 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBotswana
Papers and Code
Predicting Internet Connectivity in Schools: A Feasibility Study Leveraging Multi-modal Data and Location Encoders in Low-Resource Settings
Dec 13, 2024



Internet connectivity in schools is critical to provide students with the digital literary skills necessary to compete in modern economies. In order for governments to effectively implement digital infrastructure development in schools, accurate internet connectivity information is required. However, traditional survey-based methods can exceed the financial and capacity limits of governments. Open-source Earth Observation (EO) datasets have unlocked our ability to observe and understand socio-economic conditions on Earth from space, and in combination with Machine Learning (ML), can provide the tools to circumvent costly ground-based survey methods to support infrastructure development. In this paper, we present our work on school internet connectivity prediction using EO and ML. We detail the creation of our multi-modal, freely-available satellite imagery and survey information dataset, leverage the latest geographically-aware location encoders, and introduce the first results of using the new European Space Agency phi-lab geographically-aware foundational model to predict internet connectivity in Botswana and Rwanda. We find that ML with EO and ground-based auxiliary data yields the best performance in both countries, for accuracy, F1 score, and False Positive rates, and highlight the challenges of internet connectivity prediction from space with a case study in Kigali, Rwanda. Our work showcases a practical approach to support data-driven digital infrastructure development in low-resource settings, leveraging freely available information, and provide cleaned and labelled datasets for future studies to the community through a unique collaboration between UNICEF and the European Space Agency phi-lab.
Bayesian Convolutional Neural Networks for Limited Data Hyperspectral Remote Sensing Image Classification
May 30, 2022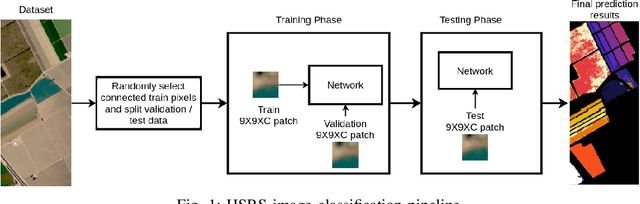

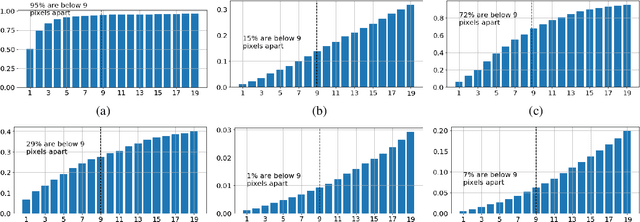
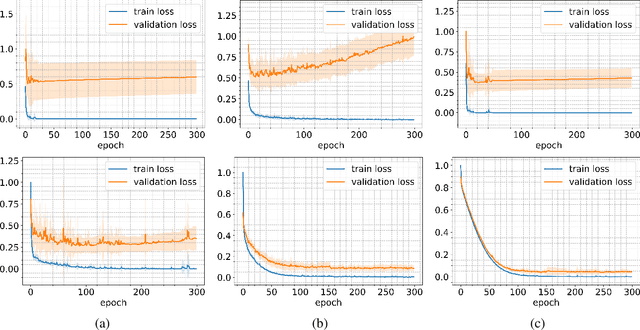
Employing deep neural networks for Hyperspectral remote sensing (HSRS) image classification is a challenging task. HSRS images have high dimensionality and a large number of channels with substantial redundancy between channels. In addition, the training data for classifying HSRS images is limited and the amount of available training data is much smaller compared to other classification tasks. These factors complicate the training process of deep neural networks with many parameters and cause them to not perform well even compared to conventional models. Moreover, convolutional neural networks produce over-confident predictions, which is highly undesirable considering the aforementioned problem. In this work, we use for HSRS image classification a special class of deep neural networks, namely a Bayesian neural network (BNN). To the extent of our knowledge, this is the first time that BNNs are used in HSRS image classification. BNNs inherently provide a measure for uncertainty. We perform extensive experiments on the Pavia Centre, Salinas, and Botswana datasets. We show that a BNN outperforms a standard convolutional neural network (CNN) and an off-the-shelf Random Forest (RF). Further experiments underline that the BNN is more stable and robust to model pruning, and that the uncertainty is higher for samples with higher expected prediction error.
