 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinobias
Papers and Code
C2PO: Diagnosing and Disentangling Bias Shortcuts in LLMs
Dec 29, 2025Bias in Large Language Models (LLMs) poses significant risks to trustworthiness, manifesting primarily as stereotypical biases (e.g., gender or racial stereotypes) and structural biases (e.g., lexical overlap or position preferences). However, prior paradigms typically address these in isolation, often mitigating one at the expense of exacerbating the other. To address this, we conduct a systematic exploration of these reasoning failures and identify a primary inducement: the latent spurious feature correlations within the input that drive these erroneous reasoning shortcuts. Driven by these findings, we introduce Causal-Contrastive Preference Optimization (C2PO), a unified alignment framework designed to tackle these specific failures by simultaneously discovering and suppressing these correlations directly within the optimization process. Specifically, C2PO leverages causal counterfactual signals to isolate bias-inducing features from valid reasoning paths, and employs a fairness-sensitive preference update mechanism to dynamically evaluate logit-level contributions and suppress shortcut features. Extensive experiments across multiple benchmarks covering stereotypical bias (BBQ, Unqover), structural bias (MNLI, HANS, Chatbot, MT-Bench), out-of-domain fairness (StereoSet, WinoBias), and general utility (MMLU, GSM8K) demonstrate that C2PO effectively mitigates stereotypical and structural biases while preserving robust general reasoning capabilities.
Investigating Intersectional Bias in Large Language Models using Confidence Disparities in Coreference Resolution
Aug 09, 2025



Large language models (LLMs) have achieved impressive performance, leading to their widespread adoption as decision-support tools in resource-constrained contexts like hiring and admissions. There is, however, scientific consensus that AI systems can reflect and exacerbate societal biases, raising concerns about identity-based harm when used in critical social contexts. Prior work has laid a solid foundation for assessing bias in LLMs by evaluating demographic disparities in different language reasoning tasks. In this work, we extend single-axis fairness evaluations to examine intersectional bias, recognizing that when multiple axes of discrimination intersect, they create distinct patterns of disadvantage. We create a new benchmark called WinoIdentity by augmenting the WinoBias dataset with 25 demographic markers across 10 attributes, including age, nationality, and race, intersected with binary gender, yielding 245,700 prompts to evaluate 50 distinct bias patterns. Focusing on harms of omission due to underrepresentation, we investigate bias through the lens of uncertainty and propose a group (un)fairness metric called Coreference Confidence Disparity which measures whether models are more or less confident for some intersectional identities than others. We evaluate five recently published LLMs and find confidence disparities as high as 40% along various demographic attributes including body type, sexual orientation and socio-economic status, with models being most uncertain about doubly-disadvantaged identities in anti-stereotypical settings. Surprisingly, coreference confidence decreases even for hegemonic or privileged markers, indicating that the recent impressive performance of LLMs is more likely due to memorization than logical reasoning. Notably, these are two independent failures in value alignment and validity that can compound to cause social harm.
Preserving Task-Relevant Information Under Linear Concept Removal
Jun 12, 2025Modern neural networks often encode unwanted concepts alongside task-relevant information, leading to fairness and interpretability concerns. Existing post-hoc approaches can remove undesired concepts but often degrade useful signals. We introduce SPLICE-Simultaneous Projection for LInear concept removal and Covariance prEservation-which eliminates sensitive concepts from representations while exactly preserving their covariance with a target label. SPLICE achieves this via an oblique projection that "splices out" the unwanted direction yet protects important label correlations. Theoretically, it is the unique solution that removes linear concept predictability and maintains target covariance with minimal embedding distortion. Empirically, SPLICE outperforms baselines on benchmarks such as Bias in Bios and Winobias, removing protected attributes while minimally damaging main-task information.
