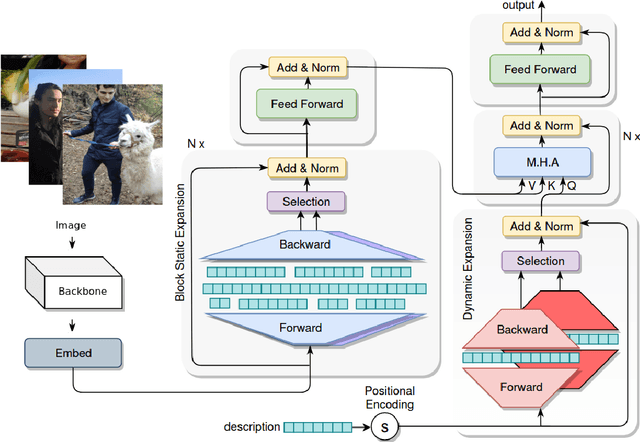
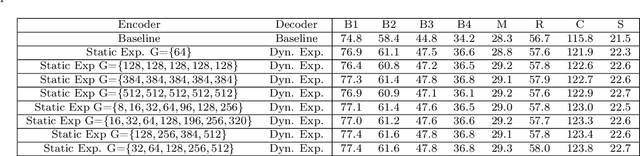
Expansion methods explore the possibility of performance bottlenecks in the input length in Deep Learning methods. In this work, we introduce the Block Static Expansion which distributes and processes the input over a heterogeneous and arbitrarily big collection of sequences characterized by a different length compared to the input one. Adopting this method we introduce a model called ExpansionNet v2, which is trained using our novel training strategy, designed to be not only effective but also 6 times faster compared to the standard approach of recent works in Image Captioning. The model achieves the state of art performance over the MS-COCO 2014 captioning challenge with a score of 143.7 CIDEr-D in the offline test split, 140.8 CIDEr-D in the online evaluation server and 72.9 All-CIDEr on the nocaps validation set. Source code available at: https://github.com/jchenghu/ExpansionNet_v2
R2FD2: Fast and Robust Matching of Multimodal Remote Sensing Image via Repeatable Feature Detector and Rotation-invariant Feature Descriptor
Dec 06, 2022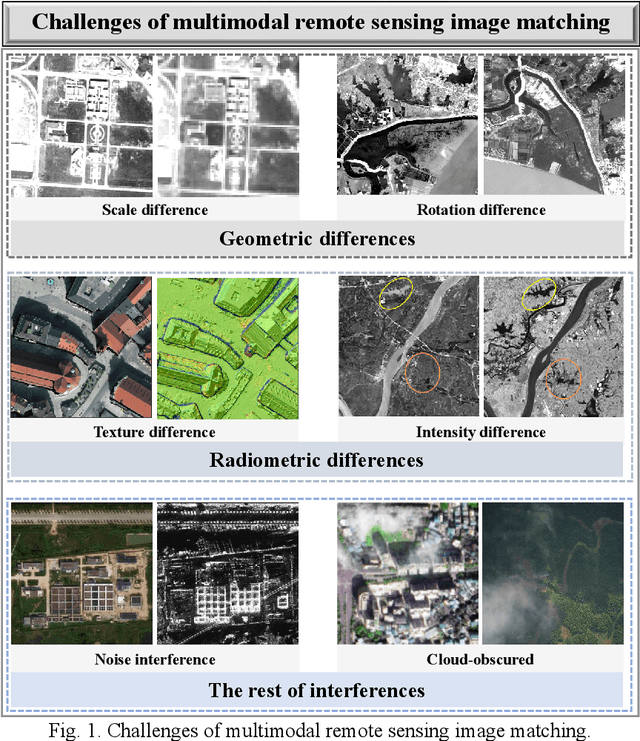

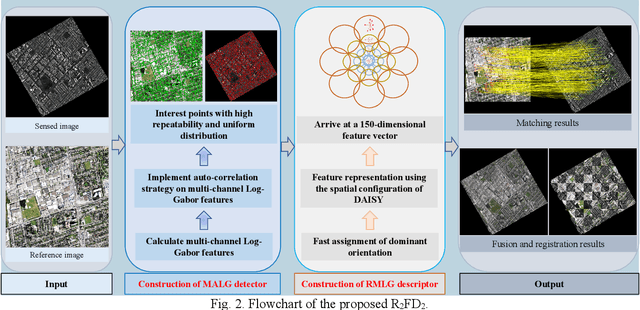
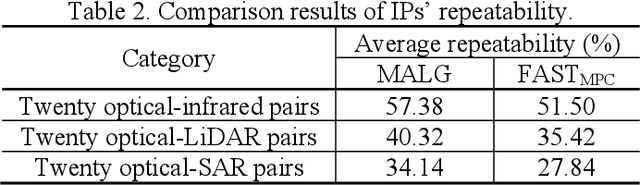
Automatically identifying feature correspondences between multimodal images is facing enormous challenges because of the significant differences both in radiation and geometry. To address these problems, we propose a novel feature matching method (named R2FD2) that is robust to radiation and rotation differences. Our R2FD2 is conducted in two critical contributions, consisting of a repeatable feature detector and a rotation-invariant feature descriptor. In the first stage, a repeatable feature detector called the Multi-channel Auto-correlation of the Log-Gabor (MALG) is presented for feature detection, which combines the multi-channel auto-correlation strategy with the Log-Gabor wavelets to detect interest points (IPs) with high repeatability and uniform distribution. In the second stage, a rotation-invariant feature descriptor is constructed, named the Rotation-invariant Maximum index map of the Log-Gabor (RMLG), which consists of two