 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossover Learning for Fast Online Video Instance Segmentation
Paper and Code
Apr 13, 2021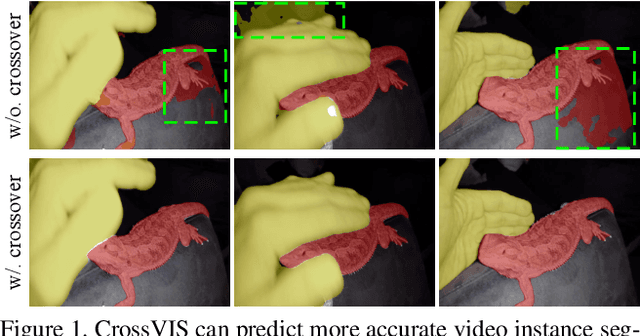
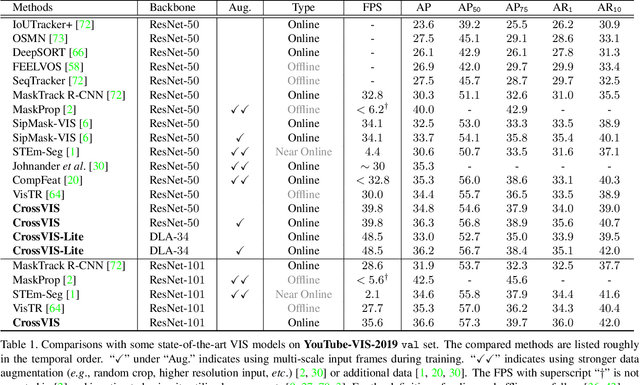
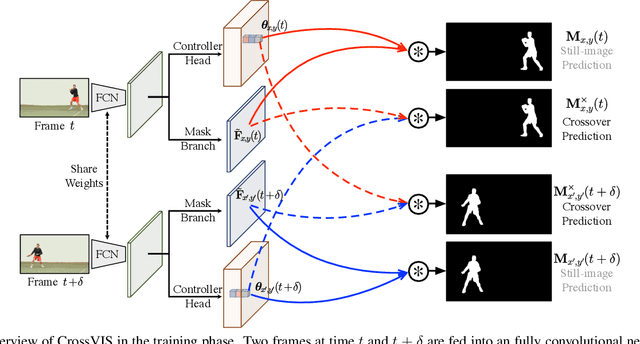
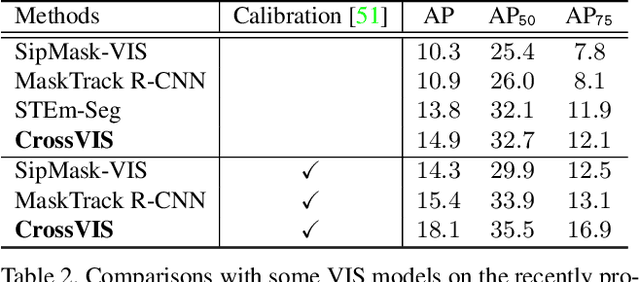
Modeling temporal visual context across frames is critical for video instance segmentation (VIS) and other video understanding tasks. In this paper, we propose a fast online VIS model named CrossVIS. For temporal information modeling in VIS, we present a novel crossover learning scheme that uses the instance feature in the current frame to pixel-wisely localize the same instance in other frames. Different from previous schemes, crossover learning does not require any additional network parameters for feature enhancement. By integrating with the instance segmentation loss, crossover learning enables efficient cross-frame instance-to-pixel relation learning and brings cost-free improvement during inference. Besides, a global balanced instance embedding branch is proposed for more accurate and more stable online instance association. We conduct extensive experiments on three challenging VIS benchmarks, \ie, YouTube-VIS-2019, OVIS, and YouTube-VIS-2021 to evaluate our methods. To our knowledge, CrossVIS achieves state-of-the-art performance among all online VIS methods and shows a decent trade-off between latency and accuracy. Code will be available to facilitate future research.