 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgefacial recognition
Facial recognition is an AI-based technique for identifying or confirming an individual's identity using their face. It maps facial features from an image or video and then compares the information with a collection of known faces to find a match.
Papers and Code
MOL: Joint Estimation of Micro-Expression, Optical Flow, and Landmark via Transformer-Graph-Style Convolution
Jun 17, 2025


Facial micro-expression recognition (MER) is a challenging problem, due to transient and subtle micro-expression (ME) actions. Most existing methods depend on hand-crafted features, key frames like onset, apex, and offset frames, or deep networks limited by small-scale and low-diversity datasets. In this paper, we propose an end-to-end micro-action-aware deep learning framework with advantages from transformer, graph convolution, and vanilla convolution. In particular, we propose a novel F5C block composed of fully-connected convolution and channel correspondence convolution to directly extract local-global features from a sequence of raw frames, without the prior knowledge of key frames. The transformer-style fully-connected convolution is proposed to extract local features while maintaining global receptive fields, and the graph-style channel correspondence convolution is introduced to model the correlations among feature patterns. Moreover, MER, optical flow estimation, and facial landmark detection are jointly trained by sharing the local-global features. The two latter tasks contribute to capturing facial subtle action information for MER, which can alleviate the impact of insufficient training data. Extensive experiments demonstrate that our framework (i) outperforms the state-of-the-art MER methods on CASME II, SAMM, and SMIC benchmarks, (ii) works well for optical flow estimation and facial landmark detection, and (iii) can capture facial subtle muscle actions in local regions associated with MEs. The code is available at https://github.com/CYF-cuber/MOL.
Attributes Shape the Embedding Space of Face Recognition Models
Jul 15, 2025Face Recognition (FR) tasks have made significant progress with the advent of Deep Neural Networks, particularly through margin-based triplet losses that embed facial images into high-dimensional feature spaces. During training, these contrastive losses focus exclusively on identity information as labels. However, we observe a multiscale geometric structure emerging in the embedding space, influenced by interpretable facial (e.g., hair color) and image attributes (e.g., contrast). We propose a geometric approach to describe the dependence or invariance of FR models to these attributes and introduce a physics-inspired alignment metric. We evaluate the proposed metric on controlled, simplified models and widely used FR models fine-tuned with synthetic data for targeted attribute augmentation. Our findings reveal that the models exhibit varying degrees of invariance across different attributes, providing insight into their strengths and weaknesses and enabling deeper interpretability. Code available here: https://github.com/mantonios107/attrs-fr-embs}{https://github.com/mantonios107/attrs-fr-embs
Boosting Micro-Expression Analysis via Prior-Guided Video-Level Regression
Aug 26, 2025Micro-expressions (MEs) are involuntary, low-intensity, and short-duration facial expressions that often reveal an individual's genuine thoughts and emotions. Most existing ME analysis methods rely on window-level classification with fixed window sizes and hard decisions, which limits their ability to capture the complex temporal dynamics of MEs. Although recent approaches have adopted video-level regression frameworks to address some of these challenges, interval decoding still depends on manually predefined, window-based methods, leaving the issue only partially mitigated. In this paper, we propose a prior-guided video-level regression method for ME analysis. We introduce a scalable interval selection strategy that comprehensively considers the temporal evolution, duration, and class distribution characteristics of MEs, enabling precise spotting of the onset, apex, and offset phases. In addition, we introduce a synergistic optimization framework, in which the spotting and recognition tasks share parameters except for the classification heads. This fully exploits complementary information, makes more efficient use of limited data, and enhances the model's capability. Extensive experiments on multiple benchmark datasets demonstrate the state-of-the-art performance of our method, with an STRS of 0.0562 on CAS(ME)$^3$ and 0.2000 on SAMMLV. The code is available at https://github.com/zizheng-guo/BoostingVRME.
