 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Real Time Egocentric Segment Captioning for The Blind and Visually Impaired in RGB-D Theatre Images
Aug 26, 2023
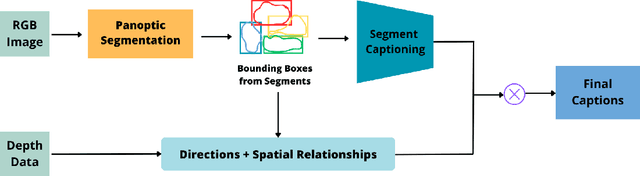
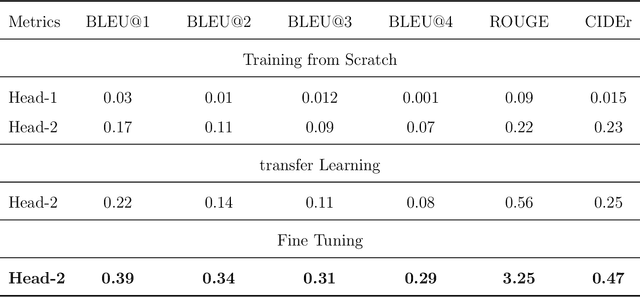
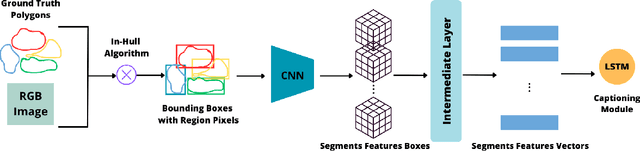

In recent years, image captioning and segmentation have emerged as crucial tasks in computer vision, with applications ranging from autonomous driving to content analysis. Although multiple solutions have emerged to help blind and visually impaired people move around their environment, few are applications that help them understand and rebuild a scene in their minds through text. Most built models focus on helping users move and avoid obstacles, restricting the number of environments blind and visually impaired people can be in. In this paper, we will propose an approach that helps them understand their surroundings using image captioning. The particularity of our research is that we offer them descriptions with positions of regions and objects regarding them (left, right, front), as well as positional relationships between regions, while we aim to give them access to theatre plays by applying the solution to our TS-RGBD dataset.
LUT-GCE: Lookup Table Global Curve Estimation for Fast Low-light Image Enhancement
Jun 30, 2023
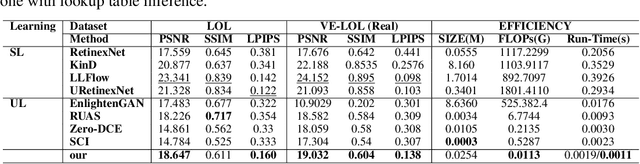
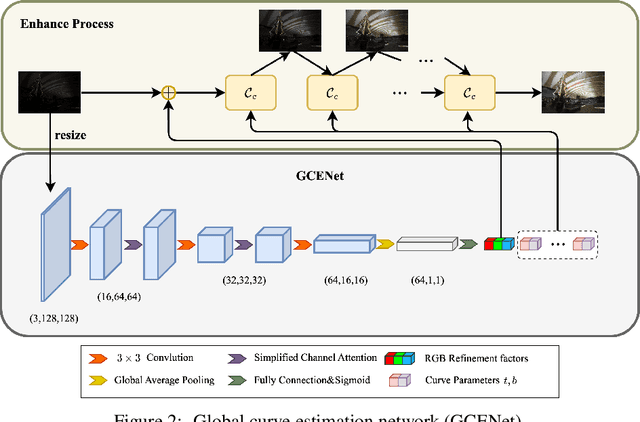
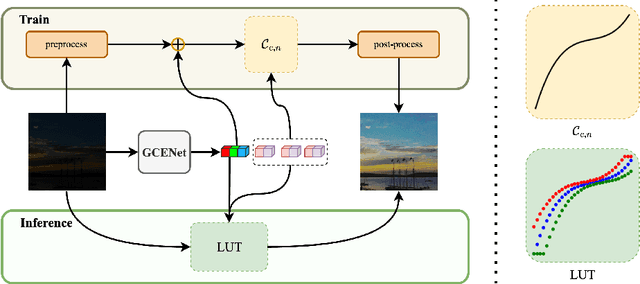
We present an effective and efficient approach for low-light image enhancement, named Lookup Table Global Curve Estimation (LUT-GCE). In contrast to existing curve-based methods with pixel-wise adjustment, we propose to estimate a global curve for the entire image that allows corrections for both under- and over-exposure. Specifically, we develop a novel cubic curve formulation for light enhancement, which enables an image-adaptive and pixel-independent curve for the range adjustment of an image. We then propose a global curve estimation network (GCENet), a very light network with only 25.4k parameters. To further speed up the inference speed, a lookup table method is employed for fast retrieval. In addition, a novel histogram smoothness loss is designed to enable zero-shot learning, which is able to improve the contrast of the image and recover clearer details. Quantitative and qualitative results demonstrate the effectiveness of the proposed approach. Furthermore, our approach outperforms the state of the art in terms of inference speed, especially on high-definition images (e.g., 1080p and 4k).
