 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConGA: Guidelines for Contextual Gender Annotation. A Framework for Annotating Gender in Machine Translation
Mar 18, 2026Handling gender across languages remains a persistent challenge for Machine Translation (MT) and Large Language Models (LLMs), especially when translating from gender-neutral languages into morphologically gendered ones, such as English to Italian. English largely omits grammatical gender, while Italian requires explicit agreement across multiple grammatical categories. This asymmetry often leads MT systems to default to masculine forms, reinforcing bias and reducing translation accuracy. To address this issue, we present the Contextual Gender Annotation (ConGA) framework, a linguistically grounded set of guidelines for word-level gender annotation. The scheme distinguishes between semantic gender in English through three tags, Masculine (M), Feminine (F), and Ambiguous (A), and grammatical gender realisation in Italian (Masculine (M), Feminine (F)), combined with entity-level identifiers for cross-sentence tracking. We apply ConGA to the gENder-IT dataset, creating a gold-standard resource for evaluating gender bias in translation. Our results reveal systematic masculine overuse and inconsistent feminine realisation, highlighting persistent limitations of current MT systems. By combining fine-grained linguistic annotation with quantitative evaluation, this work offers both a methodology and a benchmark for building more gender-aware and multilingual NLP systems.
Gender Disambiguation in Machine Translation: Diagnostic Evaluation in Decoder-Only Architectures
Mar 18, 2026While Large Language Models achieve state-of-the-art results across a wide range of NLP tasks, they remain prone to systematic biases. Among these, gender bias is particularly salient in MT, due to systematic differences across languages in whether and how gender is marked. As a result, translation often requires disambiguating implicit source signals into explicit gender-marked forms. In this context, standard benchmarks may capture broad disparities but fail to reflect the full complexity of gender bias in modern MT. In this paper, we extend recent frameworks on bias evaluation by: (i) introducing a novel measure coined "Prior Bias", capturing a model's default gender assumptions, and (ii) applying the framework to decoder-only MT models. Our results show that, despite their scale and state-of-the-art status, decoder-only models do not generally outperform encoder-decoder architectures on gender-specific metrics; however, post-training (e.g., instruction tuning) not only improves contextual awareness but also reduces the masculine Prior Bias.
Are We Paying Attention to Her? Investigating Gender Disambiguation and Attention in Machine Translation
May 13, 2025



While gender bias in modern Neural Machine Translation (NMT) systems has received much attention, traditional evaluation metrics do not to fully capture the extent to which these systems integrate contextual gender cues. We propose a novel evaluation metric called Minimal Pair Accuracy (MPA), which measures the reliance of models on gender cues for gender disambiguation. MPA is designed to go beyond surface-level gender accuracy metrics by focusing on whether models adapt to gender cues in minimal pairs -- sentence pairs that differ solely in the gendered pronoun, namely the explicit indicator of the target's entity gender in the source language (EN). We evaluate a number of NMT models on the English-Italian (EN--IT) language pair using this metric, we show that they ignore available gender cues in most cases in favor of (statistical) stereotypical gender interpretation. We further show that in anti-stereotypical cases, these models tend to more consistently take masculine gender cues into account while ignoring the feminine cues. Furthermore, we analyze the attention head weights in the encoder component and show that while all models encode gender information to some extent, masculine cues elicit a more diffused response compared to the more concentrated and specialized responses to feminine gender cues.