CEU-Net: Ensemble Semantic Segmentation of Hyperspectral Images Using Clustering
Mar 14, 2022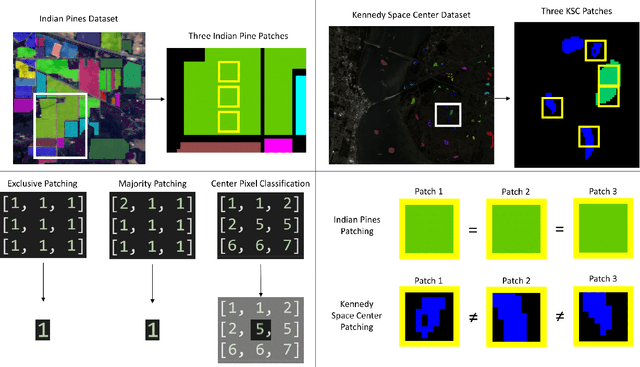

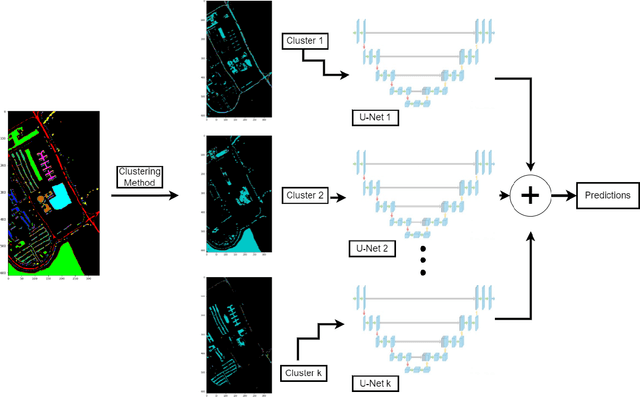

Most semantic segmentation approaches of Hyperspectral images (HSIs) use and require preprocessing steps in the form of patching to accurately classify diversified land cover in remotely sensed images. These approaches use patching to incorporate the rich neighborhood information in images and exploit the simplicity and segmentability of the most common HSI datasets. In contrast, most landmasses in the world consist of overlapping and diffused classes, making neighborhood information weaker than what is seen in common HSI datasets. To combat this issue and generalize the segmentation models to more complex and diverse HSI datasets, in this work, we propose our novel flagship model: Clustering Ensemble U-Net (CEU-Net). CEU-Net uses the ensemble method to combine spectral information extracted from convolutional neural network (CNN) training on a cluster of landscape pixels. Our CEU-Net model outperforms existing state-of-the-art HSI semantic segmentation methods and gets competitive performance with and without patching when compared to baseline models. We highlight CEU-Net's high performance across Botswana, KSC, and Salinas datasets compared to HybridSN and AeroRIT methods.
Faster hyperspectral image classification based on selective kernel mechanism using deep convolutional networks
