 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlackbird Language Matrices: A Framework to Investigate the Linguistic Competence of Language Models
Feb 24, 2026This article describes a novel language task, the Blackbird Language Matrices (BLM) task, inspired by intelligence tests, and illustrates the BLM datasets, their construction and benchmarking, and targeted experiments on chunking and systematicity. BLMs are multiple-choice problems, structured at multiple levels: within each sentence, across the input sequence, within each candidate answer. Because of their rich structure, these curated, but naturalistic datasets are key to answer some core questions about current large language models abilities: do LLMs detect linguistic objects and their properties? Do they detect and use systematic patterns across sentences? Are they more prone to linguistic or reasoning errors, and how do these interact? We show that BLMs, while challenging, can be solved at good levels of performance, in more than one language, with simple baseline models or, at better performance levels, with more tailored models. We show that their representations contain the grammatical objects and attributes relevant to solve a linguistic task. We also show that these solutions are reached by detecting systematic patterns across sentences. The paper supports the point of view that curated, structured datasets support multi-faceted investigations of properties of language and large language models. Because they present a curated, articulated structure, because they comprise both learning contexts and expected answers, and because they are partly built by hand, BLMs fall in the category of datasets that can support explainability investigations, and be useful to ask why large language models behave the way they do.
Exploring syntactic information in sentence embeddings through multilingual subject-verb agreement
Sep 10, 2024In this paper, our goal is to investigate to what degree multilingual pretrained language models capture cross-linguistically valid abstract linguistic representations. We take the approach of developing curated synthetic data on a large scale, with specific properties, and using them to study sentence representations built using pretrained language models. We use a new multiple-choice task and datasets, Blackbird Language Matrices (BLMs), to focus on a specific grammatical structural phenomenon -- subject-verb agreement across a variety of sentence structures -- in several languages. Finding a solution to this task requires a system detecting complex linguistic patterns and paradigms in text representations. Using a two-level architecture that solves the problem in two steps -- detect syntactic objects and their properties in individual sentences, and find patterns across an input sequence of sentences -- we show that despite having been trained on multilingual texts in a consistent manner, multilingual pretrained language models have language-specific differences, and syntactic structure is not shared, even across closely related languages.
Exploring Italian sentence embeddings properties through multi-tasking
Sep 10, 2024We investigate to what degree existing LLMs encode abstract linguistic information in Italian in a multi-task setting. We exploit curated synthetic data on a large scale -- several Blackbird Language Matrices (BLMs) problems in Italian -- and use them to study how sentence representations built using pre-trained language models encode specific syntactic and semantic information. We use a two-level architecture to model separately a compression of the sentence embeddings into a representation that contains relevant information for a task, and a BLM task. We then investigate whether we can obtain compressed sentence representations that encode syntactic and semantic information relevant to several BLM tasks. While we expected that the sentence structure -- in terms of sequence of phrases/chunks -- and chunk properties could be shared across tasks, performance and error analysis show that the clues for the different tasks are encoded in different manners in the sentence embeddings, suggesting that abstract linguistic notions such as constituents or thematic roles does not seem to be present in the pretrained sentence embeddings.
Tracking linguistic information in transformer-based sentence embeddings through targeted sparsification
Jul 25, 2024Analyses of transformer-based models have shown that they encode a variety of linguistic information from their textual input. While these analyses have shed a light on the relation between linguistic information on one side, and internal architecture and parameters on the other, a question remains unanswered: how is this linguistic information reflected in sentence embeddings? Using datasets consisting of sentences with known structure, we test to what degree information about chunks (in particular noun, verb or prepositional phrases), such as grammatical number, or semantic role, can be localized in sentence embeddings. Our results show that such information is not distributed over the entire sentence embedding, but rather it is encoded in specific regions. Understanding how the information from an input text is compressed into sentence embeddings helps understand current transformer models and help build future explainable neural models.
Are there identifiable structural parts in the sentence embedding whole?
Jun 24, 2024



Sentence embeddings from transformer models encode in a fixed length vector much linguistic information. We explore the hypothesis that these embeddings consist of overlapping layers of information that can be separated, and on which specific types of information -- such as information about chunks and their structural and semantic properties -- can be detected. We show that this is the case using a dataset consisting of sentences with known chunk structure, and two linguistic intelligence datasets, solving which relies on detecting chunks and their grammatical number, and respectively, their semantic roles, and through analyses of the performance on the tasks and of the internal representations built during learning.