components: fast assignment of dominant orientation and construction of feature representation. In the process of fast assignment of dominant orientation, a Rotation-invariant Maximum Index Map (RMIM) is built to address rotation deformations. Then, the proposed RMLG incorporates the rotation-invariant RMIM with the spatial configuration of DAISY to depict a more discriminative feature representation, which improves RMLG's resistance to radiation and rotation variances.Experimental results show that the proposed R2FD2 outperforms five state-of-the-art feature matching methods, and has superior advantages in adaptability and universality. Moreover, our R2FD2 achieves the accuracy of matching within two pixels and has a great advantage in matching efficiency over other state-of-the-art methods.
FRA-RIR: Fast Random Approximation of the Image-source Method
Aug 08, 2022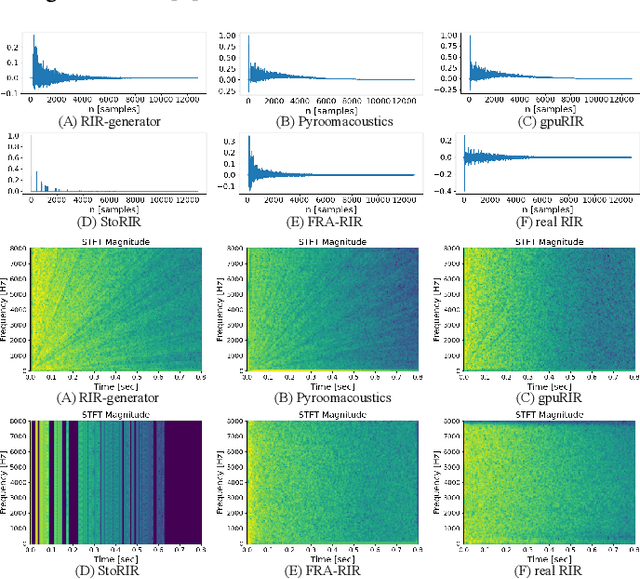
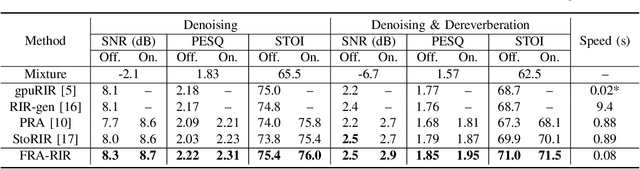
The training of modern speech processing systems often requires a large amount of simulated room impulse response (RIR) data in order to allow the systems to generalize well in real-world, reverberant environments. However, simulating realistic RIR data typically requires accurate physical modeling, and the acceleration of such simulation process typically requires certain computational platforms such as a graphics processing unit (GPU). In this paper, we propose FRA-RIR, a fast random approximation method of the widely-used image-source method (ISM), to efficiently generate realistic RIR data without specific computational devices. FRA-RIR replaces the physical simulation in the standard ISM by a series of random approximations, which significantly speeds up the simulation process and enables its application in on-the-fly data generation pipelines. Experiments show that FRA-RIR can not only be significantly faster than other existing ISM-based RIR simulation tools on standard computational platforms, but also improves the performance of speech denoising systems evaluated on real-world RIR when trained with simulated RIR. A Python implementation of FRA-RIR is available online\footnote{\url{https://github.com/yluo42/FRA-RIR}}.