Feb 14, 2022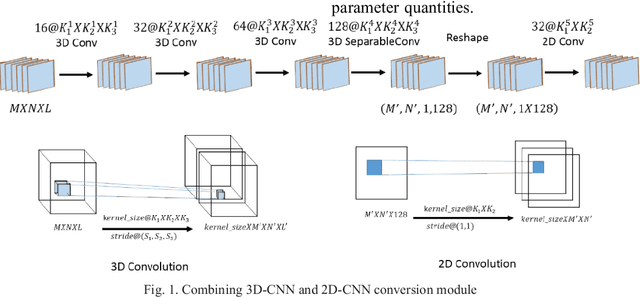
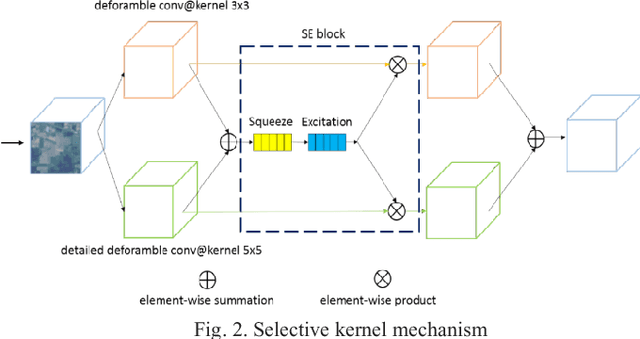
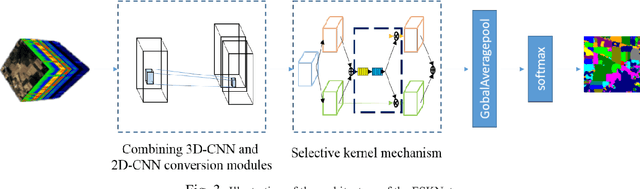

Hyperspectral imagery is rich in spatial and spectral information. Using 3D-CNN can simultaneously acquire features of spatial and spectral dimensions to facilitate classification of features, but hyperspectral image information spectral dimensional information redundancy. The use of continuous 3D-CNN will result in a high amount of parameters, and the computational power requirements of the device are high, and the training takes too long. This letter designed the Faster selective kernel mechanism network (FSKNet), FSKNet can balance this problem. It designs 3D-CNN and 2D-CNN conversion modules, using 3D-CNN to complete feature extraction while reducing the dimensionality of spatial and spectrum. However, such a model is not lightweight enough. In the converted 2D-CNN, a selective kernel mechanism is proposed, which allows each neuron to adjust the receptive field size based on the two-way input information scale. Under the Selective kernel mechanism, it mainly includes two components, se module and variable convolution. Se acquires channel dimensional attention and variable convolution to obtain spatial dimension deformation information of ground objects. The model is more accurate, faster, and less computationally intensive. FSKNet achieves high accuracy on the IN, UP, Salinas, and Botswana data sets with very small parameters.
