 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DeepCut: Unsupervised Segmentation using Graph Neural Networks Clustering
Dec 18, 2022
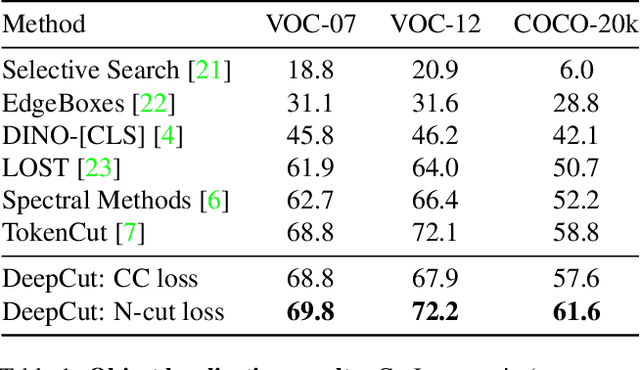
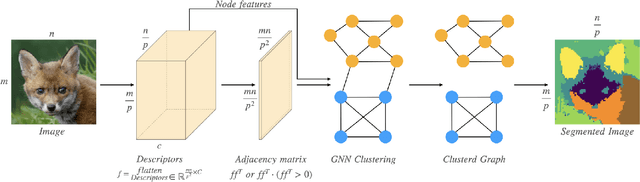
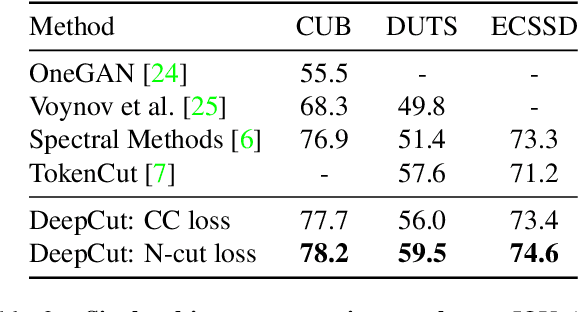

Image segmentation is a fundamental task in computer vision. Data annotation for training supervised methods can be labor-intensive, motivating unsupervised methods. Some existing approaches extract deep features from pre-trained networks and build a graph to apply classical clustering methods (e.g., $k$-means and normalized-cuts) as a post-processing stage. These techniques reduce the high-dimensional information encoded in the features to pair-wise scalar affinities. In this work, we replace classical clustering algorithms with a lightweight Graph Neural Network (GNN) trained to achieve the same clustering objective function. However, in contrast to existing approaches, we feed the GNN not only the pair-wise affinities between local image features but also the raw features themselves. Maintaining this connection between the raw feature and the clustering goal allows to perform part semantic segmentation implicitly, without requiring additional post-processing steps. We demonstrate how classical clustering objectives can be formulated as self-supervised loss functions for training our image segmentation GNN. Additionally, we use the Correlation-Clustering (CC) objective to perform clustering without defining the number of clusters ($k$-less clustering). We apply the proposed method for object localization, segmentation, and semantic part segmentation tasks, surpassing state-of-the-art performance on multiple benchmarks.
