 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SIAN: Style-Guided Instance-Adaptive Normalization for Multi-Organ Histopathology Image Synthesis
Sep 02, 2022
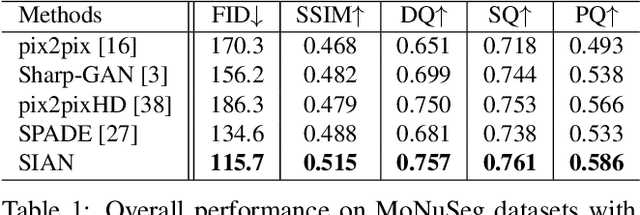

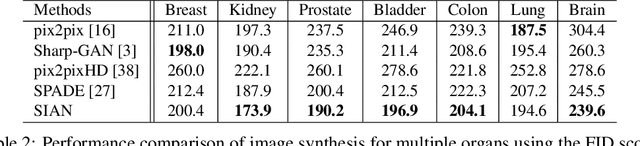
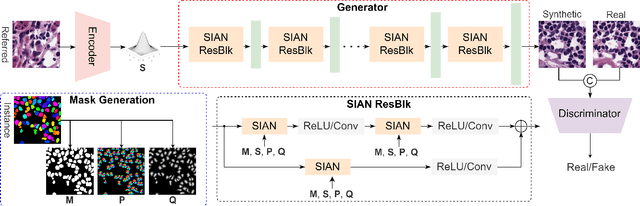
Existing deep networks for histopathology image synthesis cannot generate accurate boundaries for clustered nuclei and cannot output image styles that align with different organs. To address these issues, we propose a style-guided instance-adaptive normalization (SIAN) to synthesize realistic color distributions and textures for different organs. SIAN contains four phases, semantization, stylization, instantiation, and modulation. The four phases work together and are integrated into a generative network to embed image semantics, style, and instance-level boundaries. Experimental results demonstrate the effectiveness of all components in SIAN, and show that the proposed method outperforms the state-of-the-art conditional GANs for histopathology image synthesis using the Frechet Inception Distance (FID), structural similarity Index (SSIM), detection quality(DQ), segmentation quality(SQ), and panoptic quality(PQ). Furthermore, the performance of a segmentation network could be significantly improved by incorporating synthetic images generated using SIAN.
Lightweight Real-time Semantic Segmentation Network with Efficient Transformer and CNN
Feb 21, 2023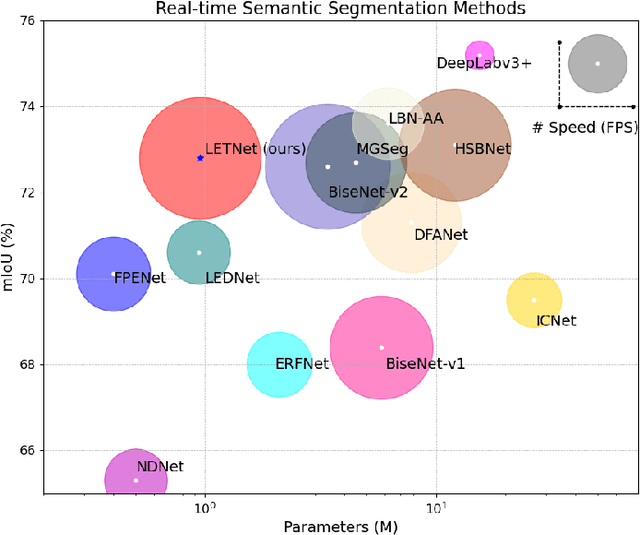
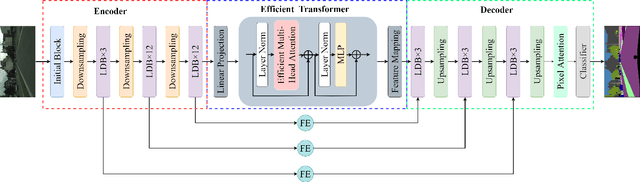
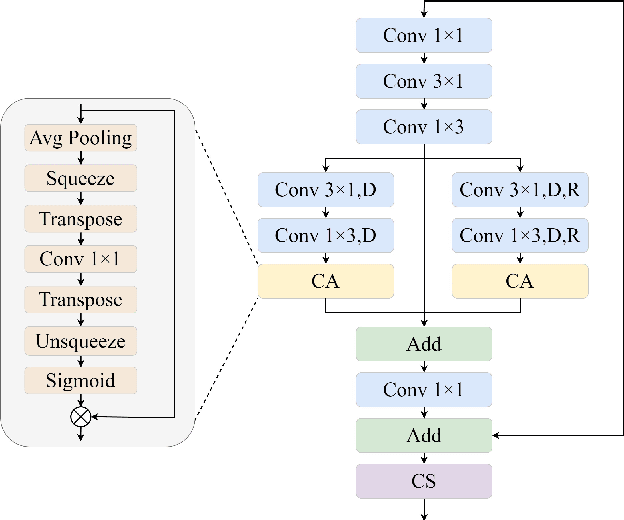
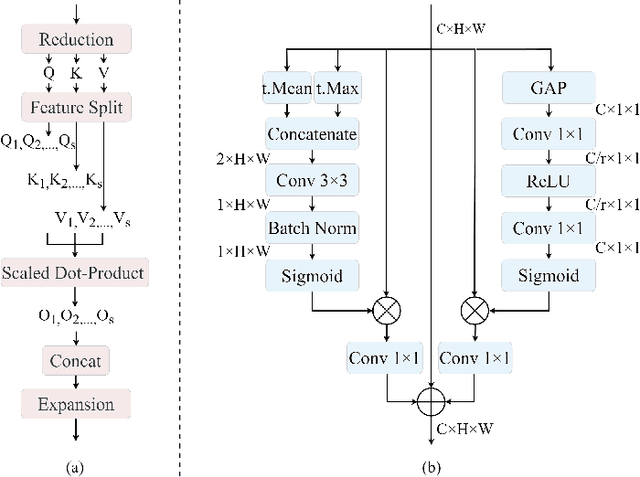
In the past decade, convolutional neural networks (CNNs) have shown prominence for semantic segmentation. Although CNN models have very impressive performance, the ability to capture global representation is still insufficient, which results in suboptimal results. Recently, Transformer achieved huge success in NLP tasks, demonstrating its advantages in modeling long-range dependency. Recently, Transformer has also attracted tremendous attention from computer vision researchers who reformulate the image processing tasks as a sequence-to-sequence prediction but resulted in deteriorating local feature details. In this work, we propose a lightweight real-time semantic segmentation network