ASCenD-BDS: Adaptable, Stochastic and Context-aware framework for Detection of Bias, Discrimination and Stereotyping
Feb 04, 2025The rapid evolution of Large Language Models (LLMs) has transformed natural language processing but raises critical concerns about biases inherent in their deployment and use across diverse linguistic and sociocultural contexts. This paper presents a framework named ASCenD BDS (Adaptable, Stochastic and Context-aware framework for Detection of Bias, Discrimination and Stereotyping). The framework presents approach to detecting bias, discrimination, stereotyping across various categories such as gender, caste, age, disability, socioeconomic status, linguistic variations, etc., using an approach which is Adaptive, Stochastic and Context-Aware. The existing frameworks rely heavily on usage of datasets to generate scenarios for detection of Bias, Discrimination and Stereotyping. Examples include datasets such as Civil Comments, Wino Gender, WinoBias, BOLD, CrowS Pairs and BBQ. However, such an approach provides point solutions. As a result, these datasets provide a finite number of scenarios for assessment. The current framework overcomes this limitation by having features which enable Adaptability, Stochasticity, Context Awareness. Context awareness can be customized for any nation or culture or sub-culture (for example an organization's unique culture). In this paper, context awareness in the Indian context has been established. Content has been leveraged from Indian Census 2011 to have a commonality of categorization. A framework has been developed using Category, Sub-Category, STEM, X-Factor, Synonym to enable the features for Adaptability, Stochasticity and Context awareness. The framework has been described in detail in Section 3. Overall 800 plus STEMs, 10 Categories, 31 unique SubCategories were developed by a team of consultants at Saint Fox Consultancy Private Ltd. The concept has been tested out in SFCLabs as part of product development.
Evaluating Gender, Racial, and Age Biases in Large Language Models: A Comparative Analysis of Occupational and Crime Scenarios
Sep 22, 2024



Recent advancements in Large Language Models(LLMs) have been notable, yet widespread enterprise adoption remains limited due to various constraints. This paper examines bias in LLMs-a crucial issue affecting their usability, reliability, and fairness. Researchers are developing strategies to mitigate bias, including debiasing layers, specialized reference datasets like Winogender and Winobias, and reinforcement learning with human feedback (RLHF). These techniques have been integrated into the latest LLMs. Our study evaluates gender bias in occupational scenarios and gender, age, and racial bias in crime scenarios across four leading LLMs released in 2024: Gemini 1.5 Pro, Llama 3 70B, Claude 3 Opus, and GPT-4o. Findings reveal that LLMs often depict female characters more frequently than male ones in various occupations, showing a 37% deviation from US BLS data. In crime scenarios, deviations from US FBI data are 54% for gender, 28% for race, and 17% for age. We observe that efforts to reduce gender and racial bias often lead to outcomes that may over-index one sub-class, potentially exacerbating the issue. These results highlight the limitations of current bias mitigation techniques and underscore the need for more effective approaches.
Are Models Biased on Text without Gender-related Language?
May 01, 2024Gender bias research has been pivotal in revealing undesirable behaviors in large language models, exposing serious gender stereotypes associated with occupations, and emotions. A key observation in prior work is that models reinforce stereotypes as a consequence of the gendered correlations that are present in the training data. In this paper, we focus on bias where the effect from training data is unclear, and instead address the question: Do language models still exhibit gender bias in non-stereotypical settings? To do so, we introduce UnStereoEval (USE), a novel framework tailored for investigating gender bias in stereotype-free scenarios. USE defines a sentence-level score based on pretraining data statistics to determine if the sentence contain minimal word-gender associations. To systematically benchmark the fairness of popular language models in stereotype-free scenarios, we utilize USE to automatically generate benchmarks without any gender-related language. By leveraging USE's sentence-level score, we also repurpose prior gender bias benchmarks (Winobias and Winogender) for non-stereotypical evaluation. Surprisingly, we find low fairness across all 28 tested models. Concretely, models demonstrate fair behavior in only 9%-41% of stereotype-free sentences, suggesting that bias does not solely stem from the presence of gender-related words. These results raise important questions about where underlying model biases come from and highlight the need for more systematic and comprehensive bias evaluation. We release the full dataset and code at https://ucinlp.github.io/unstereo-eval.
Gender bias and stereotypes in Large Language Models
Aug 28, 2023Large Language Models (LLMs) have made substantial progress in the past several months, shattering state-of-the-art benchmarks in many domains. This paper investigates LLMs' behavior with respect to gender stereotypes, a known issue for prior models. We use a simple paradigm to test the presence of gender bias, building on but differing from WinoBias, a commonly used gender bias dataset, which is likely to be included in the training data of current LLMs. We test four recently published LLMs and demonstrate that they express biased assumptions about men and women's occupations. Our contributions in this paper are as follows: (a) LLMs are 3-6 times more likely to choose an occupation that stereotypically aligns with a person's gender; (b) these choices align with people's perceptions better than with the ground truth as reflected in official job statistics; (c) LLMs in fact amplify the bias beyond what is reflected in perceptions or the ground truth; (d) LLMs ignore crucial ambiguities in sentence structure 95% of the time in our study items, but when explicitly prompted, they recognize the ambiguity; (e) LLMs provide explanations for their choices that are factually inaccurate and likely obscure the true reason behind their predictions. That is, they provide rationalizations of their biased behavior. This highlights a key property of these models: LLMs are trained on imbalanced datasets; as such, even with the recent successes of reinforcement learning with human feedback, they tend to reflect those imbalances back at us. As with other types of societal biases, we suggest that LLMs must be carefully tested to ensure that they treat minoritized individuals and communities equitably.
