 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sauron U-Net: Simple automated redundancy elimination in medical image segmentation via filter pruning
Sep 27, 2022
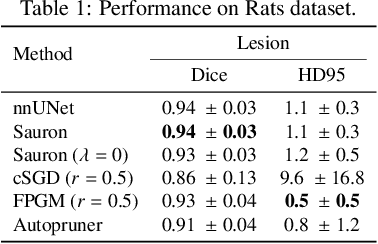
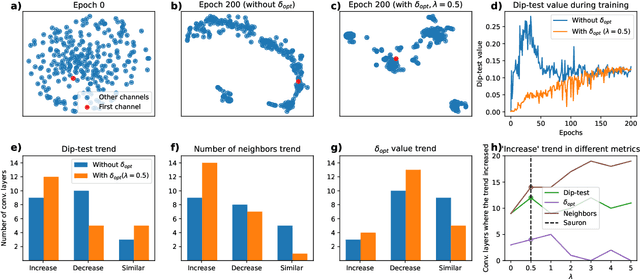
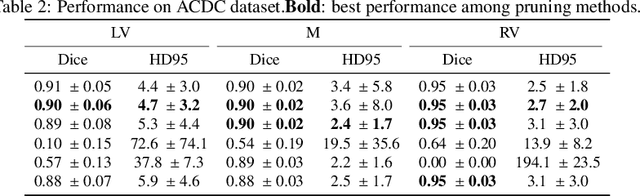
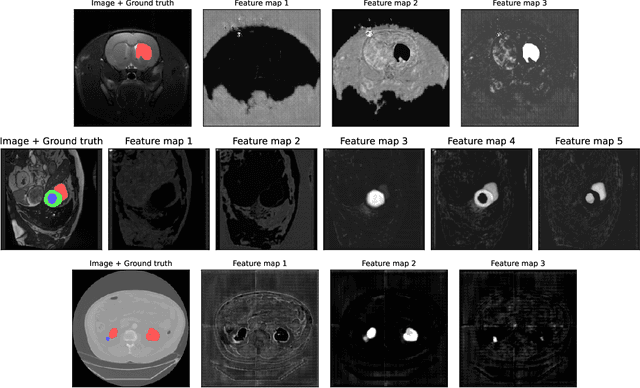
We present Sauron, a filter pruning method that eliminates redundant feature maps by discarding the corresponding filters with automatically-adjusted layer-specific thresholds. Furthermore, Sauron minimizes a regularization term that, as we show with various metrics, promotes the formation of feature maps clusters. In contrast to most filter pruning methods, Sauron is single-phase, similarly to typical neural network optimization, requiring fewer hyperparameters and design decisions. Additionally, unlike other cluster-based approaches, our method does not require pre-selecting the number of clusters, which is non-trivial to determine and varies across layers. We evaluated Sauron and three state-of-the-art filter pruning methods on three medical image segmentation tasks. This is an area where filter pruning has received little attention and where it can help building efficient models for medical grade computers that cannot use cloud services due to privacy considerations. Sauron achieved models with higher performance and pruning rate than the competing pruning methods. Additionally, since Sauron removes filters during training, its optimization accelerated over time. Finally, we show that the feature maps of a Sauron-pruned model were highly interpretable. The Sauron code is publicly available at https://github.com/jmlipman/SauronUNet.