Bayesian Image Super-Resolution with Deep Modeling of Image Statistics
Mar 31, 2022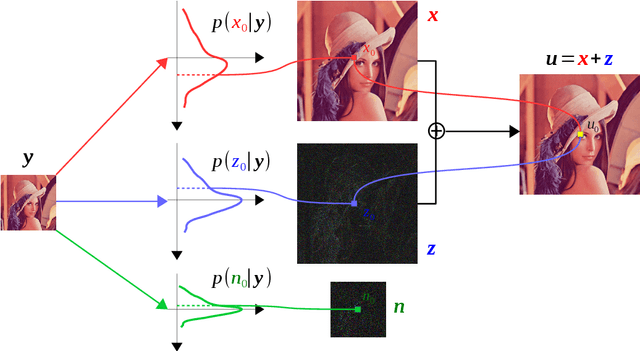
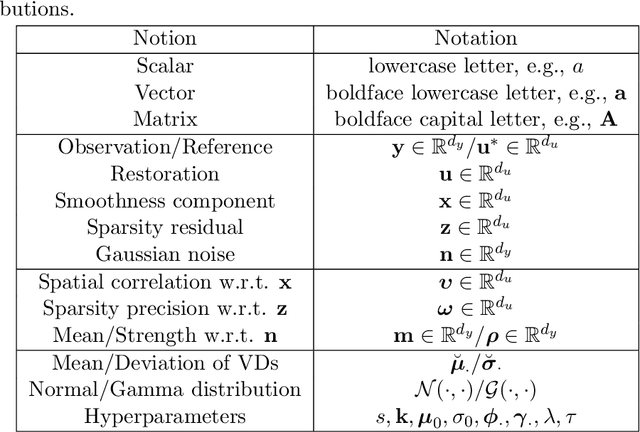
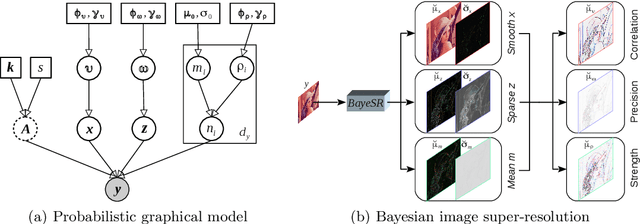

Modeling statistics of image priors is useful for image super-resolution, but little attention has been paid from the massive works of deep learning-based methods. In this work, we propose a Bayesian image restoration framework, where natural image statistics are modeled with the combination of smoothness and sparsity priors. Concretely, firstly we consider an ideal image as the sum of a smoothness component and a sparsity residual, and model real image degradation including blurring, downscaling, and noise corruption. Then, we develop a variational Bayesian approach to infer their posteriors. Finally, we implement the variational approach for single image super-resolution (SISR) using deep neural networks, and propose an unsupervised training strategy. The experiments on three image restoration tasks, \textit{i.e.,} ideal SISR, realistic SISR, and real-world SISR, demonstrate that our method has superior model generalizability against varying noise levels and degradation kernels and is effective in unsupervised SISR. The code and resulting models are released via \url{https://zmiclab.github.io/projects.html}.
* 45 pages
Flattening Surface Based On Using Contour Estimating Subdivision Surface
Dec 27, 2022


In the process of projecting the surface of a three-dimensional object onto a two-dimensional surface, due to the perspective distortion, the image on the surface of the object will have different degrees of distortion according to the level of the surface curvature. This paper presents an imprecise method for flattening this type of distortion on the surface of a regularly curved body. The main idea of this method is to roughly estimate the gridded surface subdivision that can be used to describe the surface of the three-dimensional object through the contour curve of the two-dimensional image of the object. Then, take each grid block with different sizes and shapes inversely transformed into a rectangle with exactly the same shape and size. Finally, each of the same rectangles is splicing and recombining in turn to obtain a roughly flat rectangle. This paper will introduce and show the specific process and results of using this method to solve the problem of bending page flattening, then demonstrate the feasibility and limitations of this method.