called LETNet. LETNet combines a U-shaped CNN with Transformer effectively in a capsule embedding style to compensate for respective deficiencies. Meanwhile, the elaborately designed Lightweight Dilated Bottleneck (LDB) module and Feature Enhancement (FE) module cultivate a positive impact on training from scratch simultaneously. Extensive experiments performed on challenging datasets demonstrate that LETNet achieves superior performances in accuracy and efficiency balance. Specifically, It only contains 0.95M parameters and 13.6G FLOPs but yields 72.8\% mIoU at 120 FPS on the Cityscapes test set and 70.5\% mIoU at 250 FPS on the CamVid test dataset using a single RTX 3090 GPU. The source code will be available at https://github.com/IVIPLab/LETNet.
Lateralized Learning for Multi-Class Visual Classification Tasks
Jan 30, 2023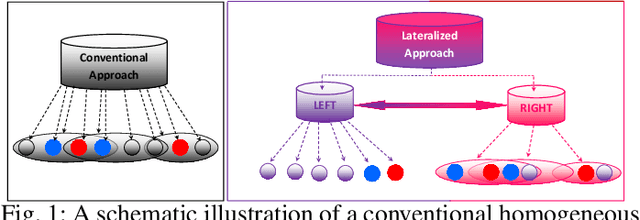

The majority of computer vision algorithms fail to find higher-order (abstract) patterns in an image so are not robust against adversarial attacks, unlike human lateralized vision. Deep learning considers each input pixel in a homogeneous manner such that different parts of a ``locality-sensitive hashing table'' are often not connected, meaning higher-order patterns are not discovered. Hence these systems are not robust against noisy, irrelevant, and redundant data, resulting in the wrong prediction being made with high confidence. Conversely, vertebrate brains afford heterogeneous knowledge representation through lateralization, enabling modular learning at different levels of abstraction. This work aims to verify the effectiveness, scalability, and robustness of a lateralized approach to real-world problems that contain noisy, irrelevant, and redundant data. The experimental results of multi-class (200 classes) image classification show that the novel system effectively learns knowledge representation at multiple levels of abstraction making it more robust than other state-of-the-art techniques. Crucially, the novel lateralized system outperformed all the state-of-the-art deep learning-based systems for the classification of normal and adversarial images by 19.05% - 41.02% and 1.36% - 49.22%, respectively. Findings demonstrate the value of heterogeneous and lateralized learning for computer vision applications.