ODIM: an efficient method to detect outliers via inlier-memorization effect of deep generative models
Jan 11, 2023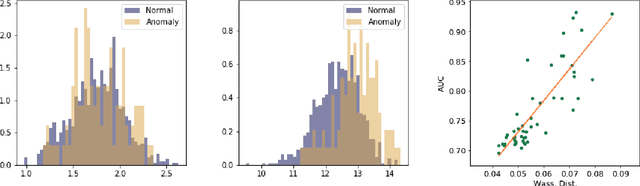
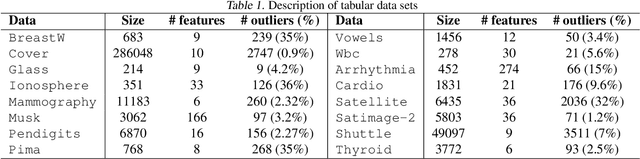
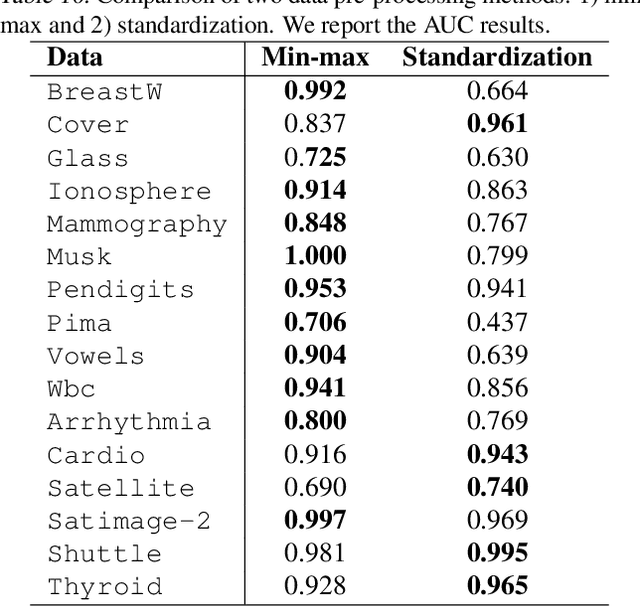
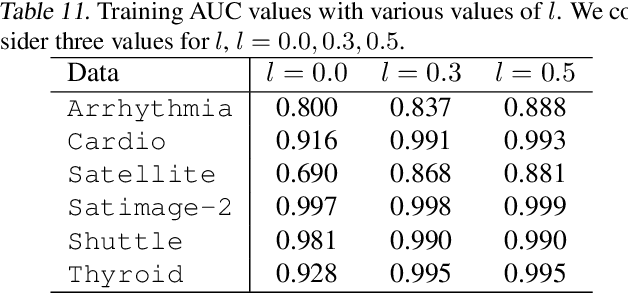
Identifying whether a given sample is an outlier or not is an important issue in various real-world domains. This study aims to solve the unsupervised outlier detection problem where training data contain outliers, but any label information about inliers and outliers is not given. We propose a powerful and efficient learning framework to identify outliers in a training data set using deep neural networks. We start with a new observation called the inlier-memorization (IM) effect. When we train a deep generative model with data contaminated with outliers, the model first memorizes inliers before outliers. Exploiting this finding, we develop a new method called the outlier detection via the IM effect (ODIM). The ODIM only requires a few updates; thus, it is computationally efficient, tens of times faster than other deep-learning-based algorithms. Also, the ODIM filters out outliers successfully, regardless of the types of data, such as tabular, image, and sequential. We empirically demonstrate the superiority and efficiency of the ODIM by analyzing 20 data sets.
MyI-Net: Fully Automatic Detection and Quantification of Myocardial Infarction from Cardiovascular MRI Images
Dec 28, 2022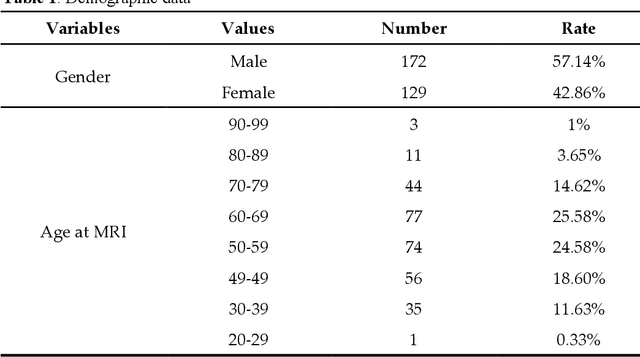
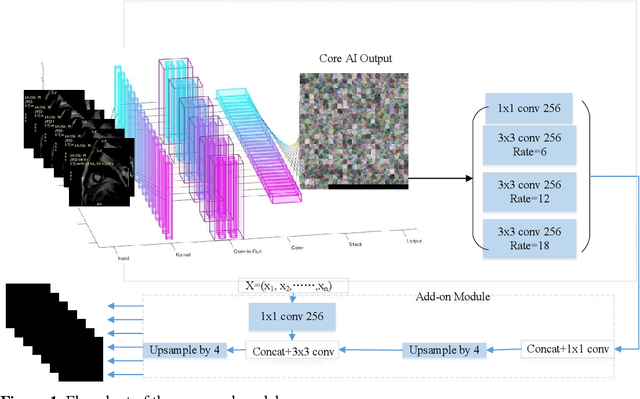

A "heart attack" or myocardial infarction (MI), occurs when an artery supplying blood to the heart is abruptly occluded. The "gold standard" method for imaging MI is Cardiovascular Magnetic Resonance Imaging (MRI), with intravenously administered gadolinium-based contrast (late gadolinium enhancement). However, no "gold standard" fully automated method for the quantification of MI exists. In this work, we propose an end-to-end fully automatic system (MyI-Net) for the detection and quantification of MI in MRI images. This has the potential to reduce the uncertainty due to the technical variability across labs and inherent problems of the data and labels. Our system consists of four processing stages designed to maintain the flow of information across scales. First, features from raw MRI images are generated using feature extractors built on ResNet and MoblieNet architectures. This is followed by the Atrous Spatial Pyramid Pooling (ASPP) to produce spatial information at different scales to preserve more image context. High-level features from ASPP and initial low-level features are concatenated at the third stage and then passed to the fourth stage where spatial information is recovered via up-sampling to produce final image segmentation output into: i) background, ii) heart muscle, iii) blood and iv) scar areas. New models were compared with state-of-art models and manual quantification. Our models showed favorable performance in global segmentation and scar tissue detection relative to state-of-the-art work, including a four-fold better performance in matching scar pixels to contours produced by clinicians.
