 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument Binarization
Document binarization is the process of converting grayscale or color documents into binary images.
Papers and Code
Integrated Framework for Selecting and Enhancing Ancient Marathi Inscription Images from Stone, Metal Plate, and Paper Documents
Jan 08, 2026Ancient script images often suffer from severe background noise, low contrast, and degradation caused by aging and environmental effects. In many cases, the foreground text and background exhibit similar visual characteristics, making the inscriptions difficult to read. The primary objective of image enhancement is to improve the readability of such degraded ancient images. This paper presents an image enhancement approach based on binarization and complementary preprocessing techniques for removing stains and enhancing unclear ancient text. The proposed methods are evaluated on different types of ancient scripts, including inscriptions on stone, metal plates, and historical documents. Experimental results show that the proposed approach achieves classification accuracies of 55.7%, 62%, and 65.6% for stone, metal plate, and document scripts, respectively, using the K-Nearest Neighbor (K-NN) classifier. Using the Support Vector Machine (SVM) classifier, accuracies of 53.2%, 59.5%, and 67.8% are obtained. The results demonstrate the effectiveness of the proposed enhancement method in improving the readability of ancient Marathi inscription images.
MFE-GAN: Efficient GAN-based Framework for Document Image Enhancement and Binarization with Multi-scale Feature Extraction
Dec 16, 2025
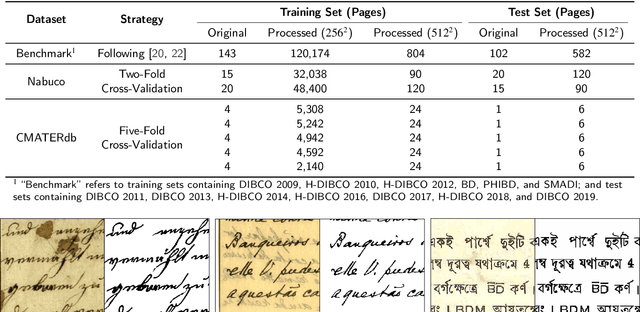

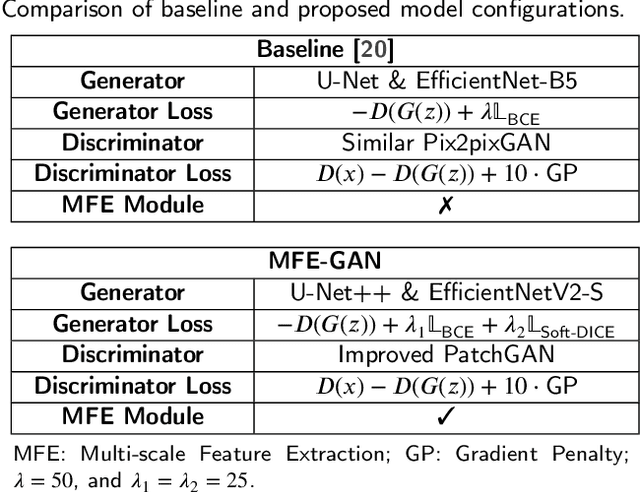
Document image enhancement and binarization are commonly performed prior to document analysis and recognition tasks for improving the efficiency and accuracy of optical character recognition (OCR) systems. This is because directly recognizing text in degraded documents, particularly in color images, often results in unsatisfactory recognition performance. To address these issues, existing methods train independent generative adversarial networks (GANs) for different color channels to remove shadows and noise, which, in turn, facilitates efficient text information extraction. However, deploying multiple GANs results in long training and inference times. To reduce both training and inference times of document image enhancement and binarization models, we propose MFE-GAN, an efficient GAN-based framework with multi-scale feature extraction (MFE), which incorporates Haar wavelet transformation (HWT) and normalization to process document images before feeding them into GANs for training. In addition, we present novel generators, discriminators, and loss functions to improve the model's performance, and we conduct ablation studies to demonstrate their effectiveness. Experimental results on the Benchmark, Nabuco, and CMATERdb datasets demonstrate that the proposed MFE-GAN significantly reduces the total training and inference times while maintaining comparable performance with respect to state-of-the-art (SOTA) methods. The implementation of this work is available at https://ruiyangju.github.io/MFE-GAN.
DKDS: A Benchmark Dataset of Degraded Kuzushiji Documents with Seals for Detection and Binarization
Nov 12, 2025Kuzushiji, a pre-modern Japanese cursive script, can currently be read and understood by only a few thousand trained experts in Japan. With the rapid development of deep learning, researchers have begun applying Optical Character Recognition (OCR) techniques to transcribe Kuzushiji into modern Japanese. Although existing OCR methods perform well on clean pre-modern Japanese documents written in Kuzushiji, they often fail to consider various types of noise, such as document degradation and seals, which significantly affect recognition accuracy. To the best of our knowledge, no existing dataset specifically addresses these challenges. To address this gap, we introduce the Degraded Kuzushiji Documents with Seals (DKDS) dataset as a new benchmark for related tasks. We describe the dataset construction process, which required the assistance of a trained Kuzushiji expert, and define two benchmark tracks: (1) text and seal detection and (2) document binarization. For the text and seal detection track, we provide baseline results using multiple versions of the You Only Look Once (YOLO) models for detecting Kuzushiji characters and seals. For the document binarization track, we present baseline results from traditional binarization algorithms, traditional algorithms combined with K-means clustering, and Generative Adversarial Network (GAN)-based methods. The DKDS dataset and the implementation code for baseline methods are available at https://ruiyangju.github.io/DKDS.
Partial differential equation system for binarization of degraded document images
Mar 11, 2025