NeSyFOLD: A System for Generating Logic-based Explanations from Convolutional Neural Networks
Jan 30, 2023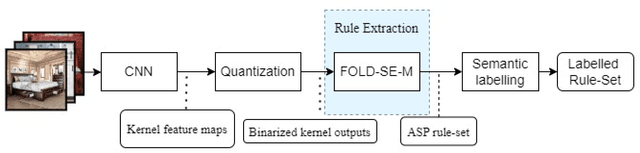
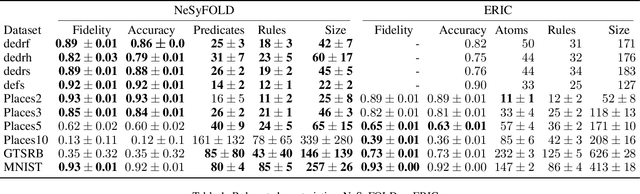
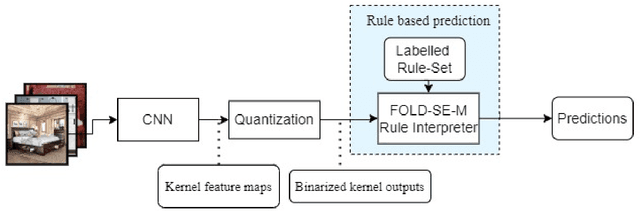

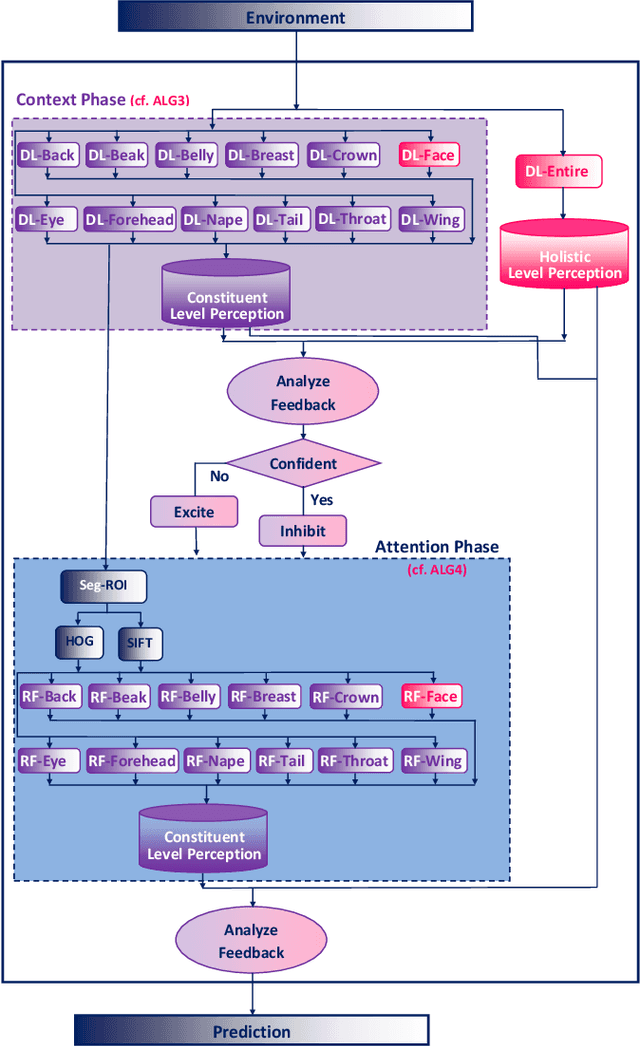
We present a novel neurosymbolic system called NeSyFOLD that classifies images while providing a logic-based explanation of the classification. NeSyFOLD's training process is as follows: (i) We first pre-train a CNN on the input image dataset and extract activations of the last layer filters as binary values; (ii) Next, we use the FOLD-SE-M rule-based machine learning algorithm to generate a logic program that can classify an image -- represented as a vector of binary activations corresponding to each filter -- while producing a logical explanation. The rules generated by the FOLD-SE-M algorithm have filter numbers as predicates. We use a novel algorithm that we have devised for automatically mapping the CNN filters to semantic concepts in the images. This mapping is used to replace predicate names (filter numbers) in the rule-set with corresponding semantic concept labels. The resulting rule-set is highly interpretable, and can be intuitively understood by humans. We compare our NeSyFOLD system with the ERIC system that uses a decision-tree like algorithm to obtain the rules. Our system has the following advantages over ERIC: (i) NeSyFOLD generates smaller rule-sets without compromising on the accuracy and fidelity; (ii) NeSyFOLD generates the mapping of filter numbers to semantic labels automatically.