Classification of Hyperspectral Images by Using Spectral Data and Fully Connected Neural Network
Jan 08, 2022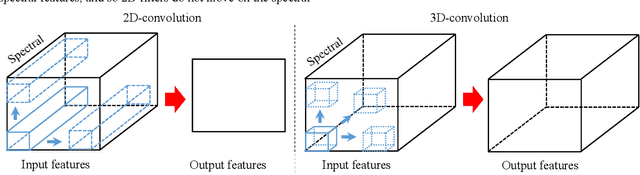
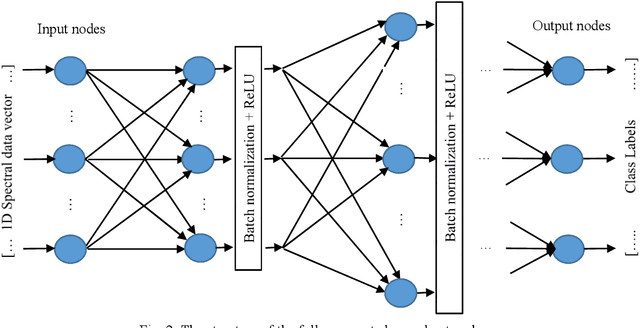
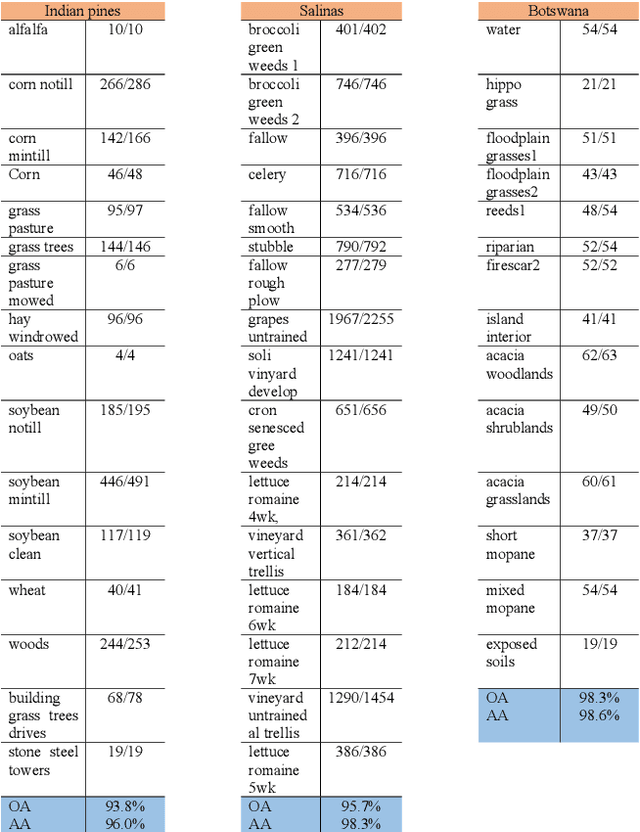
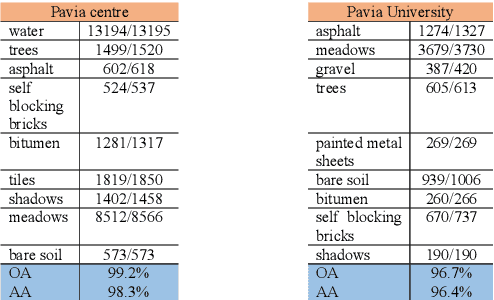
It is observed that high classification performance is achieved for one- and two-dimensional signals by using deep learning methods. In this context, most researchers have tried to classify hyperspectral images by using deep learning methods and classification success over 90% has been achieved for these images. Deep neural networks (DNN) actually consist of two parts: i) Convolutional neural network (CNN) and ii) fully connected neural network (FCNN). While CNN determines the features, FCNN is used in classification. In classification of the hyperspectral images, it is observed that almost all of the researchers used 2D or 3D convolution filters on the spatial data beside spectral data (features). It is convenient to use convolution filters on images or time signals. In hyperspectral images, each pixel is represented by a signature vector which consists of individual features that are independent of each other. Since the order of the features in the vector can be changed, it doesn't make sense to use convolution filters on these features as on time signals. At the same time, since the hyperspectral images do not have a textural structure, there is no need to use spatial data besides spectral data. In this