 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Unsupervised Image-to-Image Translation via Pre-trained StyleGAN2 Network
Oct 27, 2020
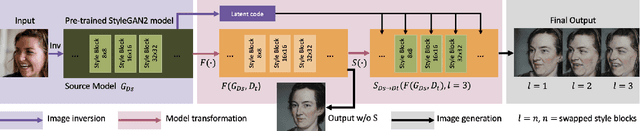



Image-to-Image (I2I) translation is a heated topic in academia, and it also has been applied in real-world industry for tasks like image synthesis, super-resolution, and colorization. However, traditional I2I translation methods train data in two or more domains together. This requires lots of computation resources. Moreover, the results are of lower quality, and they contain many more artifacts. The training process could be unstable when the data in different domains are not balanced, and modal collapse is more likely to happen. We proposed a new I2I translation method that generates a new model in the target domain via a series of model transformations on a pre-trained StyleGAN2 model in the source domain. After that, we proposed an inversion method to achieve the conversion between an image and its latent vector. By feeding the latent vector into the generated model, we can perform I2I translation between the source domain and target domain. Both qualitative and quantitative evaluations were conducted to prove that the proposed method can achieve outstanding performance in terms of image quality, diversity and semantic similarity to the input and reference images compared to state-of-the-art works.
Unsupervised Image-to-Image Translation with Stacked Cycle-Consistent Adversarial Networks
Jul 28, 2018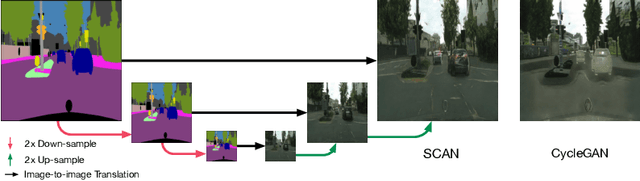
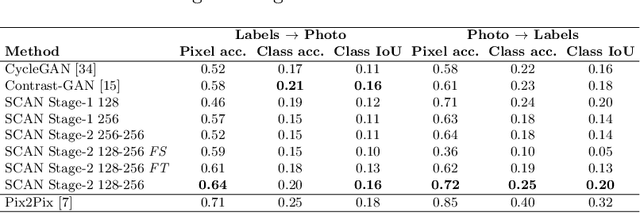
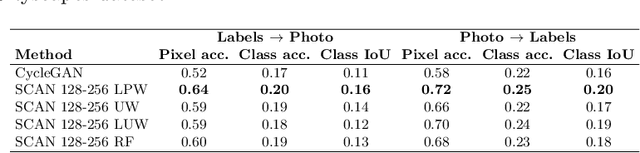
Recent studies on unsupervised image-to-image translation have made a remarkable progress by training a pair of generative adversarial networks with a cycle-consistent loss. However, such unsupervised methods may generate inferior results when the image resolution is high or the two image domains are of significant appearance differences, such as the translations between semantic layouts and natural images in the Cityscapes dataset. In this paper, we propose novel Stacked Cycle-Consistent Adversarial Networks (SCANs) by decomposing a single translation into multi-stage transformations, which not only boost the image translation quality but also enable higher resolution image-to-image translations in a coarse-to-fine manner. Moreover, to properly exploit the information from the previous stage, an adaptive fusion block is devised to learn a dynamic integration of the current stage's output and the previous stage's output. Experiments on multiple datasets demonstrate that our proposed approach can improve the translation quality compared with previous single-stage unsupervised methods.
