 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOulu Npu
Papers and Code
Face Presentation Attack Detection via Content-Adaptive Spatial Operators
Feb 21, 2026Face presentation attack detection (FacePAD) is critical for securing facial authentication against print, replay, and mask-based spoofing. This paper proposes CASO-PAD, an RGB-only, single-frame model that enhances MobileNetV3 with content-adaptive spatial operators (involution) to better capture localized spoof cues. Unlike spatially shared convolution kernels, the proposed operator generates location-specific, channel-shared kernels conditioned on the input, improving spatial selectivity with minimal overhead. CASO-PAD remains lightweight (3.6M parameters; 0.64 GFLOPs at $256\times256$) and is trained end-to-end using a standard binary cross-entropy objective. Extensive experiments on Replay-Attack, Replay-Mobile, ROSE-Youtu, and OULU-NPU demonstrate strong performance, achieving 100/100/98.9/99.7\% test accuracy, AUC of 1.00/1.00/0.9995/0.9999, and HTER of 0.00/0.00/0.82/0.44\%, respectively. On the large-scale SiW-Mv2 Protocol-1 benchmark, CASO-PAD further attains 95.45\% accuracy with 3.11\% HTER and 3.13\% EER, indicating improved robustness under diverse real-world attacks. Ablation studies show that placing the adaptive operator near the network head and using moderate group sharing yields the best accuracy--efficiency balance. Overall, CASO-PAD provides a practical pathway for robust, on-device FacePAD with mobile-class compute and without auxiliary sensors or temporal stacks.
Leveraging Intermediate Features of Vision Transformer for Face Anti-Spoofing
May 30, 2025Face recognition systems are designed to be robust against changes in head pose, illumination, and blurring during image capture. If a malicious person presents a face photo of the registered user, they may bypass the authentication process illegally. Such spoofing attacks need to be detected before face recognition. In this paper, we propose a spoofing attack detection method based on Vision Transformer (ViT) to detect minute differences between live and spoofed face images. The proposed method utilizes the intermediate features of ViT, which have a good balance between local and global features that are important for spoofing attack detection, for calculating loss in training and score in inference. The proposed method also introduces two data augmentation methods: face anti-spoofing data augmentation and patch-wise data augmentation, to improve the accuracy of spoofing attack detection. We demonstrate the effectiveness of the proposed method through experiments using the OULU-NPU and SiW datasets.
Hyp-OC: Hyperbolic One Class Classification for Face Anti-Spoofing
Apr 22, 2024



Face recognition technology has become an integral part of modern security systems and user authentication processes. However, these systems are vulnerable to spoofing attacks and can easily be circumvented. Most prior research in face anti-spoofing (FAS) approaches it as a two-class classification task where models are trained on real samples and known spoof attacks and tested for detection performance on unknown spoof attacks. However, in practice, FAS should be treated as a one-class classification task where, while training, one cannot assume any knowledge regarding the spoof samples a priori. In this paper, we reformulate the face anti-spoofing task from a one-class perspective and propose a novel hyperbolic one-class classification framework. To train our network, we use a pseudo-negative class sampled from the Gaussian distribution with a weighted running mean and propose two novel loss functions: (1) Hyp-PC: Hyperbolic Pairwise Confusion loss, and (2) Hyp-CE: Hyperbolic Cross Entropy loss, which operate in the hyperbolic space. Additionally, we employ Euclidean feature clipping and gradient clipping to stabilize the training in the hyperbolic space. To the best of our knowledge, this is the first work extending hyperbolic embeddings for face anti-spoofing in a one-class manner. With extensive experiments on five benchmark datasets: Rose-Youtu, MSU-MFSD, CASIA-MFSD, Idiap Replay-Attack, and OULU-NPU, we demonstrate that our method significantly outperforms the state-of-the-art, achieving better spoof detection performance.