Self-supervised Learning for Sonar Image Classification
Apr 20, 2022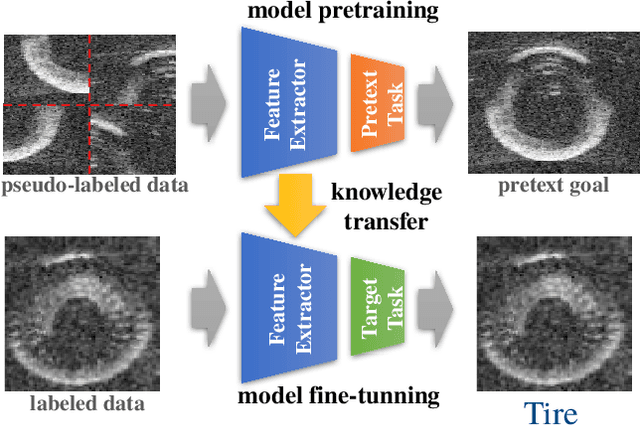
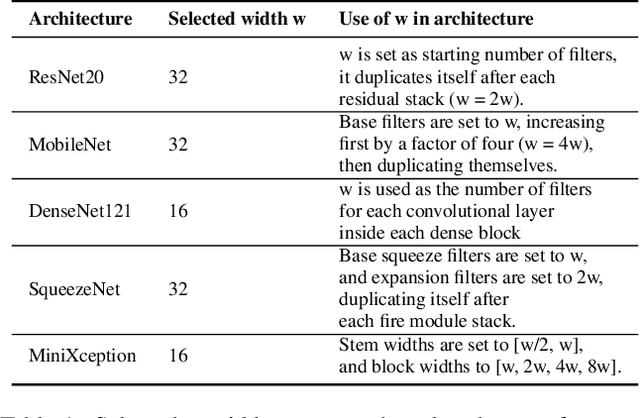

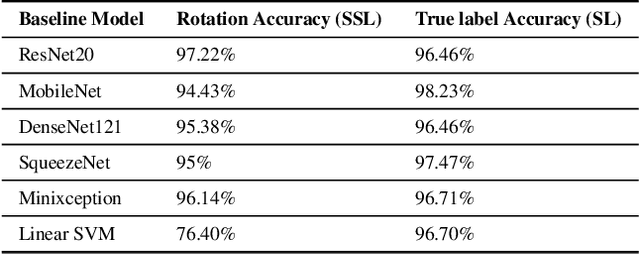
Self-supervised learning has proved to be a powerful approach to learn image representations without the need of large labeled datasets. For underwater robotics, it is of great interest to design computer vision algorithms to improve perception capabilities such as sonar image classification. Due to the confidential nature of sonar imaging and the difficulty to interpret sonar images, it is challenging to create public large labeled sonar datasets to train supervised learning algorithms. In this work, we investigate the potential of three self-supervised learning methods (RotNet, Denoising Autoencoders, and Jigsaw) to learn high-quality sonar image representation without the need of human labels. We present pre-training and transfer learning results on real-life sonar image datasets. Our results indicate that self-supervised pre-training yields classification performance comparable to supervised pre-training in a few-shot transfer learning setup across all three methods. Code and self-supervised pre-trained models are be available at https://github.com/agrija9/ssl-sonar-images
Towards Blind Watermarking: Combining Invertible and Non-invertible Mechanisms
Dec 24, 2022
