 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhu Rs19
Papers and Code
Homogeneous Tokenizer Matters: Homogeneous Visual Tokenizer for Remote Sensing Image Understanding
Mar 27, 2024



The tokenizer, as one of the fundamental components of large models, has long been overlooked or even misunderstood in visual tasks. One key factor of the great comprehension power of the large language model is that natural language tokenizers utilize meaningful words or subwords as the basic elements of language. In contrast, mainstream visual tokenizers, represented by patch-based methods such as Patch Embed, rely on meaningless rectangular patches as basic elements of vision, which cannot serve as effectively as words or subwords in language. Starting from the essence of the tokenizer, we defined semantically independent regions (SIRs) for vision. We designed a simple HOmogeneous visual tOKenizer: HOOK. HOOK mainly consists of two modules: the Object Perception Module (OPM) and the Object Vectorization Module (OVM). To achieve homogeneity, the OPM splits the image into 4*4 pixel seeds and then utilizes the attention mechanism to perceive SIRs. The OVM employs cross-attention to merge seeds within the same SIR. To achieve adaptability, the OVM defines a variable number of learnable vectors as cross-attention queries, allowing for the adjustment of token quantity. We conducted experiments on the NWPU-RESISC45, WHU-RS19 classification dataset, and GID5 segmentation dataset for sparse and dense tasks. The results demonstrate that the visual tokens obtained by HOOK correspond to individual objects, which demonstrates homogeneity. HOOK outperformed Patch Embed by 6\% and 10\% in the two tasks and achieved state-of-the-art performance compared to the baselines used for comparison. Compared to Patch Embed, which requires more than one hundred tokens for one image, HOOK requires only 6 and 8 tokens for sparse and dense tasks, respectively, resulting in efficiency improvements of 1.5 to 2.8 times. The code is available at https://github.com/GeoX-Lab/Hook.
Robust Remote Sensing Scene Classification with Multi-View Voting and Entropy Ranking
Jan 14, 2023Deep convolutional neural networks have been widely used in scene classification of remotely sensed images. In this work, we propose a robust learning method for the task that is secure against partially incorrect categorization of images. Specifically, we remove and correct errors in the labels progressively by iterative multi-view voting and entropy ranking. At each time step, we first divide the training data into disjoint parts for separate training and voting. The unanimity in the voting reveals the correctness of the labels, so that we can train a strong model with only the images with unanimous votes. In addition, we adopt entropy as an effective measure for prediction uncertainty, in order to partially recover labeling errors by ranking and selection. We empirically demonstrate the superiority of the proposed method on the WHU-RS19 dataset and the AID dataset.
Land Cover and Land Use Detection using Semi-Supervised Learning
Dec 21, 2022Semi-supervised learning (SSL) has made significant strides in the field of remote sensing. Finding a large number of labeled datasets for SSL methods is uncommon, and manually labeling datasets is expensive and time-consuming. Furthermore, accurately identifying remote sensing satellite images is more complicated than it is for conventional images. Class-imbalanced datasets are another prevalent phenomenon, and models trained on these become biased towards the majority classes. This becomes a critical issue with an SSL model's subpar performance. We aim to address the issue of labeling unlabeled data and also solve the model bias problem due to imbalanced datasets while achieving better accuracy. To accomplish this, we create "artificial" labels and train a model to have reasonable accuracy. We iteratively redistribute the classes through resampling using a distribution alignment technique. We use a variety of class imbalanced satellite image datasets: EuroSAT, UCM, and WHU-RS19. On UCM balanced dataset, our method outperforms previous methods MSMatch and FixMatch by 1.21% and 0.6%, respectively. For imbalanced EuroSAT, our method outperforms MSMatch and FixMatch by 1.08% and 1%, respectively. Our approach significantly lessens the requirement for labeled data, consistently outperforms alternative approaches, and resolves the issue of model bias caused by class imbalance in datasets.
Binary Patterns Encoded Convolutional Neural Networks for Texture Recognition and Remote Sensing Scene Classification
Mar 26, 2018
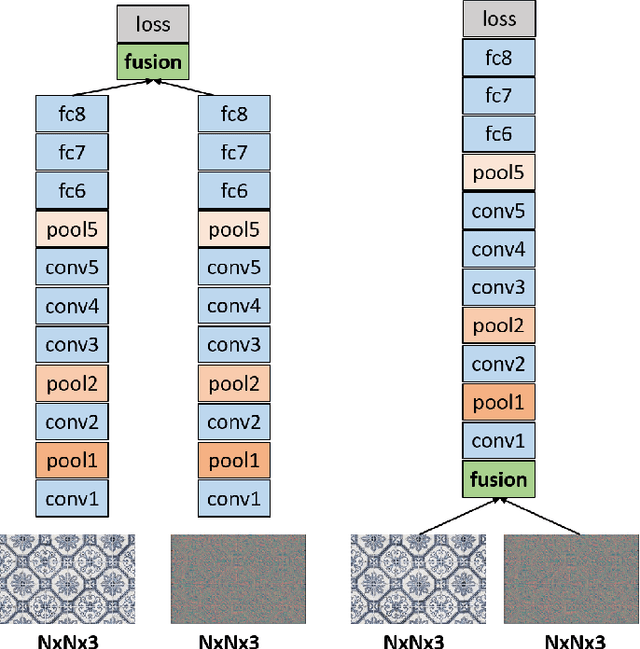
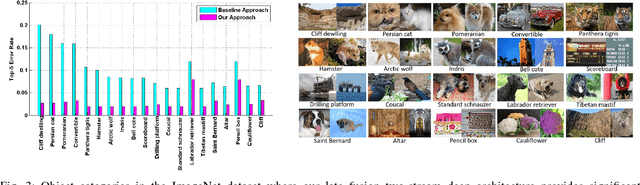