study, hyperspectral images of Indian pines, Salinas, Pavia centre, Pavia university and Botswana are classified by using only fully connected neural network and the spectral data with one dimensional. An average accuracy of 97.5% is achieved for the test sets of all hyperspectral images.
Attention Mechanism Meets with Hybrid Dense Network for Hyperspectral Image Classification
Jan 04, 2022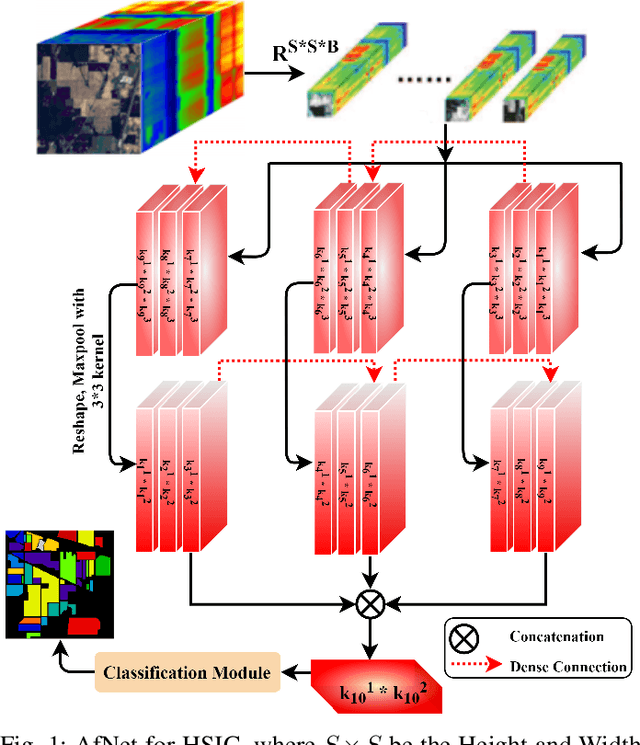
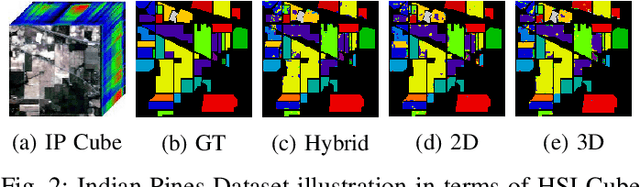
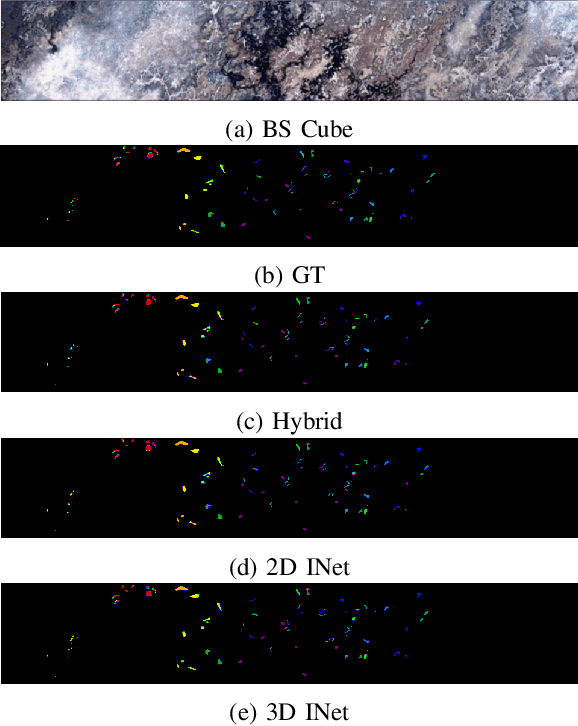
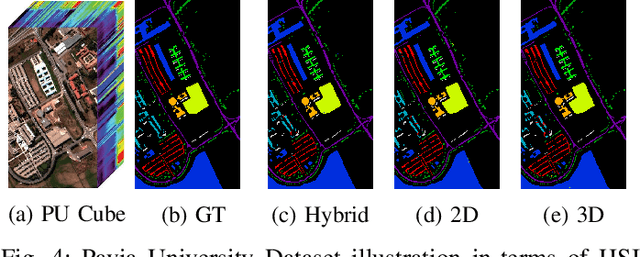
Convolutional Neural Networks (CNN) are more suitable, indeed. However, fixed kernel sizes make traditional CNN too specific, neither flexible nor conducive to feature learning, thus impacting on the classification accuracy. The convolution of different kernel size networks may overcome this problem by capturing more discriminating and relevant information. In light of this, the proposed solution aims at combining the core idea of 3D and 2D Inception net with the Attention mechanism to boost the HSIC CNN performance in a hybrid scenario. The resulting \textit{attention-fused hybrid network} (AfNet) is based on three attention-fused parallel hybrid sub-nets with different kernels in each block repeatedly using high-level features to enhance the final ground-truth maps. In short, AfNet is able to selectively filter out the discriminative features critical for classification. Several tests on HSI datasets provided competitive results for AfNet compared to state-of-the-art models. The proposed pipeline achieved, indeed, an overall accuracy of 97\% for the Indian Pines, 100\% for Botswana, 99\% for Pavia University, Pavia Center, and Salinas datasets.