In recent years, partial differential equation (PDE) systems have been successfully applied to the binarization of text images, achieving promising results. Inspired by the DH model and incorporating a novel image modeling approach, this study proposes a new weakly coupled PDE system for degraded text image binarization. In this system, the first equation is designed to estimate the background component, incorporating both diffusion and fidelity terms. The second equation estimates the foreground component and includes diffusion, fidelity, and binarization source terms. The final binarization result is obtained by applying a hard projection to the estimated foreground component. Experimental results on 86 degraded text images demonstrate that the proposed model exhibits significant advantages in handling degraded text images.
Text Change Detection in Multilingual Documents Using Image Comparison
Dec 05, 2024Document comparison typically relies on optical character recognition (OCR) as its core technology. However, OCR requires the selection of appropriate language models for each document and the performance of multilingual or hybrid models remains limited. To overcome these challenges, we propose text change detection (TCD) using an image comparison model tailored for multilingual documents. Unlike OCR-based approaches, our method employs word-level text image-to-image comparison to detect changes. Our model generates bidirectional change segmentation maps between the source and target documents. To enhance performance without requiring explicit text alignment or scaling preprocessing, we employ correlations among multi-scale attention features. We also construct a benchmark dataset comprising actual printed and scanned word pairs in various languages to evaluate our model. We validate our approach using our benchmark dataset and public benchmarks Distorted Document Images and the LRDE Document Binarization Dataset. We compare our model against state-of-the-art semantic segmentation and change detection models, as well as to conventional OCR-based models.
Arabic Handwritten Document OCR Solution with Binarization and Adaptive Scale Fusion Detection
Dec 02, 2024



The problem of converting images of text into plain text is a widely researched topic in both academia and industry. Arabic handwritten Text Recognation (AHTR) poses additional challenges due to diverse handwriting styles and limited labeled data. In this paper we present a complete OCR pipeline that starts with line segmentation using Differentiable Binarization and Adaptive Scale Fusion techniques to ensure accurate detection of text lines. Following segmentation, a CNN-BiLSTM-CTC architecture is applied to recognize characters. Our system, trained on the Arabic Multi-Fonts Dataset (AMFDS), achieves a Character Recognition Rate (CRR) of 99.20% and a Word Recognition Rate (WRR) of 93.75% on single-word samples containing 7 to 10 characters, along with a CRR of 83.76% for sentences. These results demonstrate the system's strong performance in handling Arabic scripts, establishing a new benchmark for AHTR systems.
Predicting the Original Appearance of Damaged Historical Documents
Dec 16, 2024