Stereo X-ray Tomography
Feb 26, 2023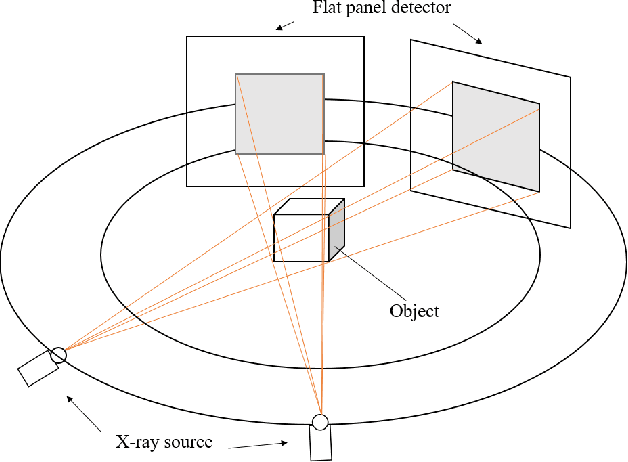

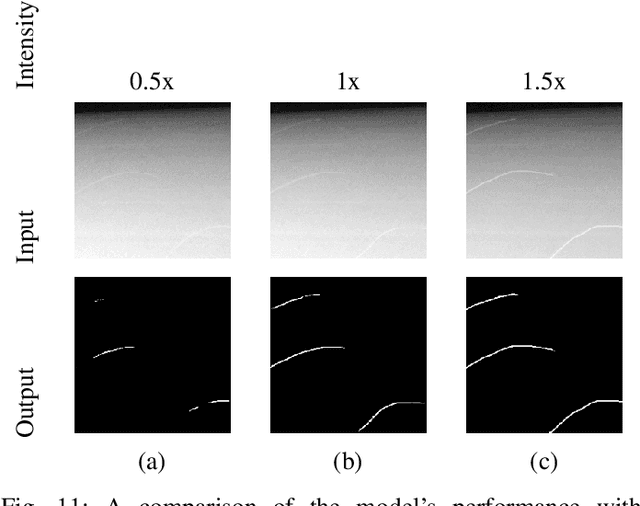
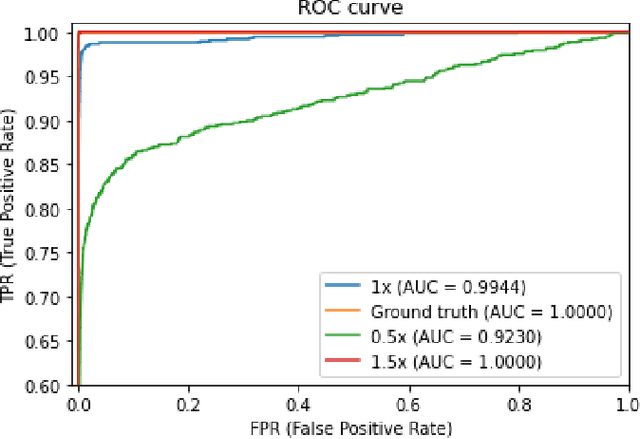
X-ray tomography is a powerful volumetric imaging technique, but detailed three dimensional (3D) imaging requires the acquisition of a large number of individual X-ray images, which is time consuming. For applications where spatial information needs to be collected quickly, for example, when studying dynamic processes, standard X-ray tomography is therefore not applicable. Inspired by stereo vision, in this paper, we develop X-ray imaging methods that work with two X-ray projection images. In this setting, without the use of additional strong prior information, we no longer have enough information to fully recover the 3D tomographic images. However, up to a point, we are nevertheless able to extract spatial locations of point and line features. From stereo vision, it is well known that, for a known imaging geometry, once the same point is identified in two images taken from different directions, then the point's location in 3D space is exactly specified. The challenge is the matching of points between images. As X-ray transmission images are fundamentally different from the surface reflection images used in standard computer vision, we here develop a different feature identification and matching approach. In fact, once point like features are identified, if there are limited points in the image, then they can often be matched exactly. In fact, by utilising a third observation from an appropriate direction, matching becomes unique. Once matched, point locations in 3D space are easily computed using geometric considerations. Linear features, with clear end points, can be located using a similar approach.