Disentangling continuous and discrete linguistic signals in transformer-based sentence embeddings
Dec 18, 2023Sentence and word embeddings encode structural and semantic information in a distributed manner. Part of the information encoded -- particularly lexical information -- can be seen as continuous, whereas other -- like structural information -- is most often discrete. We explore whether we can compress transformer-based sentence embeddings into a representation that separates different linguistic signals -- in particular, information relevant to subject-verb agreement and verb alternations. We show that by compressing an input sequence that shares a targeted phenomenon into the latent layer of a variational autoencoder-like system, the targeted linguistic information becomes more explicit. A latent layer with both discrete and continuous components captures better the targeted phenomena than a latent layer with only discrete or only continuous components. These experiments are a step towards separating linguistic signals from distributed text embeddings and linking them to more symbolic representations.
Grammatical information in BERT sentence embeddings as two-dimensional arrays
Dec 15, 2023Sentence embeddings induced with various transformer architectures encode much semantic and syntactic information in a distributed manner in a one-dimensional array. We investigate whether specific grammatical information can be accessed in these distributed representations. Using data from a task developed to test rule-like generalizations, our experiments on detecting subject-verb agreement yield several promising results. First, we show that while the usual sentence representations encoded as one-dimensional arrays do not easily support extraction of rule-like regularities, a two-dimensional reshaping of these vectors allows various learning architectures to access such information. Next, we show that various architectures can detect patterns in these two-dimensional reshaped sentence embeddings and successfully learn a model based on smaller amounts of simpler training data, which performs well on more complex test data. This indicates that current sentence embeddings contain information that is regularly distributed, and which can be captured when the embeddings are reshaped into higher dimensional arrays. Our results cast light on representations produced by language models and help move towards developing few-shot learning approaches.
* Published in RepL4NLP 2023
Semantic Relations and Deep Learning
Sep 14, 2020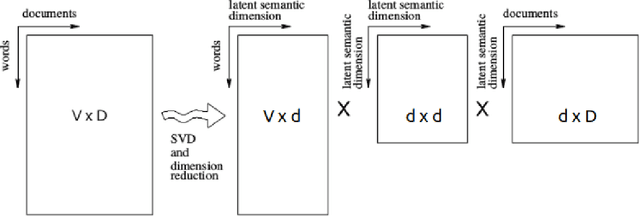
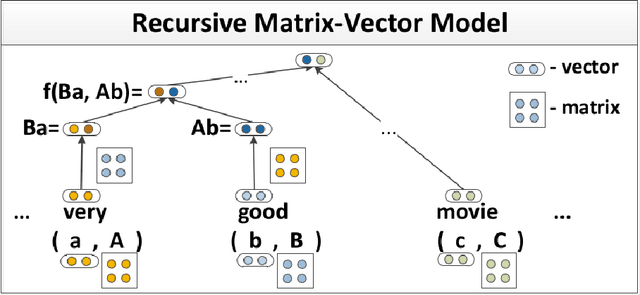
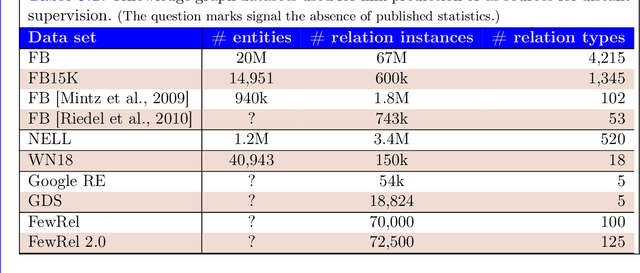
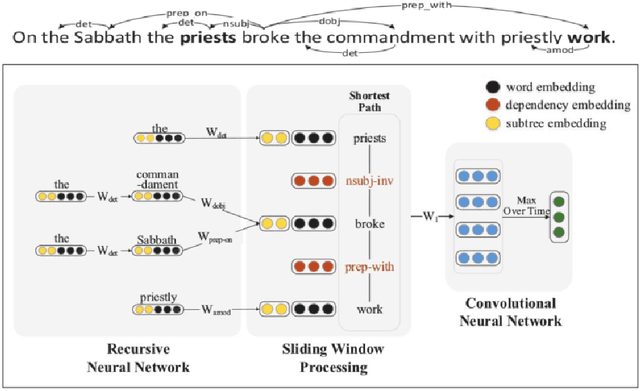
The second edition of "Semantic Relations Between Nominals" (by Vivi Nastase, Stan Szpakowicz, Preslav Nakov and Diarmuid \'O S\'eaghdha) will be published by Morgan & Claypool. A new Chapter 5 of the book discusses relation classification/extraction in the deep-learning paradigm which arose after the first edition appeared. This is a preview of Chapter 5, made public by the kind permission of Morgan & Claypool.