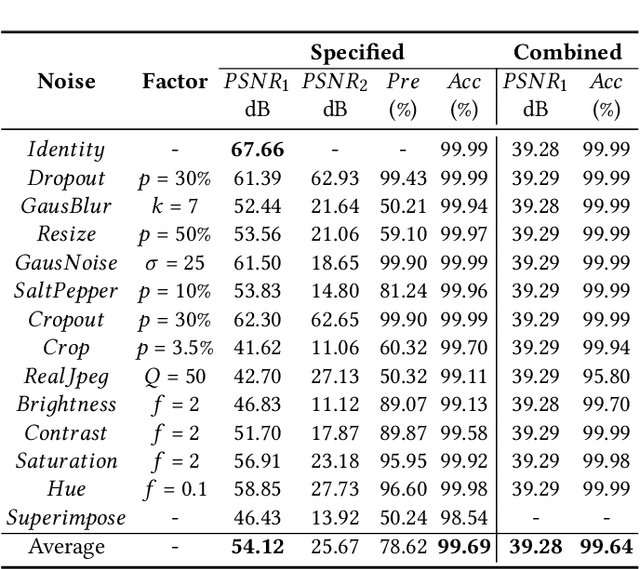
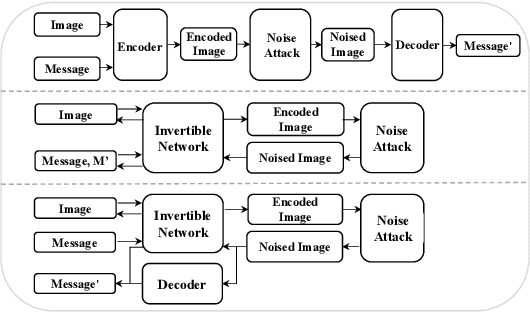
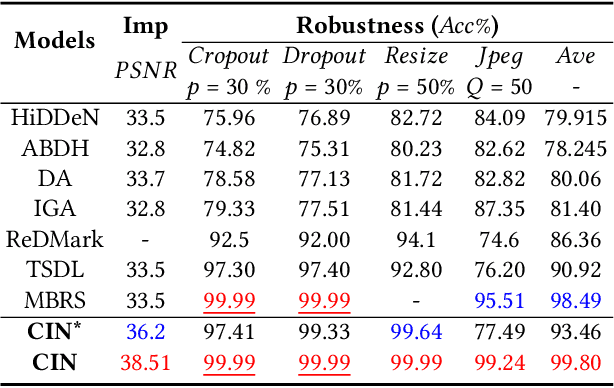
Blind watermarking provides powerful evidence for copyright protection, image authentication, and tampering identification. However, it remains a challenge to design a watermarking model with high imperceptibility and robustness against strong noise attacks. To resolve this issue, we present a framework Combining the Invertible and Non-invertible (CIN) mechanisms. The CIN is composed of the invertible part to achieve high imperceptibility and the non-invertible part to strengthen the robustness against strong noise attacks. For the invertible part, we develop a diffusion and extraction module (DEM) and a fusion and split module (FSM) to embed and extract watermarks symmetrically in an invertible way. For the non-invertible part, we introduce a non-invertible attention-based module (NIAM) and the noise-specific selection module (NSM) to solve the asymmetric extraction under a strong noise attack. Extensive experiments demonstrate that our framework outperforms the current state-of-the-art methods of imperceptibility and robustness significantly. Our framework can achieve an average of 99.99% accuracy and 67.66 dB PSNR under noise-free conditions, while 96.64% and 39.28 dB combined strong noise attacks. The code will be available in https://github.com/rmpku/CIN.