Efficient data-driven gap filling of satellite image time series using deep neural networks with partial convolutions
Aug 18, 2022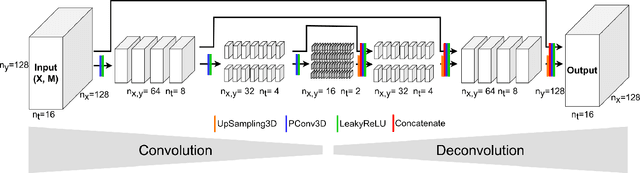


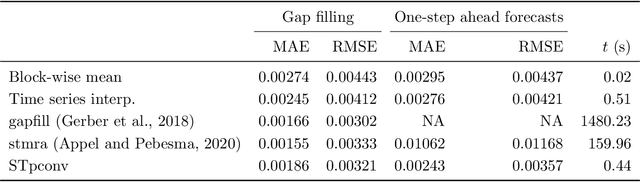
The abundance of gaps in satellite image time series often complicates the application of deep learning models such as convolutional neural networks for spatiotemporal modeling. Based on previous work in computer vision on image inpainting, this paper shows how three-dimensional spatiotemporal partial convolutions can be used as layers in neural networks to fill gaps in satellite image time series. To evaluate the approach, we apply a U-Net-like model on incomplete image time series of quasi-global carbon monoxide observations from the Sentinel-5P satellite. Prediction errors were comparable to two considered statistical approaches while computation times for predictions were up to three orders of magnitude faster, making the approach applicable to process large amounts of satellite data. Partial convolutions can be added as layers to other types of neural networks, making it relatively easy to integrate with existing deep learning models. However, the approach does not quantify prediction errors and further research is needed to understand and improve model transferability. The implementation of spatiotemporal partial convolutions and the U-Net-like model is available as open-source software.
[Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT
Jan 30, 2023![Figure 1 for [Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fdad1e0aecebde7831ba14d9096a9e0a14de30b07%2F3-Figure1-1.png&w=640&q=75)
![Figure 2 for [Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fdad1e0aecebde7831ba14d9096a9e0a14de30b07%2F8-Table1-1.png&w=640&q=75)
![Figure 3 for [Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fdad1e0aecebde7831ba14d9096a9e0a14de30b07%2F4-Figure2-1.png&w=640&q=75)
![Figure 4 for [Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fdad1e0aecebde7831ba14d9096a9e0a14de30b07%2F8-Table2-1.png&w=640&q=75)
Minerals are indispensable for a functioning modern society. Yet, their supply is limited causing a need for optimizing their exploration and extraction both from ores and recyclable materials. Typically, these processes must be meticulously adapted to the precise properties of the processed particles, requiring an extensive characterization of their shapes, appearances as well as the overall material composition. Current approaches perform this analysis based on bulk segmentation and characterization of particles, and rely on rudimentary postprocessing techniques to separate touching particles. However, due to their inability to reliably perform this separation as well as the need to retrain or reconfigure most methods for each new image, these approaches leave untapped potential to be leveraged. Here, we propose an instance segmentation method that is able to extract individual particles from large micro CT images taken from mineral samples embedded in an epoxy matrix. Our approach is based on the powerful nnU-Net framework, introduces a particle size normalization, makes use of a border-core representation to enable instance segmentation and is trained with a large dataset containing particles of numerous different materials and minerals. We demonstrate that our approach can be applied out-of-the box to a large variety of particle types, including materials and appearances that have not been part of the training set. Thus, no further manual annotations and retraining are required when applying the method to new mineral samples, enabling substantially higher scalability of experiments than existing methods. Our code and dataset are made publicly available.
