 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobilebert
Papers and Code
Lightweight Transformer Architectures for Edge Devices in Real-Time Applications
Jan 05, 2026The deployment of transformer-based models on resource-constrained edge devices represents a critical challenge in enabling real-time artificial intelligence applications. This comprehensive survey examines lightweight transformer architectures specifically designed for edge deployment, analyzing recent advances in model compression, quantization, pruning, and knowledge distillation techniques. We systematically review prominent lightweight variants including MobileBERT, TinyBERT, DistilBERT, EfficientFormer, EdgeFormer, and MobileViT, providing detailed performance benchmarks on standard datasets such as GLUE, SQuAD, ImageNet-1K, and COCO. Our analysis encompasses current industry adoption patterns across major hardware platforms (NVIDIA Jetson, Qualcomm Snapdragon, Apple Neural Engine, ARM architectures), deployment frameworks (TensorFlow Lite, ONNX Runtime, PyTorch Mobile, CoreML), and optimization strategies. Experimental results demonstrate that modern lightweight transformers can achieve 75-96% of full-model accuracy while reducing model size by 4-10x and inference latency by 3-9x, enabling deployment on devices with as little as 2-5W power consumption. We identify sparse attention mechanisms, mixed-precision quantization (INT8/FP16), and hardware-aware neural architecture search as the most effective optimization strategies. Novel findings include memory-bandwidth bottleneck analysis revealing 15-40M parameter models achieve optimal hardware utilization (60-75% efficiency), quantization sweet spots for different model types, and comprehensive energy efficiency profiling across edge platforms. We establish real-time performance boundaries and provide a practical 6-step deployment pipeline achieving 8-12x size reduction with less than 2% accuracy degradation.
Efficient Intent-Based Filtering for Multi-Party Conversations Using Knowledge Distillation from LLMs
Mar 21, 2025



Large language models (LLMs) have showcased remarkable capabilities in conversational AI, enabling open-domain responses in chat-bots, as well as advanced processing of conversations like summarization, intent classification, and insights generation. However, these models are resource-intensive, demanding substantial memory and computational power. To address this, we propose a cost-effective solution that filters conversational snippets of interest for LLM processing, tailored to the target downstream application, rather than processing every snippet. In this work, we introduce an innovative approach that leverages knowledge distillation from LLMs to develop an intent-based filter for multi-party conversations, optimized for compute power constrained environments. Our method combines different strategies to create a diverse multi-party conversational dataset, that is annotated with the target intents and is then used to fine-tune the MobileBERT model for multi-label intent classification. This model achieves a balance between efficiency and performance, effectively filtering conversation snippets based on their intents. By passing only the relevant snippets to the LLM for further processing, our approach significantly reduces overall operational costs depending on the intents and the data distribution as demonstrated in our experiments.
Resource-Efficient Transformer Architecture: Optimizing Memory and Execution Time for Real-Time Applications
Dec 25, 2024


This paper describes a memory-efficient transformer model designed to drive a reduction in memory usage and execution time by substantial orders of magnitude without impairing the model's performance near that of the original model. Recently, new architectures of transformers were presented, focused on parameter efficiency and computational optimization; however, such models usually require considerable resources in terms of hardware when deployed in real-world applications on edge devices. This approach addresses this concern by halving embedding size and applying targeted techniques such as parameter pruning and quantization to optimize the memory footprint with minimum sacrifices in terms of accuracy. Experimental results include a 52% reduction in memory usage and a 33% decrease in execution time, resulting in better efficiency than state-of-the-art models. This work compared our model with existing compelling architectures, such as MobileBERT and DistilBERT, and proved its feasibility in the domain of resource-friendly deep learning architectures, mainly for applications in real-time and in resource-constrained applications.
Efficient Deployment of Transformer Models in Analog In-Memory Computing Hardware
Nov 26, 2024



Analog in-memory computing (AIMC) has emerged as a promising solution to overcome the von Neumann bottleneck, accelerating neural network computations and improving computational efficiency. While AIMC has demonstrated success with architectures such as CNNs, MLPs, and RNNs, deploying transformer-based models using AIMC presents unique challenges. Transformers are expected to handle diverse downstream tasks and adapt to new user data or instructions after deployment, which requires more flexible approaches to suit AIMC constraints. In this paper, we propose a novel method for deploying pre-trained transformer models onto AIMC hardware. Unlike traditional approaches requiring hardware-aware training, our technique allows direct deployment without the need for retraining the original model. Instead, we utilize lightweight, low-rank adapters -- compact modules stored in digital cores -- to adapt the model to hardware constraints. We validate our approach on MobileBERT, demonstrating accuracy on par with, or even exceeding, a traditional hardware-aware training approach. Our method is particularly appealing in multi-task scenarios, as it enables a single analog model to be reused across multiple tasks. Moreover, it supports on-chip adaptation to new hardware constraints and tasks without updating analog weights, providing a flexible and versatile solution for real-world AI applications. Code is available.
On-Device Emoji Classifier Trained with GPT-based Data Augmentation for a Mobile Keyboard
Nov 06, 2024



