 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDhp19
Papers and Code
3D Landmark Detection on Human Point Clouds: A Benchmark and A Dual Cascade Point Transformer Framework
Jan 14, 2024



3D landmark detection plays a pivotal role in various applications such as 3D registration, pose estimation, and virtual try-on. While considerable success has been achieved in 2D human landmark detection or pose estimation, there is a notable scarcity of reported works on landmark detection in unordered 3D point clouds. This paper introduces a novel challenge, namely 3D landmark detection on human point clouds, presenting two primary contributions. Firstly, we establish a comprehensive human point cloud dataset, named HPoint103, designed to support the 3D landmark detection community. This dataset comprises 103 human point clouds created with commercial software and actors, each manually annotated with 11 stable landmarks. Secondly, we propose a Dual Cascade Point Transformer (D-CPT) model for precise point-based landmark detection. D-CPT gradually refines the landmarks through cascade Transformer decoder layers across the entire point cloud stream, simultaneously enhancing landmark coordinates with a RefineNet over local regions. Comparative evaluations with popular point-based methods on HPoint103 and the public dataset DHP19 demonstrate the dramatic outperformance of our D-CPT. Additionally, the integration of our RefineNet into existing methods consistently improves performance.
Rethinking Human Pose Estimation for Autonomous Driving with 3D Event Representations
Nov 09, 2023Human pose estimation is a critical component in autonomous driving and parking, enhancing safety by predicting human actions. Traditional frame-based cameras and videos are commonly applied, yet, they become less reliable in scenarios under high dynamic range or heavy motion blur. In contrast, event cameras offer a robust solution for navigating these challenging contexts. Predominant methodologies incorporate event cameras into learning frameworks by accumulating events into event frames. However, such methods tend to marginalize the intrinsic asynchronous and high temporal resolution characteristics of events. This disregard leads to a loss in essential temporal dimension data, crucial for safety-critical tasks associated with dynamic human activities. To address this issue and to unlock the 3D potential of event information, we introduce two 3D event representations: the Rasterized Event Point Cloud (RasEPC) and the Decoupled Event Voxel (DEV). The RasEPC collates events within concise temporal slices at identical positions, preserving 3D attributes with statistical cues and markedly mitigating memory and computational demands. Meanwhile, the DEV representation discretizes events into voxels and projects them across three orthogonal planes, utilizing decoupled event attention to retrieve 3D cues from the 2D planes. Furthermore, we develop and release EV-3DPW, a synthetic event-based dataset crafted to facilitate training and quantitative analysis in outdoor scenes. On the public real-world DHP19 dataset, our event point cloud technique excels in real-time mobile predictions, while the decoupled event voxel method achieves the highest accuracy. Experiments reveal our proposed 3D representation methods' superior generalization capacities against traditional RGB images and event frame techniques. Our code and dataset are available at https://github.com/MasterHow/EventPointPose.
Efficient Human Pose Estimation via 3D Event Point Cloud
Jun 09, 2022



Human Pose Estimation (HPE) based on RGB images has experienced a rapid development benefiting from deep learning. However, event-based HPE has not been fully studied, which remains great potential for applications in extreme scenes and efficiency-critical conditions. In this paper, we are the first to estimate 2D human pose directly from 3D event point cloud. We propose a novel representation of events, the rasterized event point cloud, aggregating events on the same position of a small time slice. It maintains the 3D features from multiple statistical cues and significantly reduces memory consumption and computation complexity, proved to be efficient in our work. We then leverage the rasterized event point cloud as input to three different backbones, PointNet, DGCNN, and Point Transformer, with two linear layer decoders to predict the location of human keypoints. We find that based on our method, PointNet achieves promising results with much faster speed, whereas Point Transfomer reaches much higher accuracy, even close to previous event-frame-based methods. A comprehensive set of results demonstrates that our proposed method is consistently effective for these 3D backbone models in event-driven human pose estimation. Our method based on PointNet with 2048 points input achieves 82.46mm in MPJPE3D on the DHP19 dataset, while only has a latency of 12.29ms on an NVIDIA Jetson Xavier NX edge computing platform, which is ideally suitable for real-time detection with event cameras. Code will be made publicly at https://github.com/MasterHow/EventPointPose.
EventHPE: Event-based 3D Human Pose and Shape Estimation
Aug 15, 2021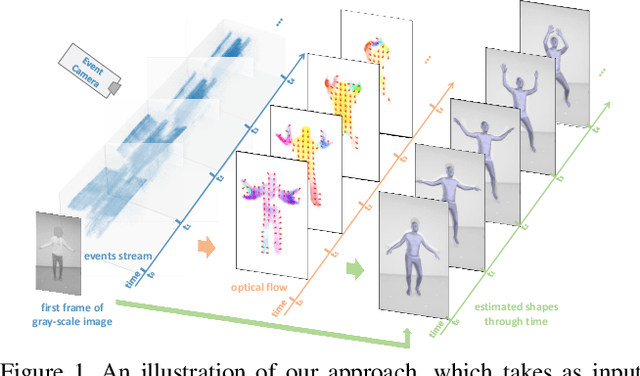