Hyperspectral Image Classification: Artifacts of Dimension Reduction on Hybrid CNN
Jan 25, 2021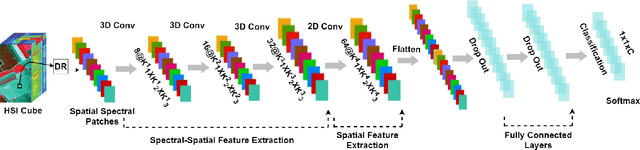
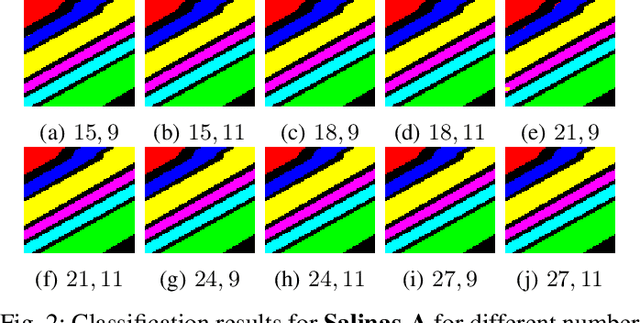
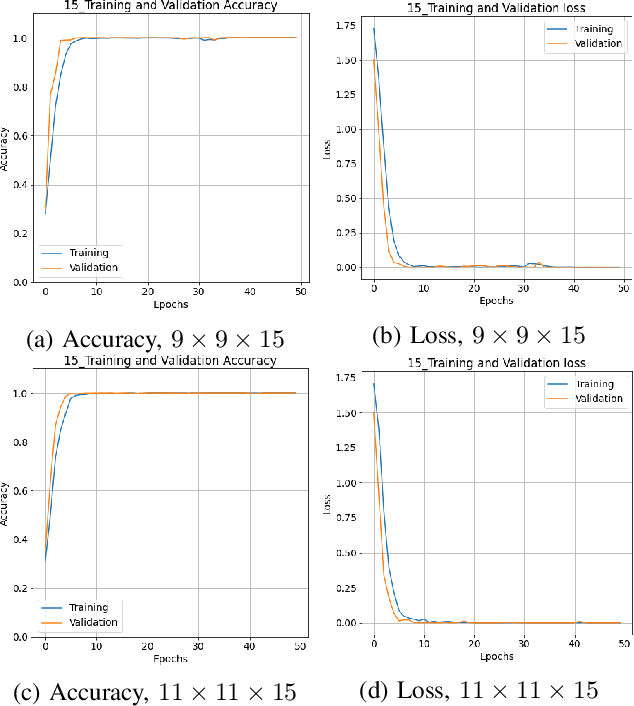
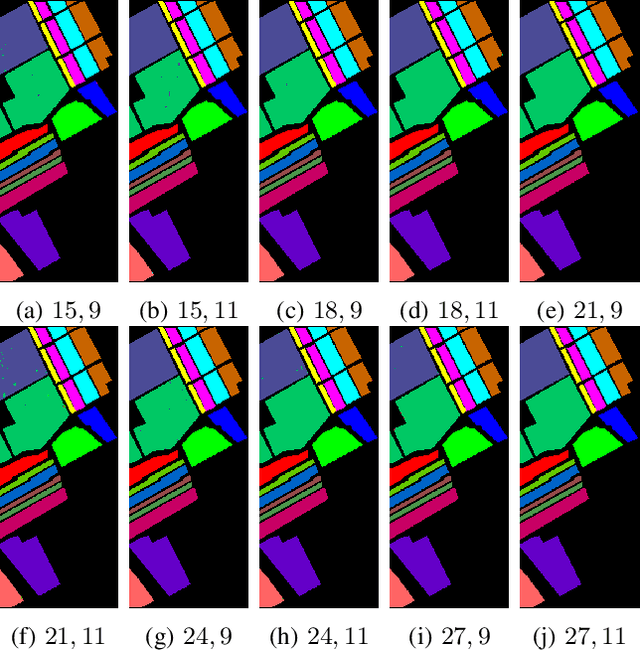
Convolutional Neural Networks (CNN) has been extensively studied for Hyperspectral Image Classification (HSIC) more specifically, 2D and 3D CNN models have proved highly efficient in exploiting the spatial and spectral information of Hyperspectral Images. However, 2D CNN only considers the spatial information and ignores the spectral information whereas 3D CNN jointly exploits spatial-spectral information at a high computational cost. Therefore, this work proposed a lightweight CNN (3D followed by 2D-CNN) model which significantly reduces the computational cost by distributing spatial-spectral feature extraction across a lighter model alongside a preprocessing that has been carried out to improve the classification results. Five benchmark Hyperspectral datasets (i.e., SalinasA, Salinas, Indian Pines, Pavia University, Pavia Center, and Botswana) are used for experimental evaluation. The experimental results show that the proposed pipeline outperformed in terms of generalization performance, statistical significance, and computational complexity, as compared to the state-of-the-art 2D/3D CNN models except commonly used computationally expensive design choices.