Keys to Better Image Inpainting: Structure and Texture Go Hand in Hand
Aug 05, 2022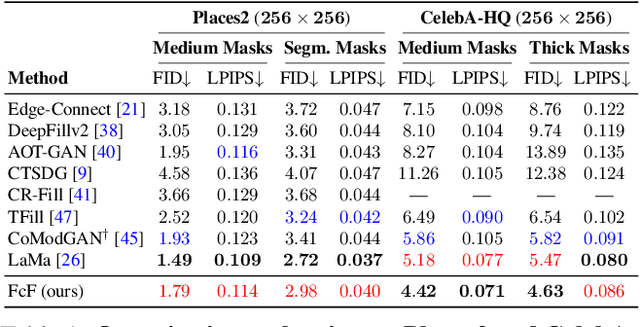
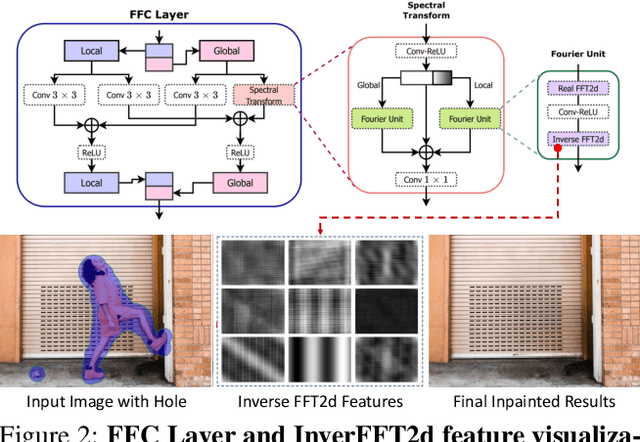
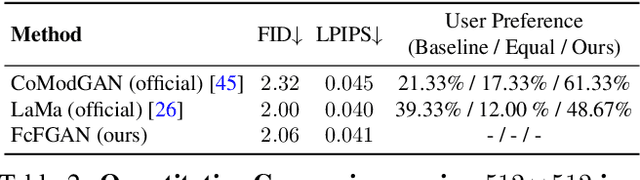
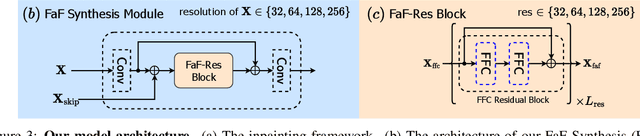
Deep image inpainting has made impressive progress with recent advances in image generation and processing algorithms. We claim that the performance of inpainting algorithms can be better judged by the generated structures and textures. Structures refer to the generated object boundary or novel geometric structures within the hole, while texture refers to high-frequency details, especially man-made repeating patterns filled inside the structural regions. We believe that better structures are usually obtained from a coarse-to-fine GAN-based generator network while repeating patterns nowadays can be better modeled using state-of-the-art high-frequency fast fourier convolutional layers. In this paper, we propose a novel inpainting network combining the advantages of the two designs. Therefore, our model achieves a remarkable visual quality to match state-of-the-art performance in both structure generation and repeating texture synthesis using a single network. Extensive experiments demonstrate the effectiveness of the method, and our conclusions further highlight the two critical factors of image inpainting quality, structures, and textures, as the future design directions of inpainting networks.