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Aug 30, 2018
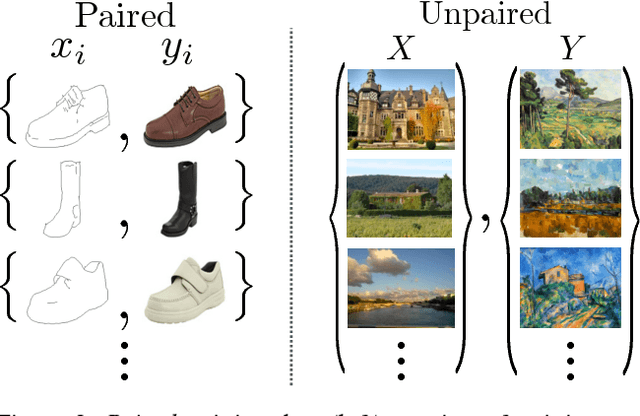
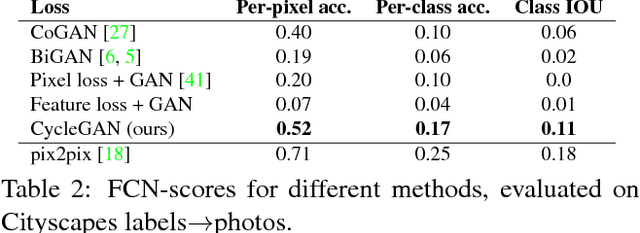
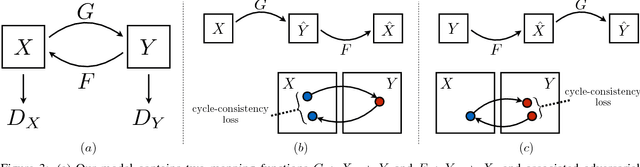
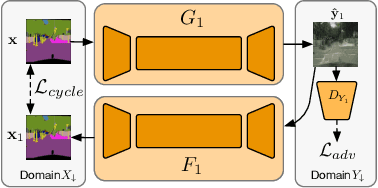
Image-to-image translation is a class of vision and graphics problems where the goal is to learn the mapping between an input image and an output image using a training set of aligned image pairs. However, for many tasks, paired training data will not be available. We present an approach for learning to translate an image from a source domain $X$ to a target domain $Y$ in the absence of paired examples. Our goal is to learn a mapping $G: X \rightarrow Y$ such that the distribution of images from $G(X)$ is indistinguishable from the distribution $Y$ using an adversarial loss. Because this mapping is highly under-constrained, we couple it with an inverse mapping $F: Y \rightarrow X$ and introduce a cycle consistency loss to push $F(G(X)) \approx X$ (and vice versa). Qualitative results are presented on several tasks where paired training data does not exist, including collection style transfer, object transfiguration, season transfer, photo enhancement, etc. Quantitative comparisons against several prior methods demonstrate the superiority of our approach.
Generative Transition Mechanism to Image-to-Image Translation via Encoded Transformation
Mar 09, 2021
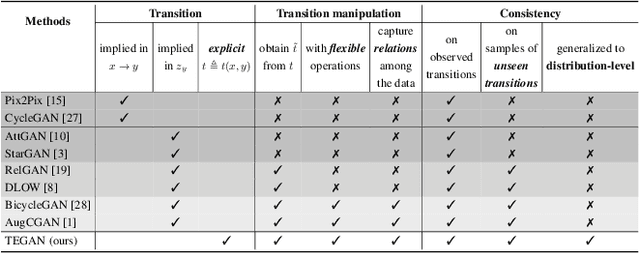
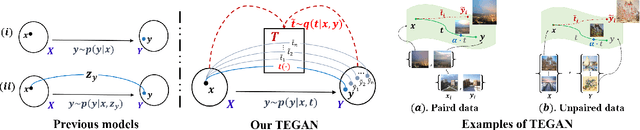
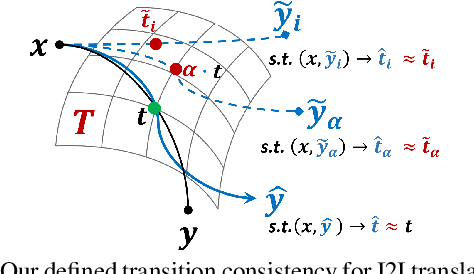
In this paper, we revisit the Image-to-Image (I2I) translation problem with transition consistency, namely the consistency defined on the conditional data mapping between each data pairs. Explicitly parameterizing each data mappings with a transition variable $t$, i.e., $x \overset{t(x,y)}{\mapsto}y$, we discover that existing I2I translation models mainly focus on maintaining consistency on results, e.g., image reconstruction or attribute prediction, named result consistency in our paper. This restricts their generalization ability to generate satisfactory results with unseen transitions in the test phase. Consequently, we propose to enforce both result consistency and transition consistency for I2I translation, to benefit the problem with a closer consistency between the input and output. To benefit the generalization ability of the translation model, we propose transition encoding to facilitate explicit regularization of these two {kinds} of consistencies on unseen transitions. We further generalize such explicitly regularized consistencies to distribution-level, thus facilitating a generalized overall consistency for I2I translation problems. With the above design, our proposed model, named Transition Encoding GAN (TEGAN), can poss superb generalization ability to generate realistic and semantically consistent translation results with unseen transitions in the test phase. It also provides a unified understanding of the existing GAN-based I2I transition models with our explicitly modeling of the data mapping, i.e., transition. Experiments on four different I2I translation tasks demonstrate the efficacy and generality of TEGAN.