Degradation-Agnostic Statistical Facial Feature Transformation for Blind Face Restoration in Adverse Weather Conditions
Jul 10, 2025With the increasing deployment of intelligent CCTV systems in outdoor environments, there is a growing demand for face recognition systems optimized for challenging weather conditions. Adverse weather significantly degrades image quality, which in turn reduces recognition accuracy. Although recent face image restoration (FIR) models based on generative adversarial networks (GANs) and diffusion models have shown progress, their performance remains limited due to the lack of dedicated modules that explicitly address weather-induced degradations. This leads to distorted facial textures and structures. To address these limitations, we propose a novel GAN-based blind FIR framework that integrates two key components: local Statistical Facial Feature Transformation (SFFT) and Degradation-Agnostic Feature Embedding (DAFE). The local SFFT module enhances facial structure and color fidelity by aligning the local statistical distributions of low-quality (LQ) facial regions with those of high-quality (HQ) counterparts. Complementarily, the DAFE module enables robust statistical facial feature extraction under adverse weather conditions by aligning LQ and HQ encoder representations, thereby making the restoration process adaptive to severe weather-induced degradations. Experimental results demonstrate that the proposed degradation-agnostic SFFT model outperforms existing state-of-the-art FIR methods based on GAN and diffusion models, particularly in suppressing texture distortions and accurately reconstructing facial structures. Furthermore, both the SFFT and DAFE modules are empirically validated in enhancing structural fidelity and perceptual quality in face restoration under challenging weather scenarios.
OPEN: A Benchmark Dataset and Baseline for Older Adult Patient Engagement Recognition in Virtual Rehabilitation Learning Environments
Jul 23, 2025Engagement in virtual learning is essential for participant satisfaction, performance, and adherence, particularly in online education and virtual rehabilitation, where interactive communication plays a key role. Yet, accurately measuring engagement in virtual group settings remains a challenge. There is increasing interest in using artificial intelligence (AI) for large-scale, real-world, automated engagement recognition. While engagement has been widely studied in younger academic populations, research and datasets focused on older adults in virtual and telehealth learning settings remain limited. Existing methods often neglect contextual relevance and the longitudinal nature of engagement across sessions. This paper introduces OPEN (Older adult Patient ENgagement), a novel dataset supporting AI-driven engagement recognition. It was collected from eleven older adults participating in weekly virtual group learning sessions over six weeks as part of cardiac rehabilitation, producing over 35 hours of data, making it the largest dataset of its kind. To protect privacy, raw video is withheld; instead, the released data include facial, hand, and body joint landmarks, along with affective and behavioral features extracted from video. Annotations include binary engagement states, affective and behavioral labels, and context-type indicators, such as whether the instructor addressed the group or an individual. The dataset offers versions with 5-, 10-, 30-second, and variable-length samples. To demonstrate utility, multiple machine learning and deep learning models were trained, achieving engagement recognition accuracy of up to 81 percent. OPEN provides a scalable foundation for personalized engagement modeling in aging populations and contributes to broader engagement recognition research.
Foundation Artificial Intelligence Models for Health Recognition Using Face Photographs (FAHR-Face)
Jun 17, 2025Background: Facial appearance offers a noninvasive window into health. We built FAHR-Face, a foundation model trained on >40 million facial images and fine-tuned it for two distinct tasks: biological age estimation (FAHR-FaceAge) and survival risk prediction (FAHR-FaceSurvival). Methods: FAHR-FaceAge underwent a two-stage, age-balanced fine-tuning on 749,935 public images; FAHR-FaceSurvival was fine-tuned on 34,389 photos of cancer patients. Model robustness (cosmetic surgery, makeup, pose, lighting) and independence (saliency mapping) was tested extensively. Both models were clinically tested in two independent cancer patient datasets with survival analyzed by multivariable Cox models and adjusted for clinical prognostic factors. Findings: For age estimation, FAHR-FaceAge had the lowest mean absolute error of 5.1 years on public datasets, outperforming benchmark models and maintaining accuracy across the full human lifespan. In cancer patients, FAHR-FaceAge outperformed a prior facial age estimation model in survival prognostication. FAHR-FaceSurvival demonstrated robust prediction of mortality, and the highest-risk quartile had more than triple the mortality of the lowest (adjusted hazard ratio 3.22; P<0.001). These findings were validated in the independent cohort and both models showed generalizability across age, sex, race and cancer subgroups. The two algorithms provided distinct, complementary prognostic information; saliency mapping revealed each model relied on distinct facial regions. The combination of FAHR-FaceAge and FAHR-FaceSurvival improved prognostic accuracy. Interpretation: A single foundation model can generate inexpensive, scalable facial biomarkers that capture both biological ageing and disease-related mortality risk. The foundation model enabled effective training using relatively small clinical datasets.