Identity masking effectiveness and gesture recognition: Effects of eye enhancement in seeing through the mask
Jan 20, 2023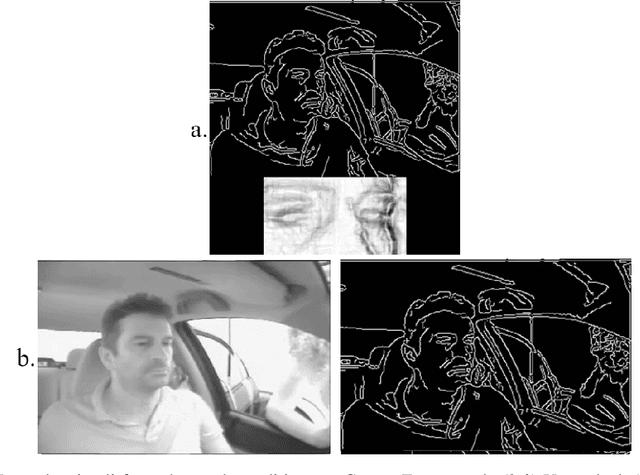

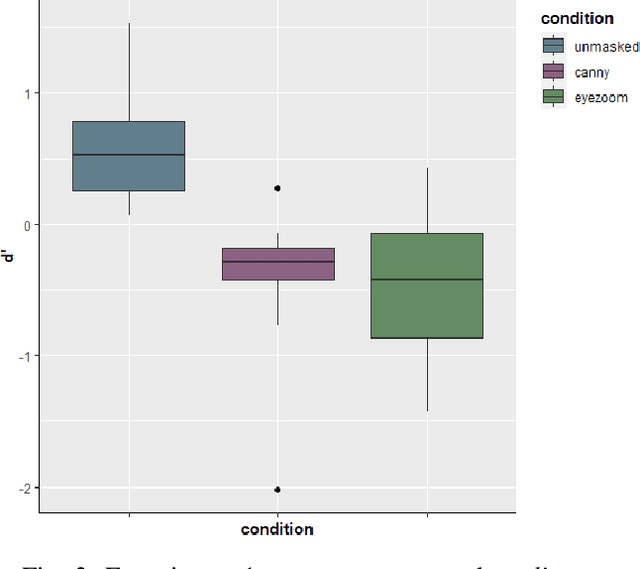
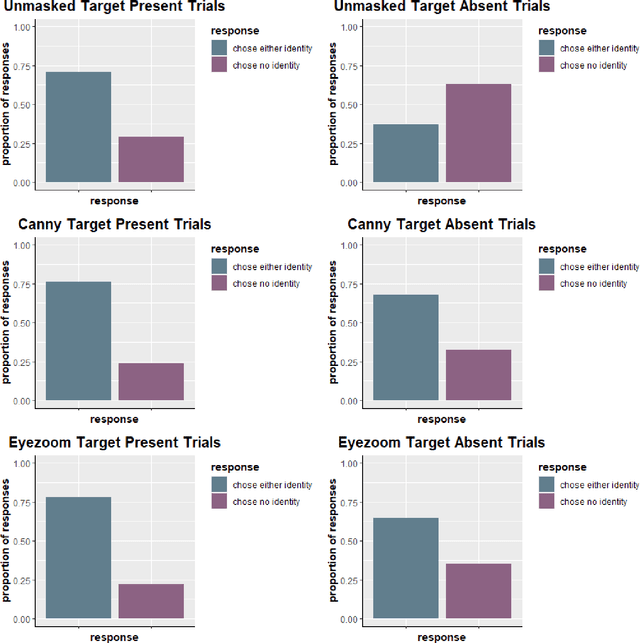
Face identity masking algorithms developed in recent years aim to protect the privacy of people in video recordings. These algorithms are designed to interfere with identification, while preserving information about facial actions. An important challenge is to preserve subtle actions in the eye region, while obscuring the salient identity cues from the eyes. We evaluated the effectiveness of identity-masking algorithms based on Canny filters, applied with and without eye enhancement, for interfering with identification and preserving facial actions. In Experiments 1 and 2, we tested human participants' ability to match the facial identity of a driver in a low resolution video to a high resolution facial image. Results showed that both masking methods impaired identification, and that eye enhancement did not alter the effectiveness of the Canny filter mask. In Experiment 3, we tested action preservation and found that neither method interfered significantly with driver action perception. We conclude that relatively simple, filter-based masking algorithms, which are suitable for application to low quality video, can be used in privacy protection without compromising action perception.