Cross-Modality Proposal-guided Feature Mining for Unregistered RGB-Thermal Pedestrian Detection
Aug 23, 2023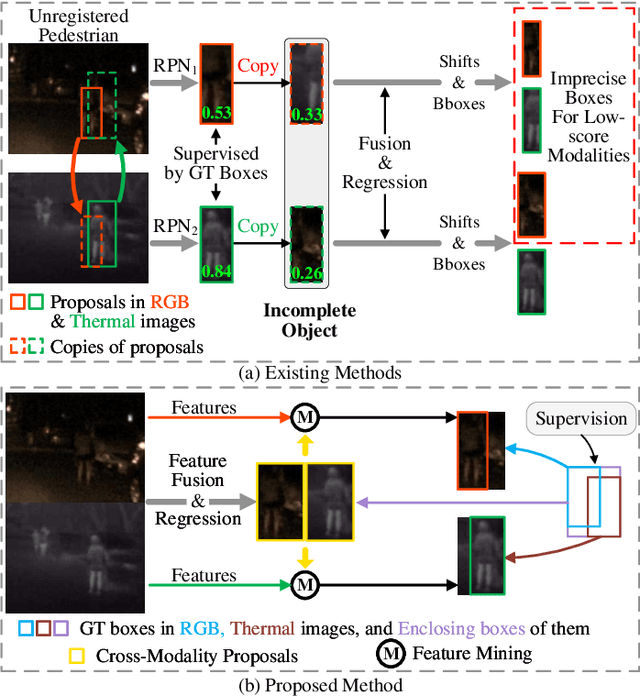
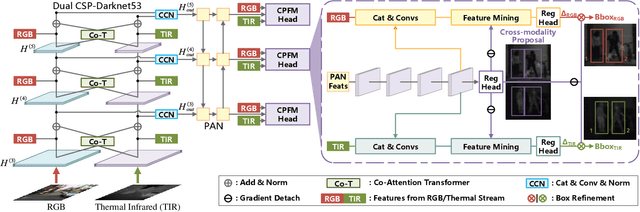
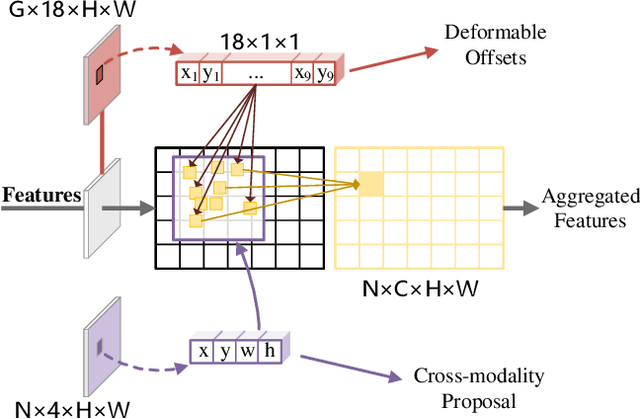
RGB-Thermal (RGB-T) pedestrian detection aims to locate the pedestrians in RGB-T image pairs to exploit the complementation between the two modalities for improving detection robustness in extreme conditions. Most existing algorithms assume that the RGB-T image pairs are well registered, while in the real world they are not aligned ideally due to parallax or different field-of-view of the cameras. The pedestrians in misaligned image pairs may locate at different positions in two images, which results in two challenges: 1) how to achieve inter-modality complementation using spatially misaligned RGB-T pedestrian patches, and 2) how to recognize the unpaired pedestrians at the boundary. To deal with these issues, we propose a new paradigm for unregistered RGB-T pedestrian detection, which predicts two separate pedestrian locations in the RGB and thermal images, respectively. Specifically, we propose a cross-modality proposal-guided feature mining (CPFM) mechanism to extract the two precise fusion features for representing the pedestrian in the two modalities, even if the RGB-T image pair is unaligned. It enables us to effectively exploit the complementation between the two modalities. With the CPFM mechanism, we build a two-stream dense detector; it predicts the two pedestrian locations in the two modalities based on the corresponding fusion feature mined by the CPFM mechanism. Besides, we design a data augmentation method, named Homography, to simulate the discrepancy in scales and views between images. We also investigate two non-maximum suppression (NMS) methods for post-processing. Favorable experimental results demonstrate the effectiveness and robustness of our method in dealing with unregistered pedestrians with different shifts.