Assessing the Difficulty of Classifying ConceptNet Relations in a Multi-Label Classification Setting
May 14, 2019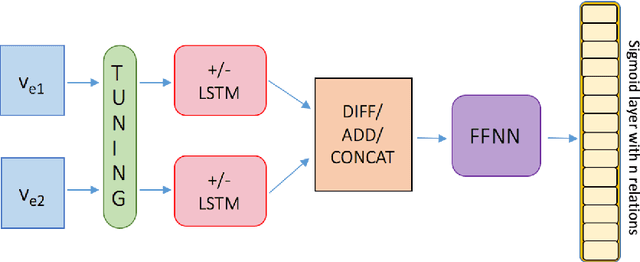

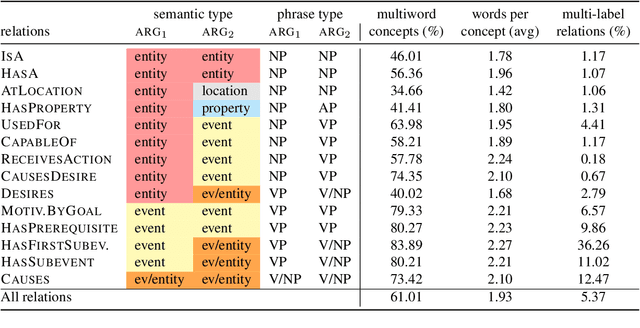
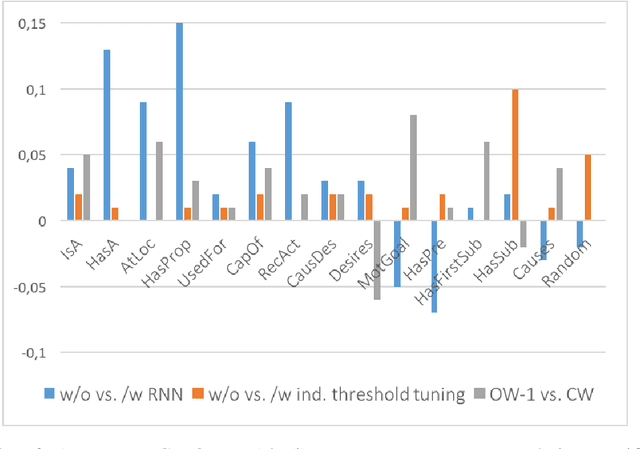
Commonsense knowledge relations are crucial for advanced NLU tasks. We examine the learnability of such relations as represented in CONCEPTNET, taking into account their specific properties, which can make relation classification difficult: a given concept pair can be linked by multiple relation types, and relations can have multi-word arguments of diverse semantic types. We explore a neural open world multi-label classification approach that focuses on the evaluation of classification accuracy for individual relations. Based on an in-depth study of the specific properties of the CONCEPTNET resource, we investigate the impact of different relation representations and model variations. Our analysis reveals that the complexity of argument types and relation ambiguity are the most important challenges to address. We design a customized evaluation method to address the incompleteness of the resource that can be expanded in future work.
