 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikimovies
Papers and Code
SKILL: Structured Knowledge Infusion for Large Language Models
May 17, 2022
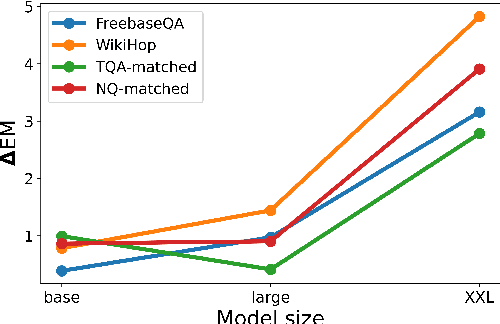
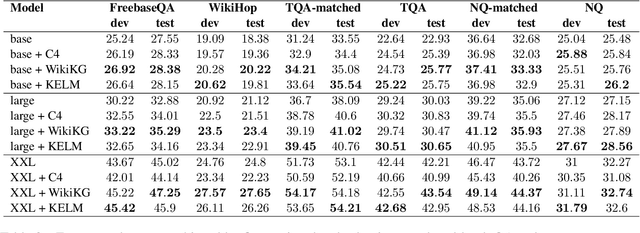
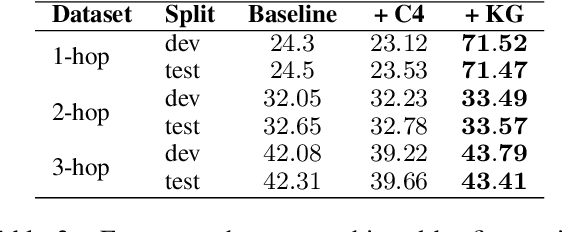
Large language models (LLMs) have demonstrated human-level performance on a vast spectrum of natural language tasks. However, it is largely unexplored whether they can better internalize knowledge from a structured data, such as a knowledge graph, or from text. In this work, we propose a method to infuse structured knowledge into LLMs, by directly training T5 models on factual triples of knowledge graphs (KGs). We show that models pre-trained on Wikidata KG with our method outperform the T5 baselines on FreebaseQA and WikiHop, as well as the Wikidata-answerable subset of TriviaQA and NaturalQuestions. The models pre-trained on factual triples compare competitively with the ones on natural language sentences that contain the same knowledge. Trained on a smaller size KG, WikiMovies, we saw 3x improvement of exact match score on MetaQA task compared to T5 baseline. The proposed method has an advantage that no alignment between the knowledge graph and text corpus is required in curating training data. This makes our method particularly useful when working with industry-scale knowledge graphs.
A Two-Stage Approach towards Generalization in Knowledge Base Question Answering
Nov 17, 2021
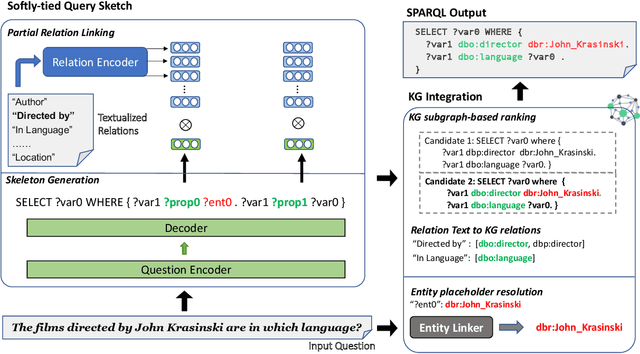
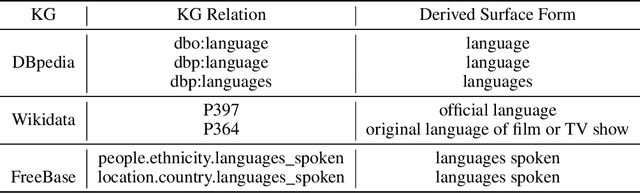
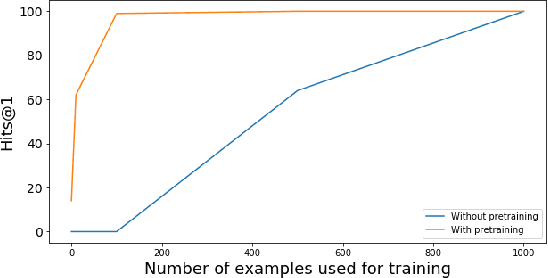
Most existing approaches for Knowledge Base Question Answering (KBQA) focus on a specific underlying knowledge base either because of inherent assumptions in the approach, or because evaluating it on a different knowledge base requires non-trivial changes. However, many popular knowledge bases share similarities in their underlying schemas that can be leveraged to facilitate generalization across knowledge bases. To achieve this generalization, we introduce a KBQA framework based on a 2-stage architecture that explicitly separates semantic parsing from the knowledge base interaction, facilitating transfer learning across datasets and knowledge graphs. We show that pretraining on datasets with a different underlying knowledge base can nevertheless provide significant performance gains and reduce sample complexity. Our approach achieves comparable or state-of-the-art performance for LC-QuAD (DBpedia), WebQSP (Freebase), SimpleQuestions (Wikidata) and MetaQA (Wikimovies-KG).