Designing discriminative powerful texture features robust to realistic imaging conditions is a challenging computer vision problem with many applications, including material recognition and analysis of satellite or aerial imagery. In the past, most texture description approaches were based on dense orderless statistical distribution of local features. However, most recent approaches to texture recognition and remote sensing scene classification are based on Convolutional Neural Networks (CNNs). The d facto practice when learning these CNN models is to use RGB patches as input with training performed on large amounts of labeled data (ImageNet). In this paper, we show that Binary Patterns encoded CNN models, codenamed TEX-Nets, trained using mapped coded images with explicit texture information provide complementary information to the standard RGB deep models. Additionally, two deep architectures, namely early and late fusion, are investigated to combine the texture and color information. To the best of our knowledge, we are the first to investigate Binary Patterns encoded CNNs and different deep network fusion architectures for texture recognition and remote sensing scene classification. We perform comprehensive experiments on four texture recognition datasets and four remote sensing scene classification benchmarks: UC-Merced with 21 scene categories, WHU-RS19 with 19 scene classes, RSSCN7 with 7 categories and the recently introduced large scale aerial image dataset (AID) with 30 aerial scene types. We demonstrate that TEX-Nets provide complementary information to standard RGB deep model of the same network architecture. Our late fusion TEX-Net architecture always improves the overall performance compared to the standard RGB network on both recognition problems. Our final combination outperforms the state-of-the-art without employing fine-tuning or ensemble of RGB network architectures.
AID: A Benchmark Dataset for Performance Evaluation of Aerial Scene Classification
Aug 18, 2016
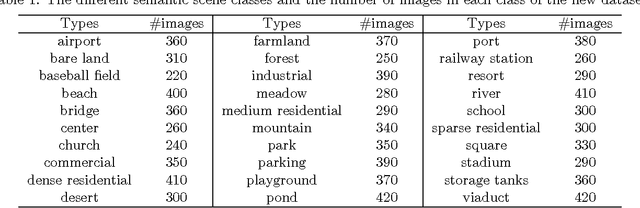


Aerial scene classification, which aims to automatically label an aerial image with a specific semantic category, is a fundamental problem for understanding high-resolution remote sensing imagery. In recent years, it has become an active task in remote sensing area and numerous algorithms have been proposed for this task, including many machine learning and data-driven approaches. However, the existing datasets for aerial scene classification like UC-Merced dataset and WHU-RS19 are with relatively small sizes, and the results on them are already saturated. This largely limits the development of scene classification algorithms. This paper describes the Aerial Image Dataset (AID): a large-scale dataset for aerial scene classification. The goal of AID is to advance the state-of-the-arts in scene classification of remote sensing images. For creating AID, we collect and annotate more than ten thousands aerial scene images. In addition, a comprehensive review of the existing aerial scene classification techniques as well as recent widely-used deep learning methods is given. Finally, we provide a performance analysis of typical aerial scene classification and deep learning approaches on AID, which can be served as the baseline results on this benchmark.