AI in Support of Diversity and Inclusion
Jan 16, 2025

In this paper, we elaborate on how AI can support diversity and inclusion and exemplify research projects conducted in that direction. We start by looking at the challenges and progress in making large language models (LLMs) more transparent, inclusive, and aware of social biases. Even though LLMs like ChatGPT have impressive abilities, they struggle to understand different cultural contexts and engage in meaningful, human like conversations. A key issue is that biases in language processing, especially in machine translation, can reinforce inequality. Tackling these biases requires a multidisciplinary approach to ensure AI promotes diversity, fairness, and inclusion. We also highlight AI's role in identifying biased content in media, which is important for improving representation. By detecting unequal portrayals of social groups, AI can help challenge stereotypes and create more inclusive technologies. Transparent AI algorithms, which clearly explain their decisions, are essential for building trust and reducing bias in AI systems. We also stress AI systems need diverse and inclusive training data. Projects like the Child Growth Monitor show how using a wide range of data can help address real world problems like malnutrition and poverty. We present a project that demonstrates how AI can be applied to monitor the role of search engines in spreading disinformation about the LGBTQ+ community. Moreover, we discuss the SignON project as an example of how technology can bridge communication gaps between hearing and deaf people, emphasizing the importance of collaboration and mutual trust in developing inclusive AI. Overall, with this paper, we advocate for AI systems that are not only effective but also socially responsible, promoting fair and inclusive interactions between humans and machines.
Gender Bias in Machine Translation and The Era of Large Language Models
Jan 18, 2024This chapter examines the role of Machine Translation in perpetuating gender bias, highlighting the challenges posed by cross-linguistic settings and statistical dependencies. A comprehensive overview of relevant existing work related to gender bias in both conventional Neural Machine Translation approaches and Generative Pretrained Transformer models employed as Machine Translation systems is provided. Through an experiment using ChatGPT (based on GPT-3.5) in an English-Italian translation context, we further assess ChatGPT's current capacity to address gender bias. The findings emphasize the ongoing need for advancements in mitigating bias in Machine Translation systems and underscore the importance of fostering fairness and inclusivity in language technologies.
Tailoring Domain Adaptation for Machine Translation Quality Estimation
Apr 18, 2023



While quality estimation (QE) can play an important role in the translation process, its effectiveness relies on the availability and quality of training data. For QE in particular, high-quality labeled data is often lacking due to the high-cost and effort associated with labeling such data. Aside from the data scarcity challenge, QE models should also be generalizable, i.e., they should be able to handle data from different domains, both generic and specific. To alleviate these two main issues -- data scarcity and domain mismatch -- this paper combines domain adaptation and data augmentation within a robust QE system. Our method is to first train a generic QE model and then fine-tune it on a specific domain while retaining generic knowledge. Our results show a significant improvement for all the language pairs investigated, better cross-lingual inference, and a superior performance in zero-shot learning scenarios as compared to state-of-the-art baselines.
The Ecological Footprint of Neural Machine Translation Systems
Feb 04, 2022Over the past decade, deep learning (DL) has led to significant advancements in various fields of artificial intelligence, including machine translation (MT). These advancements would not be possible without the ever-growing volumes of data and the hardware that allows large DL models to be trained efficiently. Due to the large amount of computing cores as well as dedicated memory, graphics processing units (GPUs) are a more effective hardware solution for training and inference with DL models than central processing units (CPUs). However, the former is very power demanding. The electrical power consumption has economical as well as ecological implications. This chapter focuses on the ecological footprint of neural MT systems. It starts from the power drain during the training of and the inference with neural MT models and moves towards the environment impact, in terms of carbon dioxide emissions. Different architectures (RNN and Transformer) and different GPUs (consumer-grate NVidia 1080Ti and workstation-grade NVidia P100) are compared. Then, the overall CO2 offload is calculated for Ireland and the Netherlands. The NMT models and their ecological impact are compared to common household appliances to draw a more clear picture. The last part of this chapter analyses quantization, a technique for reducing the size and complexity of models, as a way to reduce power consumption. As quantized models can run on CPUs, they present a power-efficient inference solution without depending on a GPU.
