 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
STBA: Towards Evaluating the Robustness of DNNs for Query-Limited Black-box Scenario
Mar 30, 2024
Many attack techniques have been proposed to explore the vulnerability of DNNs and further help to improve their robustness. Despite the significant progress made recently, existing black-box attack methods still suffer from unsatisfactory performance due to the vast number of queries needed to optimize desired perturbations. Besides, the other critical challenge is that adversarial examples built in a noise-adding manner are abnormal and struggle to successfully attack robust models, whose robustness is enhanced by adversarial training against small perturbations. There is no doubt that these two issues mentioned above will significantly increase the risk of exposure and result in a failure to dig deeply into the vulnerability of DNNs. Hence, it is necessary to evaluate DNNs' fragility sufficiently under query-limited settings in a non-additional way. In this paper, we propose the Spatial Transform Black-box Attack (STBA), a novel framework to craft formidable adversarial examples in the query-limited scenario. Specifically, STBA introduces a flow field to the high-frequency part of clean images to generate adversarial examples and adopts the following two processes to enhance their naturalness and significantly improve the query efficiency: a) we apply an estimated flow field to the high-frequency part of clean images to generate adversarial examples instead of introducing external noise to the benign image, and b) we leverage an efficient gradient estimation method based on a batch of samples to optimize such an ideal flow field under query-limited settings. Compared to existing score-based black-box baselines, extensive experiments indicated that STBA could effectively improve the imperceptibility of the adversarial examples and remarkably boost the attack success rate under query-limited settings.
Evaluating Text-to-Image Generative Models: An Empirical Study on Human Image Synthesis
Mar 08, 2024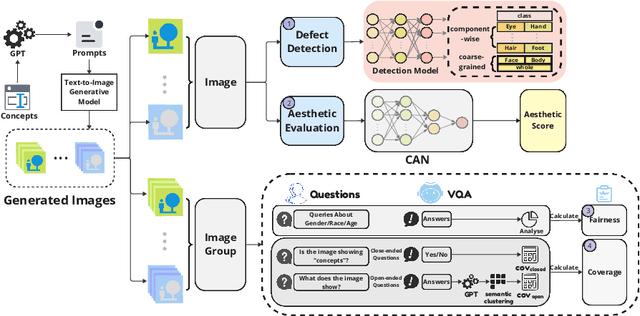
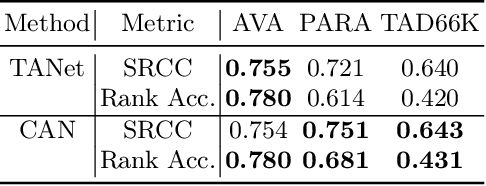
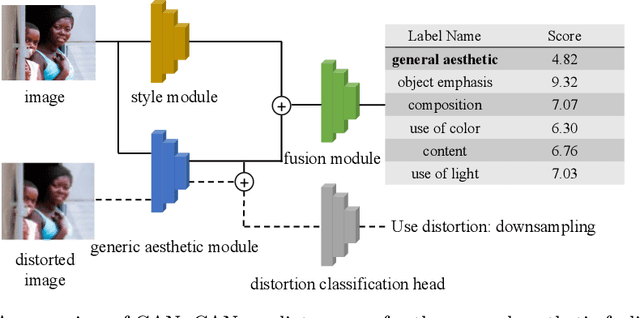
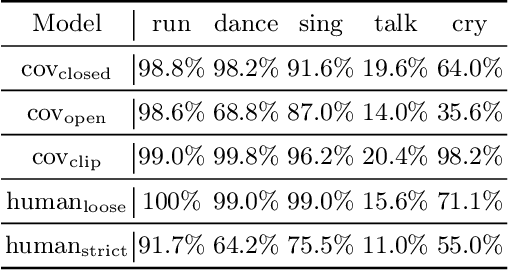
In this paper, we present an empirical study introducing a nuanced evaluation framework for text-to-image (T2I) generative models, applied to human image synthesis. Our framework categorizes evaluations into two distinct groups: first, focusing on image qualities such as aesthetics and realism, and second, examining text conditions through concept coverage and fairness. We introduce an innovative aesthetic score prediction model that assesses the visual appeal of generated images and unveils the first dataset marked with low-quality regions in generated human images to facilitate automatic defect detection. Our exploration into concept coverage probes the model's effectiveness in interpreting and rendering text-based concepts accurately, while our analysis of fairness reveals biases in model outputs, with an emphasis on gender, race, and age. While our study is grounded in human imagery, this dual-faceted approach is designed with the flexibility to be applicable to other forms of image generation, enhancing our understanding of generative models and paving the way to the next generation of more sophisticated, contextually aware, and ethically attuned generative models. We will release our code, the data used for evaluating generative models and the dataset annotated with defective areas soon.
