 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Measure of a Model: From Intelligence to Generality
Nov 14, 2025Benchmarks such as ARC, Raven-inspired tests, and the Blackbird Task are widely used to evaluate the intelligence of large language models (LLMs). Yet, the concept of intelligence remains elusive- lacking a stable definition and failing to predict performance on practical tasks such as question answering, summarization, or coding. Optimizing for such benchmarks risks misaligning evaluation with real-world utility. Our perspective is that evaluation should be grounded in generality rather than abstract notions of intelligence. We identify three assumptions that often underpin intelligence-focused evaluation: generality, stability, and realism. Through conceptual and formal analysis, we show that only generality withstands conceptual and empirical scrutiny. Intelligence is not what enables generality; generality is best understood as a multitask learning problem that directly links evaluation to measurable performance breadth and reliability. This perspective reframes how progress in AI should be assessed and proposes generality as a more stable foundation for evaluating capability across diverse and evolving tasks.
Limitations of Cross-Lingual Learning from Image Search
Sep 18, 2017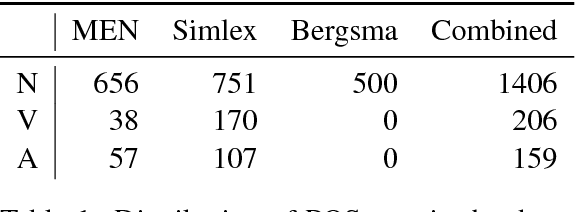

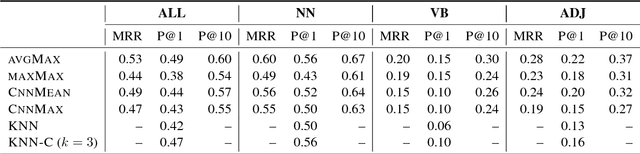
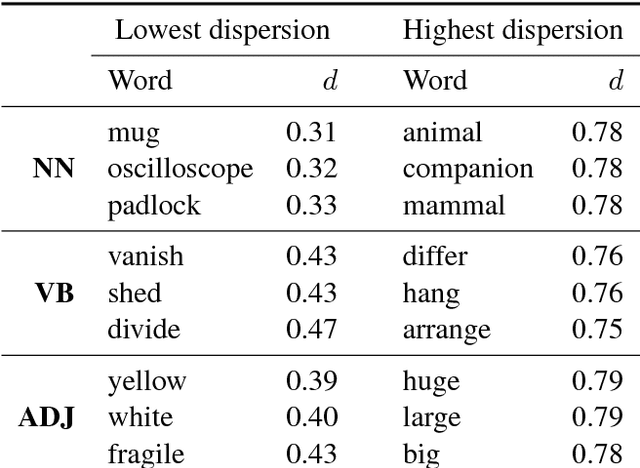
Cross-lingual representation learning is an important step in making NLP scale to all the world's languages. Recent work on bilingual lexicon induction suggests that it is possible to learn cross-lingual representations of words based on similarities between images associated with these words. However, that work focused on the translation of selected nouns only. In our work, we investigate whether the meaning of other parts-of-speech, in particular adjectives and verbs, can be learned in the same way. We also experiment with combining the representations learned from visual data with embeddings learned from textual data. Our experiments across five language pairs indicate that previous work does not scale to the problem of learning cross-lingual representations beyond simple nouns.