 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Anomaly Detection In Sound
Unsupervised anomaly detection in sound is the process of identifying unusual or abnormal sounds without using labeled examples.
Papers and Code
Contrastive Learning with Spectrum Information Augmentation in Abnormal Sound Detection
Sep 19, 2025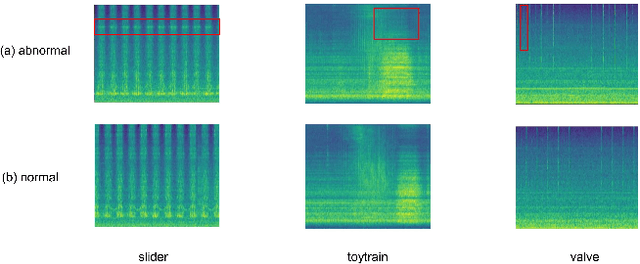

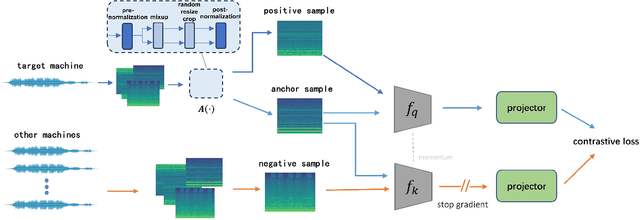

The outlier exposure method is an effective approach to address the unsupervised anomaly sound detection problem. The key focus of this method is how to make the model learn the distribution space of normal data. Based on biological perception and data analysis, it is found that anomalous audio and noise often have higher frequencies. Therefore, we propose a data augmentation method for high-frequency information in contrastive learning. This enables the model to pay more attention to the low-frequency information of the audio, which represents the normal operational mode of the machine. We evaluated the proposed method on the DCASE 2020 Task 2. The results showed that our method outperformed other contrastive learning methods used on this dataset. We also evaluated the generalizability of our method on the DCASE 2022 Task 2 dataset.
MIMII-Agent: Leveraging LLMs with Function Calling for Relative Evaluation of Anomalous Sound Detection
Jul 28, 2025This paper proposes a method for generating machine-type-specific anomalies to evaluate the relative performance of unsupervised anomalous sound detection (UASD) systems across different machine types, even in the absence of real anomaly sound data. Conventional keyword-based data augmentation methods often produce unrealistic sounds due to their reliance on manually defined labels, limiting scalability as machine types and anomaly patterns diversify. Advanced audio generative models, such as MIMII-Gen, show promise but typically depend on anomalous training data, making them less effective when diverse anomalous examples are unavailable. To address these limitations, we propose a novel synthesis approach leveraging large language models (LLMs) to interpret textual descriptions of faults and automatically select audio transformation functions, converting normal machine sounds into diverse and plausible anomalous sounds. We validate this approach by evaluating a UASD system trained only on normal sounds from five machine types, using both real and synthetic anomaly data. Experimental results reveal consistent trends in relative detection difficulty across machine types between synthetic and real anomalies. This finding supports our hypothesis and highlights the effectiveness of the proposed LLM-based synthesis approach for relative evaluation of UASD systems.
Addressing Out-of-Label Hazard Detection in Dashcam Videos: Insights from the COOOL Challenge
Jan 27, 2025This paper presents a novel approach for hazard analysis in dashcam footage, addressing the detection of driver reactions to hazards, the identification of hazardous objects, and the generation of descriptive captions. We first introduce a method for detecting driver reactions through speed and sound anomaly detection, leveraging unsupervised learning techniques. For hazard detection, we employ a set of heuristic rules as weak classifiers, which are combined using an ensemble method. This ensemble approach is further refined with differential privacy to mitigate overconfidence, ensuring robustness despite the lack of labeled data. Lastly, we use state-of-the-art vision-language models for hazard captioning, generating descriptive labels for the detected hazards. Our method achieved the highest scores in the Challenge on Out-of-Label in Autonomous Driving, demonstrating its effectiveness across all three tasks. Source codes are publicly available at https://github.com/ffyyytt/COOOL_2025.
Low-complexity Attention-based Unsupervised Anomalous Sound Detection exploiting Separable Convolutions and Angular Loss
Oct 11, 2024



In this work, a novel deep neural network, designed to enhance the efficiency and effectiveness of unsupervised sound anomaly detection, is presented. The proposed model exploits an attention module and separable convolutions to identify salient time-frequency patterns in audio data to discriminate between normal and anomalous sounds with reduced computational complexity. The approach is validated through extensive experiments using the Task 2 dataset of the DCASE 2020 challenge. Results demonstrate superior performance in terms of anomaly detection accuracy while having fewer parameters than state-of-the-art methods. Implementation details, code, and pre-trained models are available in https://github.com/michaelneri/unsupervised-audio-anomaly-detection.
ASD-Diffusion: Anomalous Sound Detection with Diffusion Models
Sep 24, 2024Unsupervised Anomalous Sound Detection (ASD) aims to design a generalizable method that can be used to detect anomalies when only normal sounds are given. In this paper, Anomalous Sound Detection based on Diffusion Models (ASD-Diffusion) is proposed for ASD in real-world factories. In our pipeline, the anomalies in acoustic features are reconstructed from their noisy corrupted features into their approximate normal pattern. Secondly, a post-processing anomalies filter algorithm is proposed to detect anomalies that exhibit significant deviation from the original input after reconstruction. Furthermore, denoising diffusion implicit model is introduced to accelerate the inference speed by a longer sampling interval of the denoising process. The proposed method is innovative in the application of diffusion models as a new scheme. Experimental results on the development set of DCASE 2023 challenge task 2 outperform the baseline by 7.75%, demonstrating the effectiveness of the proposed method.
Unsupervised detection and classification of heartbeats using the dissimilarity matrix in PCG signals
Nov 05, 2024