Constructing a Knowledge Graph from Unstructured Documents without External Alignment
Aug 20, 2020
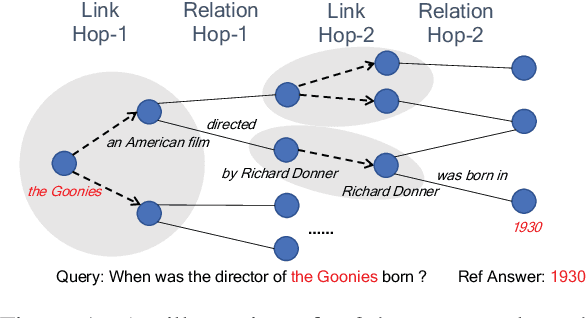
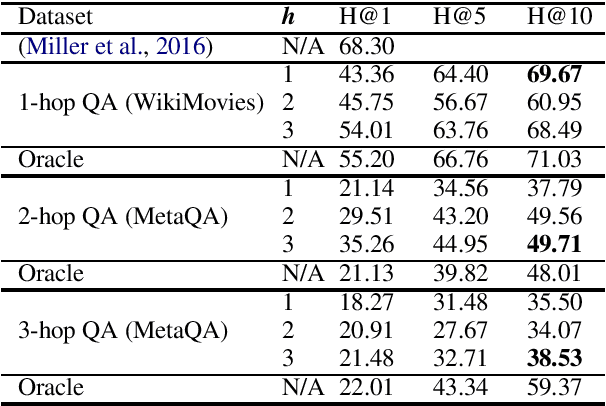

Knowledge graphs (KGs) are relevant to many NLP tasks, but building a reliable domain-specific KG is time-consuming and expensive. A number of methods for constructing KGs with minimized human intervention have been proposed, but still require a process to align into the human-annotated knowledge base. To overcome this issue, we propose a novel method to automatically construct a KG from unstructured documents that does not require external alignment and explore its use to extract desired information. To summarize our approach, we first extract knowledge tuples in their surface form from unstructured documents, encode them using a pre-trained language model, and link the surface-entities via the encoding to form the graph structure. We perform experiments with benchmark datasets such as WikiMovies and MetaQA. The experimental results show that our method can successfully create and search a KG with 18K documents and achieve 69.7% hits@10 (close to an oracle model) on a query retrieval task.
Learning to Organize Knowledge and Answer Questions with N-Gram Machines
Jul 01, 2018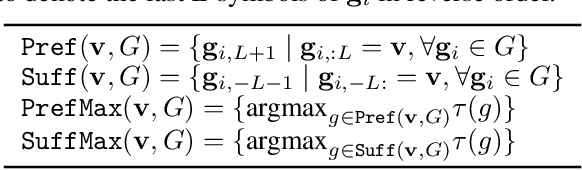

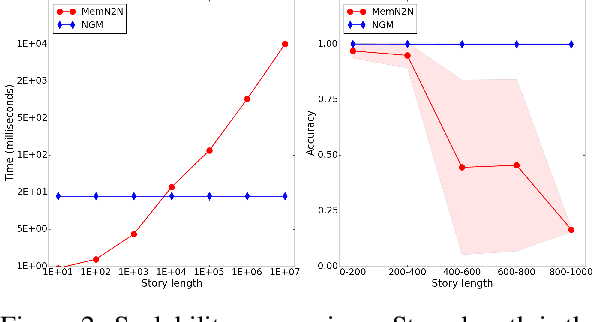
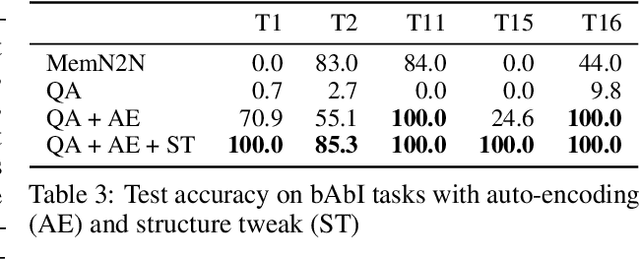
Though deep neural networks have great success in natural language processing, they are limited at more knowledge intensive AI tasks, such as open-domain Question Answering (QA). Existing end-to-end deep QA models need to process the entire text after observing the question, and therefore their complexity in responding a question is linear in the text size. This is prohibitive for practical tasks such as QA from Wikipedia, a novel, or the Web. We propose to solve this scalability issue by using symbolic meaning representations, which can be indexed and retrieved efficiently with complexity that is independent of the text size. We apply our approach, called the N-Gram Machine (NGM), to three representative tasks. First as proof-of-concept, we demonstrate that NGM successfully solves the bAbI tasks of synthetic text. Second, we show that NGM scales to large corpus by experimenting on "life-long bAbI", a special version of bAbI that contains millions of sentences. Lastly on the WikiMovies dataset, we use NGM to induce latent structure (i.e. schema) and answer questions from natural language Wikipedia text, with only QA pairs as weak supervision.