A Method for Target Detection Based on Mmw Radar and Vision Fusion
Mar 25, 2024An efficient and accurate traffic monitoring system often takes advantages of multi-sensor detection to ensure the safety of urban traffic, promoting the accuracy and robustness of target detection and tracking. A method for target detection using Radar-Vision Fusion Path Aggregation Fully Convolutional One-Stage Network (RV-PAFCOS) is proposed in this paper, which is extended from Fully Convolutional One-Stage Network (FCOS) by introducing the modules of radar image processing branches, radar-vision fusion and path aggregation. The radar image processing branch mainly focuses on the image modeling based on the spatiotemporal calibration of millimeter-wave (mmw) radar and cameras, taking the conversion of radar point clouds to radar images. The fusion module extracts features of radar and optical images based on the principle of spatial attention stitching criterion. The path aggregation module enhances the reuse of feature layers, combining the positional information of shallow feature maps with deep semantic information, to obtain better detection performance for both large and small targets. Through the experimental analysis, the method proposed in this paper can effectively fuse the mmw radar and vision perceptions, showing good performance in traffic target detection.
COVID-19 detection from pulmonary CT scans using a novel EfficientNet with attention mechanism
Mar 27, 2024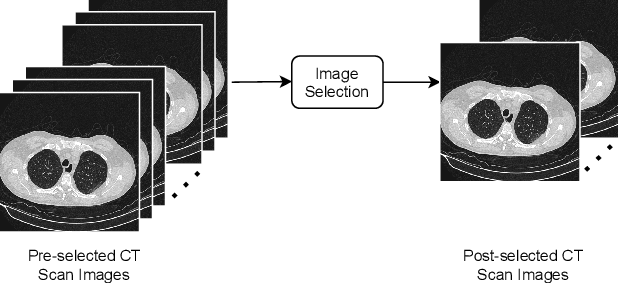
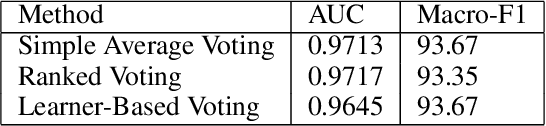

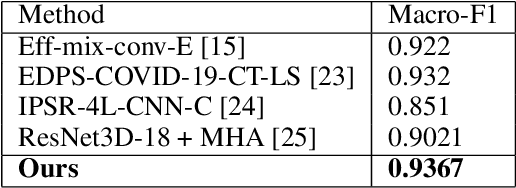
Manual analysis and diagnosis of COVID-19 through the examination of Computed Tomography (CT) images of the lungs can be time-consuming and result in errors, especially given high volume of patients and numerous images per patient. So, we address the need for automation of this task by developing a new deep learning model-based pipeline. Our motivation was sparked by the CVPR Workshop on "Domain Adaptation, Explainability and Fairness in AI for Medical Image Analysis", more specifically, the "COVID-19 Diagnosis Competition (DEF-AI-MIA COV19D)" under the same Workshop. This challenge provides an opportunity to assess our proposed pipeline for COVID-19 detection from CT scan images. The same pipeline incorporates the original EfficientNet, but with an added Attention Mechanism: EfficientNet-AM. Also, unlike the traditional/past pipelines, which relied on a pre-processing step, our pipeline takes the raw selected input images without any such step, except for an image-selection step to simply reduce the number of CT images required for training and/or testing. Moreover, our pipeline is computationally efficient, as, for example, it does not incorporate a decoder for segmenting the lungs. It also does not combine different backbones nor combine RNN with a backbone, as other pipelines in the past did. Nevertheless, our pipeline still outperforms all approaches presented by other teams in last year's instance of the same challenge, at least based on the validation subset of the competition dataset.