One Sample Diffusion Model in Projection Domain for Low-Dose CT Imaging
Dec 07, 2022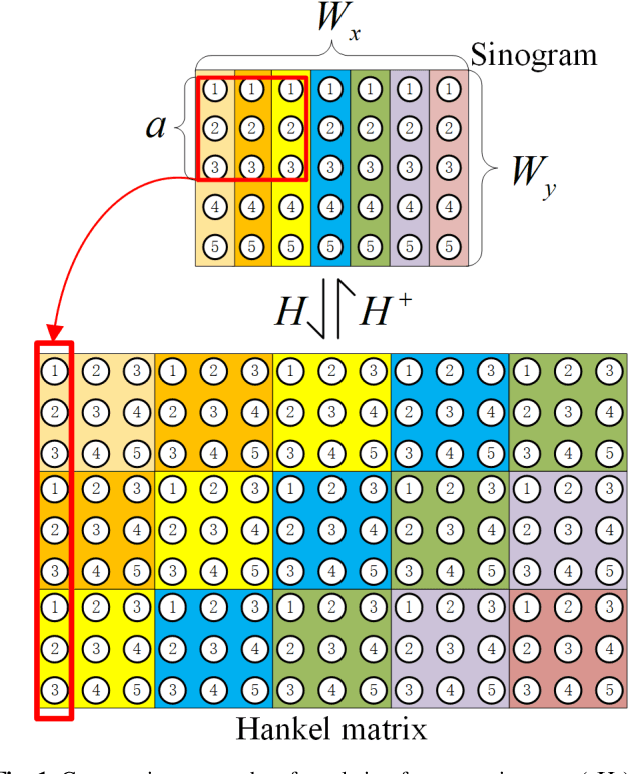
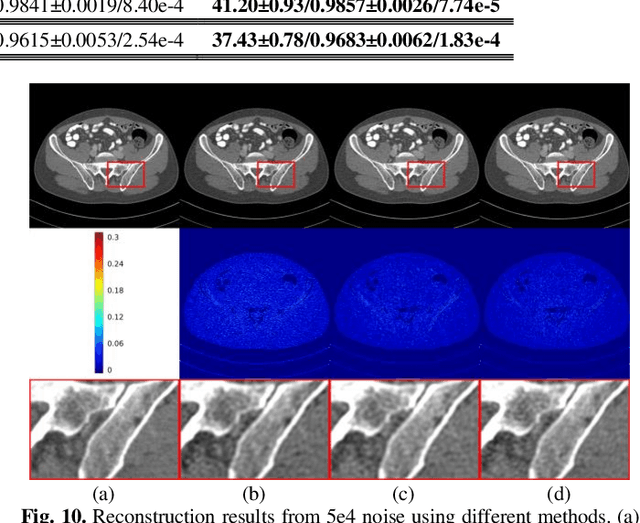
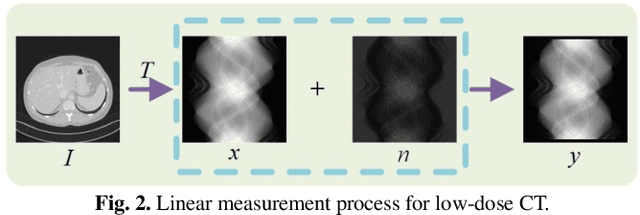
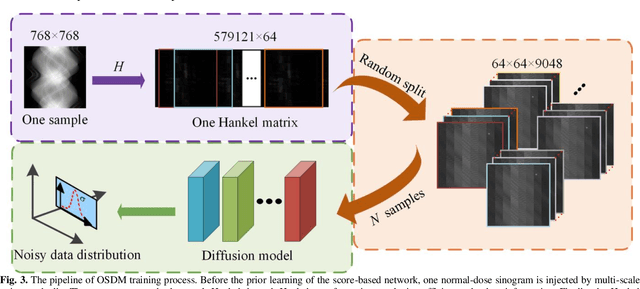
Low-dose computed tomography (CT) plays a significant role in reducing the radiation risk in clinical applications. However, lowering the radiation dose will significantly degrade the image quality. With the rapid development and wide application of deep learning, it has brought new directions for the development of low-dose CT imaging algorithms. Therefore, we propose a fully unsupervised one sample diffusion model (OSDM)in projection domain for low-dose CT reconstruction. To extract sufficient prior information from single sample, the Hankel matrix formulation is employed. Besides, the penalized weighted least-squares and total variation are introduced to achieve superior image quality. Specifically, we first train a score-based generative model on one sinogram by extracting a great number of tensors from the structural-Hankel matrix as the network input to capture prior distribution. Then, at the inference stage, the stochastic differential equation solver and data consistency step are performed iteratively to obtain the sinogram data. Finally, the final image is obtained through the filtered back-projection algorithm. The reconstructed results are approaching to the normal-dose counterparts. The results prove that OSDM is practical and effective model for reducing the artifacts and preserving the image quality.