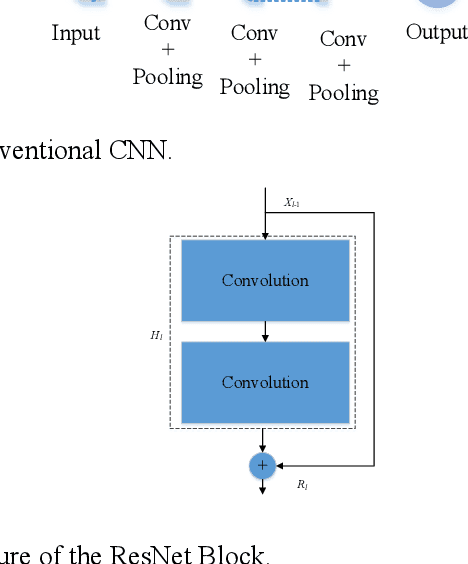
A Comprehensive Survey of Transformers for Computer Vision
Nov 11, 2022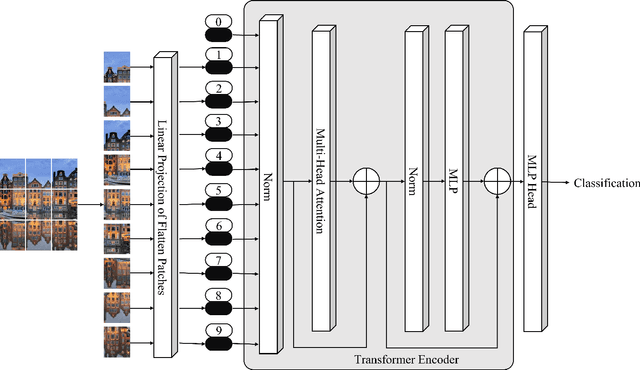
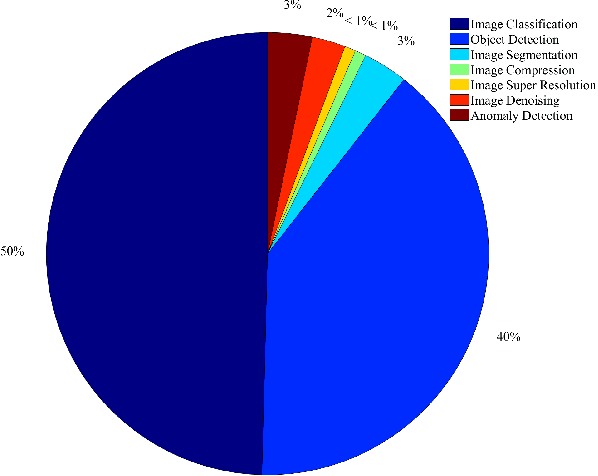
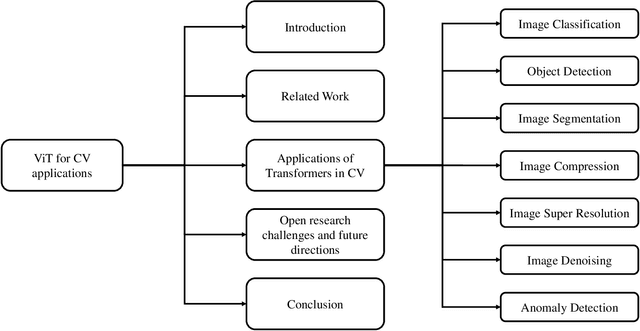
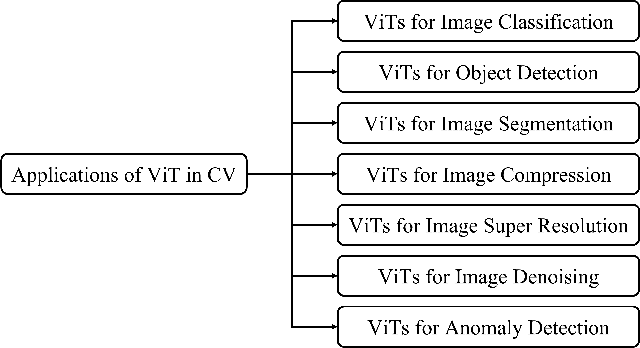
As a special type of transformer, Vision Transformers (ViTs) are used to various computer vision applications (CV), such as image recognition. There are several potential problems with convolutional neural networks (CNNs) that can be solved with ViTs. For image coding tasks like compression, super-resolution, segmentation, and denoising, different variants of the ViTs are used. The purpose of this survey is to present the first application of ViTs in CV. The survey is the first of its kind on ViTs for CVs to the best of our knowledge. In the first step, we classify different CV applications where ViTs are applicable. CV applications include image classification, object detection, image segmentation, image compression, image super-resolution, image denoising, and anomaly detection. Our next step is to review the state-of-the-art in each category and list the available models. Following that, we present a detailed analysis and comparison of each model and list its pros and cons. After that, we present our insights and lessons learned for each category. Moreover, we discuss several open research challenges and future research directions.