Garment3DGen: 3D Garment Stylization and Texture Generation
Mar 27, 2024We introduce Garment3DGen a new method to synthesize 3D garment assets from a base mesh given a single input image as guidance. Our proposed approach allows users to generate 3D textured clothes based on both real and synthetic images, such as those generated by text prompts. The generated assets can be directly draped and simulated on human bodies. First, we leverage the recent progress of image to 3D diffusion methods to generate 3D garment geometries. However, since these geometries cannot be utilized directly for downstream tasks, we propose to use them as pseudo ground-truth and set up a mesh deformation optimization procedure that deforms a base template mesh to match the generated 3D target. Second, we introduce carefully designed losses that allow the input base mesh to freely deform towards the desired target, yet preserve mesh quality and topology such that they can be simulated. Finally, a texture estimation module generates high-fidelity texture maps that are globally and locally consistent and faithfully capture the input guidance, allowing us to render the generated 3D assets. With Garment3DGen users can generate the textured 3D garment of their choice without the need of artist intervention. One can provide a textual prompt describing the garment they desire to generate a simulation-ready 3D asset. We present a plethora of quantitative and qualitative comparisons on various assets both real and generated and provide use-cases of how one can generate simulation-ready 3D garments.
Text-to-Image Diffusion Models are Great Sketch-Photo Matchmakers
Mar 12, 2024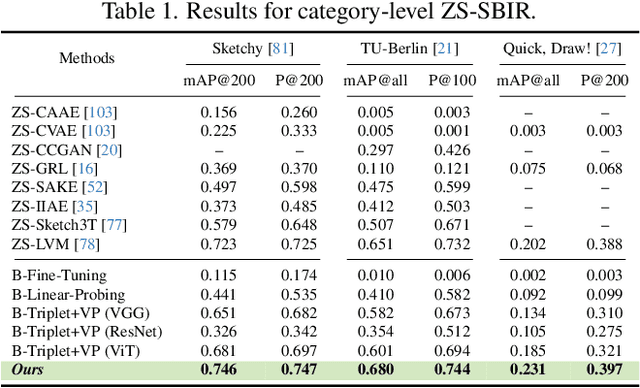
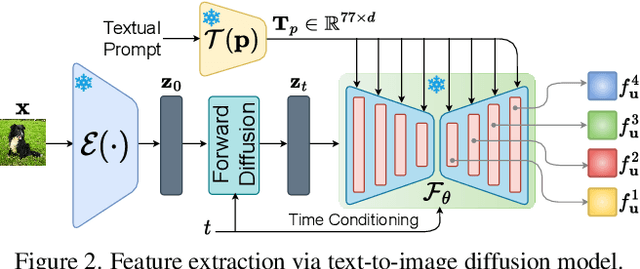


This paper, for the first time, explores text-to-image diffusion models for Zero-Shot Sketch-based Image Retrieval (ZS-SBIR). We highlight a pivotal discovery: the capacity of text-to-image diffusion models to seamlessly bridge the gap between sketches and photos. This proficiency is underpinned by their robust cross-modal capabilities and shape bias, findings that are substantiated through our pilot studies. In order to harness pre-trained diffusion models effectively, we introduce a straightforward yet powerful strategy focused on two key aspects: selecting optimal feature layers and utilising visual and textual prompts. For the former, we identify which layers are most enriched with information and are best suited for the specific retrieval requirements (category-level or fine-grained). Then we employ visual and textual prompts to guide the model's feature extraction process, enabling it to generate more discriminative and contextually relevant cross-modal representations. Extensive experiments on several benchmark datasets validate significant performance improvements.