SuperGF: Unifying Local and Global Features for Visual Localization
Dec 23, 2022
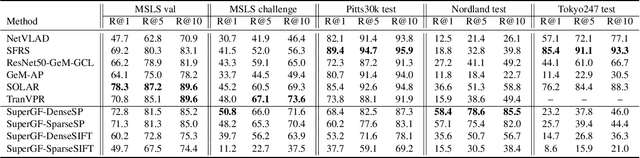
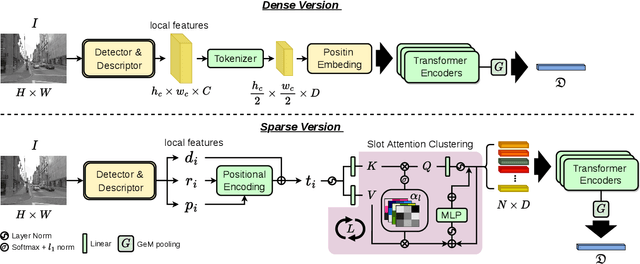
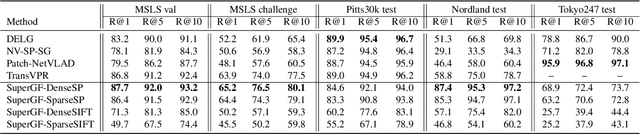
Advanced visual localization techniques encompass image retrieval challenges and 6 Degree-of-Freedom (DoF) camera pose estimation, such as hierarchical localization. Thus, they must extract global and local features from input images. Previous methods have achieved this through resource-intensive or accuracy-reducing means, such as combinatorial pipelines or multi-task distillation. In this study, we present a novel method called SuperGF, which effectively unifies local and global features for visual localization, leading to a higher trade-off between localization accuracy and computational efficiency. Specifically, SuperGF is a transformer-based aggregation model that operates directly on image-matching-specific local features and generates global features for retrieval. We conduct experimental evaluations of our method in terms of both accuracy and efficiency, demonstrating its advantages over other methods. We also provide implementations of SuperGF using various types of local features, including dense and sparse learning-based or hand-crafted descriptors.
Data class-specific all-optical transformations and encryption
Dec 25, 2022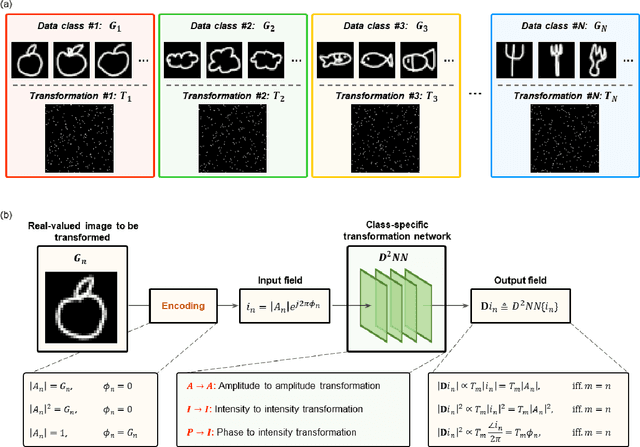
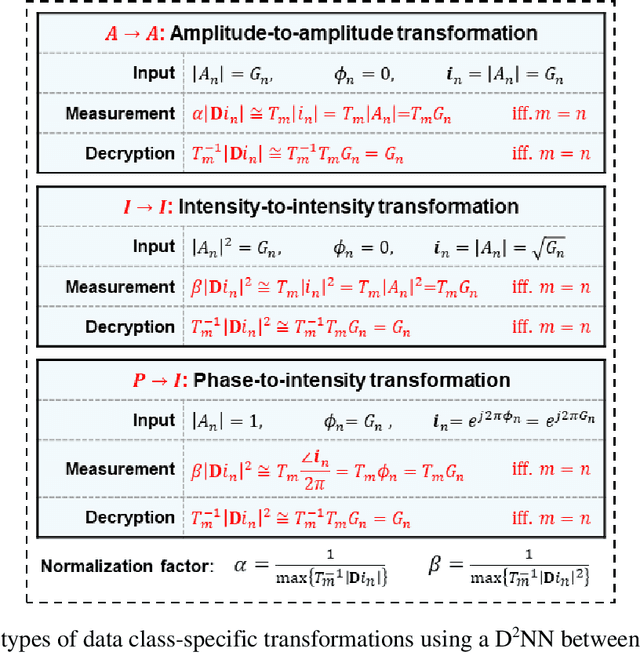
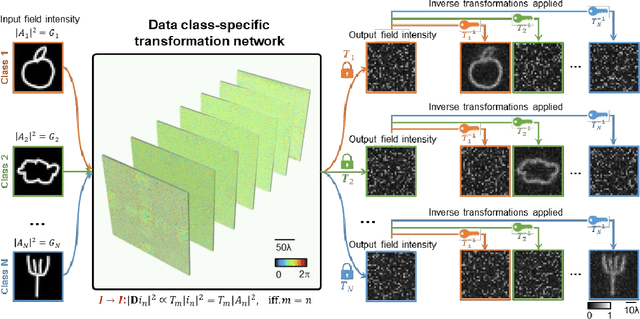
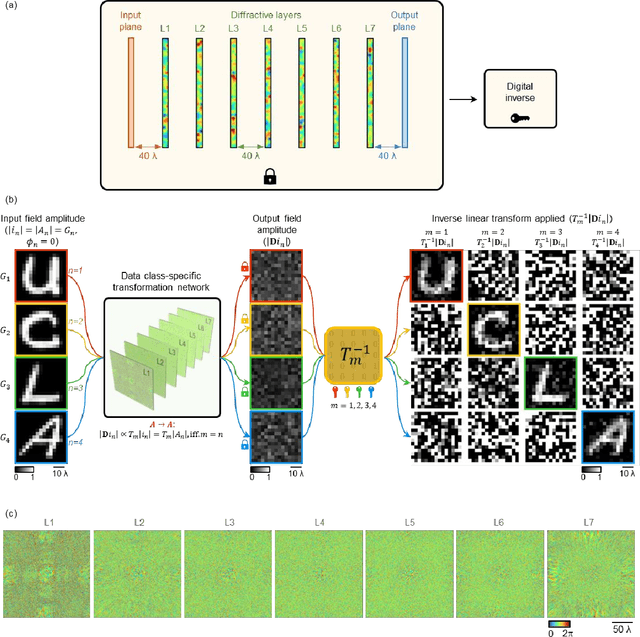