Towards Realistic Underwater Dataset Generation and Color Restoration
Dec 16, 2022
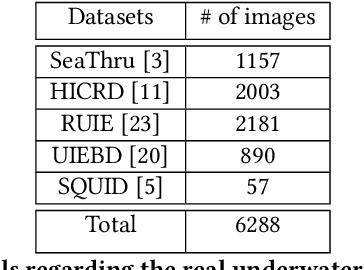

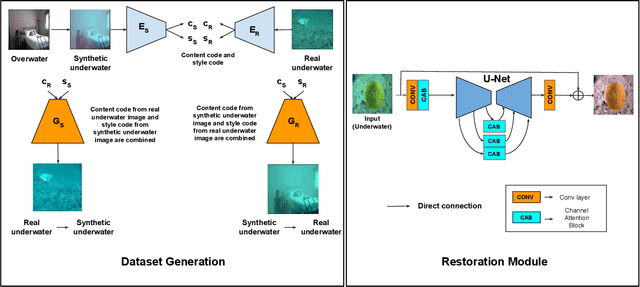
Recovery of true color from underwater images is an ill-posed problem. This is because the wide-band attenuation coefficients for the RGB color channels depend on object range, reflectance, etc. which are difficult to model. Also, there is backscattering due to suspended particles in water. Thus, most existing deep-learning based color restoration methods, which are trained on synthetic underwater datasets, do not perform well on real underwater data. This can be attributed to the fact that synthetic data cannot accurately represent real conditions. To address this issue, we use an image to image translation network to bridge the gap between the synthetic and real domains by translating images from synthetic underwater domain to real underwater domain. Using this multimodal domain adaptation technique, we create a dataset that can capture a diverse array of underwater conditions. We then train a simple but effective CNN based network on our domain adapted dataset to perform color restoration. Code and pre-trained models can be accessed at https://github.com/nehamjain10/TRUDGCR
Multi-Modality Image Super-Resolution using Generative Adversarial Networks
Jun 22, 2022



Over the past few years deep learning-based techniques such as Generative Adversarial Networks (GANs) have significantly improved solutions to image super-resolution and image-to-image translation problems. In this paper, we propose a solution to the joint problem of image super-resolution and multi-modality image-to-image translation. The problem can be stated as the recovery of a high-resolution image in a modality, given a low-resolution observation of the same image in an alternative modality. Our paper offers two models to address this problem and will be evaluated on the recovery of high-resolution day images given low-resolution night images of the same scene. Promising qualitative and quantitative results will be presented for each model.
Attack as the Best Defense: Nullifying Image-to-image Translation GANs via Limit-aware Adversarial Attack
Oct 06, 2021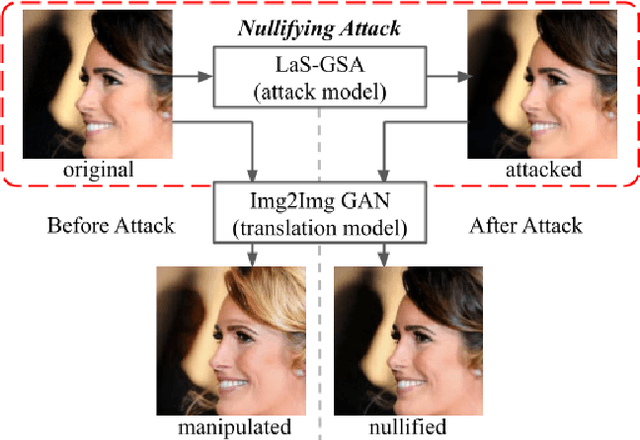
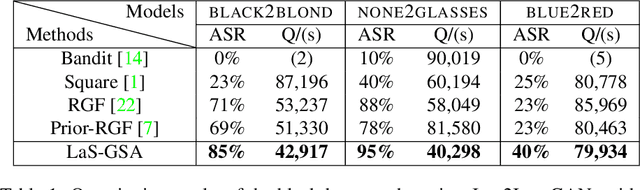
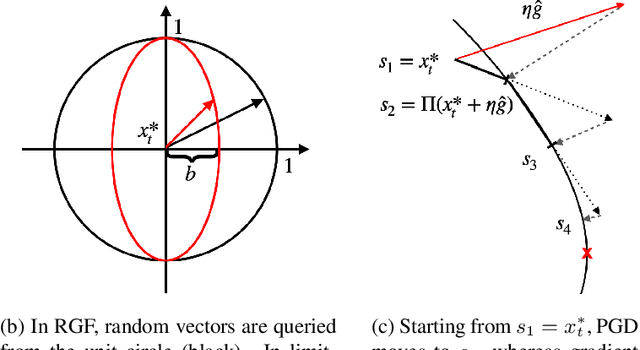