Iterative Learning for Joint Image Denoising and Motion Artifact Correction of 3D Brain MRI
Mar 13, 2024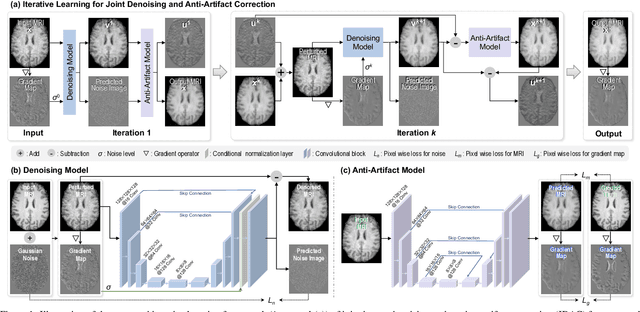

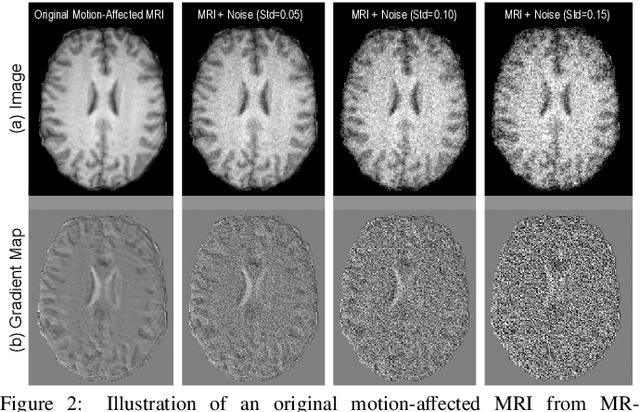
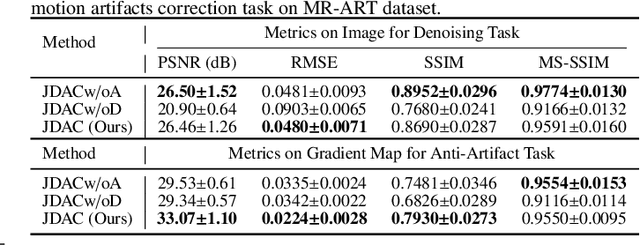
Image noise and motion artifacts greatly affect the quality of brain MRI and negatively influence downstream medical image analysis. Previous studies often focus on 2D methods that process each volumetric MR image slice-by-slice, thus losing important 3D anatomical information. Additionally, these studies generally treat image denoising and artifact correction as two standalone tasks, without considering their potential relationship, especially on low-quality images where severe noise and motion artifacts occur simultaneously. To address these issues, we propose a Joint image Denoising and motion Artifact Correction (JDAC) framework via iterative learning to handle noisy MRIs with motion artifacts, consisting of an adaptive denoising model and an anti-artifact model. In the adaptive denoising model, we first design a novel noise level estimation strategy, and then adaptively reduce the noise through a U-Net backbone with feature normalization conditioning on the estimated noise variance. The anti-artifact model employs another U-Net for eliminating motion artifacts, incorporating a novel gradient-based loss function designed to maintain the integrity of brain anatomy during the motion correction process. These two models are iteratively employed for joint image denoising and artifact correction through an iterative learning framework. An early stopping strategy depending on noise level estimation is applied to accelerate the iteration process. The denoising model is trained with 9,544 T1-weighted MRIs with manually added Gaussian noise as supervision. The anti-artifact model is trained on 552 T1-weighted MRIs with motion artifacts and paired motion-free images. Experimental results on a public dataset and a clinical study suggest the effectiveness of JDAC in both tasks of denoising and motion artifact correction, compared with several state-of-the-art methods.
Diffusion-based Iterative Counterfactual Explanations for Fetal Ultrasound Image Quality Assessment
Mar 13, 2024
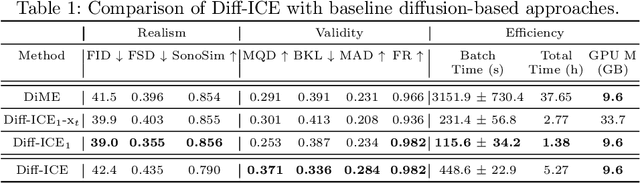
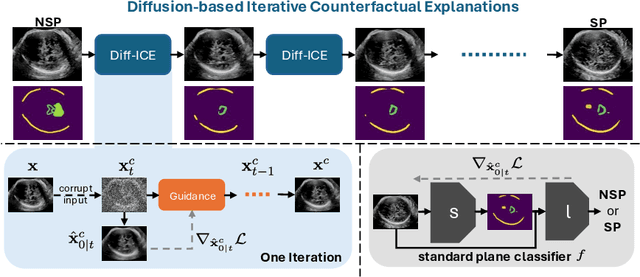
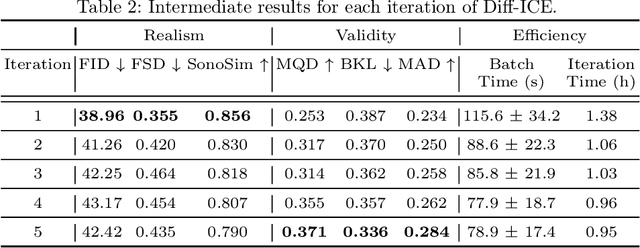
Obstetric ultrasound image quality is crucial for accurate diagnosis and monitoring of fetal health. However, producing high-quality standard planes is difficult, influenced by the sonographer's expertise and factors like the maternal BMI or the fetus dynamics. In this work, we propose using diffusion-based counterfactual explainable AI to generate realistic high-quality standard planes from low-quality non-standard ones. Through quantitative and qualitative evaluation, we demonstrate the effectiveness of our method in producing plausible counterfactuals of increased quality. This shows future promise both for enhancing training of clinicians by providing visual feedback, as well as for improving image quality and, consequently, downstream diagnosis and monitoring.