Diffractive optical networks provide rich opportunities for visual computing tasks since the spatial information of a scene can be directly accessed by a diffractive processor without requiring any digital pre-processing steps. Here we present data class-specific transformations all-optically performed between the input and output fields-of-view (FOVs) of a diffractive network. The visual information of the objects is encoded into the amplitude (A), phase (P), or intensity (I) of the optical field at the input, which is all-optically processed by a data class-specific diffractive network. At the output, an image sensor-array directly measures the transformed patterns, all-optically encrypted using the transformation matrices pre-assigned to different data classes, i.e., a separate matrix for each data class. The original input images can be recovered by applying the correct decryption key (the inverse transformation) corresponding to the matching data class, while applying any other key will lead to loss of information. The class-specificity of these all-optical diffractive transformations creates opportunities where different keys can be distributed to different users; each user can only decode the acquired images of only one data class, serving multiple users in an all-optically encrypted manner. We numerically demonstrated all-optical class-specific transformations covering A-->A, I-->I, and P-->I transformations using various image datasets. We also experimentally validated the feasibility of this framework by fabricating a class-specific I-->I transformation diffractive network using two-photon polymerization and successfully tested it at 1550 nm wavelength. Data class-specific all-optical transformations provide a fast and energy-efficient method for image and data encryption, enhancing data security and privacy.