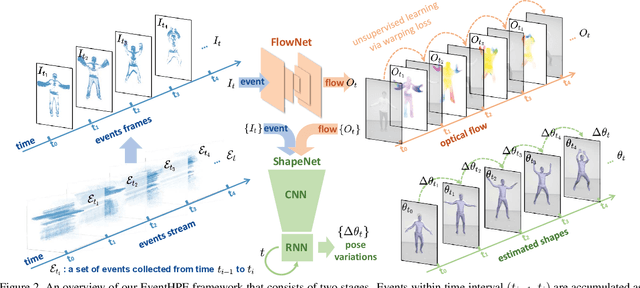
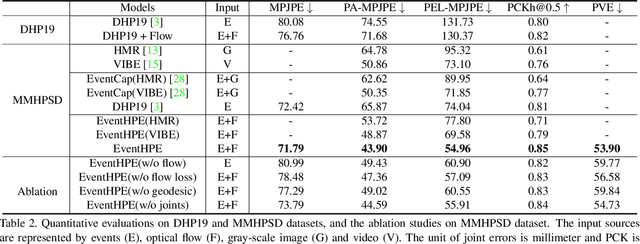
Event camera is an emerging imaging sensor for capturing dynamics of moving objects as events, which motivates our work in estimating 3D human pose and shape from the event signals. Events, on the other hand, have their unique challenges: rather than capturing static body postures, the event signals are best at capturing local motions. This leads us to propose a two-stage deep learning approach, called EventHPE. The first-stage, FlowNet, is trained by unsupervised learning to infer optical flow from events. Both events and optical flow are closely related to human body dynamics, which are fed as input to the ShapeNet in the second stage, to estimate 3D human shapes. To mitigate the discrepancy between image-based flow (optical flow) and shape-based flow (vertices movement of human body shape), a novel flow coherence loss is introduced by exploiting the fact that both flows are originated from the identical human motion. An in-house event-based 3D human dataset is curated that comes with 3D pose and shape annotations, which is by far the largest one to our knowledge. Empirical evaluations on DHP19 dataset and our in-house dataset demonstrate the effectiveness of our approach.
Instantaneous Stereo Depth Estimation of Real-World Stimuli with a Neuromorphic Stereo-Vision Setup
Apr 06, 2021
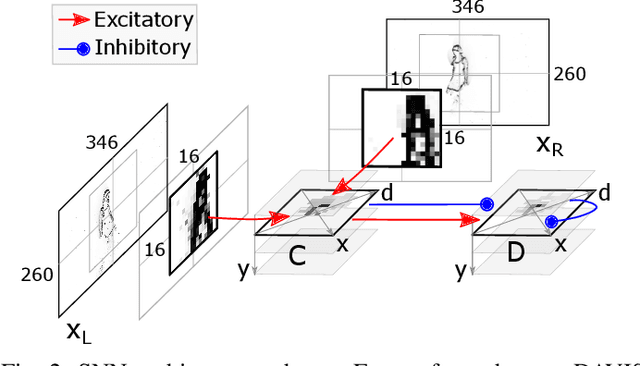
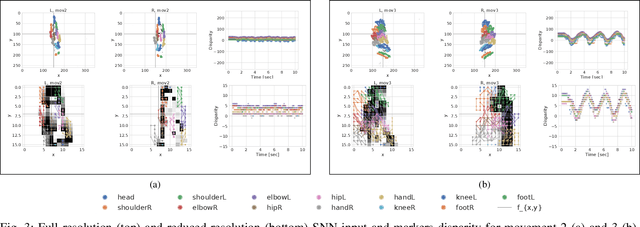
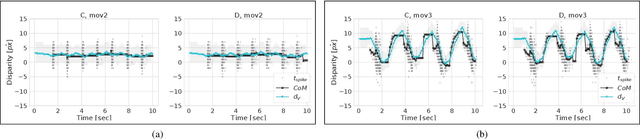
The stereo-matching problem, i.e., matching corresponding features in two different views to reconstruct depth, is efficiently solved in biology. Yet, it remains the computational bottleneck for classical machine vision approaches. By exploiting the properties of event cameras, recently proposed Spiking Neural Network (SNN) architectures for stereo vision have the potential of simplifying the stereo-matching problem. Several solutions that combine event cameras with spike-based neuromorphic processors already exist. However, they are either simulated on digital hardware or tested on simplified stimuli. In this work, we use the Dynamic Vision Sensor 3D Human Pose Dataset (DHP19) to validate a brain-inspired event-based stereo-matching architecture implemented on a mixed-signal neuromorphic processor with real-world data. Our experiments show that this SNN architecture, composed of coincidence detectors and disparity sensitive neurons, is able to provide a coarse estimate of the input disparity instantaneously, thereby detecting the presence of a stimulus moving in depth in real-time.