Learning Hyperspectral Feature Extraction and Classification with ResNeXt Network
Feb 07, 2020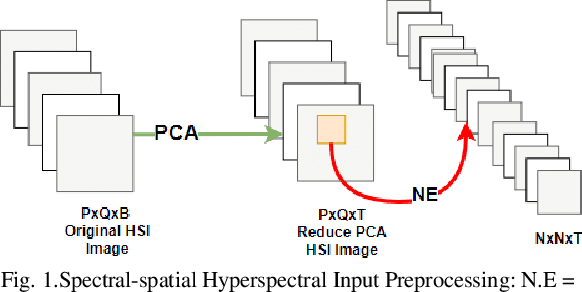

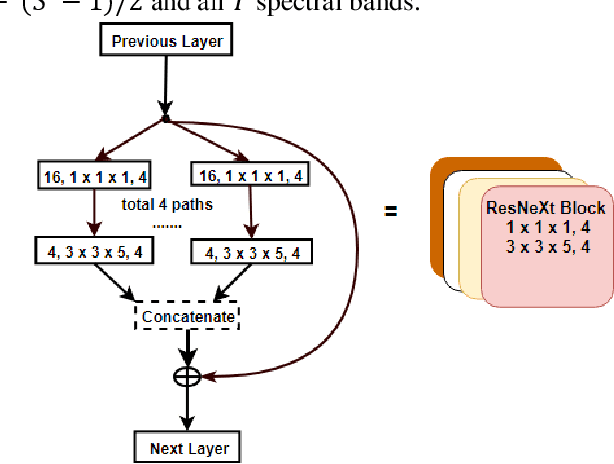
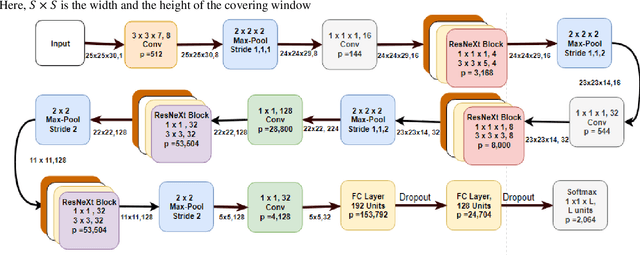
The Hyperspectral image (HSI) classification is a standard remote sensing task, in which each image pixel is given a label indicating the physical land-cover on the earth's surface. The achievements of image semantic segmentation and deep learning approaches on ordinary images have accelerated the research on hyperspectral image classification. Moreover, the utilization of both the spectral and spatial cues in hyperspectral images has shown improved classification accuracy in hyperspectral image classification. The use of only 3D Convolutional Neural Networks (3D-CNN) to extract both spatial and spectral cues from Hyperspectral images results in an explosion of parameters hence high computational cost. We propose network architecture called the MixedSN that utilizes the 3D convolutions to modeling spectral-spatial information in the early layers of the architecture and the 2D convolutions at the top layers which majorly deal with semantic abstraction. We constrain our architecture to ResNeXt block because of their performance and simplicity. Our model drastically reduced the number of parameters and achieved comparable classification performance with state-of-the-art methods on Indian Pine (IP) scene dataset, Pavia University scene (PU) dataset, Salinas (SA) Scene dataset, and Botswana (BW) dataset.