The proposed system consists of a two-stage cascade. The first stage performs a rough heartbeat detection while the second stage refines the previous one, improving the temporal localization and also classifying the heartbeats into types S1 and S2. The first contribution is a novel approach that combines the dissimilarity matrix with the frame-level spectral divergence to locate heartbeats using the repetitiveness shown by the heart sounds and the temporal relationships between the intervals defined by the events S1/S2 and non-S1/S2 (systole and diastole). The second contribution is a verification-correction-classification process based on a sliding window that allows the preservation of the temporal structure of the cardiac cycle in order to be applied in the heart sound classification. The proposed method has been assessed using the open access databases PASCAL, CirCor DigiScope Phonocardiogram and an additional sound mixing procedure considering both Additive White Gaussian Noise (AWGN) and different kinds of clinical ambient noises from a commercial database. The proposed method provides the best detection/classification performance in realistic scenarios where the presence of cardiac anomalies as well as different types of clinical environmental noises are active in the PCG signal. Of note, the promising modelling of the temporal structures of the heart provided by the dissimilarity matrix together with the frame-level spectral divergence, as well as the removal of a significant number of spurious heart events and recovery of missing heart events, both corrected by the proposed verification-correction-classification algorithm, suggest that our proposal is a successful tool to be applied in heart segmentation.
First-Shot Unsupervised Anomalous Sound Detection With Unknown Anomalies Estimated by Metadata-Assisted Audio Generation
Oct 22, 2023



First-shot (FS) unsupervised anomalous sound detection (ASD) is a brand-new task introduced in DCASE 2023 Challenge Task 2, where the anomalous sounds for the target machine types are unseen in training. Existing methods often rely on the availability of normal and abnormal sound data from the target machines. However, due to the lack of anomalous sound data for the target machine types, it becomes challenging when adapting the existing ASD methods to the first-shot task. In this paper, we propose a new framework for the first-shot unsupervised ASD, where metadata-assisted audio generation is used to estimate unknown anomalies, by utilising the available machine information (i.e., metadata and sound data) to fine-tune a text-to-audio generation model for generating the anomalous sounds that contain unique acoustic characteristics accounting for each different machine types. We then use the method of Time-Weighted Frequency domain audio Representation with Gaussian Mixture Model (TWFR-GMM) as the backbone to achieve the first-shot unsupervised ASD. Our proposed FS-TWFR-GMM method achieves competitive performance amongst top systems in DCASE 2023 Challenge Task 2, while requiring only 1% model parameters for detection, as validated in our experiments.
Transformer-based Autoencoder with ID Constraint for Unsupervised Anomalous Sound Detection
Oct 13, 2023Unsupervised anomalous sound detection (ASD) aims to detect unknown anomalous sounds of devices when only normal sound data is available. The autoencoder (AE) and self-supervised learning based methods are two mainstream methods. However, the AE-based methods could be limited as the feature learned from normal sounds can also fit with anomalous sounds, reducing the ability of the model in detecting anomalies from sound. The self-supervised methods are not always stable and perform differently, even for machines of the same type. In addition, the anomalous sound may be short-lived, making it even harder to distinguish from normal sound. This paper proposes an ID constrained Transformer-based autoencoder (IDC-TransAE) architecture with weighted anomaly score computation for unsupervised ASD. Machine ID is employed to constrain the latent space of the Transformer-based autoencoder (TransAE) by introducing a simple ID classifier to learn the difference in the distribution for the same machine type and enhance the ability of the model in distinguishing anomalous sound. Moreover, weighted anomaly score computation is introduced to highlight the anomaly scores of anomalous events that only appear for a short time. Experiments performed on DCASE 2020 Challenge Task2 development dataset demonstrate the effectiveness and superiority of our proposed method.
IA Para el Mantenimiento Predictivo en Canteras: Modelado
Oct 24, 2023Dependence on raw materials, especially in the mining sector, is a key part of today's economy. Aggregates are vital, being the second most used raw material after water. Digitally transforming this sector is key to optimizing operations. However, supervision and maintenance (predictive and corrective) are challenges little explored in this sector, due to the particularities of the sector, machinery and environmental conditions. All this, despite the successes achieved in other scenarios in monitoring with acoustic and contact sensors. We present an unsupervised learning scheme that trains a variational autoencoder model on a set of sound records. This is the first such dataset collected during processing plant operations, containing information from different points of the processing line. Our results demonstrate the model's ability to reconstruct and represent in latent space the recorded sounds, the differences in operating conditions and between different equipment. In the future, this should facilitate the classification of sounds, as well as the detection of anomalies and degradation patterns in the operation of the machinery.
First-shot anomaly sound detection for machine condition monitoring: A domain generalization baseline
Mar 01, 2023


This paper provides a baseline system for First-shot-compliant unsupervised anomaly detection (ASD) for machine condition monitoring. First-shot ASD does not allow systems to do machine-type dependent hyperparameter tuning or tool ensembling based on the performance metric calculated with the grand truth. To show benchmark performance for First-shot ASD, this paper proposes an anomaly sound detection system that works on the domain generalization task in the Detection and Classification of Acoustic Scenes and Events (DCASE) 2022 Challenge Task 2: "Unsupervised Anomalous Sound Detection for Machine Condition Monitoring Applying Domain Generalization Technique" while complying with the First-shot requirements introduced in the DCASE 2023 Challenge Task 2 (DCASE2023T2). A simple autoencoder based implementation combined with selective Mahalanobis metric is implemented as a baseline system. The performance evaluation is conducted to set the target benchmark for the forthcoming DCASE2023T2. Source code of the baseline system will be available on GitHub: https://github.com/nttcslab/dcase2023_task2_baseline_ae .