Dynamic Neural Portraits
Nov 25, 2022
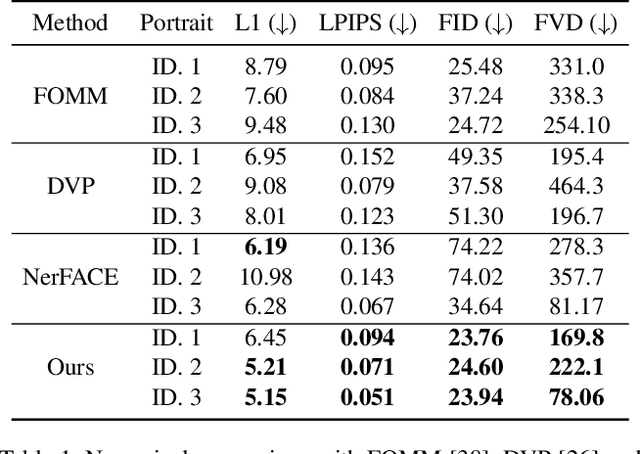
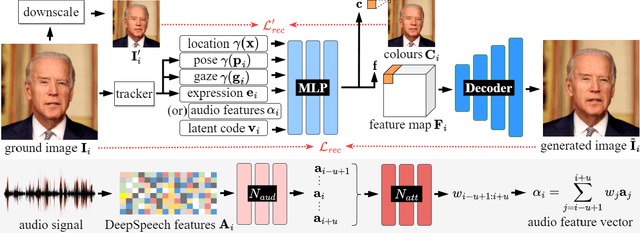
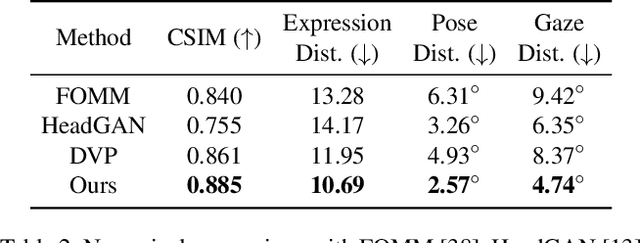
We present Dynamic Neural Portraits, a novel approach to the problem of full-head reenactment. Our method generates photo-realistic video portraits by explicitly controlling head pose, facial expressions and eye gaze. Our proposed architecture is different from existing methods that rely on GAN-based image-to-image translation networks for transforming renderings of 3D faces into photo-realistic images. Instead, we build our system upon a 2D coordinate-based MLP with controllable dynamics. Our intuition to adopt a 2D-based representation, as opposed to recent 3D NeRF-like systems, stems from the fact that video portraits are captured by monocular stationary cameras, therefore, only a single viewpoint of the scene is available. Primarily, we condition our generative model on expression blendshapes, nonetheless, we show that our system can be successfully driven by audio features as well. Our experiments demonstrate that the proposed method is 270 times faster than recent NeRF-based reenactment methods, with our networks achieving speeds of 24 fps for resolutions up to 1024 x 1024, while outperforming prior works in terms of visual quality.