Masking Strategies for Background Bias Removal in Computer Vision Models
Aug 23, 2023
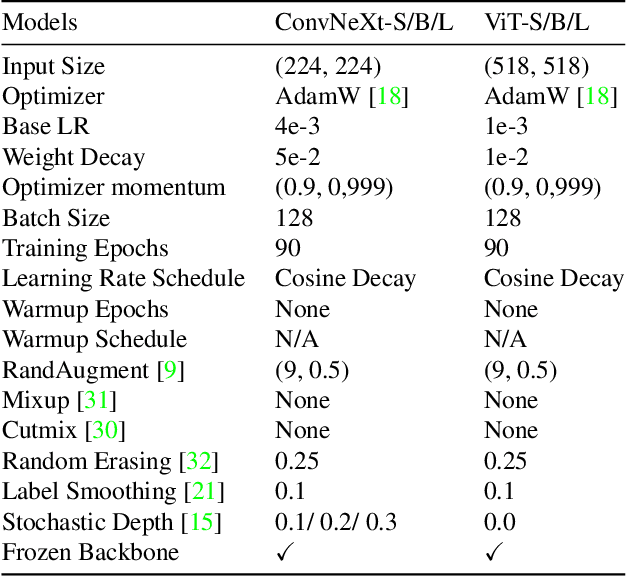
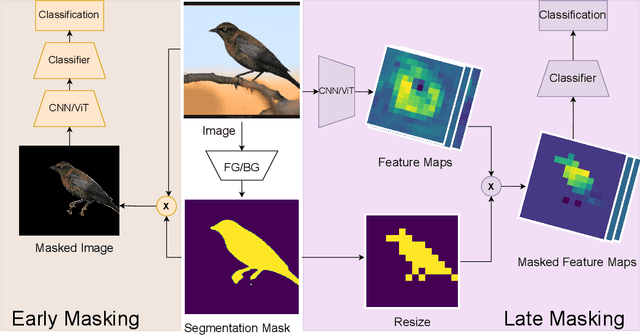
Models for fine-grained image classification tasks, where the difference between some classes can be extremely subtle and the number of samples per class tends to be low, are particularly prone to picking up background-related biases and demand robust methods to handle potential examples with out-of-distribution (OOD) backgrounds. To gain deeper insights into this critical problem, our research investigates the impact of background-induced bias on fine-grained image classification, evaluating standard backbone models such as Convolutional Neural Network (CNN) and Vision Transformers (ViT). We explore two masking strategies to mitigate background-induced bias: Early masking, which removes background information at the (input) image level, and late masking, which selectively masks high-level spatial features corresponding to the background. Extensive experiments assess the behavior of CNN and ViT models under different masking strategies, with a focus on their generalization to OOD backgrounds. The obtained findings demonstrate that both proposed strategies enhance OOD performance compared to the baseline models, with early masking consistently exhibiting the best OOD performance. Notably, a ViT variant employing GAP-Pooled Patch token-based classification combined with early masking achieves the highest OOD robustness.