ConvoWaste: An Automatic Waste Segregation Machine Using Deep Learning
Feb 06, 2023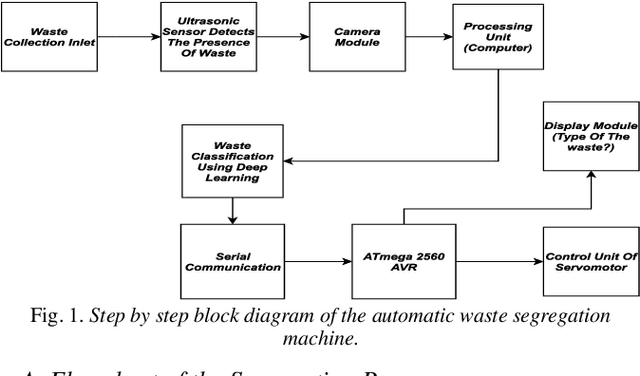
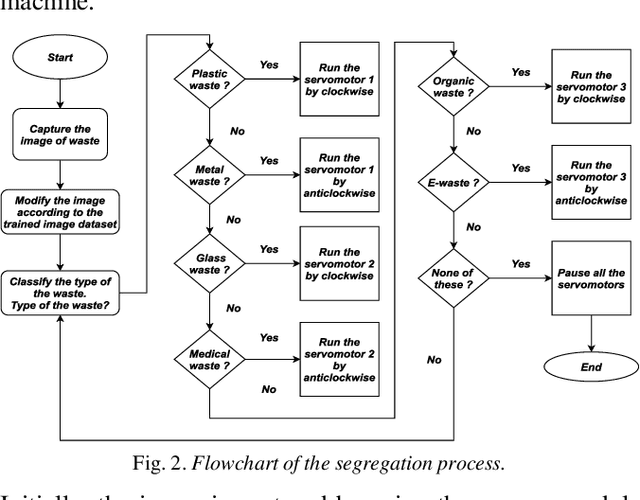
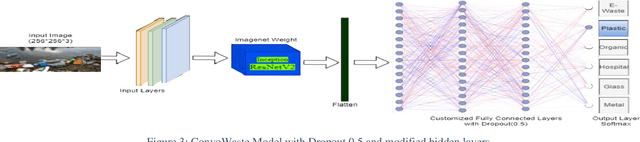
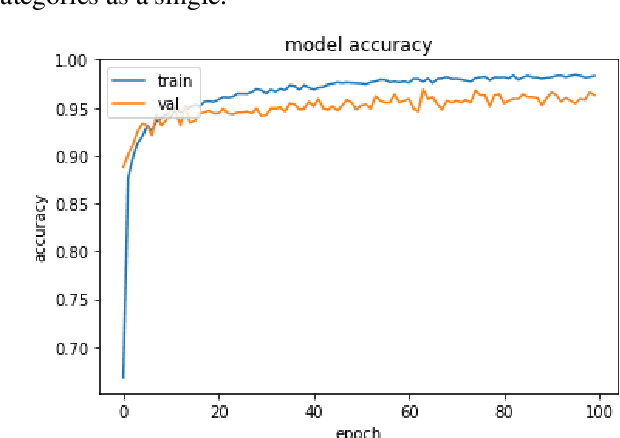
Nowadays, proper urban waste management is one of the biggest concerns for maintaining a green and clean environment. An automatic waste segregation system can be a viable solution to improve the sustainability of the country and boost the circular economy. This paper proposes a machine to segregate waste into different parts with the help of a smart object detection algorithm using ConvoWaste in the field of deep convolutional neural networks (DCNN) and image processing techniques. In this paper, deep learning and image processing techniques are applied to precisely classify the waste, and the detected waste is placed inside the corresponding bins with the help of a servo motor-based system. This machine has the provision to notify the responsible authority regarding the waste level of the bins and the time to trash out the bins filled with garbage by using the ultrasonic sensors placed in each bin and the dual-band GSM-based communication technology. The entire system is controlled remotely through an Android app in order to dump the separated waste in the desired place thanks to its automation properties. The use of this system can aid in the process of recycling resources that were initially destined to become waste, utilizing natural resources, and turning these