 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutube Vis 2021 Validation
Papers and Code
PM-VIS: High-Performance Box-Supervised Video Instance Segmentation
Apr 22, 2024



Labeling pixel-wise object masks in videos is a resource-intensive and laborious process. Box-supervised Video Instance Segmentation (VIS) methods have emerged as a viable solution to mitigate the labor-intensive annotation process. . In practical applications, the two-step approach is not only more flexible but also exhibits a higher recognition accuracy. Inspired by the recent success of Segment Anything Model (SAM), we introduce a novel approach that aims at harnessing instance box annotations from multiple perspectives to generate high-quality instance pseudo masks, thus enriching the information contained in instance annotations. We leverage ground-truth boxes to create three types of pseudo masks using the HQ-SAM model, the box-supervised VIS model (IDOL-BoxInst), and the VOS model (DeAOT) separately, along with three corresponding optimization mechanisms. Additionally, we introduce two ground-truth data filtering methods, assisted by high-quality pseudo masks, to further enhance the training dataset quality and improve the performance of fully supervised VIS methods. To fully capitalize on the obtained high-quality Pseudo Masks, we introduce a novel algorithm, PM-VIS, to integrate mask losses into IDOL-BoxInst. Our PM-VIS model, trained with high-quality pseudo mask annotations, demonstrates strong ability in instance mask prediction, achieving state-of-the-art performance on the YouTube-VIS 2019, YouTube-VIS 2021, and OVIS validation sets, notably narrowing the gap between box-supervised and fully supervised VIS methods.
BoxVIS: Video Instance Segmentation with Box Annotations
Mar 26, 2023It is expensive and labour-extensive to label the pixel-wise object masks in a video. As a results, the amount of pixel-wise annotations in existing video instance segmentation (VIS) datasets is small, limiting the generalization capability of trained VIS models. An alternative but much cheaper solution is to use bounding boxes to label instances in videos. Inspired by the recent success of box-supervised image instance segmentation, we first adapt the state-of-the-art pixel-supervised VIS models to a box-supervised VIS (BoxVIS) baseline, and observe only slight performance degradation. We consequently propose to improve BoxVIS performance from two aspects. First, we propose a box-center guided spatial-temporal pairwise affinity (STPA) loss to predict instance masks for better spatial and temporal consistency. Second, we collect a larger scale box-annotated VIS dataset (BVISD) by consolidating the videos from current VIS benchmarks and converting images from the COCO dataset to short pseudo video clips. With the proposed BVISD and the STPA loss, our trained BoxVIS model demonstrates promising instance mask prediction performance. Specifically, it achieves 43.2\% and 29.0\% mask AP on the YouTube-VIS 2021 and OVIS valid sets, respectively, exhibiting comparable or even better generalization performance than state-of-the-art pixel-supervised VIS models by using only 16\% annotation time and cost. Codes and data of BoxVIS can be found at \url{https://github.com/MinghanLi/BoxVIS}.
STC: Spatio-Temporal Contrastive Learning for Video Instance Segmentation
Feb 08, 2022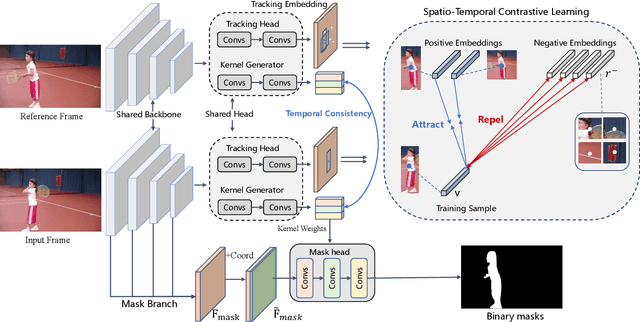
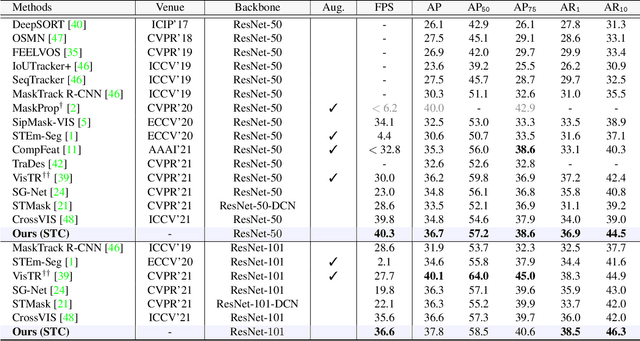
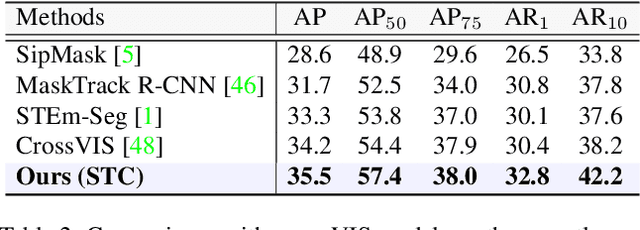

