 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlackbird
Papers and Code
Modelling the Morphology of Verbal Paradigms: A Case Study in the Tokenization of Turkish and Hebrew
Feb 05, 2026We investigate how transformer models represent complex verb paradigms in Turkish and Modern Hebrew, concentrating on how tokenization strategies shape this ability. Using the Blackbird Language Matrices task on natural data, we show that for Turkish -- with its transparent morphological markers -- both monolingual and multilingual models succeed, either when tokenization is atomic or when it breaks words into small subword units. For Hebrew, instead, monolingual and multilingual models diverge. A multilingual model using character-level tokenization fails to capture the language non-concatenative morphology, but a monolingual model with morpheme-aware segmentation performs well. Performance improves on more synthetic datasets, in all models.
On the Measure of a Model: From Intelligence to Generality
Nov 14, 2025Benchmarks such as ARC, Raven-inspired tests, and the Blackbird Task are widely used to evaluate the intelligence of large language models (LLMs). Yet, the concept of intelligence remains elusive- lacking a stable definition and failing to predict performance on practical tasks such as question answering, summarization, or coding. Optimizing for such benchmarks risks misaligning evaluation with real-world utility. Our perspective is that evaluation should be grounded in generality rather than abstract notions of intelligence. We identify three assumptions that often underpin intelligence-focused evaluation: generality, stability, and realism. Through conceptual and formal analysis, we show that only generality withstands conceptual and empirical scrutiny. Intelligence is not what enables generality; generality is best understood as a multitask learning problem that directly links evaluation to measurable performance breadth and reliability. This perspective reframes how progress in AI should be assessed and proposes generality as a more stable foundation for evaluating capability across diverse and evolving tasks.
Exploring Italian sentence embeddings properties through multi-tasking
Sep 10, 2024We investigate to what degree existing LLMs encode abstract linguistic information in Italian in a multi-task setting. We exploit curated synthetic data on a large scale -- several Blackbird Language Matrices (BLMs) problems in Italian -- and use them to study how sentence representations built using pre-trained language models encode specific syntactic and semantic information. We use a two-level architecture to model separately a compression of the sentence embeddings into a representation that contains relevant information for a task, and a BLM task. We then investigate whether we can obtain compressed sentence representations that encode syntactic and semantic information relevant to several BLM tasks. While we expected that the sentence structure -- in terms of sequence of phrases/chunks -- and chunk properties could be shared across tasks, performance and error analysis show that the clues for the different tasks are encoded in different manners in the sentence embeddings, suggesting that abstract linguistic notions such as constituents or thematic roles does not seem to be present in the pretrained sentence embeddings.
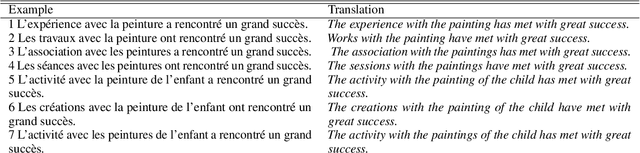
Exploring syntactic information in sentence embeddings through multilingual subject-verb agreement
Sep 10, 2024In this paper, our goal is to investigate to what degree multilingual pretrained language models capture cross-linguistically valid abstract linguistic representations. We take the approach of developing curated synthetic data on a large scale, with specific properties, and using them to study sentence representations built using pretrained language models. We use a new multiple-choice task and datasets, Blackbird Language Matrices (BLMs), to focus on a specific grammatical structural phenomenon -- subject-verb agreement across a variety of sentence structures -- in several languages. Finding a solution to this task requires a system detecting complex linguistic patterns and paradigms in text representations. Using a two-level architecture that solves the problem in two steps -- detect syntactic objects and their properties in individual sentences, and find patterns across an input sequence of sentences -- we show that despite having been trained on multilingual texts in a consistent manner, multilingual pretrained language models have language-specific differences, and syntactic structure is not shared, even across closely related languages.
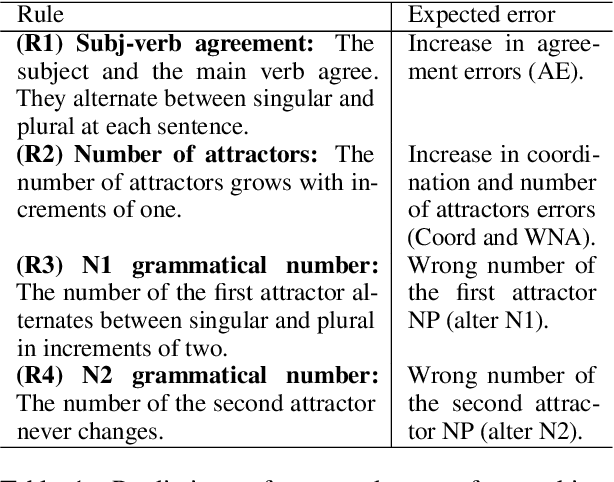
Blackbird language matrices , a new task for rule-like generalization in neural networks: Motivations and Formal Specifications
Jun 20, 2023We motivate and formally define a new task for fine-tuning rule-like generalization in large language models. It is conjectured that the shortcomings of current LLMs are due to a lack of ability to generalize. It has been argued that, instead, humans are better at generalization because they have a tendency at extracting rules from complex data. We try to recreate this tendency to rule-based generalization. When exposed to tests of analytic intelligence, for example, the visual RAVEN IQ test, human problem-solvers identify the relevant objects in the picture and their relevant attributes and reason based on rules applied to these objects and attributes. Based on the induced rules, they are able to provide a solution to the test. We propose a task that translates this IQ task into language. In this paper, we provide the formal specification for the task and the generative process of its datasets.