Historical documents encompass a wealth of cultural treasures but suffer from severe damages including character missing, paper damage, and ink erosion over time. However, existing document processing methods primarily focus on binarization, enhancement, etc., neglecting the repair of these damages. To this end, we present a new task, termed Historical Document Repair (HDR), which aims to predict the original appearance of damaged historical documents. To fill the gap in this field, we propose a large-scale dataset HDR28K and a diffusion-based network DiffHDR for historical document repair. Specifically, HDR28K contains 28,552 damaged-repaired image pairs with character-level annotations and multi-style degradations. Moreover, DiffHDR augments the vanilla diffusion framework with semantic and spatial information and a meticulously designed character perceptual loss for contextual and visual coherence. Experimental results demonstrate that the proposed DiffHDR trained using HDR28K significantly surpasses existing approaches and exhibits remarkable performance in handling real damaged documents. Notably, DiffHDR can also be extended to document editing and text block generation, showcasing its high flexibility and generalization capacity. We believe this study could pioneer a new direction of document processing and contribute to the inheritance of invaluable cultures and civilizations. The dataset and code is available at https://github.com/yeungchenwa/HDR.
* Accepted to AAAI 2025; Github Page: https://github.com/yeungchenwa/HDR
Efficient GANs for Document Image Binarization Based on DWT and Normalization
Jul 05, 2024



For document image binarization task, generative adversarial networks (GANs) can generate images where shadows and noise are effectively removed, which allow for text information extraction. The current state-of-the-art (SOTA) method proposes a three-stage network architecture that utilizes six GANs. Despite its excellent model performance, the SOTA network architecture requires long training and inference times. To overcome this problem, this work introduces an efficient GAN method based on the three-stage network architecture that incorporates the Discrete Wavelet Transformation and normalization to reduce the input image size, which in turns, decrease both training and inference times. In addition, this work presents novel generators, discriminators, and loss functions to improve the model's performance. Experimental results show that the proposed method reduces the training time by 10% and the inference time by 26% when compared to the SOTA method while maintaining the model performance at 73.79 of Avg-Score. Our implementation code is available on GitHub at https://github.com/RuiyangJu/Efficient_Document_Image_Binarization.
Binarizing Documents by Leveraging both Space and Frequency
Apr 26, 2024Document Image Binarization is a well-known problem in Document Analysis and Computer Vision, although it is far from being solved. One of the main challenges of this task is that documents generally exhibit degradations and acquisition artifacts that can greatly vary throughout the page. Nonetheless, even when dealing with a local patch of the document, taking into account the overall appearance of a wide portion of the page can ease the prediction by enriching it with semantic information on the ink and background conditions. In this respect, approaches able to model both local and global information have been proven suitable for this task. In particular, recent applications of Vision Transformer (ViT)-based models, able to model short and long-range dependencies via the attention mechanism, have demonstrated their superiority over standard Convolution-based models, which instead struggle to model global dependencies. In this work, we propose an alternative solution based on the recently introduced Fast Fourier Convolutions, which overcomes the limitation of standard convolutions in modeling global information while requiring fewer parameters than ViTs. We validate the effectiveness of our approach via extensive experimental analysis considering different types of degradations.
A Fair Evaluation of Various Deep Learning-Based Document Image Binarization Approaches
Jan 22, 2024Binarization of document images is an important pre-processing step in the field of document analysis. Traditional image binarization techniques usually rely on histograms or local statistics to identify a valid threshold to differentiate between different aspects of the image. Deep learning techniques are able to generate binarized versions of the images by learning context-dependent features that are less error-prone to degradation typically occurring in document images. In recent years, many deep learning-based methods have been developed for document binarization. But which one to choose? There have been no studies that compare these methods rigorously. Therefore, this work focuses on the evaluation of different deep learning-based methods under the same evaluation protocol. We evaluate them on different Document Image Binarization Contest (DIBCO) datasets and obtain very heterogeneous results. We show that the DE-GAN model was able to perform better compared to other models when evaluated on the DIBCO2013 dataset while DP-LinkNet performed best on the DIBCO2017 dataset. The 2-StageGAN performed best on the DIBCO2018 dataset while SauvolaNet outperformed the others on the DIBCO2019 challenge. Finally, we make the code, all models and evaluation publicly available (https://github.com/RichSu95/Document_Binarization_Collection) to ensure reproducibility and simplify future binarization evaluations.
* DAS 2022