Multi-Label Chest X-Ray Classification via Deep Learning
Nov 27, 2022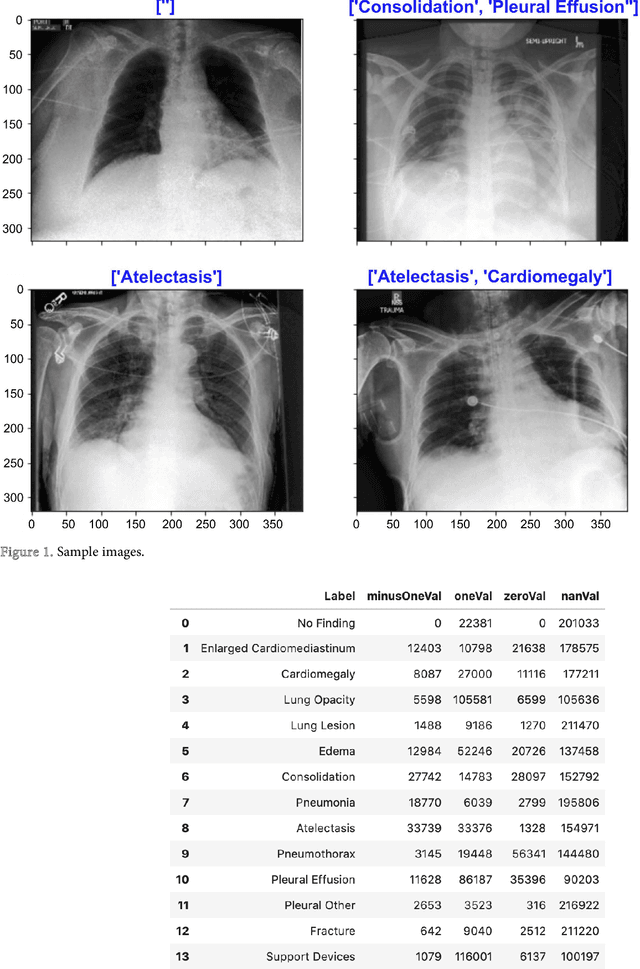
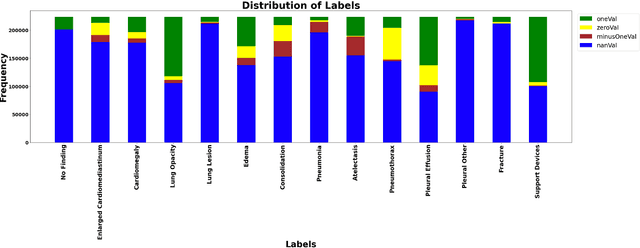
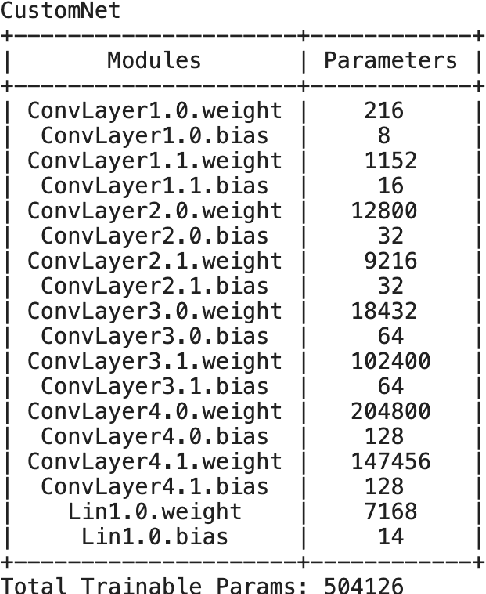
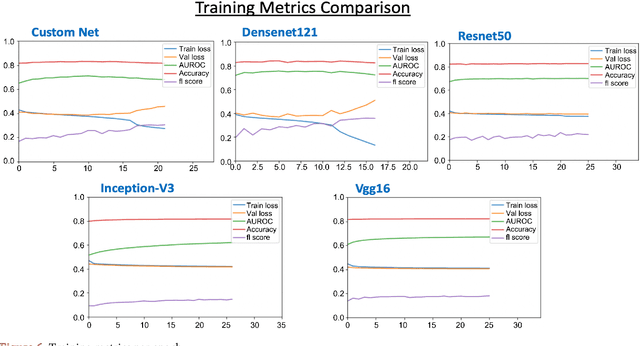
In this era of pandemic, the future of healthcare industry has never been more exciting. Artificial intelligence and machine learning (AI & ML) present opportunities to develop solutions that cater for very specific needs within the industry. Deep learning in healthcare had become incredibly powerful for supporting clinics and in transforming patient care in general. Deep learning is increasingly being applied for the detection of clinically important features in the images beyond what can be perceived by the naked human eye. Chest X-ray images are one of the most common clinical method for diagnosing a number of diseases such as pneumonia, lung cancer and many other abnormalities like lesions and fractures. Proper diagnosis of a disease from X-ray images is often challenging task for even expert radiologists and there is a growing need for computerized support systems due to the large amount of information encoded in X-Ray images. The goal of this paper is to develop a lightweight solution to detect 14 different chest conditions from an X ray image. Given an X-ray image as input, our classifier outputs a label vector indicating which of 14 disease classes does the image fall into. Along