 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASS: Multi-Attentional Semantic Segmentation of LiDAR Data for Dense Top-View Understanding
Paper and Code
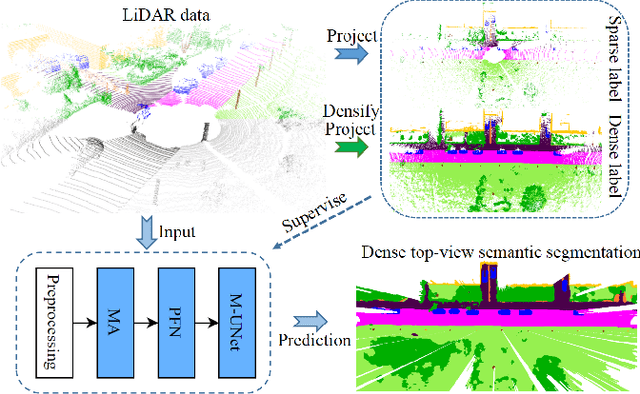
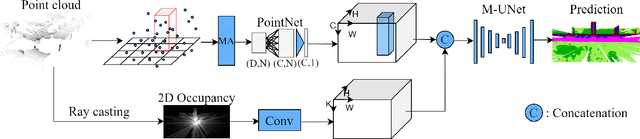
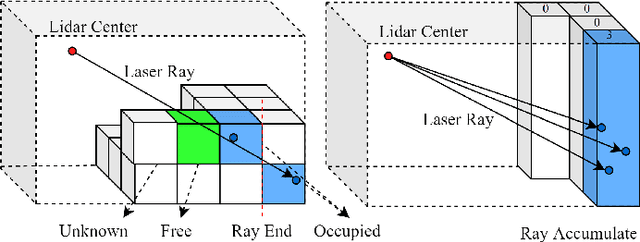
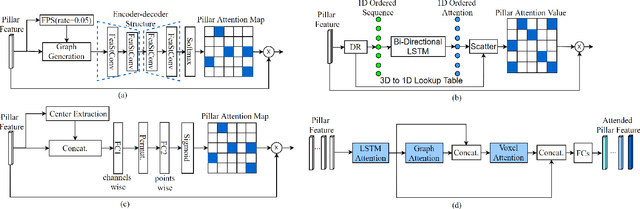
At the heart of all automated driving systems is the ability to sense the surroundings, e.g., through semantic segmentation of LiDAR sequences, which experienced a remarkable progress due to the release of large datasets such as SemanticKITTI and nuScenes-LidarSeg. While most previous works focus on sparse segmentation of the LiDAR input, dense output masks provide self-driving cars with almost complete environment information. In this paper, we introduce MASS - a Multi-Attentional Semantic Segmentation model specifically built for dense top-view understanding of the driving scenes. Our framework operates on pillar- and occupancy features and comprises three attention-based building blocks: (1) a keypoint-driven graph attention, (2) an LSTM-based attention computed from a vector embedding of the spatial input, and (3) a pillar-based attention, resulting in a dense 360-degree segmentation mask. With extensive experiments on both, SemanticKITTI and nuScenes-LidarSeg, we quantitatively demonstrate the effectiveness of our model, outperforming the state of the art by 19.0% on SemanticKITTI and reaching 32.7% in mIoU on nuScenes-LidarSeg, where MASS is the first work addressing the dense segmentation task. Furthermore, our multi-attention model is shown to be very effective for 3D object detection validated on the KITTI-3D dataset, showcasing its high generalizability to other tasks related to 3D vision.