Emojis improve communication quality among smart-phone users that use mobile keyboards to exchange text. To predict emojis for users based on input text, we should consider the on-device low memory and time constraints, ensure that the on-device emoji classifier covers a wide range of emoji classes even though the emoji dataset is typically imbalanced, and adapt the emoji classifier output to user favorites. This paper proposes an on-device emoji classifier based on MobileBert with reasonable memory and latency requirements for SwiftKey. To account for the data imbalance, we utilize the widely used GPT to generate one or more tags for each emoji class. For each emoji and corresponding tags, we merge the original set with GPT-generated sentences and label them with this emoji without human intervention to alleviate the data imbalance. At inference time, we interpolate the emoji output with the user history for emojis for better emoji classifications. Results show that the proposed on-device emoji classifier deployed for SwiftKey increases the accuracy performance of emoji prediction particularly on rare emojis and emoji engagement.
On Importance of Pruning and Distillation for Efficient Low Resource NLP
Sep 21, 2024


The rise of large transformer models has revolutionized Natural Language Processing, leading to significant advances in tasks like text classification. However, this progress demands substantial computational resources, escalating training duration, and expenses with larger model sizes. Efforts have been made to downsize and accelerate English models (e.g., Distilbert, MobileBert). Yet, research in this area is scarce for low-resource languages. In this study, we explore the case of the low-resource Indic language Marathi. Leveraging the marathi-topic-all-doc-v2 model as our baseline, we implement optimization techniques to reduce computation time and memory usage. Our focus is on enhancing the efficiency of Marathi transformer models while maintaining top-tier accuracy and reducing computational demands. Using the MahaNews document classification dataset and the marathi-topic-all-doc-v2 model from L3Cube, we apply Block Movement Pruning, Knowledge Distillation, and Mixed Precision methods individually and in combination to boost efficiency. We demonstrate the importance of strategic pruning levels in achieving desired efficiency gains. Furthermore, we analyze the balance between efficiency improvements and environmental impact, highlighting how optimized model architectures can contribute to a more sustainable computational ecosystem. Implementing these techniques on a single GPU system, we determine that the optimal configuration is 25\% pruning + knowledge distillation. This approach yielded a 2.56x speedup in computation time while maintaining baseline accuracy levels.
Toward Attention-based TinyML: A Heterogeneous Accelerated Architecture and Automated Deployment Flow
Aug 05, 2024One of the challenges for Tiny Machine Learning (tinyML) is keeping up with the evolution of Machine Learning models from Convolutional Neural Networks to Transformers. We address this by leveraging a heterogeneous architectural template coupling RISC-V processors with hardwired accelerators supported by an automated deployment flow. We demonstrate an Attention-based model in a tinyML power envelope with an octa-core cluster coupled with an accelerator for quantized Attention. Our deployment flow enables an end-to-end 8-bit MobileBERT, achieving leading-edge energy efficiency and throughput of 2960 GOp/J and 154 GOp/s at 32.5 Inf/s consuming 52.0 mW (0.65 V, 22 nm FD-SOI technology).
Quantized Transformer Language Model Implementations on Edge Devices
Oct 06, 2023Large-scale transformer-based models like the Bidirectional Encoder Representations from Transformers (BERT) are widely used for Natural Language Processing (NLP) applications, wherein these models are initially pre-trained with a large corpus with millions of parameters and then fine-tuned for a downstream NLP task. One of the major limitations of these large-scale models is that they cannot be deployed on resource-constrained devices due to their large model size and increased inference latency. In order to overcome these limitations, such large-scale models can be converted to an optimized FlatBuffer format, tailored for deployment on resource-constrained edge devices. Herein, we evaluate the performance of such FlatBuffer transformed MobileBERT models on three different edge devices, fine-tuned for Reputation analysis of English language tweets in the RepLab 2013 dataset. In addition, this study encompassed an evaluation of the deployed models, wherein their latency, performance, and resource efficiency were meticulously assessed. Our experiment results show that, compared to the original BERT large model, the converted and quantized MobileBERT models have 160$\times$ smaller footprints for a 4.1% drop in accuracy while analyzing at least one tweet per second on edge devices. Furthermore, our study highlights the privacy-preserving aspect of TinyML systems as all data is processed locally within a serverless environment.
ZipLM: Hardware-Aware Structured Pruning of Language Models
Feb 07, 2023