with the image features, we are also going to use non-image features available in the data such as X-ray view type, age, gender etc. The original study conducted Stanford ML Group is our base line. Original study focuses on predicting 5 diseases. Our aim is to improve upon previous work, expand prediction to 14 diseases and provide insight for future chest radiography research.
Hierarchical Explanations for Video Action Recognition
Jan 04, 2023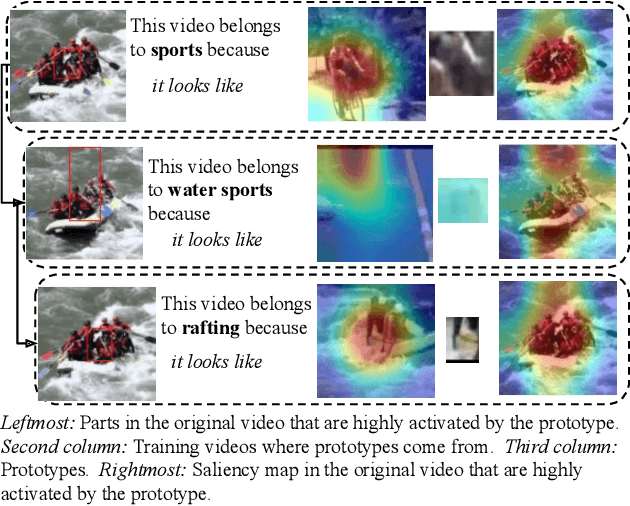

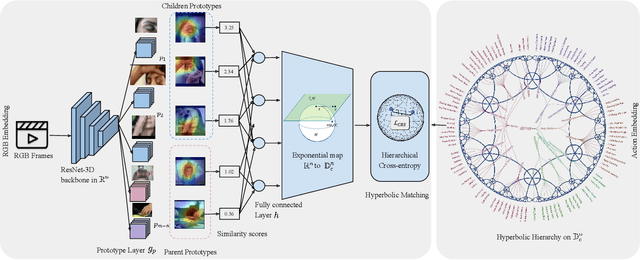

We propose Hierarchical ProtoPNet: an interpretable network that explains its reasoning process by considering the hierarchical relationship between classes. Different from previous methods that explain their reasoning process by dissecting the input image and finding the prototypical parts responsible for the classification, we propose to explain the reasoning process for video action classification by dissecting the input video frames on multiple levels of the class hierarchy. The explanations leverage the hierarchy to deal with uncertainty, akin to human reasoning: When we observe water and human activity, but no definitive action it can be recognized as the water sports parent class. Only after observing a person swimming can we definitively refine it to the swimming action. Experiments on ActivityNet and UCF-101 show performance improvements while providing multi-level explanations.