Transfer Learning for Microstructure Segmentation with CS-UNet: A Hybrid Algorithm with Transformer and CNN Encoders
Aug 26, 2023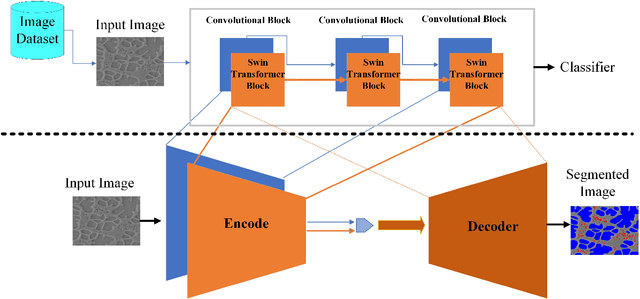

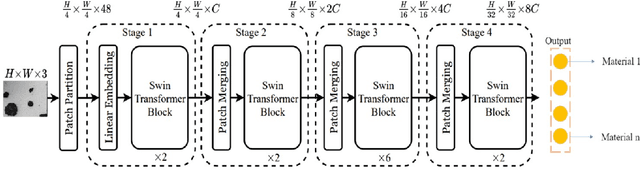
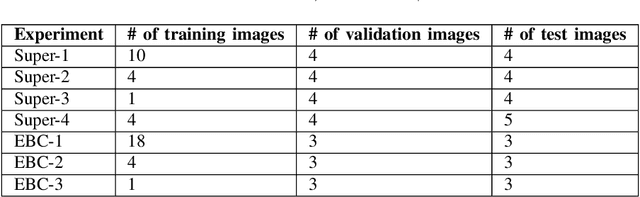
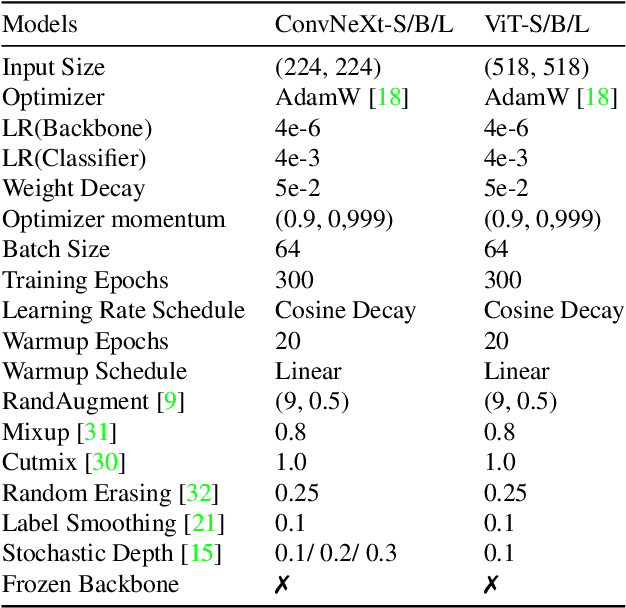
Transfer learning improves the performance of deep learning models by initializing them with parameters pre-trained on larger datasets. Intuitively, transfer learning is more effective when pre-training is on the in-domain datasets. A recent study by NASA has demonstrated that the microstructure segmentation with encoder-decoder algorithms benefits more from CNN encoders pre-trained on microscopy images than from those pre-trained on natural images. However, CNN models only capture the local spatial relations in images. In recent years, attention networks such as Transformers are increasingly used in image analysis to capture the long-range relations between pixels. In this study, we compare the segmentation performance of Transformer and CNN models pre-trained on microscopy images with those pre-trained on natural images. Our result partially confirms the NASA study that the segmentation performance of out-of-distribution images (taken under different imaging and sample conditions) is significantly improved when pre-training on microscopy images. However, the performance gain for one-shot and few-shot learning is more modest with Transformers. We also find that for image segmentation, the combination of pre-trained Transformers and CNN encoders are consistently better than pre-trained CNN encoders alone. Our dataset (of about 50,000 images) combines the public portion of the NASA dataset with additional images we collected. Even with much less training data, our pre-trained models have significantly better performance for image segmentation. This result suggests that Transformers and CNN complement each other and when pre-trained on microscopy images, they are more beneficial to the downstream tasks.