Channel-wise Feature Decorrelation for Enhanced Learned Image Compression
Mar 16, 2024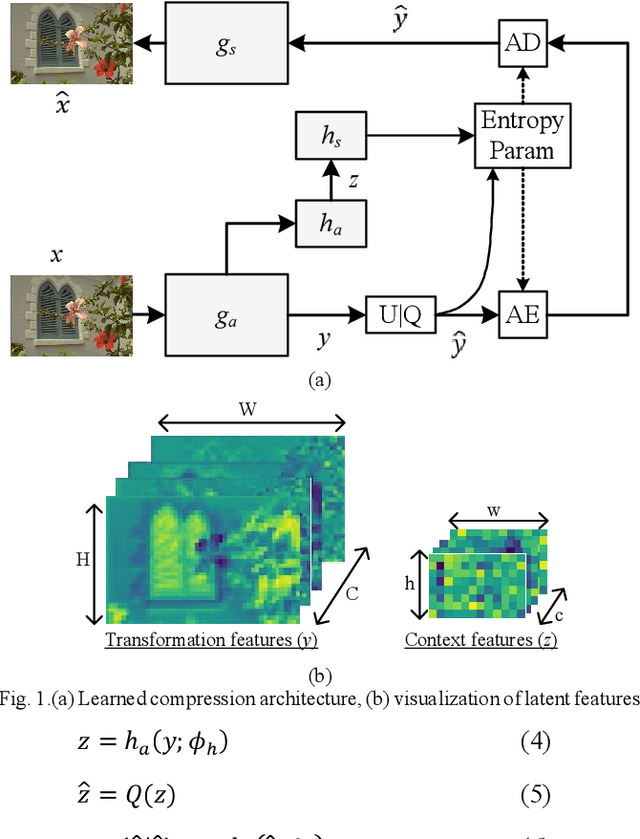
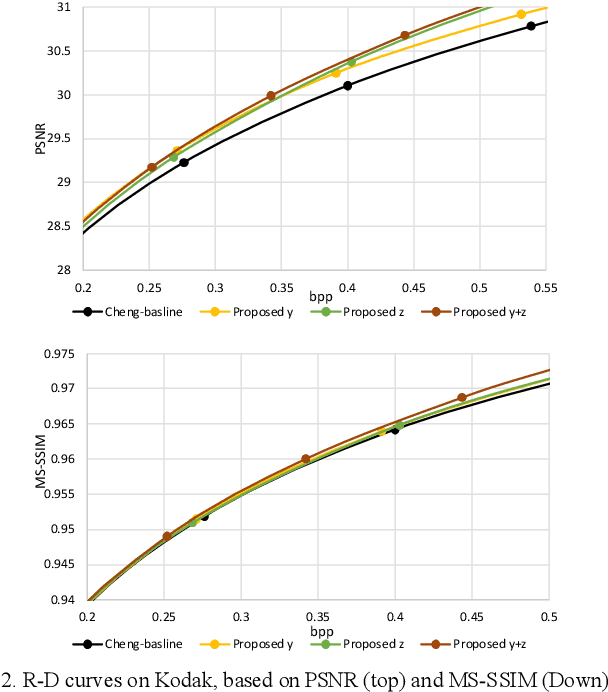
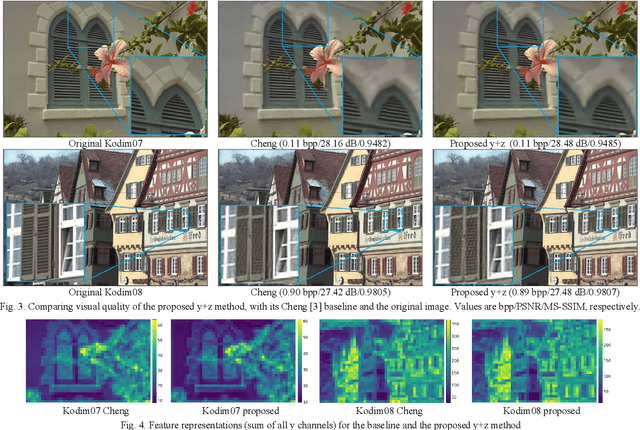
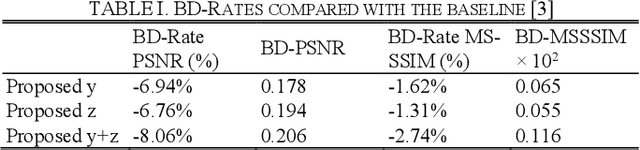
The emerging Learned Compression (LC) replaces the traditional codec modules with Deep Neural Networks (DNN), which are trained end-to-end for rate-distortion performance. This approach is considered as the future of image/video compression, and major efforts have been dedicated to improving its compression efficiency. However, most proposed works target compression efficiency by employing more complex DNNS, which contributes to higher computational complexity. Alternatively, this paper proposes to improve compression by fully exploiting the existing DNN capacity. To do so, the latent features are guided to learn a richer and more diverse set of features, which corresponds to better reconstruction. A channel-wise feature decorrelation loss is designed and is integrated into the LC optimization. Three strategies are proposed and evaluated, which optimize (1) the transformation network, (2) the context model, and (3) both networks. Experimental results on two established LC methods show that the proposed method improves the compression with a BD-Rate of up to 8.06%, with no added complexity. The proposed solution can be applied as a plug-and-play solution to optimize any similar LC method.
Learn "No" to Say "Yes" Better: Improving Vision-Language Models via Negations