With the successful creation of high-quality image-to-image (Img2Img) translation GANs comes the non-ethical applications of DeepFake and DeepNude. Such misuses of img2img techniques present a challenging problem for society. In this work, we tackle the problem by introducing the Limit-Aware Self-Guiding Gradient Sliding Attack (LaS-GSA). LaS-GSA follows the Nullifying Attack to cancel the img2img translation process under a black-box setting. In other words, by processing input images with the proposed LaS-GSA before publishing, any targeted img2img GANs can be nullified, preventing the model from maliciously manipulating the images. To improve efficiency, we introduce the limit-aware random gradient-free estimation and the gradient sliding mechanism to estimate the gradient that adheres to the adversarial limit, i.e., the pixel value limitations of the adversarial example. Theoretical justifications validate how the above techniques prevent inefficiency caused by the adversarial limit in both the direction and the step length. Furthermore, an effective self-guiding prior is extracted solely from the threat model and the target image to efficiently leverage the prior information and guide the gradient estimation process. Extensive experiments demonstrate that LaS-GSA requires fewer queries to nullify the image translation process with higher success rates than 4 state-of-the-art black-box methods.
Semantic Example Guided Image-to-Image Translation
Oct 04, 2019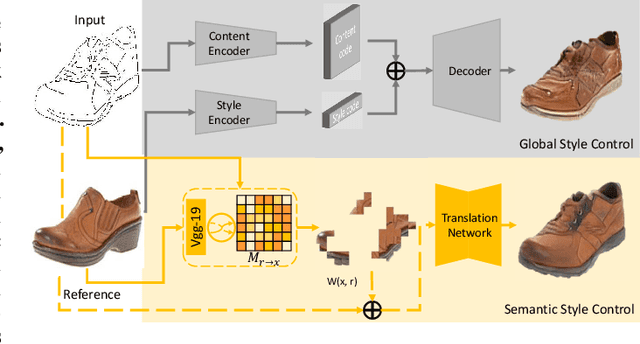


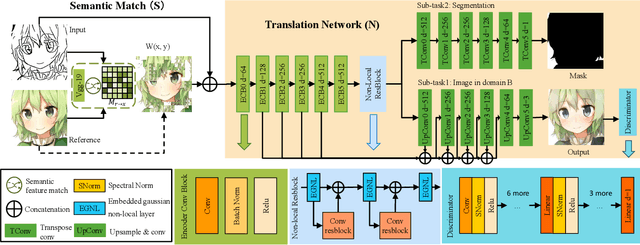
Many image-to-image (I2I) translation problems are in nature of high diversity that a single input may have various counterparts. Prior works proposed the multi-modal network that can build a many-to-many mapping between two visual domains. However, most of them are guided by sampled noises. Some others encode the reference images into a latent vector, by which the semantic information of the reference image will be washed away. In this work, we aim to provide a solution to control the output based on references semantically. Given a reference image and an input in another domain, a semantic matching is first performed between the two visual contents and generates the auxiliary image, which is explicitly encouraged to preserve semantic characteristics of the reference. A deep network then is used for I2I translation and the final outputs are expected to be semantically similar to both the input and the reference; however, no such paired data can satisfy that dual-similarity in a supervised fashion, so we build up a self-supervised framework to serve the training purpose. We improve the quality and diversity of the outputs by employing non-local blocks and a multi-task architecture. We assess the proposed method through extensive qualitative and quantitative evaluations and also presented comparisons with several state-of-art models.