resources back into usable products. Thus, the system helps fulfill the criteria of a circular economy through resource optimization and extraction. Finally, the system is designed to provide services at a low cost while maintaining a high level of accuracy in terms of technological advancement in the field of artificial intelligence (AI). We have gotten 98% accuracy for our ConvoWaste deep learning model.
Improved CNN Prediction Based Reversible Data Hiding
Jan 04, 2023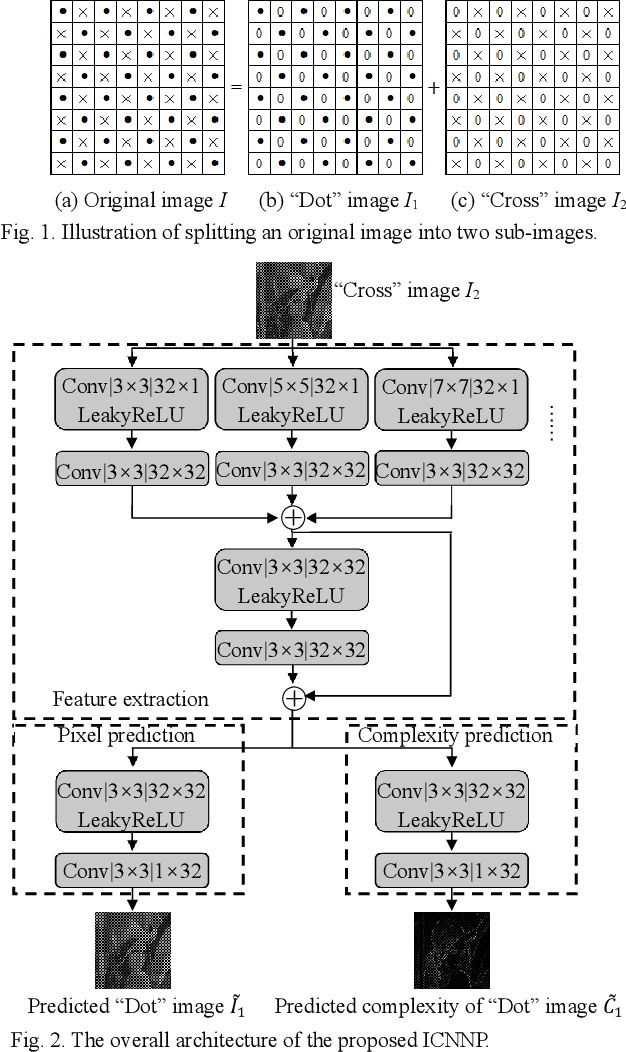
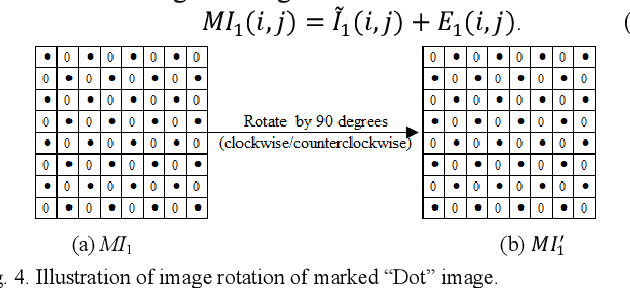
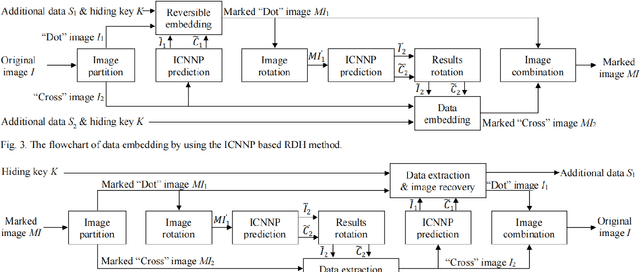
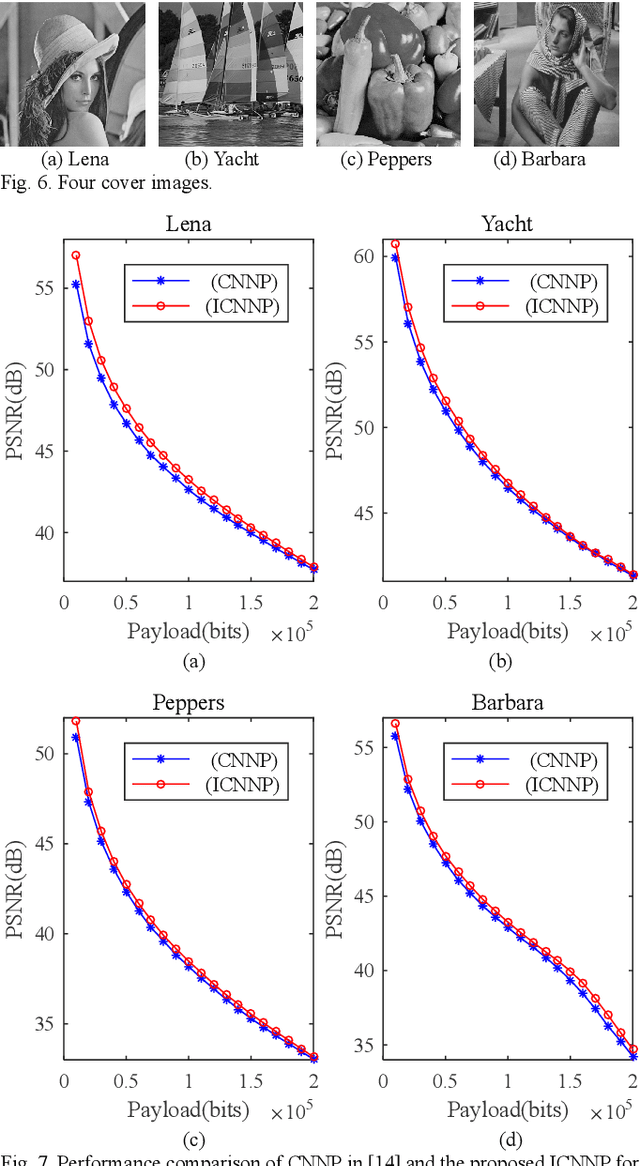
This letter proposes an improved CNN predictor (ICNNP) for reversible data hiding (RDH) in images, which consists of a feature extraction module, a pixel prediction module, and a complexity prediction module. Due to predicting the complexity of each pixel with the ICNNP during the embedding process, the proposed method can achieve superior performance than the CNN predictor-based method. Specifically, an input image does be first split into two different sub-images, i.e., the "Dot" image and the "Cross" image. Meanwhile, each sub-image is applied to predict another one. Then, the prediction errors of pixels are sorted with the predicted pixel complexities. In light of this, some sorted prediction errors with less complexity are selected to be efficiently used for low-distortion data embedding with a traditional histogram shift scheme. Experimental results demonstrate that the proposed method can achieve better embedding performance than that of the CNN predictor with the same histogram shifting strategy.