Differentiable Learning of Logical Rules for Knowledge Base Reasoning
Nov 27, 2017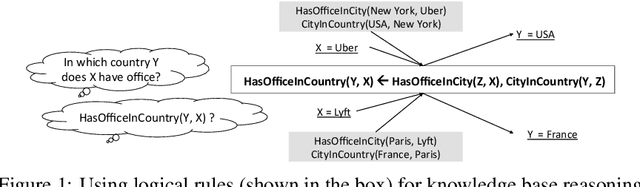
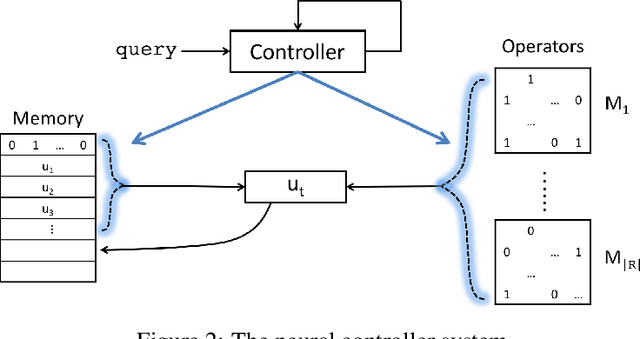
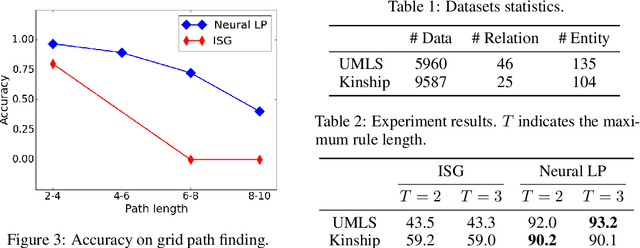
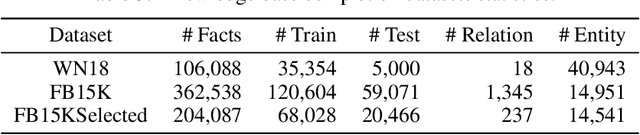
We study the problem of learning probabilistic first-order logical rules for knowledge base reasoning. This learning problem is difficult because it requires learning the parameters in a continuous space as well as the structure in a discrete space. We propose a framework, Neural Logic Programming, that combines the parameter and structure learning of first-order logical rules in an end-to-end differentiable model. This approach is inspired by a recently-developed differentiable logic called TensorLog, where inference tasks can be compiled into sequences of differentiable operations. We design a neural controller system that learns to compose these operations. Empirically, our method outperforms prior work on multiple knowledge base benchmark datasets, including Freebase and WikiMovies.
Key-Value Memory Networks for Directly Reading Documents
Oct 10, 2016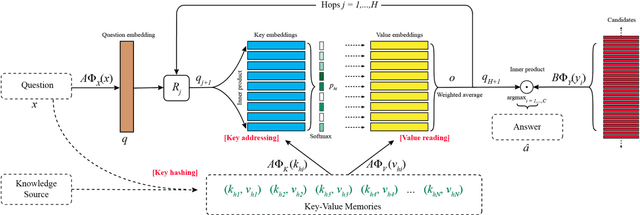

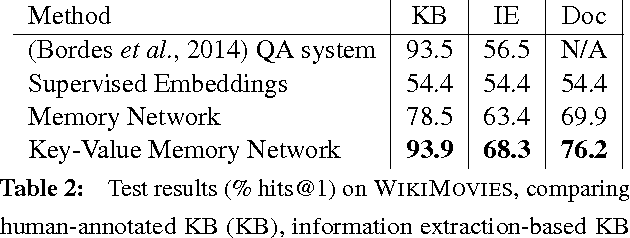

Directly reading documents and being able to answer questions from them is an unsolved challenge. To avoid its inherent difficulty, question answering (QA) has been directed towards using Knowledge Bases (KBs) instead, which has proven effective. Unfortunately KBs often suffer from being too restrictive, as the schema cannot support certain types of answers, and too sparse, e.g. Wikipedia contains much more information than Freebase. In this work we introduce a new method, Key-Value Memory Networks, that makes reading documents more viable by utilizing different encodings in the addressing and output stages of the memory read operation. To compare using KBs, information extraction or Wikipedia documents directly in a single framework we construct an analysis tool, WikiMovies, a QA dataset that contains raw text alongside a preprocessed KB, in the domain of movies. Our method reduces the gap between all three settings. It also achieves state-of-the-art results on the existing WikiQA benchmark.