Natural images from the birthplace of the human eye
Feb 04, 2011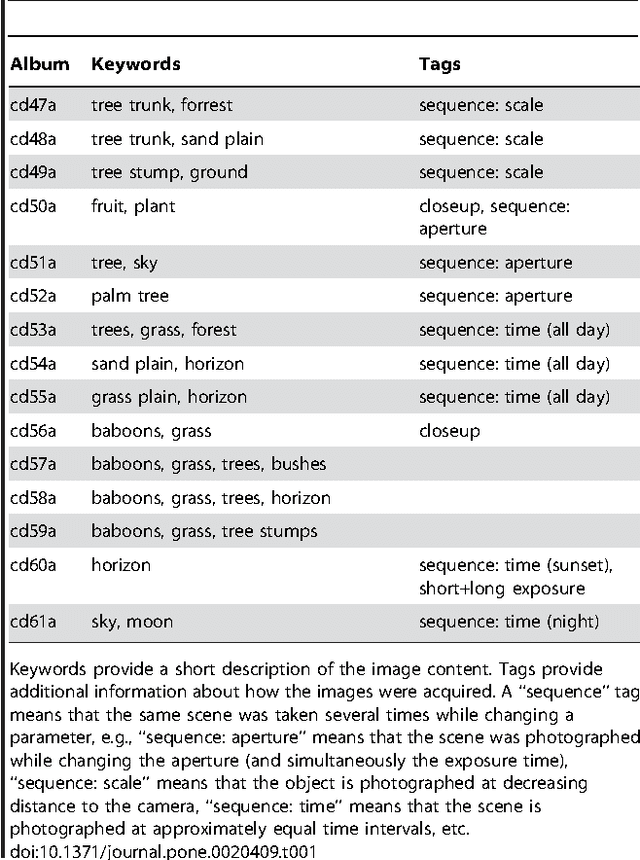
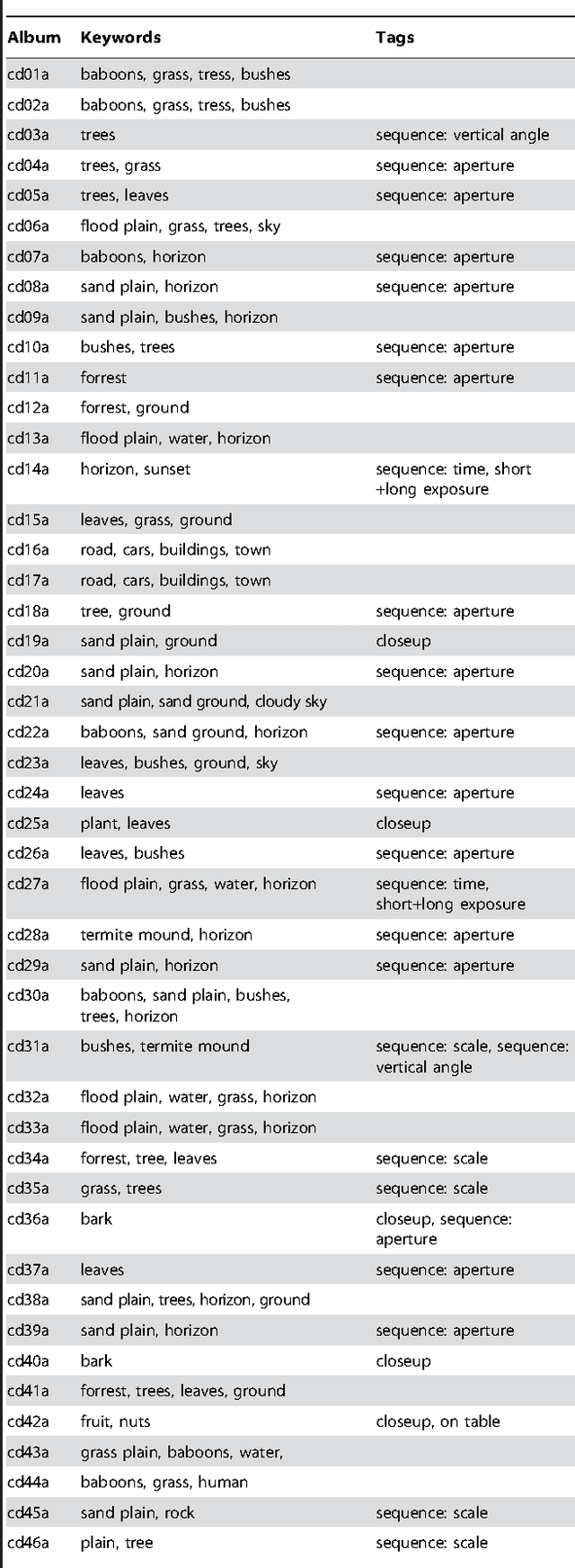
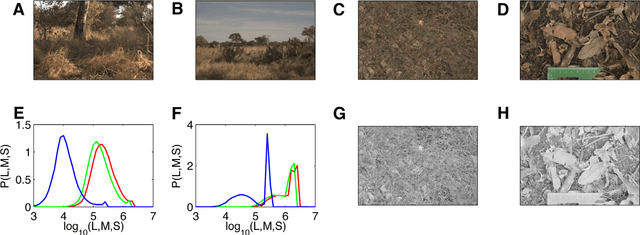
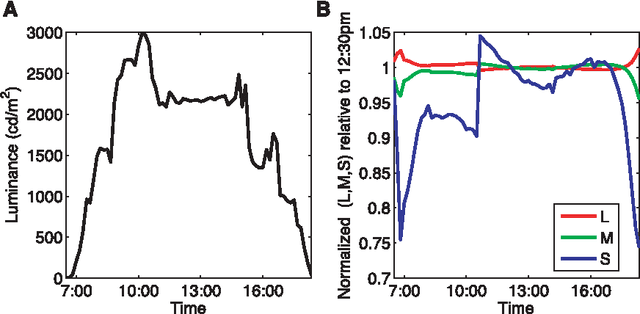
Here we introduce a database of calibrated natural images publicly available through an easy-to-use web interface. Using a Nikon D70 digital SLR camera, we acquired about 5000 six-megapixel images of Okavango Delta of Botswana, a tropical savanna habitat similar to where the human eye is thought to have evolved. Some sequences of images were captured unsystematically while following a baboon troop, while others were designed to vary a single parameter such as aperture, object distance, time of day or position on the horizon. Images are available in the raw RGB format and in grayscale. Images are also available in units relevant to the physiology of human cone photoreceptors, where pixel values represent the expected number of photoisomerizations per second for cones sensitive to long (L), medium (M) and short (S) wavelengths. This database is distributed under a Creative Commons Attribution-Noncommercial Unported license to facilitate research in computer vision, psychophysics of perception, and visual neuroscience.
* Submitted to PLoS ONE