CLIPC8: Face liveness detection algorithm based on image-text pairs and contrastive learning
Nov 29, 2023



Face recognition technology is widely used in the financial field, and various types of liveness attack behaviors need to be addressed. Existing liveness detection algorithms are trained on specific training datasets and tested on testing datasets, but their performance and robustness in transferring to unseen datasets are relatively poor. To tackle this issue, we propose a face liveness detection method based on image-text pairs and contrastive learning, dividing liveness attack problems in the financial field into eight categories and using text information to describe the images of these eight types of attacks. The text encoder and image encoder are used to extract feature vector representations for the classification description text and face images, respectively. By maximizing the similarity of positive samples and minimizing the similarity of negative samples, the model learns shared representations between images and texts. The proposed method is capable of effectively detecting specific liveness attack behaviors in certain scenarios, such as those occurring in dark environments or involving the tampering of ID card photos. Additionally, it is also effective in detecting traditional liveness attack methods, such as printing photo attacks and screen remake attacks. The zero-shot capabilities of face liveness detection on five public datasets, including NUAA, CASIA-FASD, Replay-Attack, OULU-NPU and MSU-MFSD also reaches the level of commercial algorithms. The detection capability of proposed algorithm was verified on 5 types of testing datasets, and the results show that the method outperformed commercial algorithms, and the detection rates reached 100% on multiple datasets. Demonstrating the effectiveness and robustness of introducing image-text pairs and contrastive learning into liveness detection tasks as proposed in this paper.
Semi-Supervised learning for Face Anti-Spoofing using Apex frame
Sep 10, 2023


Conventional feature extraction techniques in the face anti-spoofing domain either analyze the entire video sequence or focus on a specific segment to improve model performance. However, identifying the optimal frames that provide the most valuable input for the face anti-spoofing remains a challenging task. In this paper, we address this challenge by employing Gaussian weighting to create apex frames for videos. Specifically, an apex frame is derived from a video by computing a weighted sum of its frames, where the weights are determined using a Gaussian distribution centered around the video's central frame. Furthermore, we explore various temporal lengths to produce multiple unlabeled apex frames using a Gaussian function, without the need for convolution. By doing so, we leverage the benefits of semi-supervised learning, which considers both labeled and unlabeled apex frames to effectively discriminate between live and spoof classes. Our key contribution emphasizes the apex frame's capacity to represent the most significant moments in the video, while unlabeled apex frames facilitate efficient semi-supervised learning, as they enable the model to learn from videos of varying temporal lengths. Experimental results using four face anti-spoofing databases: CASIA, REPLAY-ATTACK, OULU-NPU, and MSU-MFSD demonstrate the apex frame's efficacy in advancing face anti-spoofing techniques.
Hyperbolic Face Anti-Spoofing
Aug 17, 2023



Learning generalized face anti-spoofing (FAS) models against presentation attacks is essential for the security of face recognition systems. Previous FAS methods usually encourage models to extract discriminative features, of which the distances within the same class (bonafide or attack) are pushed close while those between bonafide and attack are pulled away. However, these methods are designed based on Euclidean distance, which lacks generalization ability for unseen attack detection due to poor hierarchy embedding ability. According to the evidence that different spoofing attacks are intrinsically hierarchical, we propose to learn richer hierarchical and discriminative spoofing cues in hyperbolic space. Specifically, for unimodal FAS learning, the feature embeddings are projected into the Poincar\'e ball, and then the hyperbolic binary logistic regression layer is cascaded for classification. To further improve generalization, we conduct hyperbolic contrastive learning for the bonafide only while relaxing the constraints on diverse spoofing attacks. To alleviate the vanishing gradient problem in hyperbolic space, a new feature clipping method is proposed to enhance the training stability of hyperbolic models. Besides, we further design a multimodal FAS framework with Euclidean multimodal feature decomposition and hyperbolic multimodal feature fusion & classification. Extensive experiments on three benchmark datasets (i.e., WMCA, PADISI-Face, and SiW-M) with diverse attack types demonstrate that the proposed method can bring significant improvement compared to the Euclidean baselines on unseen attack detection. In addition, the proposed framework is also generalized well on four benchmark datasets (i.e., MSU-MFSD, IDIAP REPLAY-ATTACK, CASIA-FASD, and OULU-NPU) with a limited number of attack types.
Deep Ensemble Learning with Frame Skipping for Face Anti-Spoofing
Jul 11, 2023Face presentation attacks (PA), also known as spoofing attacks, pose a substantial threat to biometric systems that rely on facial recognition systems, such as access control systems, mobile payments, and identity verification systems. To mitigate the spoofing risk, several video-based methods have been presented in the literature that analyze facial motion in successive video frames. However, estimating the motion between adjacent frames is a challenging task and requires high computational cost. In this paper, we rephrase the face anti-spoofing task as a motion prediction problem and introduce a deep ensemble learning model with a frame skipping mechanism. In particular, the proposed frame skipping adopts a uniform sampling approach by dividing the original video into video clips of fixed size. By doing so, every nth frame of the clip is selected to ensure that the temporal patterns can easily be perceived during the training of three different recurrent neural networks (RNNs). Motivated by the performance of individual RNNs, a meta-model is developed to improve the overall detection performance by combining the prediction of individual RNNs. Extensive experiments were performed on four datasets, and state-of-the-art performance is reported on MSU-MFSD (3.12%), Replay-Attack (11.19%), and OULU-NPU (12.23%) databases by using half total error rates (HTERs) in the most challenging cross-dataset testing scenario.