PACO: Parts and Attributes of Common Objects
Jan 04, 2023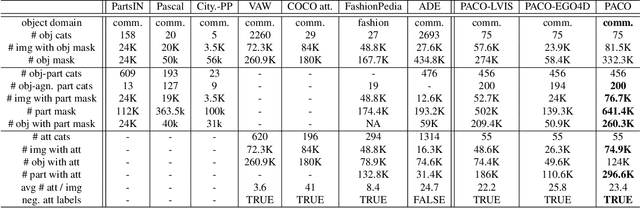
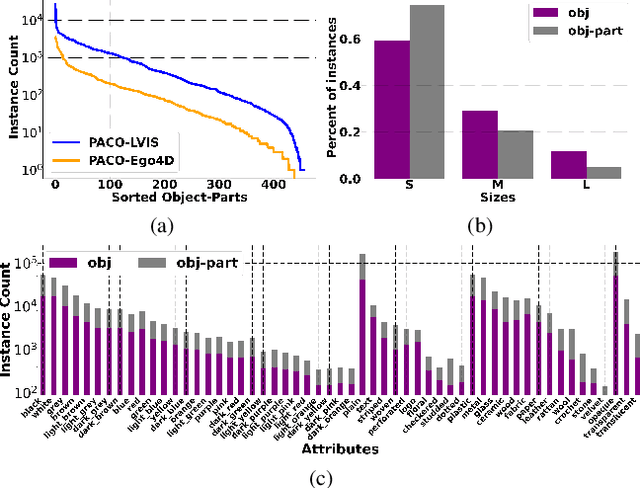
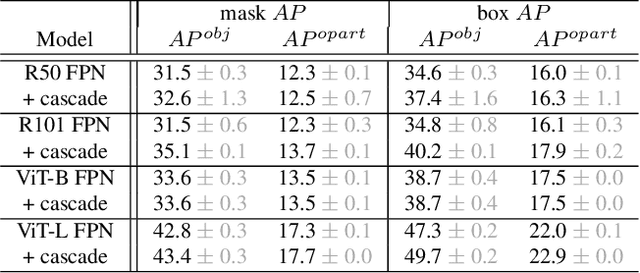

Object models are gradually progressing from predicting just category labels to providing detailed descriptions of object instances. This motivates the need for large datasets which go beyond traditional object masks and provide richer annotations such as part masks and attributes. Hence, we introduce PACO: Parts and Attributes of Common Objects. It spans 75 object categories, 456 object-part categories and 55 attributes across image (LVIS) and video (Ego4D) datasets. We provide 641K part masks annotated across 260K object boxes, with roughly half of them exhaustively annotated with attributes as well. We design evaluation metrics and provide benchmark results for three tasks on the dataset: part mask segmentation, object and part attribute prediction and zero-shot instance detection. Dataset, models, and code are open-sourced at https://github.com/facebookresearch/paco.