CoDeF: Content Deformation Fields for Temporally Consistent Video Processing
Aug 15, 2023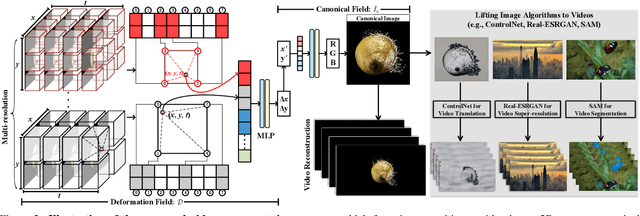



We present the content deformation field CoDeF as a new type of video representation, which consists of a canonical content field aggregating the static contents in the entire video and a temporal deformation field recording the transformations from the canonical image (i.e., rendered from the canonical content field) to each individual frame along the time axis.Given a target video, these two fields are jointly optimized to reconstruct it through a carefully tailored rendering pipeline.We advisedly introduce some regularizations into the optimization process, urging the canonical content field to inherit semantics (e.g., the object shape) from the video.With such a design, CoDeF naturally supports lifting image algorithms for video processing, in the sense that one can apply an image algorithm to the canonical image and effortlessly propagate the outcomes to the entire video with the aid of the temporal deformation field.We experimentally show that CoDeF is able to lift image-to-image translation to video-to-video translation and lift keypoint detection to keypoint tracking without any training.More importantly, thanks to our lifting strategy that deploys the algorithms on only one image, we achieve superior cross-frame consistency in processed videos compared to existing video-to-video translation approaches, and even manage to track non-rigid objects like water and smog.Project page can be found at https://qiuyu96.github.io/CoDeF/.
Autonomous damage assessment of structural columns using low-cost micro aerial vehicles and multi-view computer vision
Aug 30, 2023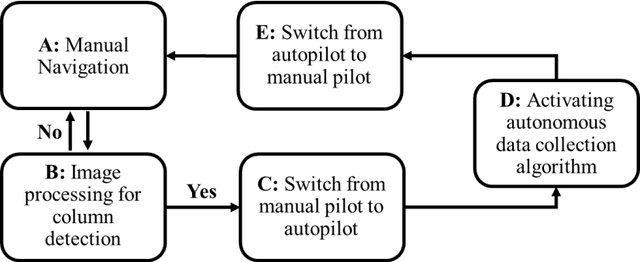
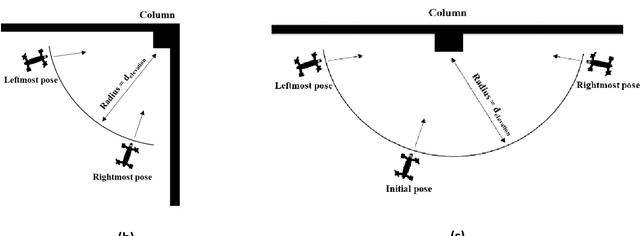

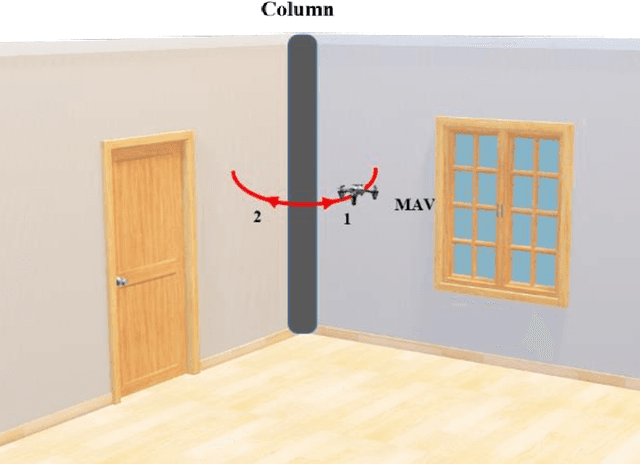
Structural columns are the crucial load-carrying components of buildings and bridges. Early detection of column damage is important for the assessment of the residual performance and the prevention of system-level collapse. This research proposes an innovative end-to-end micro aerial vehicles (MAVs)-based approach to automatically scan and inspect columns. First, an MAV-based automatic image collection method is proposed. The MAV is programmed to sense the structural columns and their surrounding environment. During the navigation, the MAV first detects and approaches the structural columns. Then, it starts to collect image data at multiple viewpoints around every detected column. Second, the collected images will be used to assess the damage types and damage locations. Third, the damage state of the structural column will be determined by fusing the evaluation outcomes from multiple camera views. In this study, reinforced concrete (RC) columns are selected to demonstrate the effectiveness of the approach. Experimental results indicate that the proposed MAV-based inspection approach can effectively collect images from multiple viewing angles, and accurately assess critical RC column damages. The approach improves the level of autonomy during the inspection. In addition, the evaluation outcomes are more comprehensive than the existing 2D vision methods. The concept of the proposed inspection approach can be extended to other structural columns such as bridge piers.