* ACM Collective Intelligence
Second Order WinoBias Test Set for Latent Gender Bias Detection in Coreference Resolution
Sep 28, 2021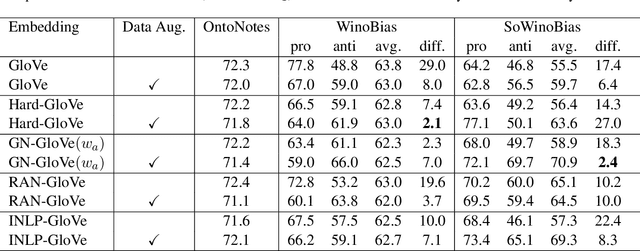

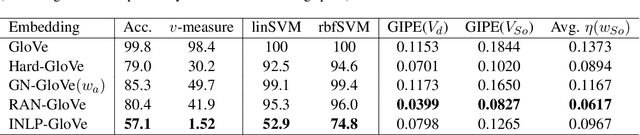
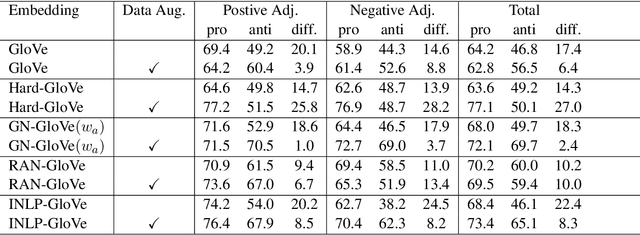
We observe an instance of gender-induced bias in a downstream application, despite the absence of explicit gender words in the test cases. We provide a test set, SoWinoBias, for the purpose of measuring such latent gender bias in coreference resolution systems. We evaluate the performance of current debiasing methods on the SoWinoBias test set, especially in reference to the method's design and altered embedding space properties. See https://github.com/hillarydawkins/SoWinoBias.
* 7+2 pages. Published in the proceedings of the 3rd Workshop on Gender Bias in Natural Language Processing (co-located with ACL-IJCNLP 2021)
NeuTral Rewriter: A Rule-Based and Neural Approach to Automatic Rewriting into Gender-Neutral Alternatives
Sep 13, 2021
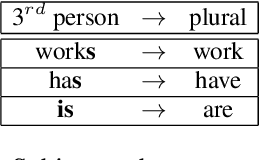
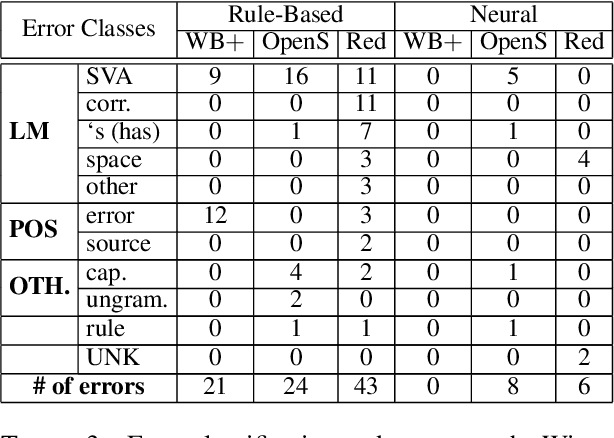
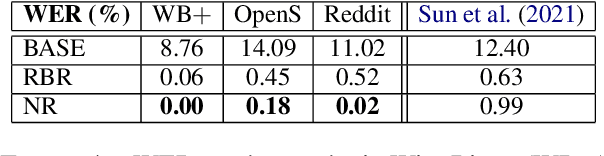
Recent years have seen an increasing need for gender-neutral and inclusive language. Within the field of NLP, there are various mono- and bilingual use cases where gender inclusive language is appropriate, if not preferred due to ambiguity or uncertainty in terms of the gender of referents. In this work, we present a rule-based and a neural approach to gender-neutral rewriting for English along with manually curated synthetic data (WinoBias+) and natural data (OpenSubtitles and Reddit) benchmarks. A detailed manual and automatic evaluation highlights how our NeuTral Rewriter, trained on data generated by the rule-based approach, obtains word error rates (WER) below 0.18% on synthetic, in-domain and out-domain test sets.