Domain Generalization via Ensemble Stacking for Face Presentation Attack Detection
Jan 05, 2023Face presentation attack detection (PAD) plays a pivotal role in securing face recognition systems against spoofing attacks. Although great progress has been made in designing face PAD methods, developing a model that can generalize well to an unseen test domain remains a significant challenge. Moreover, due to different types of spoofing attacks, creating a dataset with a sufficient number of samples for training deep neural networks is a laborious task. This work addresses these challenges by creating synthetic data and introducing a deep learning-based unified framework for improving the generalization ability of the face PAD. In particular, synthetic data is generated by proposing a video distillation technique that blends a spatiotemporal warped image with a still image based on alpha compositing. Since the proposed synthetic samples can be generated by increasing different alpha weights, we train multiple classifiers by taking the advantage of a specific type of ensemble learning known as a stacked ensemble, where each such classifier becomes an expert in its own domain but a non-expert to others. Motivated by this, a meta-classifier is employed to learn from these experts collaboratively so that when developing an ensemble, they can leverage complementary information from each other to better tackle or be more useful for an unseen target domain. Experimental results using half total error rates (HTERs) on four PAD databases CASIA-MFSD (6.97 %), Replay-Attack (33.49%), MSU-MFSD (4.02%), and OULU-NPU (10.91%)) demonstrate the robustness of the method and open up new possibilities for advancing presentation attack detection using ensemble learning with large-scale synthetic data.
Multi-Frames Temporal Abnormal Clues Learning Method for Face Anti-Spoofing
Aug 08, 2022
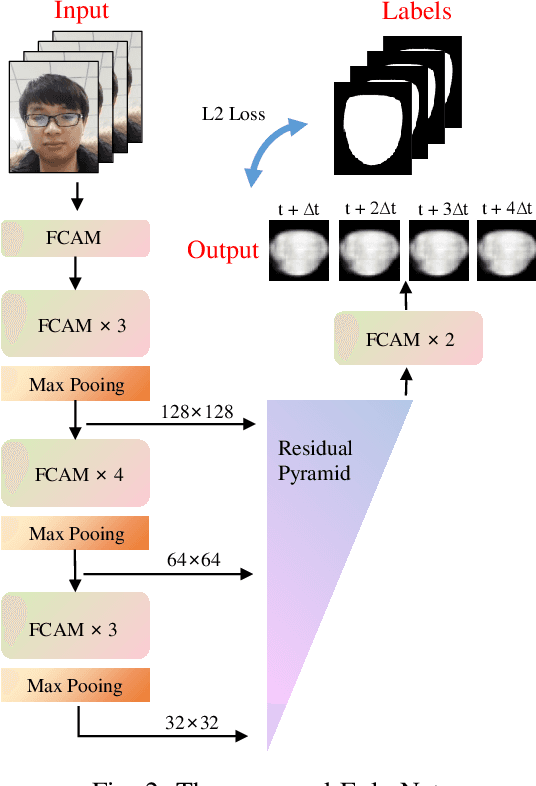
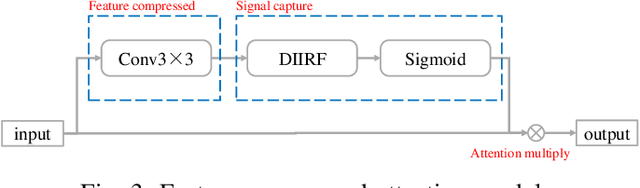
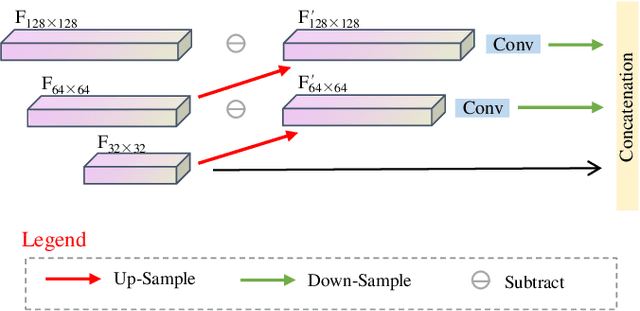
Face anti-spoofing researches are widely used in face recognition and has received more attention from industry and academics. In this paper, we propose the EulerNet, a new temporal feature fusion network in which the differential filter and residual pyramid are used to extract and amplify abnormal clues from continuous frames, respectively. A lightweight sample labeling method based on face landmarks is designed to label large-scale samples at a lower cost and has better results than other methods such as 3D camera. Finally, we collect 30,000 live and spoofing samples using various mobile ends to create a dataset that replicates various forms of attacks in a real-world setting. Extensive experiments on public OULU-NPU show that our algorithm is superior to the state of art and our solution has already been deployed in real-world systems servicing millions of users.