Flattening-Net: Deep Regular 2D Representation for 3D Point Cloud Analysis
Dec 17, 2022
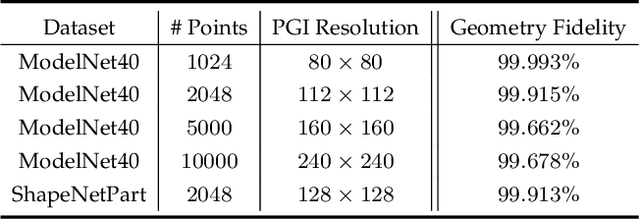
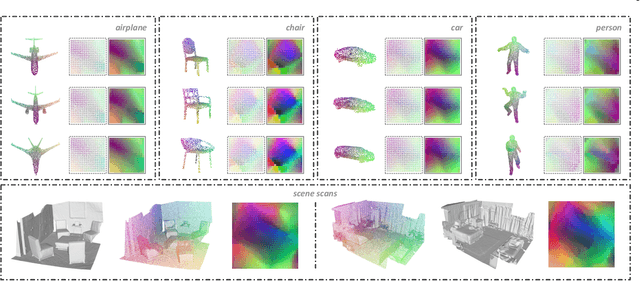
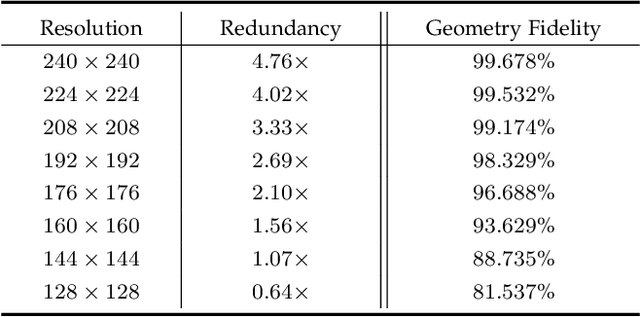
Point clouds are characterized by irregularity and unstructuredness, which pose challenges in efficient data exploitation and discriminative feature extraction. In this paper, we present an unsupervised deep neural architecture called Flattening-Net to represent irregular 3D point clouds of arbitrary geometry and topology as a completely regular 2D point geometry image (PGI) structure, in which coordinates of spatial points are captured in colors of image pixels. \mr{Intuitively, Flattening-Net implicitly approximates a locally smooth 3D-to-2D surface flattening process while effectively preserving neighborhood consistency.} \mr{As a generic representation modality, PGI inherently encodes the intrinsic property of the underlying manifold structure and facilitates surface-style point feature aggregation.} To demonstrate its potential, we construct a unified learning framework directly operating on PGIs to achieve \mr{diverse types of high-level and low-level} downstream applications driven by specific task networks, including classification, segmentation, reconstruction, and upsampling. Extensive experiments demonstrate that our methods perform favorably against the current state-of-the-art competitors. We will make the code and data publicly available at https://github.com/keeganhk/Flattening-Net.
Photo Rater: Photographs Auto-Selector with Deep Learning
Nov 26, 2022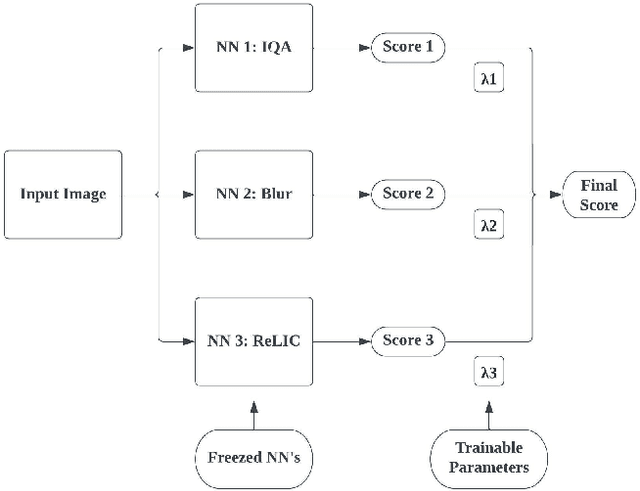


Photo Rater is a computer vision project that uses neural networks to help photographers select the best photo among those that are taken based on the same scene. This process is usually referred to as "culling" in photography, and it can be tedious and time-consuming if done manually. Photo Rater utilizes three separate neural networks to complete such a task: one for general image quality assessment, one for classifying whether the photo is blurry (either due to unsteady hands or out-of-focusness), and one for assessing general aesthetics (including the composition of the photo, among others). After feeding the image through each neural network, Photo Rater outputs a final score for each image, ranking them based on this score and presenting it to the user.