Diving into Darkness: A Dual-Modulated Framework for High-Fidelity Super-Resolution in Ultra-Dark Environments
Sep 11, 2023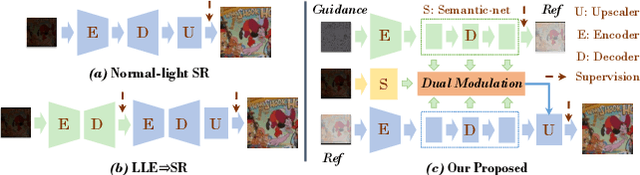
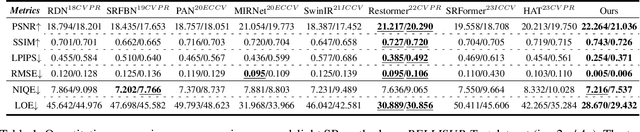


Super-resolution tasks oriented to images captured in ultra-dark environments is a practical yet challenging problem that has received little attention. Due to uneven illumination and low signal-to-noise ratio in dark environments, a multitude of problems such as lack of detail and color distortion may be magnified in the super-resolution process compared to normal-lighting environments. Consequently, conventional low-light enhancement or super-resolution methods, whether applied individually or in a cascaded manner for such problem, often encounter limitations in recovering luminance, color fidelity, and intricate details. To conquer these issues, this paper proposes a specialized dual-modulated learning framework that, for the first time, attempts to deeply dissect the nature of the low-light super-resolution task. Leveraging natural image color characteristics, we introduce a self-regularized luminance constraint as a prior for addressing uneven lighting. Expanding on this, we develop Illuminance-Semantic Dual Modulation (ISDM) components to enhance feature-level preservation of illumination and color details. Besides, instead of deploying naive up-sampling strategies, we design the Resolution-Sensitive Merging Up-sampler (RSMU) module that brings together different sampling modalities as substrates, effectively mitigating the presence of artifacts and halos. Comprehensive experiments showcases the applicability and generalizability of our approach to diverse and challenging ultra-low-light conditions, outperforming state-of-the-art methods with a notable improvement (i.e., $\uparrow$5\% in PSNR, and $\uparrow$43\% in LPIPS). Especially noteworthy is the 19-fold increase in the RMSE score, underscoring our method's exceptional generalization across different darkness levels. The code will be available online upon publication of the paper.