Self-Supervised Face Presentation Attack Detection with Dynamic Grayscale Snippets
Aug 27, 2022
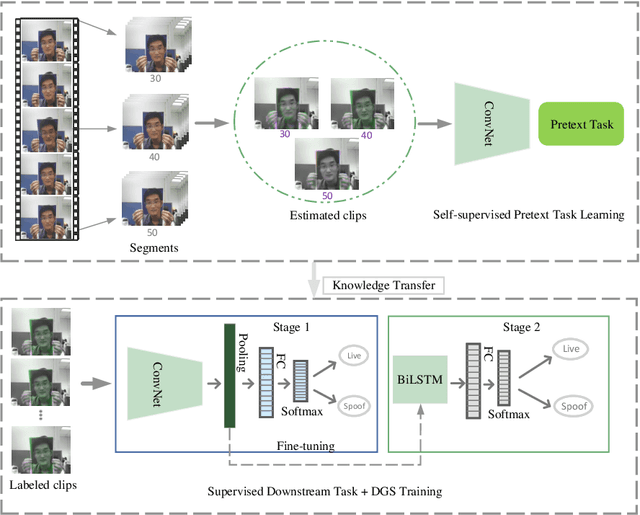
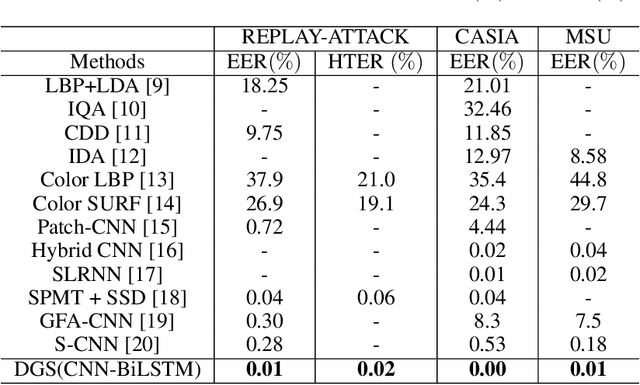
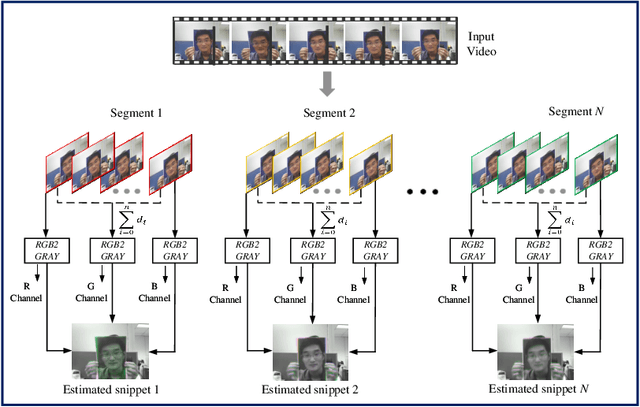
Face presentation attack detection (PAD) plays an important role in defending face recognition systems against presentation attacks. The success of PAD largely relies on supervised learning that requires a huge number of labeled data, which is especially challenging for videos and often requires expert knowledge. To avoid the costly collection of labeled data, this paper presents a novel method for self-supervised video representation learning via motion prediction. To achieve this, we exploit the temporal consistency based on three RGB frames which are acquired at three different times in the video sequence. The obtained frames are then transformed into grayscale images where each image is specified to three different channels such as R(red), G(green), and B(blue) to form a dynamic grayscale snippet (DGS). Motivated by this, the labels are automatically generated to increase the temporal diversity based on DGS by using the different temporal lengths of the videos, which prove to be very helpful for the downstream task. Benefiting from the self-supervised nature of our method, we report the results that outperform existing methods on four public benchmark datasets, namely Replay-Attack, MSU-MFSD, CASIA-FASD, and OULU-NPU. Explainability analysis has been carried out through LIME and Grad-CAM techniques to visualize the most important features used in the DGS.