The breakthrough performance of large language models (LLMs) comes with large computational footprints and high deployment costs. In this paper, we progress towards resolving this problem by proposing a new structured compression approach for LLMs, called ZipLM, which provides state-of-the-art compression-vs-accuracy results, while guaranteeing to match a set of (achievable) target speedups on any given target hardware. Specifically, given a task, a model, an inference environment, as well as a set of speedup targets, ZipLM identifies and removes redundancies in the model through iterative structured shrinking of the model's weight matrices. Importantly, ZipLM works in both, the post-training/one-shot and the gradual compression setting, where it produces a set of accurate models in a single run, making it highly-efficient in practice. Our approach is based on new structured pruning and knowledge distillation techniques, and consistently outperforms prior structured compression methods in terms of accuracy-versus-speedup in experiments on BERT- and GPT-family models. In particular, when compressing GPT2 model, it outperforms DistilGPT2 while being 60% smaller and 30% faster. Further, ZipLM matches performance of heavily optimized MobileBERT model, obtained via extensive architecture search, by simply pruning the baseline BERT-large architecture, and outperforms all prior BERT-base compression techniques like CoFi, MiniLM and TinyBERT.
AutoDistill: an End-to-End Framework to Explore and Distill Hardware-Efficient Language Models
Jan 21, 2022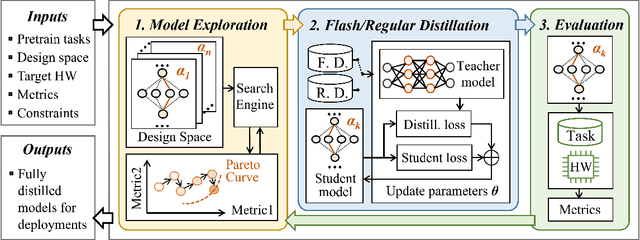
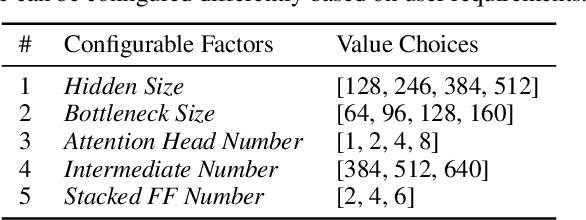
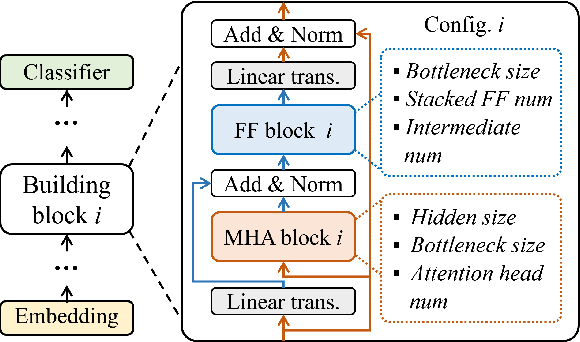
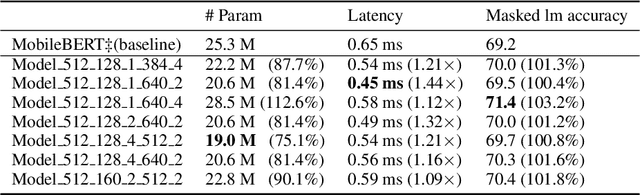
Recently, large pre-trained models have significantly improved the performance of various Natural LanguageProcessing (NLP) tasks but they are expensive to serve due to long serving latency and large memory usage. To compress these models, knowledge distillation has attracted an increasing amount of interest as one of the most effective methods for model compression. However, existing distillation methods have not yet addressed the unique challenges of model serving in datacenters, such as handling fast evolving models, considering serving performance, and optimizing for multiple objectives. To solve these problems, we propose AutoDistill, an end-to-end model distillation framework integrating model architecture exploration and multi-objective optimization for building hardware-efficient NLP pre-trained models. We use Bayesian Optimization to conduct multi-objective Neural Architecture Search for selecting student model architectures. The proposed search comprehensively considers both prediction accuracy and serving latency on target hardware. The experiments on TPUv4i show the finding of seven model architectures with better pre-trained accuracy (up to 3.2% higher) and lower inference latency (up to 1.44x faster) than MobileBERT. By running downstream NLP tasks in the GLUE benchmark, the model distilled for pre-training by AutoDistill with 28.5M parameters achieves an 81.69 average score, which is higher than BERT_BASE, DistillBERT, TinyBERT, NAS-BERT, and MobileBERT. The most compact model found by AutoDistill contains only 20.6M parameters but still outperform BERT_BASE(109M), DistillBERT(67M), TinyBERT(67M), and MobileBERT(25.3M) regarding the average GLUE score. By evaluating on SQuAD, a model found by AutoDistill achieves an 88.4% F1 score with 22.8M parameters, which reduces parameters by more than 62% while maintaining higher accuracy than DistillBERT, TinyBERT, and NAS-BERT.