Query-based Hard-Image Retrieval for Object Detection at Test Time
Sep 23, 2022
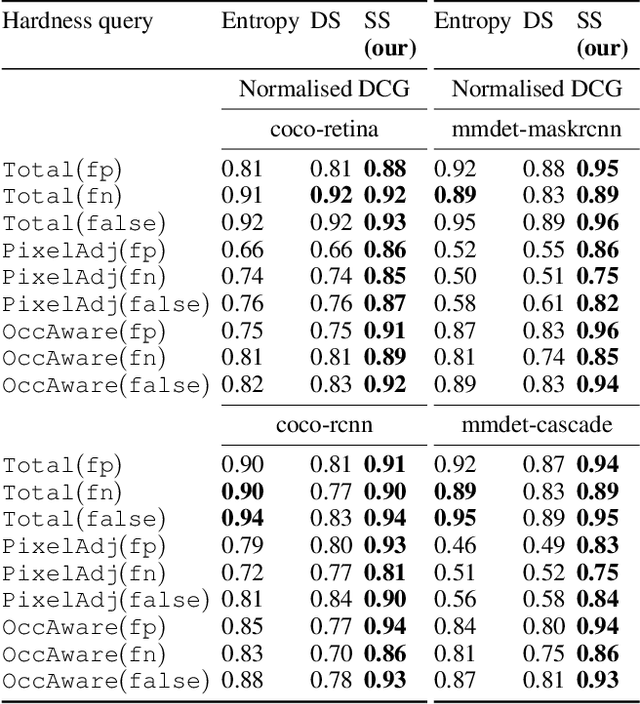
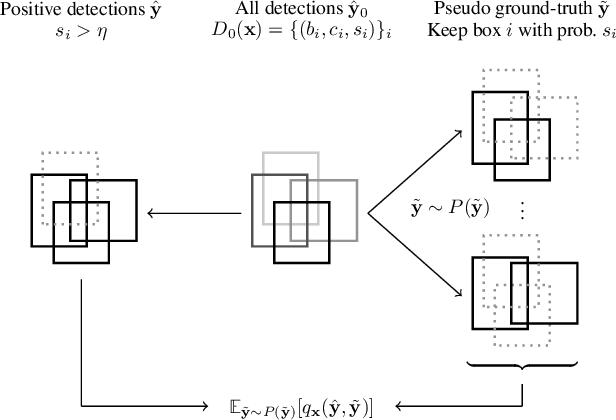
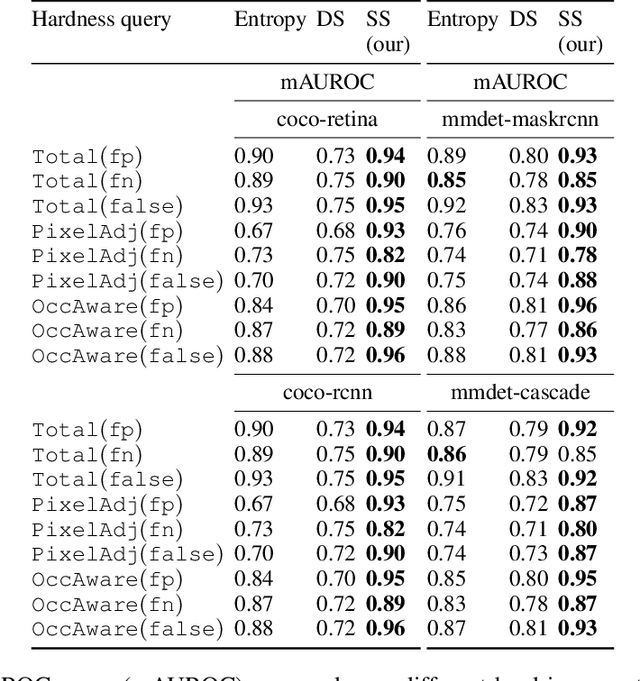
There is a longstanding interest in capturing the error behaviour of object detectors by finding images where their performance is likely to be unsatisfactory. In real-world applications such as autonomous driving, it is also crucial to characterise potential failures beyond simple requirements of detection performance. For example, a missed detection of a pedestrian close to an ego vehicle will generally require closer inspection than a missed detection of a car in the distance. The problem of predicting such potential failures at test time has largely been overlooked in the literature and conventional approaches based on detection uncertainty fall short in that they are agnostic to such fine-grained characterisation of errors. In this work, we propose to reformulate the problem of finding "hard" images as a query-based hard image retrieval task, where queries are specific definitions of "hardness", and offer a simple and intuitive method that can solve this task for a large family of queries. Our method is entirely post-hoc, does not require ground-truth annotations, is independent of the choice of a detector, and relies on an efficient Monte Carlo estimation that uses a simple stochastic model in place of the ground-truth. We show experimentally that it can be applied successfully to a wide variety of queries for which it can reliably identify hard images for a given detector without any labelled data. We provide results on ranking and classification tasks using the widely used RetinaNet, Faster-RCNN, Mask-RCNN, and Cascade Mask-RCNN object detectors.