Video Instance Segmentation (VIS) is a task that simultaneously requires classification, segmentation, and instance association in a video. Recent VIS approaches rely on sophisticated pipelines to achieve this goal, including RoI-related operations or 3D convolutions. In contrast, we present a simple and efficient single-stage VIS framework based on the instance segmentation method CondInst by adding an extra tracking head. To improve instance association accuracy, a novel bi-directional spatio-temporal contrastive learning strategy for tracking embedding across frames is proposed. Moreover, an instance-wise temporal consistency scheme is utilized to produce temporally coherent results. Experiments conducted on the YouTube-VIS-2019, YouTube-VIS-2021, and OVIS-2021 datasets validate the effectiveness and efficiency of the proposed method. We hope the proposed framework can serve as a simple and strong alternative for many other instance-level video association tasks. Code will be made available.
One-stage Video Instance Segmentation: From Frame-in Frame-out to Clip-in Clip-out
Mar 12, 2022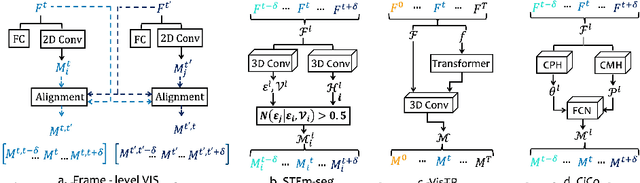
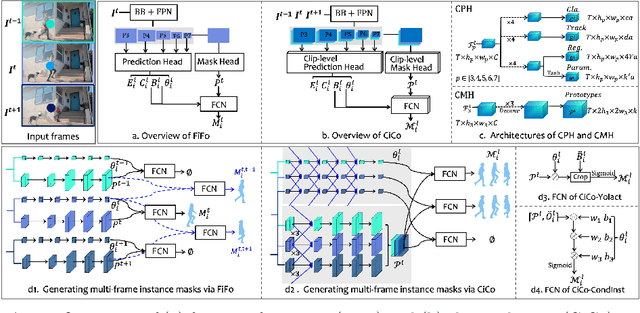
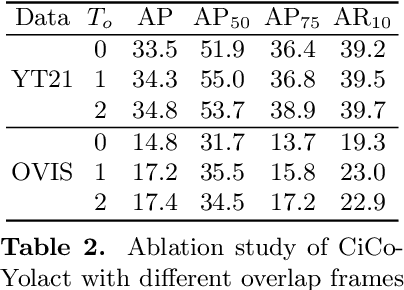

Many video instance segmentation (VIS) methods partition a video sequence into individual frames to detect and segment objects frame by frame. However, such a frame-in frame-out (FiFo) pipeline is ineffective to exploit the temporal information. Based on the fact that adjacent frames in a short clip are highly coherent in content, we propose to extend the one-stage FiFo framework to a clip-in clip-out (CiCo) one, which performs VIS clip by clip. Specifically, we stack FPN features of all frames in a short video clip to build a spatio-temporal feature cube, and replace the 2D conv layers in the prediction heads and the mask branch with 3D conv layers, forming clip-level prediction heads (CPH) and clip-level mask heads (CMH). Then the clip-level masks of an instance can be generated by feeding its box-level predictions from CPH and clip-level features from CMH into a small fully convolutional network. A clip-level segmentation loss is proposed to ensure that the generated instance masks are temporally coherent in the clip. The proposed CiCo strategy is free of inter-frame alignment, and can be easily embedded into existing FiFo based VIS approaches. To validate the generality and effectiveness of our CiCo strategy, we apply it to two representative FiFo methods, Yolact \cite{bolya2019yolact} and CondInst \cite{tian2020conditional}, resulting in two new one-stage VIS models, namely CiCo-Yolact and CiCo-CondInst, which achieve 37.1/37.3\%, 35.2/35.4\% and 17.2/18.0\% mask AP using the ResNet50 backbone, and 41.8/41.4\%, 38.0/38.9\% and 18.0/18.2\% mask AP using the Swin Transformer tiny backbone on YouTube-VIS 2019, 2021 and OVIS valid sets, respectively, recording new state-of-the-arts. Code and video demos of CiCo can be found at \url{https://github.com/MinghanLi/CiCo}.