RangeViT: Towards Vision Transformers for 3D Semantic Segmentation in Autonomous Driving
Jan 24, 2023
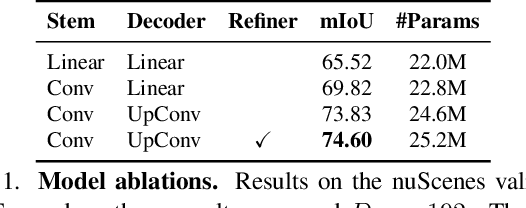
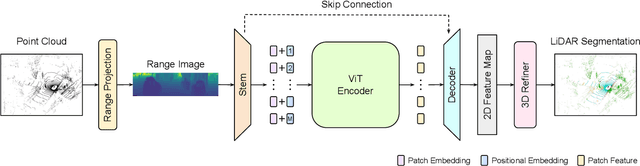
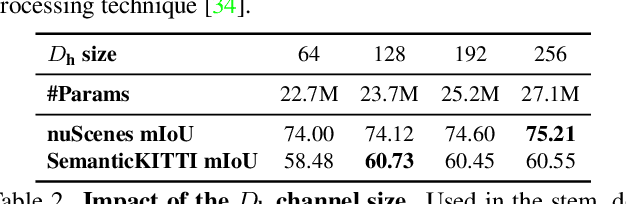
Casting semantic segmentation of outdoor LiDAR point clouds as a 2D problem, e.g., via range projection, is an effective and popular approach. These projection-based methods usually benefit from fast computations and, when combined with techniques which use other point cloud representations, achieve state-of-the-art results. Today, projection-based methods leverage 2D CNNs but recent advances in computer vision show that vision transformers (ViTs) have achieved state-of-the-art results in many image-based benchmarks. In this work, we question if projection-based methods for 3D semantic segmentation can benefit from these latest improvements on ViTs. We answer positively but only after combining them with three key ingredients: (a) ViTs are notoriously hard to train and require a lot of training data to learn powerful representations. By preserving the same backbone architecture as for RGB images, we can exploit the knowledge from long training on large image collections that are much cheaper to acquire and annotate than point clouds. We reach our best results with pre-trained ViTs on large image datasets. (b) We compensate ViTs' lack of inductive bias by substituting a tailored convolutional stem for the classical linear embedding layer. (c) We refine pixel-wise predictions with a convolutional decoder and a skip connection from the convolutional stem to combine low-level but fine-grained features of the the convolutional stem with the high-level but coarse predictions of the ViT encoder. With these ingredients, we show that our method, called RangeViT, outperforms existing projection-based methods on nuScenes and SemanticKITTI. We provide the implementation code at https://github.com/valeoai/rangevit.
Medical Image Segmentation using LeViT-UNet++: A Case Study on GI Tract Data
Sep 15, 2022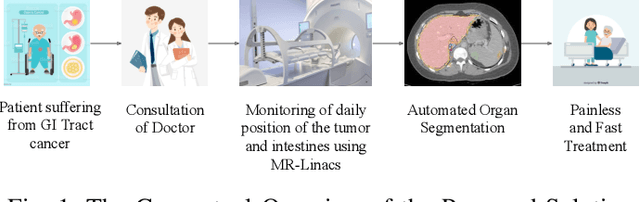
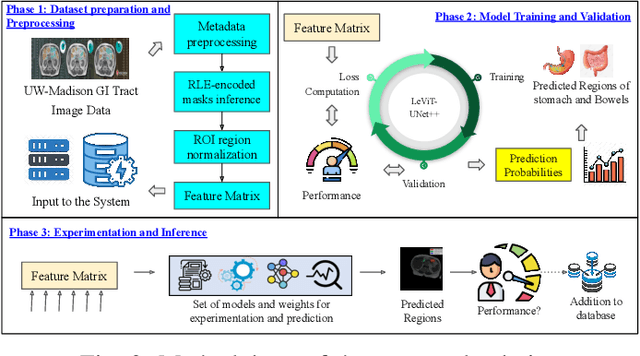
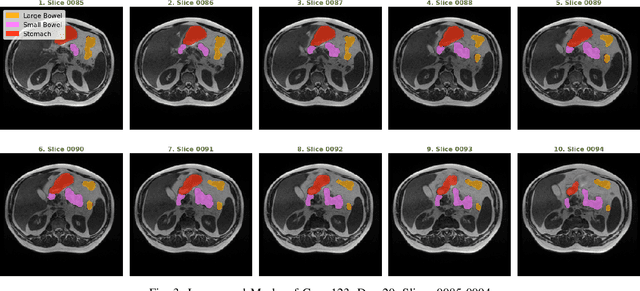
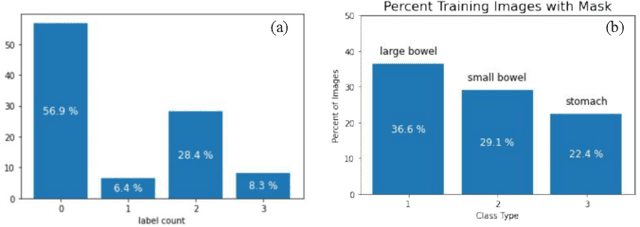