Efficient Feature Extraction for High-resolution Video Frame Interpolation
Nov 25, 2022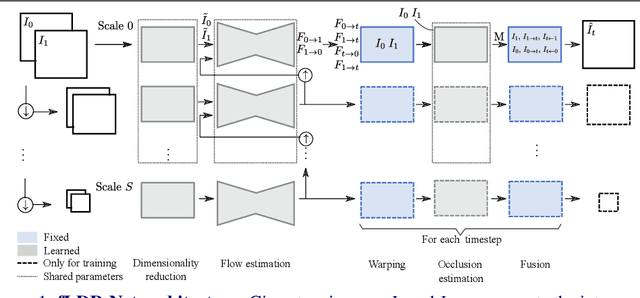
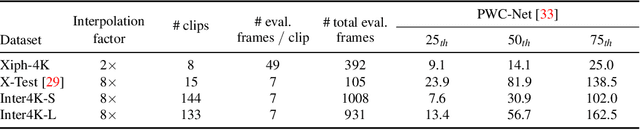
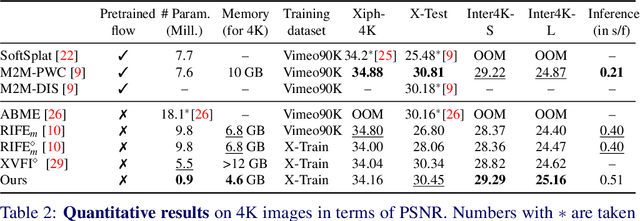
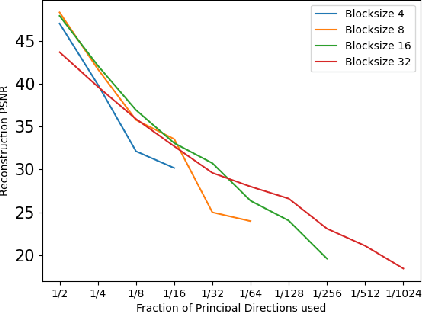
Most deep learning methods for video frame interpolation consist of three main components: feature extraction, motion estimation, and image synthesis. Existing approaches are mainly distinguishable in terms of how these modules are designed. However, when interpolating high-resolution images, e.g. at 4K, the design choices for achieving high accuracy within reasonable memory requirements are limited. The feature extraction layers help to compress the input and extract relevant information for the latter stages, such as motion estimation. However, these layers are often costly in parameters, computation time, and memory. We show how ideas from dimensionality reduction combined with a lightweight optimization can be used to compress the input representation while keeping the extracted information suitable for frame interpolation. Further, we require neither a pretrained flow network nor a synthesis network, additionally reducing the number of trainable parameters and required memory. When evaluating on three 4K benchmarks, we achieve state-of-the-art image quality among the methods without pretrained flow while having the lowest network complexity and memory requirements overall.
TAOTF: A Two-stage Approximately Orthogonal Training Framework in Deep Neural Networks
Nov 25, 2022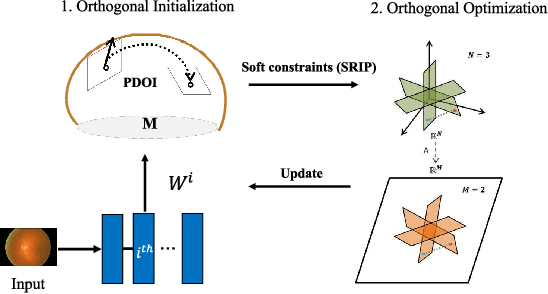
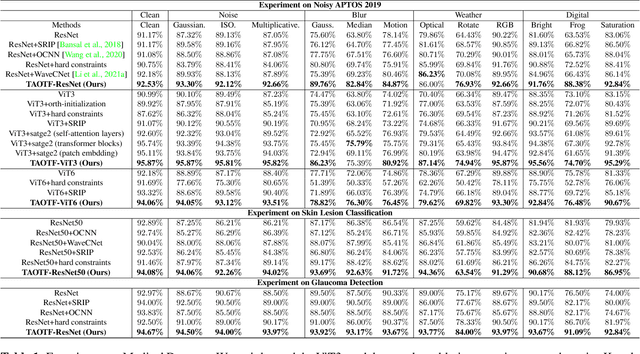
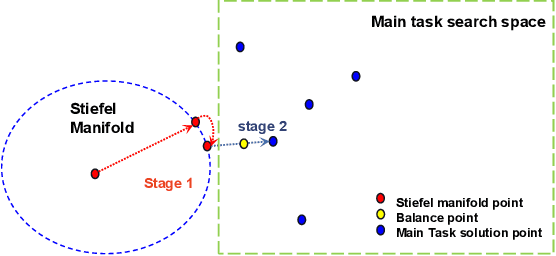
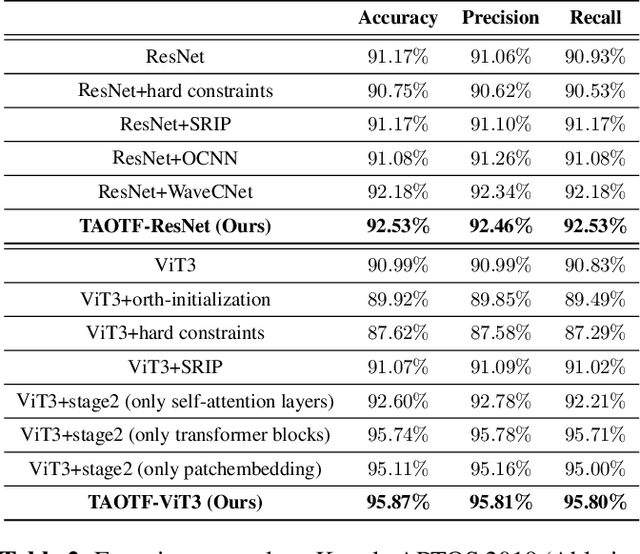
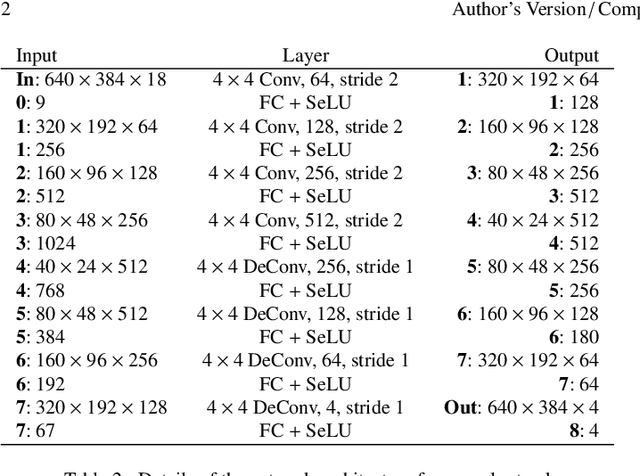
The orthogonality constraints, including the hard and soft ones, have been used to normalize the weight matrices of Deep Neural Network (DNN) models, especially the Convolutional Neural Network (CNN) and Vision Transformer (ViT), to reduce model parameter redundancy and improve training stability. However, the robustness to noisy data of these models with constraints is not always satisfactory. In this