MienCap: Realtime Performance-Based Facial Animation with Live Mood Dynamics
Aug 06, 2025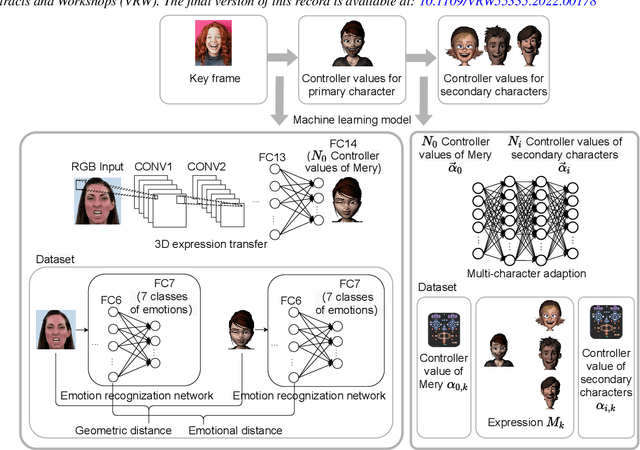
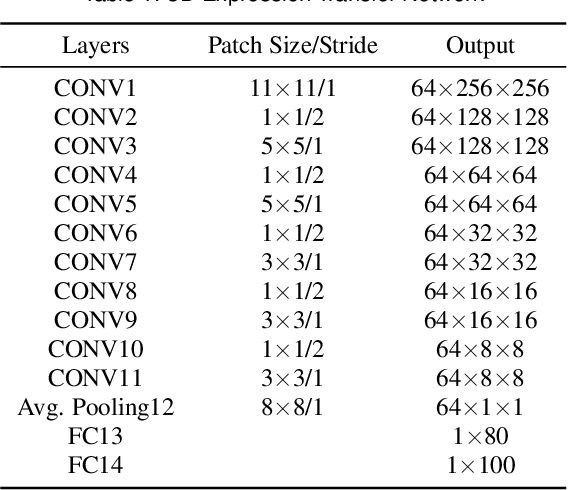
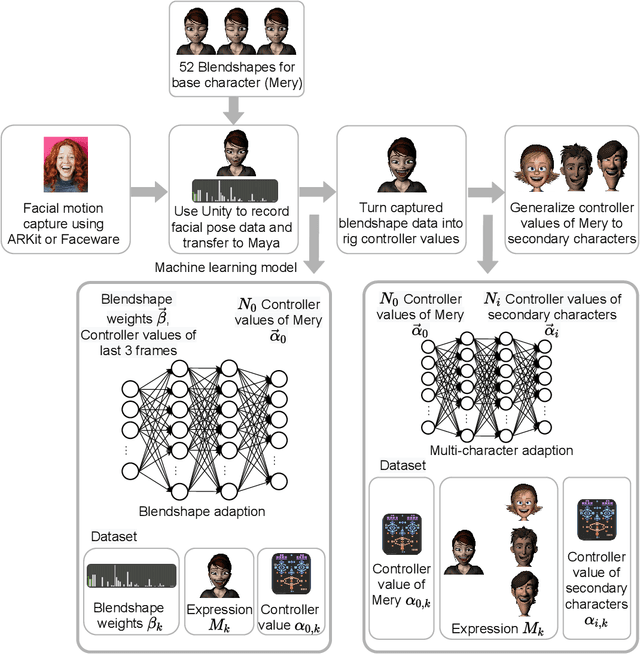

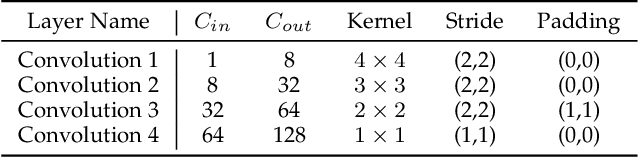
Our purpose is to improve performance-based animation which can drive believable 3D stylized characters that are truly perceptual. By combining traditional blendshape animation techniques with multiple machine learning models, we present both non-real time and real time solutions which drive character expressions in a geometrically consistent and perceptually valid way. For the non-real time system, we propose a 3D emotion transfer network makes use of a 2D human image to generate a stylized 3D rig parameters. For the real time system, we propose a blendshape adaption network which generates the character rig parameter motions with geometric consistency and temporally stability. We demonstrate the effectiveness of our system by comparing to a commercial product Faceware. Results reveal that ratings of the recognition, intensity, and attractiveness of expressions depicted for animated characters via our systems are statistically higher than Faceware. Our results may be implemented into the animation pipeline, and provide animators with a system for creating the expressions they wish to use more quickly and accurately.