PRISM: Probabilistic Real-Time Inference in Spatial World Models
Dec 06, 2022We introduce PRISM, a method for real-time filtering in a probabilistic generative model of agent motion and visual perception. Previous approaches either lack uncertainty estimates for the map and agent state, do not run in real-time, do not have a dense scene representation or do not model agent dynamics. Our solution reconciles all of these aspects. We start from a predefined state-space model which combines differentiable rendering and 6-DoF dynamics. Probabilistic inference in this model amounts to simultaneous localisation and mapping (SLAM) and is intractable. We use a series of approximations to Bayesian inference to arrive at probabilistic map and state estimates. We take advantage of well-established methods and closed-form updates, preserving accuracy and enabling real-time capability. The proposed solution runs at 10Hz real-time and is similarly accurate to state-of-the-art SLAM in small to medium-sized indoor environments, with high-speed UAV and handheld camera agents (Blackbird, EuRoC and TUM-RGBD).
Blackbird's language matrices : a new benchmark to investigate disentangled generalisation in neural networks
May 22, 2022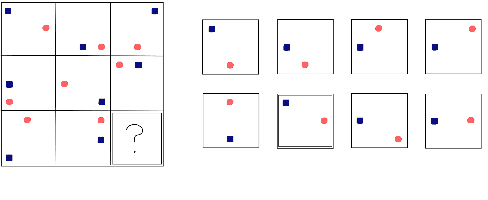

Current successes of machine learning architectures are based on computationally expensive algorithms and prohibitively large amounts of data. We need to develop tasks and data to train networks to reach more complex and more compositional skills. In this paper, we illustrate Blackbird's language matrices (BLMs), a novel grammatical dataset developed to test a linguistic variant of Raven's progressive matrices, an intelligence test usually based on visual stimuli. The dataset consists of 44800 sentences, generatively constructed to support investigations of current models' linguistic mastery of grammatical agreement rules and their ability to generalise them. We present the logic of the dataset, the method to automatically construct data on a large scale and the architecture to learn them. Through error analysis and several experiments on variations of the dataset, we demonstrate that this language task and the data that instantiate it provide a new challenging testbed to understand generalisation and abstraction.
The Blackbird Dataset: A large-scale dataset for UAV perception in aggressive flight
Oct 03, 2018
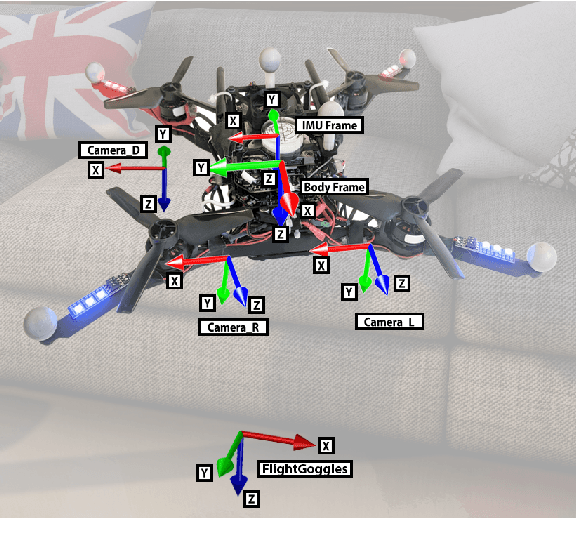
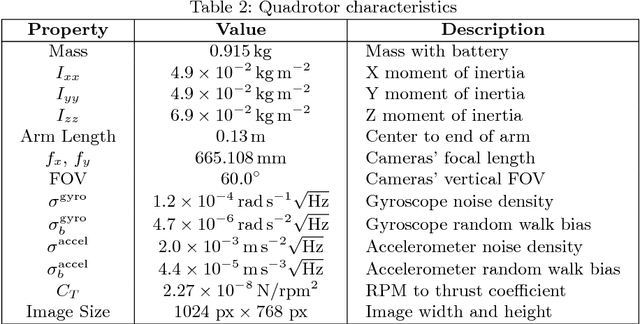

The Blackbird unmanned aerial vehicle (UAV) dataset is a large-scale, aggressive indoor flight dataset collected using a custom-built quadrotor platform for use in evaluation of agile perception.Inspired by the potential of future high-speed fully-autonomous drone racing, the Blackbird dataset contains over 10 hours of flight data from 168 flights over 17 flight trajectories and 5 environments at velocities up to $7.0ms^-1$. Each flight includes sensor data from 120Hz stereo and downward-facing photorealistic virtual cameras, 100Hz IMU, $\sim190Hz$ motor speed sensors, and 360Hz millimeter-accurate motion capture ground truth. Camera images for each flight were photorealistically rendered using FlightGoggles across a variety of environments to facilitate easy experimentation of high performance perception algorithms. The dataset is available for download at http://blackbird-dataset.mit.edu/