work, we propose a novel two-stage approximately orthogonal training framework (TAOTF) to find a trade-off between the orthogonal solution space and the main task solution space to solve this problem in noisy data scenarios. In the first stage, we propose a novel algorithm called polar decomposition-based orthogonal initialization (PDOI) to find a good initialization for the orthogonal optimization. In the second stage, unlike other existing methods, we apply soft orthogonal constraints for all layers of DNN model. We evaluate the proposed model-agnostic framework both on the natural image and medical image datasets, which show that our method achieves stable and superior performances to existing methods.
Deep scene-scale material estimation from multi-view indoor captures
Nov 15, 2022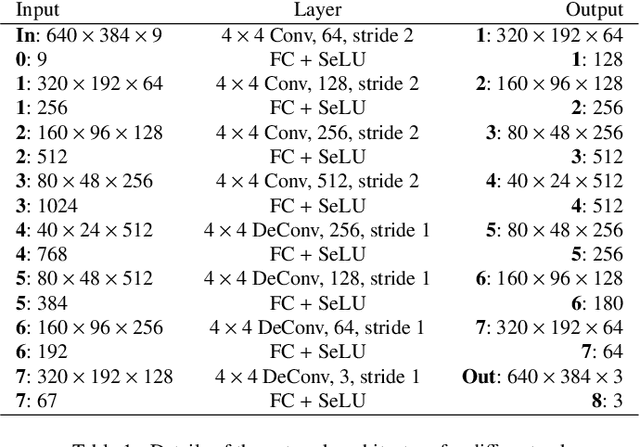

The movie and video game industries have adopted photogrammetry as a way to create digital 3D assets from multiple photographs of a real-world scene. But photogrammetry algorithms typically output an RGB texture atlas of the scene that only serves as visual guidance for skilled artists to create material maps suitable for physically-based rendering. We present a learning-based approach that automatically produces digital assets ready for physically-based rendering, by estimating approximate material maps from multi-view captures of indoor scenes that are used with retopologized geometry. We base our approach on a material estimation Convolutional Neural Network (CNN) that we execute on each input image. We leverage the view-dependent visual cues provided by the multiple observations of the scene by gathering, for each pixel of a given image, the color of the corresponding point in other images. This image-space CNN provides us with an ensemble of predictions, which we merge in texture space as the last step of our approach. Our results demonstrate that the recovered assets can be directly used for physically-based rendering and editing of real indoor scenes from any viewpoint and novel lighting. Our method generates approximate material maps in a fraction of time compared to the closest previous solutions.
