 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Transferability of Prompt Tuning for Natural Language Understanding
Paper and Code
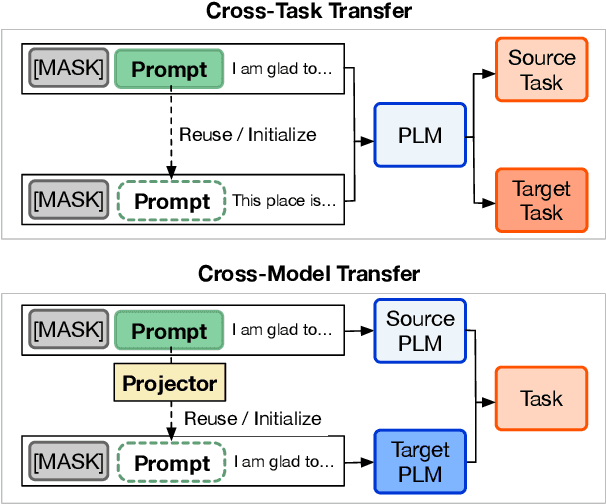
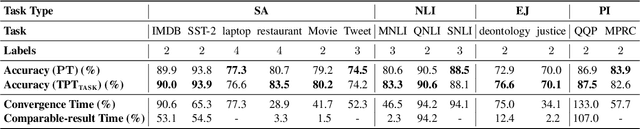
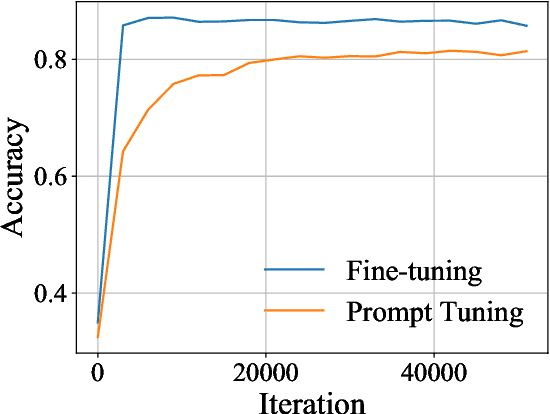
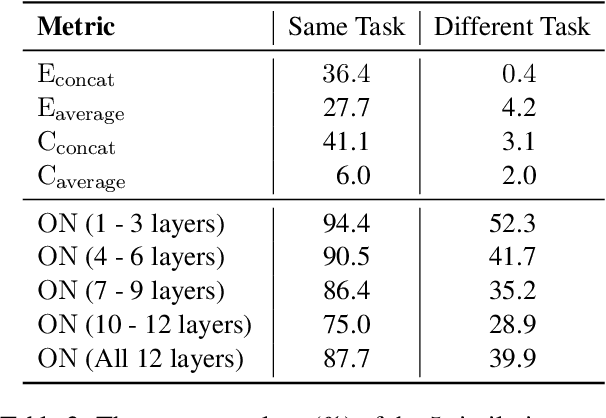
Prompt tuning (PT) is a promising parameter-efficient method to utilize extremely large pre-trained language models (PLMs), which could achieve comparable performance to full-parameter fine-tuning by only tuning a few soft prompts. However, compared to fine-tuning, PT empirically requires much more training steps. To explore whether we can improve the efficiency of PT by reusing trained soft prompts and sharing learned knowledge, we empirically investigate the transferability of soft prompts across different tasks and models. In cross-task transfer, we find that trained soft prompts can well transfer to similar tasks and initialize PT for them to accelerate training and improve performance. Moreover, to explore what factors influence prompts' transferability across tasks, we investigate how to measure the prompt similarity and find that the overlapping rate of activated neurons highly correlates to the transferability. In cross-model transfer, we explore how to project the prompts of a PLM to another PLM and successfully train a kind of projector which can achieve non-trivial transfer performance on similar tasks. However, initializing PT with the projected prompts does not work well, which may be caused by optimization preferences and PLMs' high redundancy. Our findings show that improving PT with knowledge transfer is possible and promising, while prompts' cross-task transferability is generally better than the cross-model transferability.