Non-Adaptive Adversarial Face Generation
Jul 16, 2025


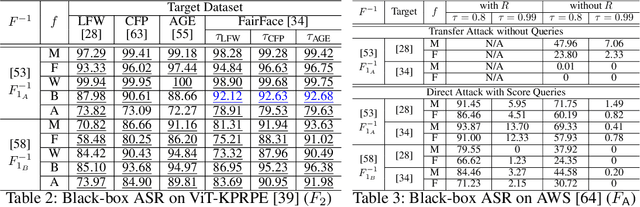
Adversarial attacks on face recognition systems (FRSs) pose serious security and privacy threats, especially when these systems are used for identity verification. In this paper, we propose a novel method for generating adversarial faces-synthetic facial images that are visually distinct yet recognized as a target identity by the FRS. Unlike iterative optimization-based approaches (e.g., gradient descent or other iterative solvers), our method leverages the structural characteristics of the FRS feature space. We figure out that individuals sharing the same attribute (e.g., gender or race) form an attributed subsphere. By utilizing such subspheres, our method achieves both non-adaptiveness and a remarkably small number of queries. This eliminates the need for relying on transferability and open-source surrogate models, which have been a typical strategy when repeated adaptive queries to commercial FRSs are impossible. Despite requiring only a single non-adaptive query consisting of 100 face images, our method achieves a high success rate of over 93% against AWS's CompareFaces API at its default threshold. Furthermore, unlike many existing attacks that perturb a given image, our method can deliberately produce adversarial faces that impersonate the target identity while exhibiting high-level attributes chosen by the adversary.
Landmark Guided Visual Feature Extractor for Visual Speech Recognition with Limited Resource
Aug 10, 2025Visual speech recognition is a technique to identify spoken content in silent speech videos, which has raised significant attention in recent years. Advancements in data-driven deep learning methods have significantly improved both the speed and accuracy of recognition. However, these deep learning methods can be effected by visual disturbances, such as lightning conditions, skin texture and other user-specific features. Data-driven approaches could reduce the performance degradation caused by these visual disturbances using models pretrained on large-scale datasets. But these methods often require large amounts of training data and computational resources, making them costly. To reduce the influence of user-specific features and enhance performance with limited data, this paper proposed a landmark guided visual feature extractor. Facial landmarks are used as auxiliary information to aid in training the visual feature extractor. A spatio-temporal multi-graph convolutional network is designed to fully exploit the spatial locations and spatio-temporal features of facial landmarks. Additionally, a multi-level lip dynamic fusion framework is introduced to combine the spatio-temporal features of the landmarks with the visual features extracted from the raw video frames. Experimental results show that this approach performs well with limited data and also improves the model's accuracy on unseen speakers.
Touch Speaks, Sound Feels: A Multimodal Approach to Affective and Social Touch from Robots to Humans
Aug 11, 2025



Affective tactile interaction constitutes a fundamental component of human communication. In natural human-human encounters, touch is seldom experienced in isolation; rather, it is inherently multisensory. Individuals not only perceive the physical sensation of touch but also register the accompanying auditory cues generated through contact. The integration of haptic and auditory information forms a rich and nuanced channel for emotional expression. While extensive research has examined how robots convey emotions through facial expressions and speech, their capacity to communicate social gestures and emotions via touch remains largely underexplored. To address this gap, we developed a multimodal interaction system incorporating a 5*5 grid of 25 vibration motors synchronized with audio playback, enabling robots to deliver combined haptic-audio stimuli. In an experiment involving 32 Chinese participants, ten emotions and six social gestures were presented through vibration, sound, or their combination. Participants rated each stimulus on arousal and valence scales. The results revealed that (1) the combined haptic-audio modality significantly enhanced decoding accuracy compared to single modalities; (2) each individual channel-vibration or sound-effectively supported certain emotions recognition, with distinct advantages depending on the emotional expression; and (3) gestures alone were generally insufficient for conveying clearly distinguishable emotions. These findings underscore the importance of multisensory integration in affective human-robot interaction and highlight the complementary roles of haptic and auditory cues in enhancing emotional communication.