Gastro-Intestinal Tract cancer is considered a fatal malignant condition of the organs in the GI tract. Due to its fatality, there is an urgent need for medical image segmentation techniques to segment organs to reduce the treatment time and enhance the treatment. Traditional segmentation techniques rely upon handcrafted features and are computationally expensive and inefficient. Vision Transformers have gained immense popularity in many image classification and segmentation tasks. To address this problem from a transformers' perspective, we introduced a hybrid CNN-transformer architecture to segment the different organs from an image. The proposed solution is robust, scalable, and computationally efficient, with a Dice and Jaccard coefficient of 0.79 and 0.72, respectively. The proposed solution also depicts the essence of deep learning-based automation to improve the effectiveness of the treatment
Bridging Implicit and Explicit Geometric Transformations for Single-Image View Synthesis
Sep 15, 2022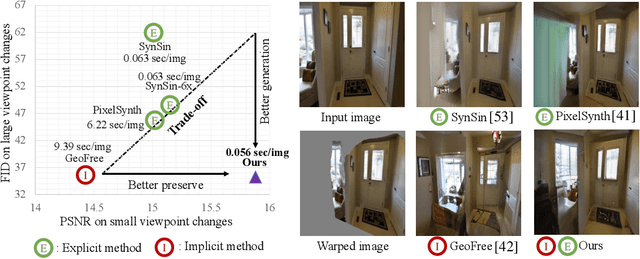

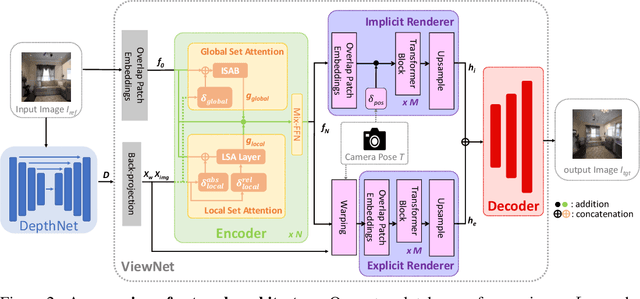
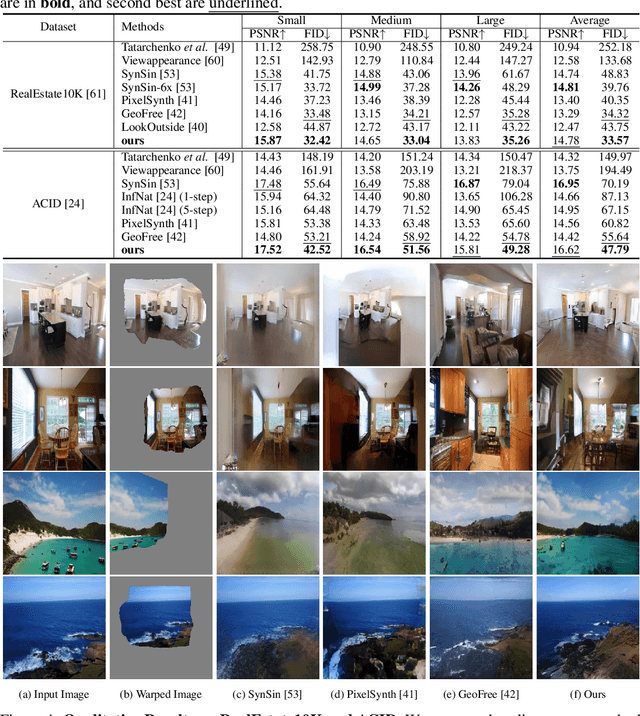
Creating novel views from a single image has achieved tremendous strides with advanced autoregressive models. Although recent methods generate high-quality novel views, synthesizing with only one explicit or implicit 3D geometry has a trade-off between two objectives that we call the ``seesaw'' problem: 1) preserving reprojected contents and 2) completing realistic out-of-view regions. Also, autoregressive models require a considerable computational cost. In this paper, we propose a single-image view synthesis framework for mitigating the seesaw problem. The proposed model is an efficient non-autoregressive model with implicit and explicit renderers. Motivated by characteristics that explicit methods well preserve reprojected pixels and implicit methods complete realistic out-of-view region, we introduce a loss function to complement two renderers. Our loss function promotes that explicit features improve the reprojected area of implicit features and implicit features improve the out-of-view area of explicit features. With the proposed architecture and loss function, we can alleviate the seesaw problem, outperforming autoregressive-based state-of-the-art methods and generating an image $\approx$100 times faster. We validate the efficiency and effectiveness of our method with experiments on RealEstate10K and ACID datasets.