NeuTral Rewriter: A Rule-Based and Neural Approach to Automatic Rewriting into Gender-Neutral Alternatives
Sep 13, 2021
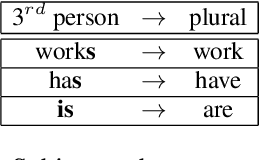
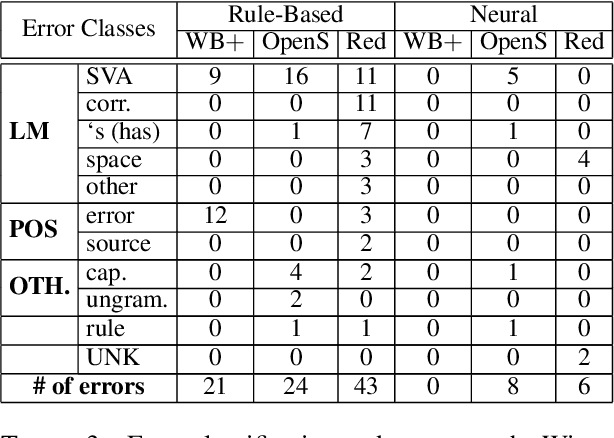
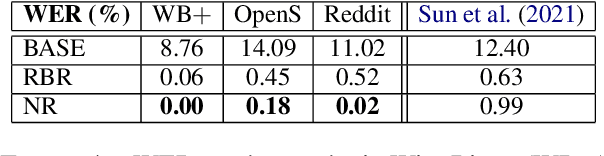
Recent years have seen an increasing need for gender-neutral and inclusive language. Within the field of NLP, there are various mono- and bilingual use cases where gender inclusive language is appropriate, if not preferred due to ambiguity or uncertainty in terms of the gender of referents. In this work, we present a rule-based and a neural approach to gender-neutral rewriting for English along with manually curated synthetic data (WinoBias+) and natural data (OpenSubtitles and Reddit) benchmarks. A detailed manual and automatic evaluation highlights how our NeuTral Rewriter, trained on data generated by the rule-based approach, obtains word error rates (WER) below 0.18% on synthetic, in-domain and out-domain test sets.
GENder-IT: An Annotated English-Italian Parallel Challenge Set for Cross-Linguistic Natural Gender Phenomena
Aug 31, 2021Languages differ in terms of the absence or presence of gender features, the number of gender classes and whether and where gender features are explicitly marked. These cross-linguistic differences can lead to ambiguities that are difficult to resolve, especially for sentence-level MT systems. The identification of ambiguity and its subsequent resolution is a challenging task for which currently there aren't any specific resources or challenge sets available. In this paper, we introduce gENder-IT, an English--Italian challenge set focusing on the resolution of natural gender phenomena by providing word-level gender tags on the English source side and multiple gender alternative translations, where needed, on the Italian target side.
Generating Gender Augmented Data for NLP
Jul 13, 2021
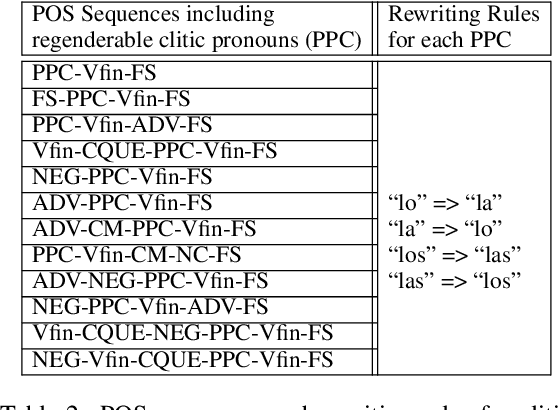


Gender bias is a frequent occurrence in NLP-based applications, especially pronounced in gender-inflected languages. Bias can appear through associations of certain adjectives and animate nouns with the natural gender of referents, but also due to unbalanced grammatical gender frequencies of inflected words. This type of bias becomes more evident in generating conversational utterances where gender is not specified within the sentence, because most current NLP applications still work on a sentence-level context. As a step towards more inclusive NLP, this paper proposes an automatic and generalisable rewriting approach for short conversational sentences. The rewriting method can be applied to sentences that, without extra-sentential context, have multiple equivalent alternatives in terms of gender. The method can be applied both for creating gender balanced outputs as well as for creating gender balanced training data. The proposed approach is based on a neural machine translation (NMT) system trained to 'translate' from one gender alternative to another. Both the automatic and manual analysis of the approach show promising results for automatic generation of gender alternatives for conversational sentences in Spanish.