Synchronous Image-Label Diffusion Probability Model with Application to Stroke Lesion Segmentation on Non-contrast CT
Jul 18, 2023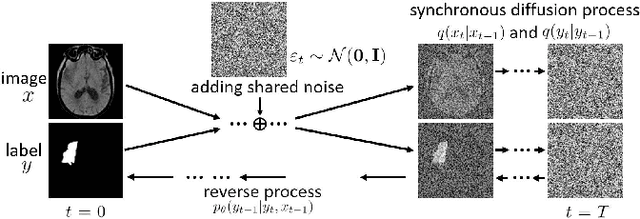
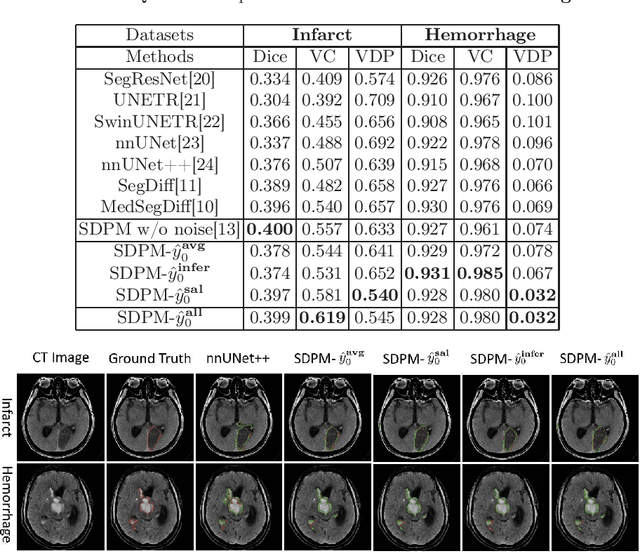
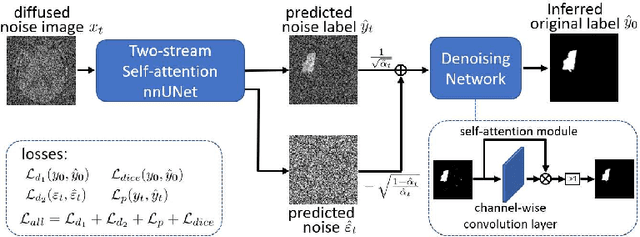
Stroke lesion volume is a key radiologic measurement for assessing the prognosis of Acute Ischemic Stroke (AIS) patients, which is challenging to be automatically measured on Non-Contrast CT (NCCT) scans. Recent diffusion probabilistic models have shown potentials of being used for image segmentation. In this paper, a novel Synchronous image-label Diffusion Probability Model (SDPM) is proposed for stroke lesion segmentation on NCCT using Markov diffusion process. The proposed SDPM is fully based on a Latent Variable Model (LVM), offering a complete probabilistic elaboration. An additional net-stream, parallel with a noise prediction stream, is introduced to obtain initial noisy label estimates for efficiently inferring the final labels. By optimizing the specified variational boundaries, the trained model can infer multiple label estimates for reference given the input images with noises. The proposed model was assessed on three stroke lesion datasets including one public and two private datasets. Compared to several U-net and transformer-based segmentation methods, our proposed SDPM model is able to achieve state-of-the-art performance. The code is publicly available.
Comparative Study of Visual SLAM-Based Mobile Robot Localization Using Fiducial Markers
Sep 08, 2023
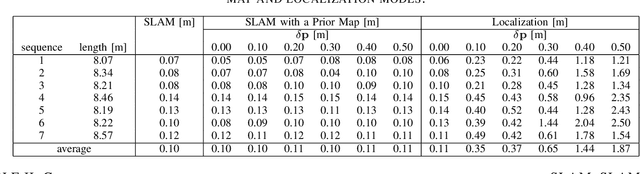
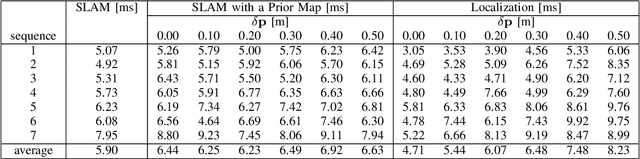
This paper presents a comparative study of three modes for mobile robot localization based on visual SLAM using fiducial markers (i.e., square-shaped artificial landmarks with a black-and-white grid pattern): SLAM, SLAM with a prior map, and localization with a prior map. The reason for comparing the SLAM-based approaches leveraging fiducial markers is because previous work has shown their superior performance over feature-only methods, with less computational burden compared to methods that use both feature and marker detection without compromising the localization performance. The evaluation is conducted using indoor image sequences captured with a hand-held camera containing multiple fiducial markers in the environment. The performance metrics include absolute trajectory error and runtime for the optimization process per frame. In particular, for the last two modes (SLAM and localization with a prior map), we evaluate their performances by perturbing the quality of prior map to study the extent to which each mode is tolerant to such perturbations. Hardware experiments show consistent trajectory error levels across the three modes, with the localization mode exhibiting the shortest runtime among them. Yet, with map perturbations, SLAM with a prior map maintains performance, while localization mode degrades in both aspects.