Mar 29, 2024
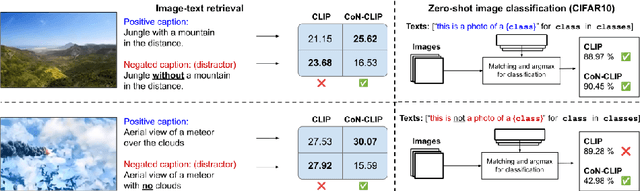

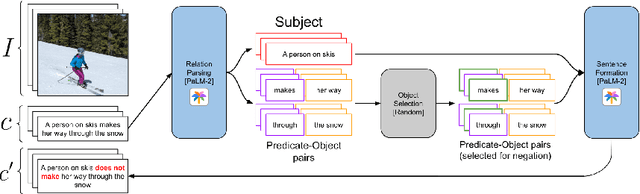
Existing vision-language models (VLMs) treat text descriptions as a unit, confusing individual concepts in a prompt and impairing visual semantic matching and reasoning. An important aspect of reasoning in logic and language is negations. This paper highlights the limitations of popular VLMs such as CLIP, at understanding the implications of negations, i.e., the effect of the word "not" in a given prompt. To enable evaluation of VLMs on fluent prompts with negations, we present CC-Neg, a dataset containing 228,246 images, true captions and their corresponding negated captions. Using CC-Neg along with modifications to the contrastive loss of CLIP, our proposed CoN-CLIP framework, has an improved understanding of negations. This training paradigm improves CoN-CLIP's ability to encode semantics reliably, resulting in 3.85% average gain in top-1 accuracy for zero-shot image classification across 8 datasets. Further, CoN-CLIP outperforms CLIP on challenging compositionality benchmarks such as SugarCREPE by 4.4%, showcasing emergent compositional understanding of objects, relations, and attributes in text. Overall, our work addresses a crucial limitation of VLMs by introducing a dataset and framework that strengthens semantic associations between images and text, demonstrating improved large-scale foundation models with significantly reduced computational cost, promoting efficiency and accessibility.