* 17 pages
Scalar Invariant Networks with Zero Bias
Nov 15, 2022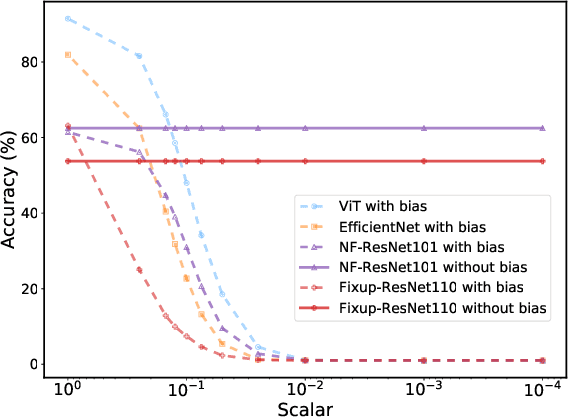
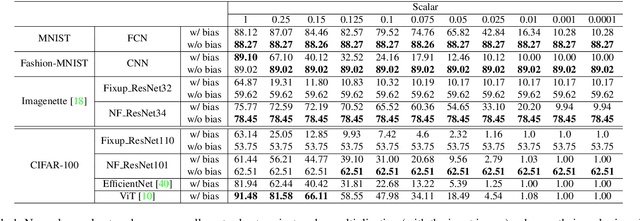
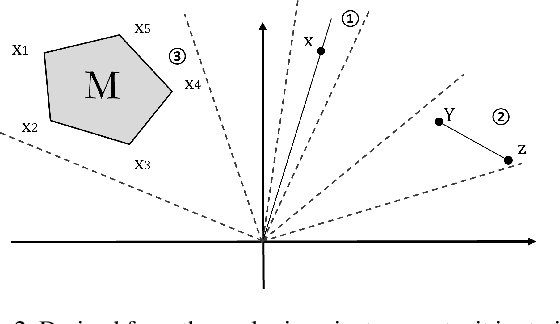
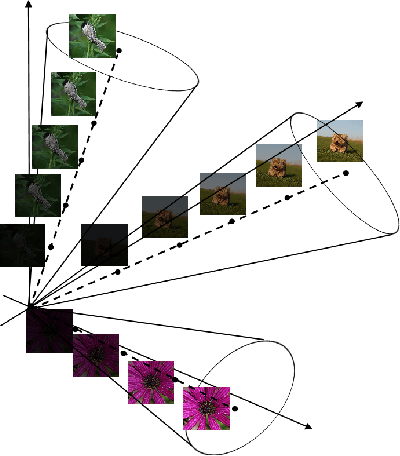
Just like weights, bias terms are the learnable parameters of many popular machine learning models, including neural networks. Biases are believed to effectively increase the representational power of neural networks to solve a wide range of tasks in computer vision. However, we argue that if we consider the intrinsic distribution of images in the input space as well as some desired properties a model should have from the first principles, biases can be completely ignored in addressing many image-related tasks, such as image classification. Our observation indicates that zero-bias neural networks could perform comparably to neural networks with bias at least on practical image classification tasks. In addition, we prove that zero-bias neural networks possess a nice property called scalar (multiplication) invariance, which has great potential in learning and understanding images captured under poor illumination conditions. We then extend scalar invariance to more general cases that allow us to verify certain convex regions of the input space. Our experimental results show that zero-bias models could outperform the state-of-art models by a very large margin (over 60%) when predicting images under a low illumination condition (multiplying a scalar of 0.01); while achieving the same-level performance as normal models.