Learning Knowledge Graph Embeddings with Type Regularizer
Mar 02, 2018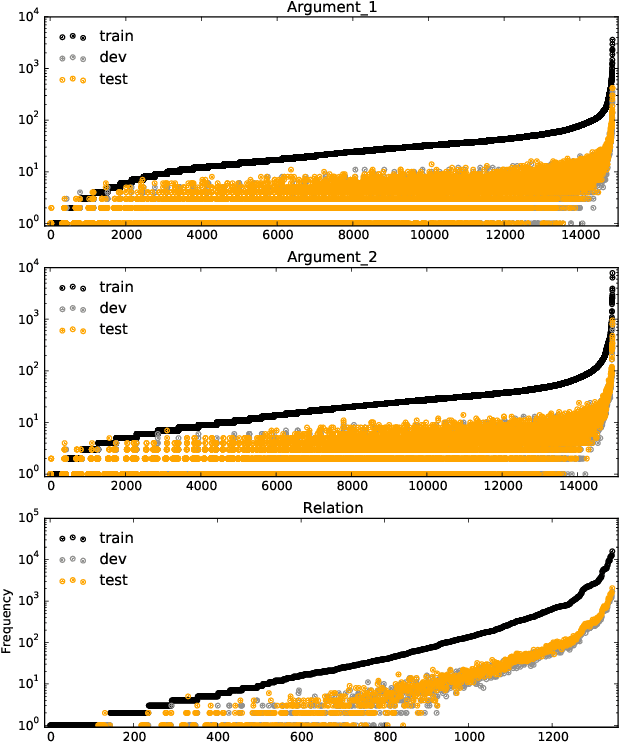
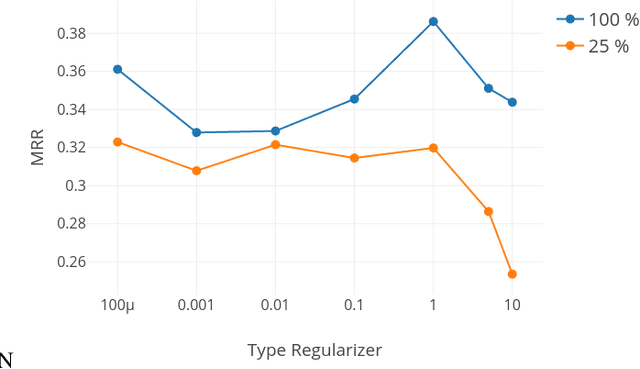
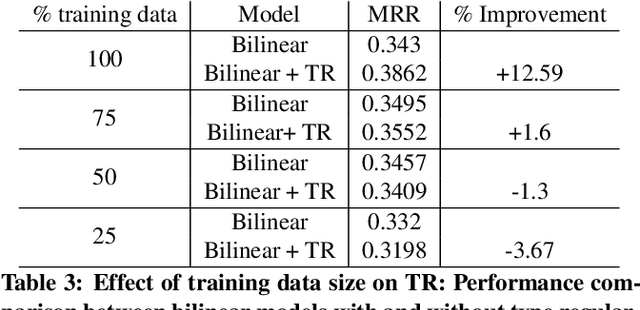
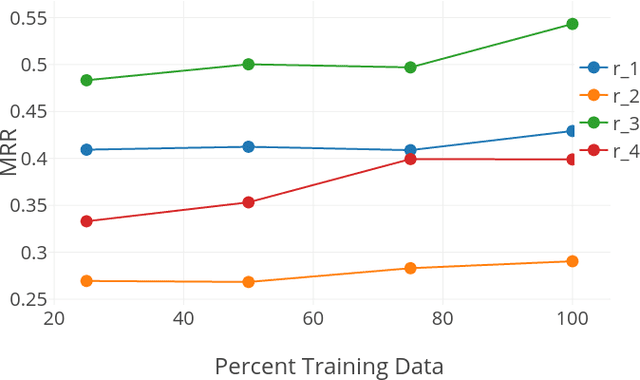
Learning relations based on evidence from knowledge bases relies on processing the available relation instances. Many relations, however, have clear domain and range, which we hypothesize could help learn a better, more generalizing, model. We include such information in the RESCAL model in the form of a regularization factor added to the loss function that takes into account the types (categories) of the entities that appear as arguments to relations in the knowledge base. We note increased performance compared to the baseline model in terms of mean reciprocal rank and hits@N, N = 1, 3, 10. Furthermore, we discover scenarios that significantly impact the effectiveness of the type regularizer.