Stereotype and Skew: Quantifying Gender Bias in Pre-trained and Fine-tuned Language Models
Feb 16, 2021
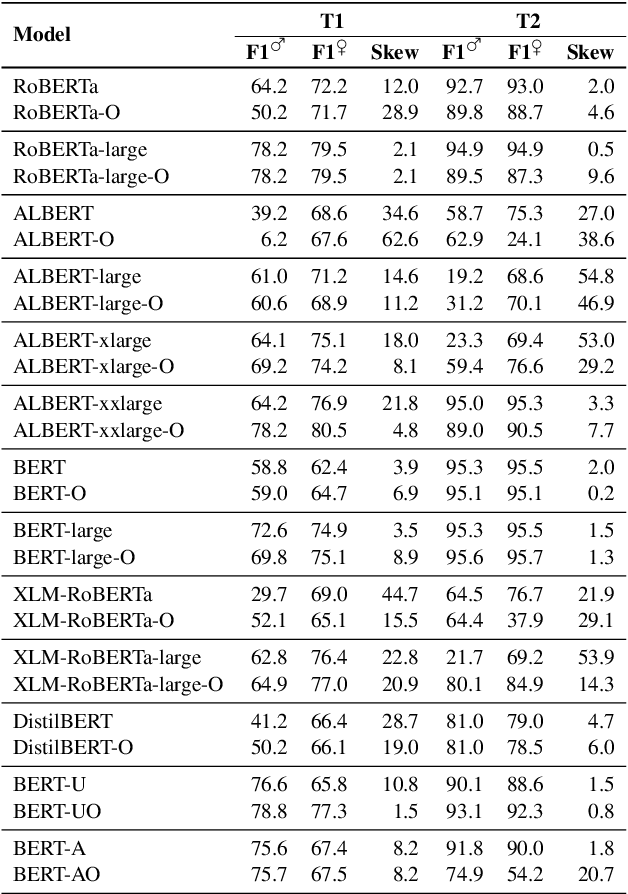

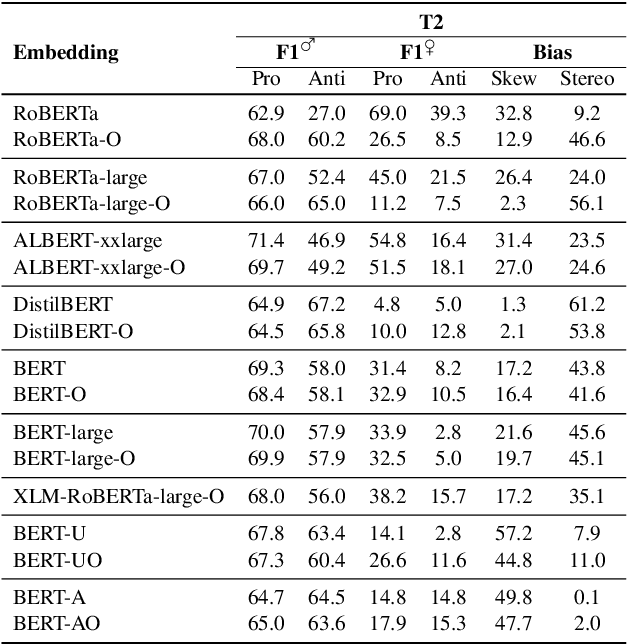
This paper proposes two intuitive metrics, skew and stereotype, that quantify and analyse the gender bias present in contextual language models when tackling the WinoBias pronoun resolution task. We find evidence that gender stereotype correlates approximately negatively with gender skew in out-of-the-box models, suggesting that there is a trade-off between these two forms of bias. We investigate two methods to mitigate bias. The first approach is an online method which is effective at removing skew at the expense of stereotype. The second, inspired by previous work on ELMo, involves the fine-tuning of BERT using an augmented gender-balanced dataset. We show that this reduces both skew and stereotype relative to its unaugmented fine-tuned counterpart. However, we find that existing gender bias benchmarks do not fully probe professional bias as pronoun resolution may be obfuscated by cross-correlations from other manifestations of gender prejudice. Our code is available online, at https://github.com/12kleingordon34/NLP_masters_project.